







在原来两个博文基础上整理而来
感谢一波这个博客和lgd1234567
实现代码可以直接git这个地址,里面预训练网络已经存在了,不需要额外下载模型数据im2txt_demo
Image Caption即图像描述,github上面的很多的项目是img2txt,目的是从图片中自动生成一段描述性文字,即看图说话。难点是不仅要能检测出图像中的物体,而且要理解物体之间的相互关系,最后还要用合理的语言表达出来。需要将图像中检测到的目标得到相应的向量,再将这些向量映射到文字。
图像识别方面fastrcnn,ssd等模型效果较好,下面图的项目链接
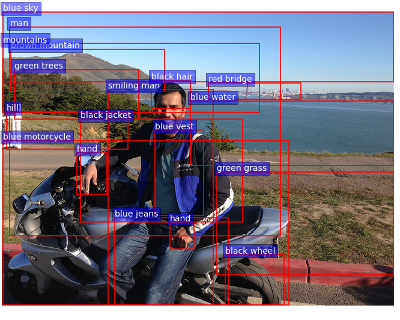
但是这一步仅仅完成了一半,下一步更多的是将这些词组成句子,这是NLP的问题。
接下来针对目前相关的论文进行相关理论的介绍,后面将会针对一个项目具体实现。
自己对NLP不了解,下面的一段是摘抄自「Show and Tell」——图像标注(Image Caption)任务技术综述
Encoder-Decoder结构
在介绍Image Caption相关的技术前,有必要先来复习一下RNN的Encoder-Decoder结构。我们知道,在最原始的RNN结构中,输入序列和输出序列必须是严格等长的。但在机器翻译等任务中,源语言句子的长度和目标语言句子的长度往往不同,因此我们需要将原始序列映射为一个不同长度的序列。Encoder-Decoder模型就解决了这样一个长度不一致的映射问题,它的结构如下图所示:

w1,w2,w3...wn w 1 , w 2 , w 3 ... w n 是输入的单词序列,而 y1,y2,...ym y 1 , y 2 , . . . y m 为输出的单词序列,每个wi和yi都是已经经过独热编码的单词,因此它们都是1xD的向量,其中D为程序中使用的单词表的长度。RNN的隐层状态(hidden state)用 h1,h2,h3...hn h 1 , h 2 , h 3 ... h n 表示。在实际应用中,我们往往不是把独热编码的 w1,w2,w3...wn w 1 , w 2 , w 3 ... w n 输入RNN,而是将其转换为对应的word embedding的形式,即图中的 x1,x2,x3...xn x 1 , x 2 , x 3 ... x n ,再输入RNN网络。在Encoder部分,RNN将所有的输入“编码”成一个固定的向量表示,即最后一个隐层状态 hn h n , 我们就认为这个 hn h n 包含了原始输入中所有有效的信息,,Decoder在每一步都会利用 h_{n} 这个信息,进行“解码”,并输出合适的单词序列 y1,y2,...ym y 1 , y 2 , . . . y m 。这样,我们就完成了不同长度序列之间的转换工作。
Encoder-Decoder结构最初是在论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中提出并应用到机器翻译系统中的。有兴趣的同学可以参考原始论文了解其细节,这里我们还是回到Image Caption任务中来,看看如何把Encoder-Decoder结构用到Image Caption上。
1. Show and Tell: A Neural Image Caption Generator
在Image Caption输入的图像代替了之前机器翻译中的输入的单词序列,图像是一系列的像素值,我们需要从使用图像特征提取常用的CNN从图像中提取出相应的视觉特征,然后使用Decoder将该特征解码成输出序列,下图是论文的网络结构,特征提取采用的是CNN,Decoder部分,将RNN换成了性能更好的LSTM,输入还是word embedding,每步的输出是单词表中所有单词的概率。

2.Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
将输入序列编码成语义特征
hn
h
n
再解码,但是因为
hn
h
n
的长度限制,会使得对于长句的翻译精度降低,论文《Neural machine translation by jointly learning to align and translate》提出了一种Attention机制,不再使用统一的语义特征,而让Decoder在输入序列中自由选取需要的特征,大大提高了Encoder-Decoder的模型性能。《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》利用Attention机制对原来的Encoder-Decoder机制进行改进。具体的就是利用CNN的空间特性,给图片的不同位置都提取一个特征,有了含位置信息的特征,Decoder在解码时拥有在这196个位置特征中选择的能力,这就是Attention机制。下图展示了一些例子,每个句子都是模型自动生成的,在图片中用白色高亮标注了生成下划线单词时模型关注的区域:

3.What Value Do Explicit High Level Concepts Have in Vision to Language Problems?
这篇文章提出了使用高层语义特,这个对于从事图像方向的人来说很好理解,CNN的最终的分类层具有全局信息,这对于生成的语句来说是很重要的,所以最后也需要将这些包含进去。该文的作者将高层语义理解为一个多标签的分类问题。当一个图像中存在多个物体时就变成了一对多的问题。
Decoder的结构和最初的那篇论文中的结构完全一致。如在下图中,蓝色的线就是之前直接使用的卷积特征 CNN(I) ,而红色线就是这篇文章提出的
Vatt(I)
V
att
(
I
)
。实验证明,使用
Vatt(I)
V
att
(
I
)
代替 CNN(I) 可以大幅提高模型效果。

4.Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation
之前的两篇论文,《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》以及《What Value Do Explicit High Level Concepts Have in Vision to Language Problems?》一个是给RNN加上了Attention结构,一个是改进了CNN提取的特征,都是比较好理解的。而这篇文章比较fancy,较多地改动了Decoder部分RNN的本身的结构,使得RNN网络不仅能将图像特征翻译为文字,还能反过来从文字得到图像特征,此外还顺带提高了性能,我们一起来看下是怎么做的。
下图就是这篇文章中使用的Decoder RNN。 v 表示图像特征,
st
s
t
表示第t阶段RNN的隐层状态,而
wt
w
t
是第t阶段生成的单词。
v,st,wt
v
,
s
t
,
w
t
这三个量都是之前的模型中存在的,而作者又再这些量的基础上加入了
ut
u
t
和
v~
v
~
。其中
ut
u
t
表示的是“已经生成的文字”的隐变量,作用是记住已经生成单词中包含的信息。这个量在每次生成
wt
w
t
时都会使用到,作为给模型的提示。此外,作者还要求在每个阶段都可以使用
ut
u
t
去还原视觉信息 v ,通过
ut
u
t
计算的视觉信息就是
v~
v
~
,在训练尽可能要求
v~≈v
v
~
≈
v
,换句话说,我们已经生成的文字都要尽可能地去表达视觉信息,才能做到这样的还原。

设
Wt={w1,w2,...,wt}
W
t
=
{
w
1
,
w
2
,
.
.
.
,
w
t
}
,表示在第t阶段已经生成的所有t个单词。
Ut={u1,u2,...,ut}
U
t
=
{
u
1
,
u
2
,
.
.
.
,
u
t
}
是已经生成的单词表达信息的隐变量。这篇文章的核心就是,我们之前建模的都是
P(wt|v,Wt−1,Ut−1)
P
(
w
t
|
v
,
W
t
−
1
,
U
t
−
1
)
,即在图像信息和已经生成单词的条件下找寻下一个单词的概率,而这篇文章建模的是
P(wt,v|Wt−1,Ut−1)
P
(
w
t
,
v
|
W
t
−
1
,
U
t
−
1
)
,由于这是
wt
w
t
,v 的联合分布,因此我们不仅可以生成文字,还可以反过来利用文字生成图像特征。
如下图,我们在生成文字的时候,不需要用到
v~
v
~
,因此将其去掉即可:

在利用文字生成图像特征时,没有下面的 v 和
st
s
t
,同样将之去除:

5.From Captions to Visual Concepts and Back
最后还有一篇不得不提到的《From Captions to Visual Concepts and Back》。这篇为微软出品,是和第一篇谷歌的论文同时期的文章,它们都去参加了微软的Image Caption比赛(MS COCO caption challenge),总的结果是并列第一(如下图),在具体的小指标上各有上下,都是属于开创性的工作。之所以放到最后讲是因为它并不属于Encoder-Decoder架构,而是采用传统的语言建模方式。

在图像特征提取方面,这篇文章和《What Value Do Explicit High Level Concepts Have in Vision to Language Problems?》类似,都是从图像中提取可能存在的单词,再对语言进行建模。不同点在于,之前那篇文章采用的是多标签学习的方式,而这篇文章采用的是多示例学习(Multiple Instance Learning)的方法,不仅可以从图像中提取可能的单词,而且可以把单词对应到具体的图像区域。
首先来简单介绍下多示例学习。多示例学习实际是一种半监督算法。考虑这样一种训练数据:我们有很多个数据包(bag),每个数据包中有很多个示例(instance)。我们只有对bag的正负类标记,而没有对instance的正负例标记。当一个bag被标记为正时,这个包里一定有一个instance是正类,但也有可能其他instance是负类,当一个bag被标记为负类时,它里面的所有instance一定是负类。我们的目标是训练一个分类器,可以对instance的正负进行判别。
多示例学习在现实中其实很常见。如一篇文章违禁时通常是因为该文章具有某些违禁词,但我们可能无法知道具体是哪个词违禁。在这个例子中,bag就是文章,instance就是单词。又如在医学图像领域,CT图被标定为有无病症,而一个人有病症是因为在CT图的某个区域被检测为病灶区域。我们往往只有CT图的标注,但没有CT图中每个区域的标注。这时,bag就是CT图像,而instance就是CT图中的小区域。
在这篇论文中,就是使用多示例学习来处理从图片出提取单词这一问题。对每一个单词来说,标注中含有该单词的图片就是正例的bag,图中的区域就是instance。由此,我们使用多示例学习方法进行两步迭代,第一步是利用当前算法,选出正例bag中最有可能是正例的instance、以及负例bag的instance,第二步是利用选出的instance进行训练,更新训练。这样迭代下去,就可以对图片的区域进行分类了。这样我们就可以从图片的区域中提取所需要的单词(如下图)。在实际操作的时候,使用的是一种针对目标检测改进版的多示例学习方法Noisy-OR MIL,细节可以参考论文《Multiple instance boosting for object detection》。

在图像中提取好单词后,这篇文章就采用一种传统的方法来进行语言建模。设在图片中提取的单词都放在一个集合
V~
V
~
中,自动生成的图片标注为
{w1,w2,w3....}
{
w
1
,
w
2
,
w
3
.
.
.
.
}
,我们的目标就是去建模
P(wl|w1,w2,w3,....wl−1,Vl~)
P
(
w
l
|
w
1
,
w
2
,
w
3
,
.
.
.
.
w
l
−
1
,
V
l
~
)
,其中
Vl~⊂V~
V
l
~
⊂
V
~
,表示生成第l个单词时,还没有使用的单词。
建模 P(wl|w1,w2,w3,....wl−1 P ( w l | w 1 , w 2 , w 3 , . . . . w l − 1 , Vl~) V l ~ ) 的方法是使用一些特征提取函数从 wl,w1,w2,w3,....wl−1 w l , w 1 , w 2 , w 3 , . . . . w l − 1 , Vl~ V l ~ 这些单词中提取一些特征,如文中使用了 wi w i 是否属于 Vl~ V l ~ 、 n−Gram n − G r a m 关系等特征,每个特征提取函数设为 fk f k ,对每个要生成的单词,就可以得到一个打分 ∑kλkfk(wl,w1,w2,w3,....wl−1$,$Vl~) ∑ k λ k f k ( w l , w 1 , w 2 , w 3 , . . . . w l − 1 $ , $ V l ~ ) ,最后使用softmax函数将这些打分转换为概率即可。
实现img2txt
1.下载项目源码及配置环境
首先需要配置tensorflow的环境,接下来需要需要下载im2txt的文件,该文件在tensorflow/model下,我们需要下载完整的tensorflow的文件。这个项目的论文是Show and Tell: A Neural Image Caption Generator,需要的数据集是mscoco。
git下载整个model文件
git clone https://github.com/tensorflow/models.git我的电脑已经配置好了环境,所以此步略去了,具体的步骤可以参照下面的,也可以参照我上面的安装环境的链接:
首先按照 Github 上 im2txt 的说明,安装所有必需的包
- 安装Bazel
- 安装TensorFlow 1.0或更高版本
- 安装 NumPy
- Natural Language Toolkit (NLTK)
下载模型和词汇
如果要自己训练模型,按照官网的说法,需要先下载几个小时的数据集,然后再训练1~2周,最后还要精调几个星期训练要花不少时间,所以用训练好的模型,下载地址是
原地址 (如果有VPN)
网盘地址: 密码:9bun
github上面的下载地址
下载之后放在 im2txt/model 文件夹下
im2txt/
......
model/
graph.pbtxt
model.ckpt-2000000
model.ckpt-2000000.meta同时下载包含词语的文件 word_counts.txt,下载好之后放在 data 文件夹下
编写脚本
在 im2txt 文件夹下新建一个 run.sh 脚本文件,输入以下命令
CHECKPOINT_PATH="${HOME}/im2txt/model/train"
VOCAB_FILE="${HOME}/im2txt/data/mscoco/word_counts.txt"
IMAGE_FILE="${HOME}/im2txt/data/mscoco/raw-data/val2014/COCO_val2014_000000224477.jpg"
bazel build -c opt //im2txt:run_inference
bazel-bin/im2txt/run_inference \
--checkpoint_path=${CHECKPOINT_PATH} \
--vocab_file=${VOCAB_FILE} \
--input_files=${IMAGE_FILE}其中的变量用自己的路径代替,比如我当前设置的路径
#CHECKPOINT_PATH="/home/andy/workspace/im2txt/model/model.ckpt-2000000"
CHECKPOINT_PATH="/home/andy/workspace/im2txt/model/newmodel.ckpt-2000000"
VOCAB_FILE="/home/andy/workspace/im2txt/data/word_counts.txt"
IMAGE_FILE="/home/andy/workspace/im2txt/data/images/6.jpg"
bazel build -c opt //im2txt:run_inference
bazel-bin/im2txt/run_inference \
--checkpoint_path=${CHECKPOINT_PATH} \
--vocab_file=${VOCAB_FILE} \
--input_files=${IMAGE_FILE}
运行脚本
sudo chmod 777 run.sh然后将工作目录设置为 im2txt 的上层目录,运行脚本
./im2txt/run.sh随便百度了一张图片进行了一下测试

INFO: Analysed target //im2txt:run_inference (0 packages loaded).
INFO: Found 1 target...
Target //im2txt:run_inference up-to-date:
bazel-bin/im2txt/run_inference
INFO: Elapsed time: 0.185s, Critical Path: 0.00s
INFO: Build completed successfully, 1 total action
INFO:tensorflow:Building model.
INFO:tensorflow:Initializing vocabulary from file: /home/andy/workspace/im2txt/data/word_counts.txt
INFO:tensorflow:Created vocabulary with 11519 words
INFO:tensorflow:Running caption generation on 1 files matching /home/andy/workspace/im2txt/data/images/6.jpg
2018-01-26 18:49:48.147488: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2 AVX AVX2 FMA
2018-01-26 18:49:48.374003: I tensorflow/core/common_runtime/gpu/gpu_device.cc:965] Found device 0 with properties:
name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.582
pciBusID: 0000:06:00.0
totalMemory: 10.91GiB freeMemory: 10.28GiB
2018-01-26 18:49:48.374033: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1055] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:06:00.0, compute capability: 6.1)
INFO:tensorflow:Loading model from checkpoint: /home/andy/workspace/im2txt/model/newmodel.ckpt-2000000
INFO:tensorflow:Restoring parameters from /home/andy/workspace/im2txt/model/newmodel.ckpt-2000000
INFO:tensorflow:Successfully loaded checkpoint: newmodel.ckpt-2000000
Captions for image 6.jpg:
0) a woman in a blue dress holding a pink umbrella . (p=0.000009)
1) a woman in a blue dress holding a pink flower . (p=0.000009)
2) a woman in a dress is holding a pink flower . (p=0.000004)
同时 bazel build 命令会在 WORKSPACE 的同级目录下生成一些文件夹
bazel-bin/
bazel-genfiles/
bazel-out/
bazel-testlogs/`这里写代码片`
......而 bazel-bin 下就是编译好的 run_inference,会在 run.sh 中被调用
错误总结
1.在执行 run.sh 时,bazel 的 build 命令只能运行在工作目录下
ERROR: The 'build' command is only supported from within a workspace.解决方法是,在执行 run.sh 的目录下新建一个 WORKSPACE
touch WORKSPACE2. 找不到 im2txt 包
在执行 run.sh 时,出现找不到 im2txt 包的错误
ERROR: Skipping '//im2txt:run_inference': no such package 'im2txt': BUILD file not found on package path
WARNING: Target pattern parsing failed.
ERROR: no such package 'im2txt': BUILD file not found on package path
INFO: Elapsed time: 0.107s
FAILED: Build did NOT complete successfully (0 packages loaded)
./run.sh: 9: ./run.sh: bazel-bin/im2txt/run_inference: not found这是因为没有在 im2txt 的上层目录执行,解决方法是在 im2txt 的上层目录执行 run.sh 脚本
或者直接在 run.sh 添加一句返回上层目录的命令
CHECKPOINT_PATH="/home/w/workspace/tensorflow-space/tensorflow-gpu/practices/im2txt/model/model.ckpt-2000000"
VOCAB_FILE="/home/w/workspace/tensorflow-space/tensorflow-gpu/practices/im2txt/data/word_counts.txt"
IMAGE_FILE="/home/w/workspace/tensorflow-space/tensorflow-gpu/practices/im2txt/data/images/1.jpg"
cd .. # 返回上层目录
bazel build -c opt run_inference
bazel-bin/im2txt/run_inference \
--checkpoint_path=${CHECKPOINT_PATH} \
--vocab_file=${VOCAB_FILE} \
--input_files=${IMAGE_FILE}然后直接在 run.sh 的当前目录下执行
./run.sh3. 找不到 lstm/basic_lstm_cell/×××
运行 run.sh 时,TensorFlow 在模型中找不到 lstm/basic_lstm_cell/×××
# 错误1
NotFoundError: Tensor name "lstm/basic_lstm_cell/bias" not foundin checkpoint files
# 错误2
NotFoundError: Key lstm/basic_lstm_cell/kernel not found in checkpoint这是因为 TF1.0 和 TF1.2 的 LSTM 在命名上出现了差异,TF1.0 之前的命名跟 TF1.0 也不一样,所以需要根据错误信息自己修改
| TF1.0 | TF1.2 |
|---|---|
| lstm/basic_lstm_cell/weights | lstm/basic_lstm_cell/kernel |
| lstm/basic_lstm_cell/biases | lstm/basic_lstm_cell/bias |
解决方式是,新建 rename_ckpt.py 文件,使用输入以下方法将原有训练模型转化
解决方式是,新建 rename_ckpt.py 文件,使用输入以下方法将原有训练模型转化
import tensorflow as tf
def rename_ckpt():
vars_to_rename = {
"lstm/BasicLSTMCell/Linear/Bias": "lstm/basic_lstm_cell/bias",
"lstm/BasicLSTMCell/Linear/Matrix": "lstm/basic_lstm_cell/kernel"
}
new_checkpoint_vars = {}
reader = tf.train.NewCheckpointReader(
"/home/andy/workspace//im2txt/model/model.ckpt-2000000"
)
for old_name in reader.get_variable_to_shape_map():
if old_name in vars_to_rename:
new_name = vars_to_rename[old_name]
else:
new_name = old_name
new_checkpoint_vars[new_name] = tf.Variable(
reader.get_tensor(old_name))
init = tf.global_variables_initializer()
saver = tf.train.Saver(new_checkpoint_vars)
with tf.Session() as sess:
sess.run(init)
saver.save(
sess,
"/home/andy/workspace//im2txt/model/newmodel.ckpt-2000000"
)
print("checkpoint file rename successful... ")
if __name__ == '__main__':
rename_ckpt()运行 rename_ckpt.py 脚本,成功修改之后的结果如下
$ python rename_ckpt.py
checkpoint file rename successful...此时,model 文件夹下会出现几个新的文件
model/
......
checkpoint
newmodel.ckpt-2000000.data-00000-of-00001
newmodel.ckpt-2000000.index
newmodel.ckpt-2000000.meta同时还要将 run.sh 脚本中的 CHECKPOINT_PATH 改成修改后的 ckpt 文件
CHECKPOINT_PATH="/home/andy/workspace/im2txt/model/newmodel.ckpt-2000000"后面的错误没有遇到
4. 读取图片错误
运行 run.sh 时,出现编码的错误信息,而错误追踪信息表明是读取图片时发生的错误
Traceback (most recent call last):
File "/home/widiot/workspace/tensorflow-space/tensorflow-gpu/practices/bazel-bin/im2txt/run_inference.runfiles/__main__/im2txt/run_inference.py", line 85, in <module>
tf.app.run()
File "/home/widiot/workspace/tensorflow-space/tensorflow-gpu/venv/lib/python3.5/site-packages/tensorflow/python/platform/app.py", line 129, in run
_sys.exit(main(argv))
File "/home/widiot/workspace/tensorflow-space/tensorflow-gpu/practices/bazel-bin/im2txt/run_inference.runfiles/__main__/im2txt/run_inference.py", line 74, in main
image = f.read()
......
'utf-8' codec can't decode byte 0xff in position 0: invalid start byte解决方法是修改一下打开图片的方式,我出现错误的文件是 run_inference.py
for filename in filenames:
with tf.gfile.GFile(filename, "r") as f:
image = f.read()
# 第73行修改为
for filename in filenames:
with tf.gfile.GFile(filename, "rb") as f:
image = f.read()该错误地址为 issue
5. 输出相同叙述文本
执行 run.sh 脚本后,输出的结果全是一样的叙述文本,并且后面还有很多 . 和 <S>
......
Captions for image 1.jpg:
0) a man riding a wave on top of a surfboard . <S> . <S> . <S> <S> . (p=0.001145)
1) a man riding a wave on top of a surfboard . <S> . <S> <S> . <S> <S> (p=0.000888)
2) a man riding a wave on top of a surfboard . <S> . <S> <S> . <S> <S> (p=0.000658)我查看了代码,发现 caption_generator.py 脚本中有判断是不是结束符 </S>的语句
......
# 第194行
if w == self.vocab.end_id:
if self.length_normalization_factor > 0:
......而这一行代码的结果始终为 False,我将 w 的值和 end_id 的值对比发现 w=2,而 end_id=3
然后我去查看 word_counts.txt,发现<S>的位置为 2,</S>的位置为 3,跟代码中模型的输出不一样
a 969108
<S> 586368
</S> 586368
. 440479
on 213612
of 202290
......将这两个字符调换位置,重新运行 run.sh,结果就正常了
......
Captions for image 1.jpg:
0) a man riding a wave on top of a surfboard . (p=0.035667)
1) a person riding a surf board on a wave (p=0.016235)
2) a man on a surfboard riding a wave . (p=0.010144)
参考资料:
【TensorFlow】im2txt — 将图像转为叙述文本
「Show and Tell」——图像标注(Image Caption)任务技术综述

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









