







基础知识
二叉树的数据结构
struct TreeNode{
int val; //数据域
TreeNode *left //左右指针
TreeNode *right
TreeNode(int x):val(x),left(NULL),right(NULL){}
//构造函数
}构造二叉树
构造如下的一棵二叉树:
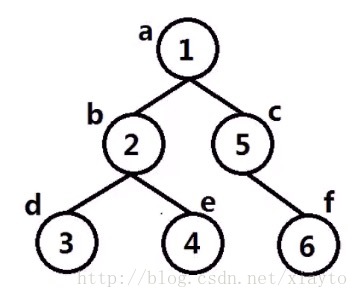
int main(){
TreeNode a(1);
TreeNode b(2);
TreeNode c(3);
TreeNode d(4);
TreeNode e(5);
TreeNode f(6);
a.left=&b;
a.right=&c;
b.left=&d;
b.right=&e;
c.right=&f;
}二叉树的深度遍历
前序遍历访问
traversal(node->left)
中序遍历访问
traversal(node->right)
后序遍历访问
前中后指的是访问根节点的顺序,前序:先根再左再右
二叉树的层次遍历
也就是广度优先搜索,用队列一层一层的访问节点,访问一个节点压入该节点的孩子节点,队列不空,持续该过程。
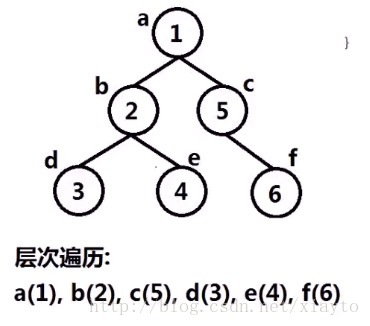
void BFS_print(TreeNode* root){
queue<TreeNode*> Q;
Q.push(root);
while(!Q.empty()){
TreeNode* node=Q.front();
Q.pop();
printf("(%d)\n",node->val);
if(node->left){
Q.push(node->left;
}
if(node->right){
Q.push(node->right;
}
}
}leetcode题目
113 Path Sum
题意:
给定一个二叉树与整数sum,找出所有从根节点到叶节点的路径,要求这些路径上节点值的和等于sum。
解题思路:
用深度优先搜索路径。
1 先序遍历时将节点值存储到path栈中,path_value累加节点值
2 当遍历到叶节点时判断path_value是不是等于sum,if等于push进result中。
3 在后序遍历时,将节点从path栈中弹出,path_value减去节点值
代码:
class Solution {
public:
vector<vector<int>> pathSum(TreeNode* root, int sum) {
vector<vector<int>> result;
vector<int> path;
int path_value=0;
preorder(root,path_value,sum,path,result);
return result;
}
private:
void preorder(TreeNode *node,int &path_value,int sum,vector<int> &path,vector<vector<int>> &result){
//先序遍历内容:
if(!node){
return;
}
path_value=path_value+node->val;
path.push_back(node->val);
if(!node->left&&!node->right&&path_value==sum){
result.push_back(path);
}
preorder(node->left,path_value,sum,path,result);
preorder(node->right,path_value,sum,path,result);
//后序遍历内容:
path.pop_back();
path_value=path_value-node->val;
}
};236 Lowest Common Ancestor of a Binary Tree
题意:
给出两个节点,求出他们最近的公共祖先。
解题思路:
1 用深度优先搜索找点,找到点后保存路径。
2 同时遍历两个路径,找最后一个相同点。
代码:
void preorder(TreeNode* node,
TreeNode *search,
std::vector<TreeNode*> &path,
std::vector<TreeNode*> &result,
int &finish){
if (!node || finish){
return; //结束技巧,finish用于标记已找到节点
}
path.push_back(node);
if (node == search){
finish = 1;
result = path;
}
preorder(node->left, search, path, result, finish);
preorder(node->right, search, path, result, finish);
path.pop_back();//后序遍历时根节点要做退出操作,就是左右节点都不是要找的点,根节点弹出
}
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
std::vector<TreeNode*> path;
std::vector<TreeNode*> node_p_path;
std::vector<TreeNode*> node_q_path;
int finish = 0;
preorder(root, p, path, node_p_path, finish);//找p点的路径并保存于node_p_path
path.clear();
finish = 0;
preorder(root, q, path, node_q_path, finish);//找q点的路径并保存于node_q_path
int path_len = 0;
if (node_p_path.size() < node_q_path.size()){
path_len = node_p_path.size();
}
else{
path_len = node_q_path.size();
}
TreeNode *result = 0;
//找两个路径中最后一个相同点
for (int i = 0; i < path_len; i++){
if (node_p_path[i] == node_q_path[i]){
result = node_p_path[i];//少写一点代码
}
}
return result;
}
};114. Flatten Binary Tree to Linked List
题意:
不用大的额外空间,将二叉树转换为链表,left为null,right为链表的next指针。链表的顺序是树的先序遍历。
解题思路:
如果不考虑大的额外空间,最简单的做法是用一个vector存先序遍历的结果,然后遍历这个vector。
代码:
class Solution {
public:
void flatten(TreeNode *root) {
std::vector<TreeNode *> node_vec;
preorder(root, node_vec);
for (int i = 1; i < node_vec.size(); i++){
node_vec[i-1]->left = NULL;
node_vec[i-1]->right = node_vec[i];
}
}
private:
void preorder(TreeNode *node,vector<TreeNode *> &node_vec){
if (!node){
return;
}
node_vec.push_back(node);
preorder(node->left, node_vec);
preorder(node->right, node_vec);
}
};解题思路2:
思考过程是:独立开树的一部分,思考前中后遍历时候应该做什么。考虑输入和输出:
* 先序遍历:第一次访问根节点时,我们要保留左右节点,让right指针指向左节点。右指针指向NULL。
* 中序遍历:第二次访问根节点,这时左子树完成了链表变形,要将左子树的最后节点指向,右子树的开始节点。所以要输出一个末尾节点,可以用&引用去维护。
* 后续遍历:维护最末的节点。
代码:
class Solution {
public:
void flatten(TreeNode* root) {
TreeNode *last=NULL;
preorder(root,last);
}
private:
void preorder(TreeNode* node,TreeNode* &last){
//*& TreeNode*的意思是传入TreeNode的指针变量,&是可以在函数中改变这个变量
if(!node){
return;
}
if(!node->left&&!node->right){
last=node;
return;
}
TreeNode* left=node->left; //保留左右节点
TreeNode* right=node->right;
TreeNode* left_last=NULL;//初始化要维护的末尾节点。
TreeNode* right_last=NULL;
if(left){
preorder(left,left_last);//递归,维护左子树的末尾节点
node->left=NULL; //放在中序遍历执行时因为可以省去判断是否有左子树的语句。
node->right=left;
last=left_last;
}
if(right){
preorder(right,right_last);
if(left_last){
left_last->right=right;//让左子树的末尾节点指向右子树的开始节点。放在后序遍历执行可以省去判断是否有右子树的语句。
}
last=right_last;//维护右子树的末尾节点
}
}
};199.Binary Tree Right Side View
题意:
从右边观察二叉树,输出每一层最右边的节点。
解题思路:
层次遍历二叉树,将节点和层数绑定微pair,压入队列时,将节点和层数同时压入,记录每一层的最后一个节点。
代码:
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
vector<int> view; //存储每层最后的节点。
queue<pair<TreeNode*,int>> Q;
//广度优先搜索,用一个pair存储节点和它对应的层数。
if(root){
Q.push(make_pair(root,0));
}
while(!Q.empty()){
TreeNode* node=Q.front().first;
int depth=Q.front().second;
Q.pop();
if(view.size()==depth){
view.push_back(node->val); //当出现新的层时压入一个节点。
}
else{
view[depth]=node->val;
}
if(node->left){
Q.push(make_pair(node->left,depth+1)); //压入左节点,标记为下一层
}
if(node->right){
Q.push(make_pair(node->right,depth+1)); //压入右节点,标记为下一层
}
}
return view;
}
};图
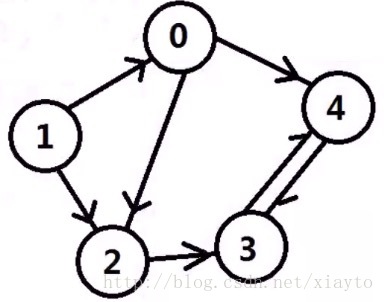
图的表示(邻接矩阵):

代码:
int main(){
const int MAX_N = 5;
int Graph[MAX_N][MAX_N] = {0};
Graph[0][2] = 1;
Graph[0][4] = 1;
Graph[1][0] = 1;
Graph[1][2] = 1;
Graph[2][3] = 1;
Graph[3][4] = 1;
Graph[4][3] = 1;
printf("Graph:\n");
for (int i = 0; i < MAX_N; i++){
for (int j = 0; j < MAX_N; j++){
printf("%d ", Graph[i][j]);
}
printf("\n");
}
return 0;
}表示稠密图作用比较大,但是表示稀疏图一般用邻接表。
图的表示(邻接表):

代码:
#include <stdio.h>
#include <vector>
struct GraphNode{
int label;
std::vector<GraphNode *> neighbors;
GraphNode(int x) : label(x) {};
};
int main(){
const int MAX_N = 5;
GraphNode *Graph[MAX_N];
for (int i = 0; i < MAX_N; i++){
Graph[i] = new GraphNode(i);
}
Graph[0]->neighbors.push_back(Graph[2]);
Graph[0]->neighbors.push_back(Graph[4]);
Graph[1]->neighbors.push_back(Graph[0]);
Graph[1]->neighbors.push_back(Graph[2]);
Graph[2]->neighbors.push_back(Graph[3]);
Graph[3]->neighbors.push_back(Graph[4]);
Graph[4]->neighbors.push_back(Graph[3]);
printf("Graph:\n");
for (int i = 0; i < MAX_N; i++){
printf("Label(%d) : ", i);
for (int j = 0; j < Graph[i]->neighbors.size(); j++){
printf("%d ", Graph[i]->neighbors[j]->label);
}
printf("\n");
}
for (int i = 0; i < MAX_N; i++){
delete Graph[i];
}
return 0;
}深度优先搜索
struct GraphNode{
int label;
std::vector<GraphNode *> neighbors;
GraphNode(int x) : label(x) {};
};
void DFS_graph(GraphNode *node, int visit[]){
visit[node->label] = 1;
printf("%d ", node->label);
for (int i = 0; i < node->neighbors.size(); i++){
if (visit[node->neighbors[i]->label] == 0){
DFS_graph(node->neighbors[i], visit);
}
}
} 广度优先搜索
struct GraphNode{
int label;
std::vector<GraphNode *> neighbors;
GraphNode(int x) : label(x) {};
};
void BFS_graph(GraphNode *node, int visit[]){
std::queue<GraphNode *> Q;
Q.push(node);
visit[node->label] = 1;
while(!Q.empty()){
GraphNode *node = Q.front();
Q.pop();
printf("%d ", node->label);
for (int i = 0; i < node->neighbors.size(); i++){
if (visit[node->neighbors[i]->label] == 0){
Q.push(node->neighbors[i]);
visit[node->neighbors[i]->label] = 1;
}
}
}
}leetcode题目
207. Course Schedule
题意:给出课程之间的依赖关系,求是否可以将所有的课程全部完成。其实就是求有向图是否有环。
解题思路一:
- 用深度优先搜索,如果递归搜索某一条路径时发现路径中有重复的节点,则有环,不能完成。
- 这里的visit的数组要设计三种状态:-1是未被搜索,0是正在被搜索的路径上,1是已经完成搜索的节点。
- 像递归二叉树思考方式一样,思考先序中序后序遍历要进行什么操作:
- 先序遍历:将该节点标记状态visit为0
- 中序遍历:如果访问过程中出现访问到visit为0的点则返回false
- 后续遍历:访问完成将该节点标记状态visit为-1
代码:
struct GraphNode{
int label;
std::vector<GraphNode *> neighbors;
GraphNode(int x) : label(x) {};
};
bool DFS_graph(GraphNode *node, std::vector<int> &visit){
visit[node->label] = 0;
for (int i = 0; i < node->neighbors.size(); i++){
if (visit[node->neighbors[i]->label] == -1){
if (DFS_graph(node->neighbors[i], visit) == 0){
return false;
}
}
else if (visit[node->neighbors[i]->label] == 0){
return false;
}
}
visit[node->label] = 1;
return true;
}
class Solution {
public:
bool canFinish(int numCourses,
std::vector<std::pair<int, int> >& prerequisites) {
std::vector<GraphNode*> graph;
std::vector<int> visit;
for (int i = 0; i < numCourses; i++){
graph.push_back(new GraphNode(i));
visit.push_back(-1);
}
for (int i = 0; i < prerequisites.size(); i++){
GraphNode *begin = graph[prerequisites[i].second];
GraphNode *end = graph[prerequisites[i].first];
begin->neighbors.push_back(end);
}
for (int i = 0; i < graph.size(); i++){
if (visit[i] == -1 && !DFS_graph(graph[i], visit)){
return false;
}
}
for (int i = 0; i < numCourses; i++){
delete graph[i];
}
return true;
}
};解题思路二:
用广度优先搜索,用入度的概念,每次只将入度为0的点压入队列,它指向的所有节点的入度都-1,-1后入度为0的点可以压入队列,如果能遍历整个图,则可以完成,不能遍历则不能完成。
代码:
struct GraphNode{
int label;
std::vector<GraphNode *> neighbors;
GraphNode(int x) : label(x) {};
};
class Solution {
public:
bool canFinish(int numCourses,
std::vector<std::pair<int, int> >& prerequisites) {
std::vector<GraphNode*> graph;
std::vector<int> degree;
for (int i = 0; i < numCourses; i++){
degree.push_back(0);
graph.push_back(new GraphNode(i));
}
for (int i = 0; i < prerequisites.size(); i++){
GraphNode *begin = graph[prerequisites[i].second];
GraphNode *end = graph[prerequisites[i].first];
begin->neighbors.push_back(end);
degree[prerequisites[i].first]++;
}
std::queue<GraphNode *> Q;
for (int i = 0; i < numCourses; i++){
if (degree[i] == 0){
Q.push(graph[i]);
}
}
while(!Q.empty()){
GraphNode *node = Q.front();
Q.pop();
for (int i = 0; i < node->neighbors.size(); i++){
degree[node->neighbors[i]->label]--;
if (degree[node->neighbors[i]->label] == 0){
Q.push(node->neighbors[i]);
}
}
}
for (int i = 0; i < graph.size(); i++){
delete graph[i];
}
for (int i = 0; i < degree.size(); i++){
if (degree[i]){
return false;
}
}
return true;
}
};














 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









