






直接上代码
import time
import requests
import json
import tqdm
aim_url="https://movie.douban.com/j/chart/top_list"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.82"
}
count=input("想要爬取前几部数据?")
mydict={
"type": "11",
"interval_id":"100:90",
"action":"",
"start": "1",
"limit": count
}
response=requests.get(url=aim_url,headers=headers,params=mydict)
print(time.time())
star_time=time.time()
data=response.json()
# print(data)
# with open("./豆瓣.txt","a",encoding="utf8") as fp :
# json.dump(data,fp=fp,ensure_ascii=False)
for k,item in enumerate(tqdm.tqdm(data, desc="Processing data")):
print(f"第{k+1}部:{item['title']}")
# time.sleep(0.1)
end_time = time.time()
print(f"爬取{count}部成功,用时{end_time-star_time}s")
# 创建了一个进度条对象,然后将其作为可迭代对象传递给enumerate函数。在每次迭代时,进度条会自动更新并显示当前的进度。
运行效果
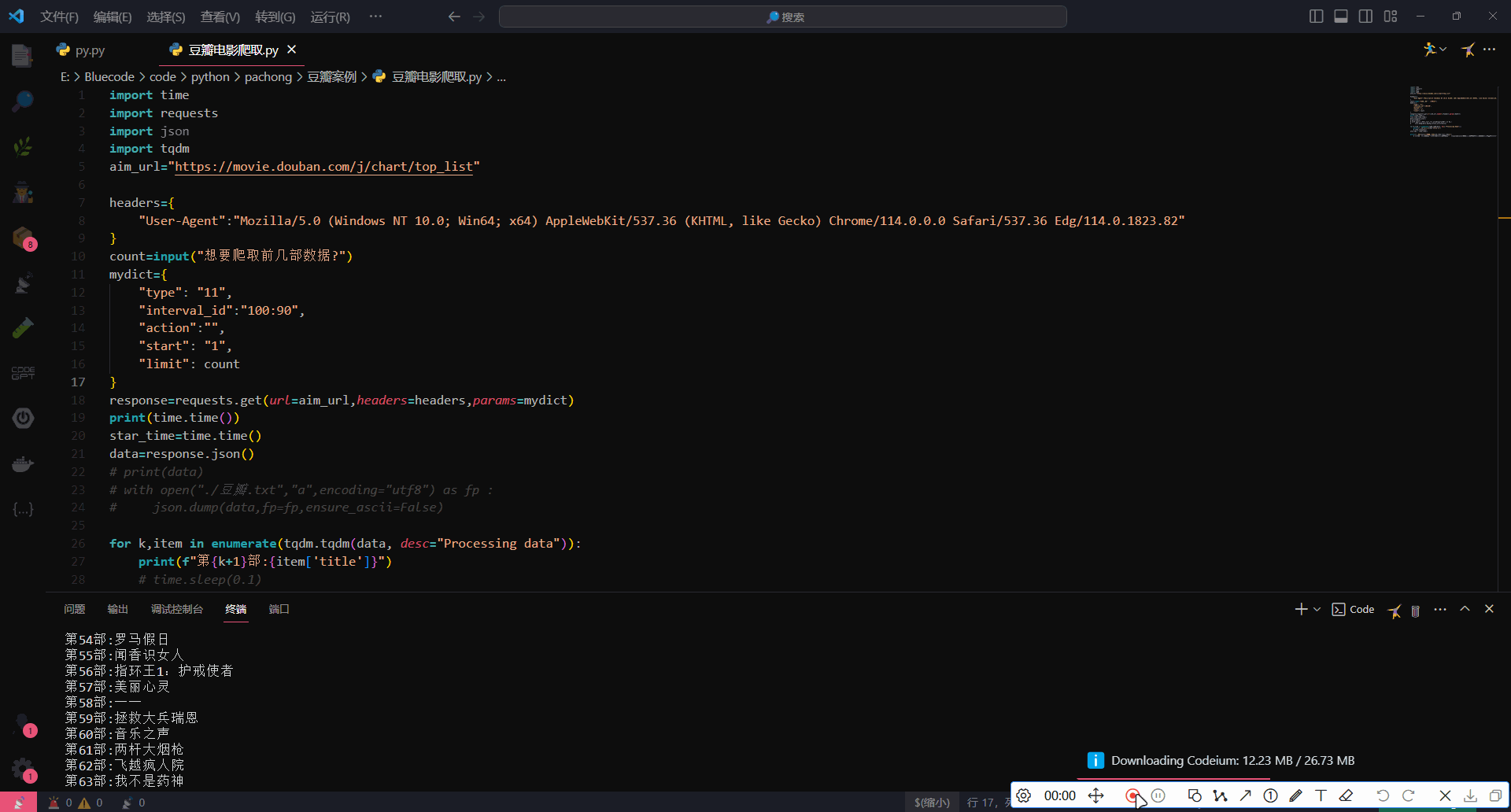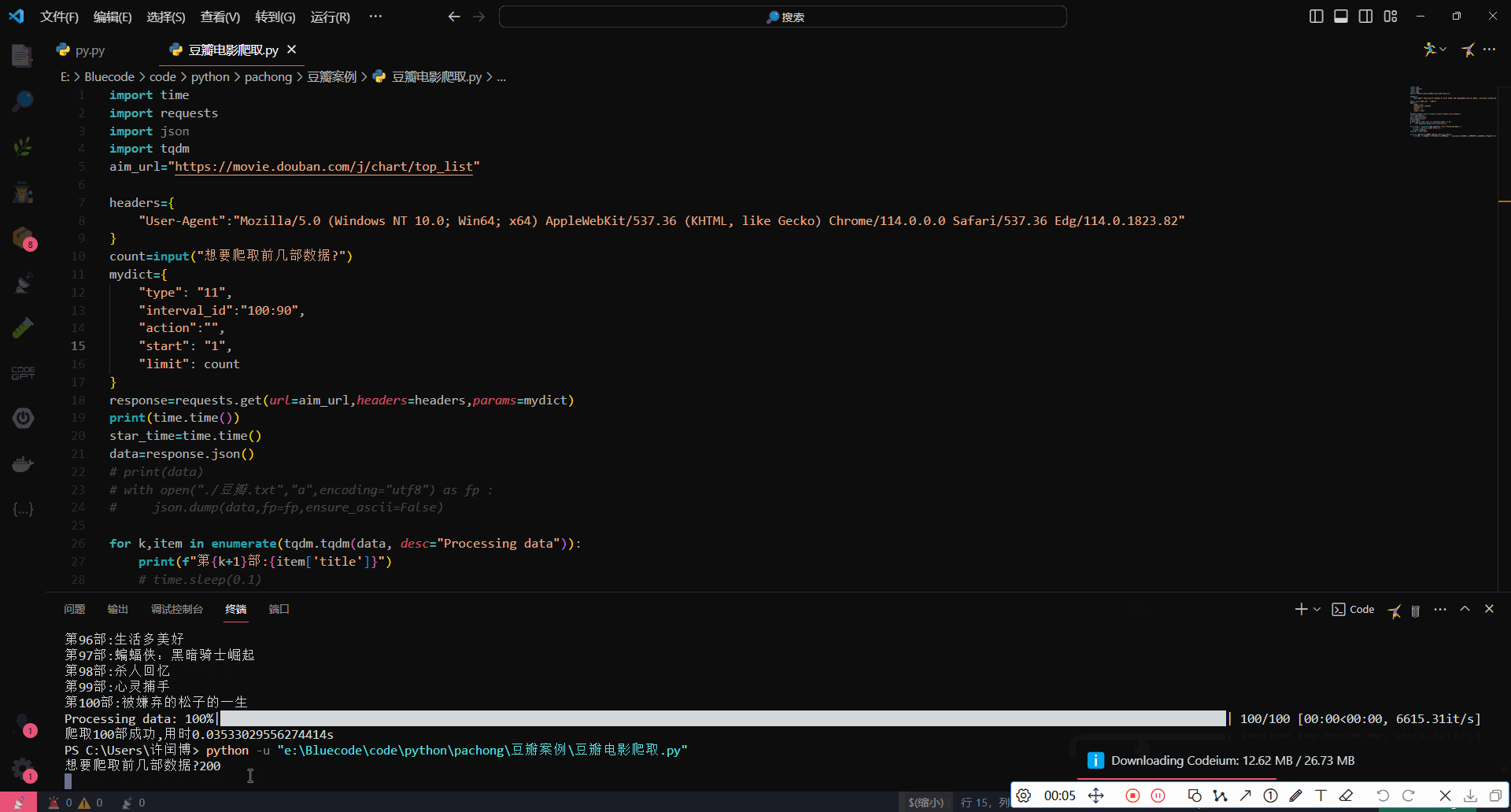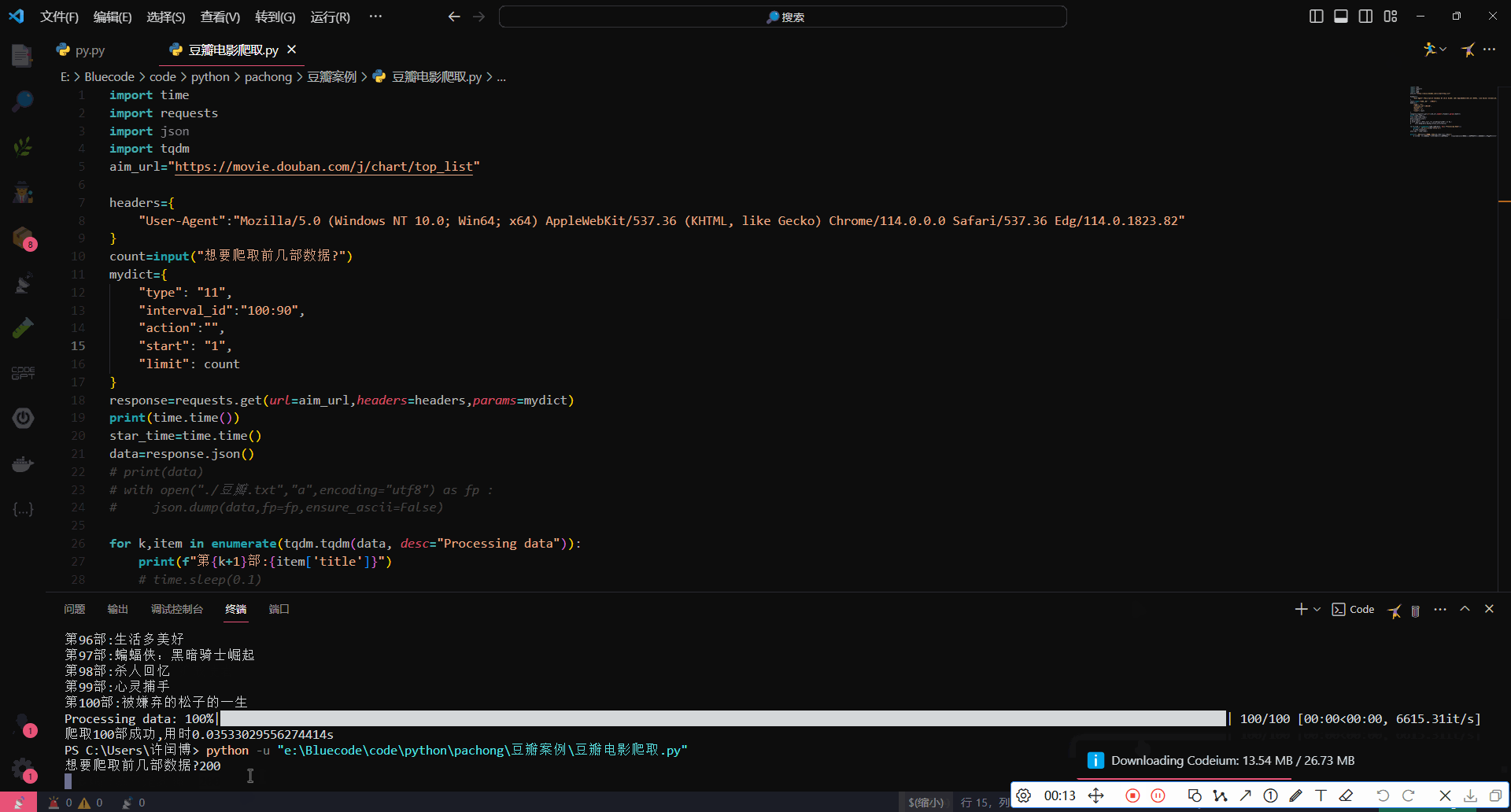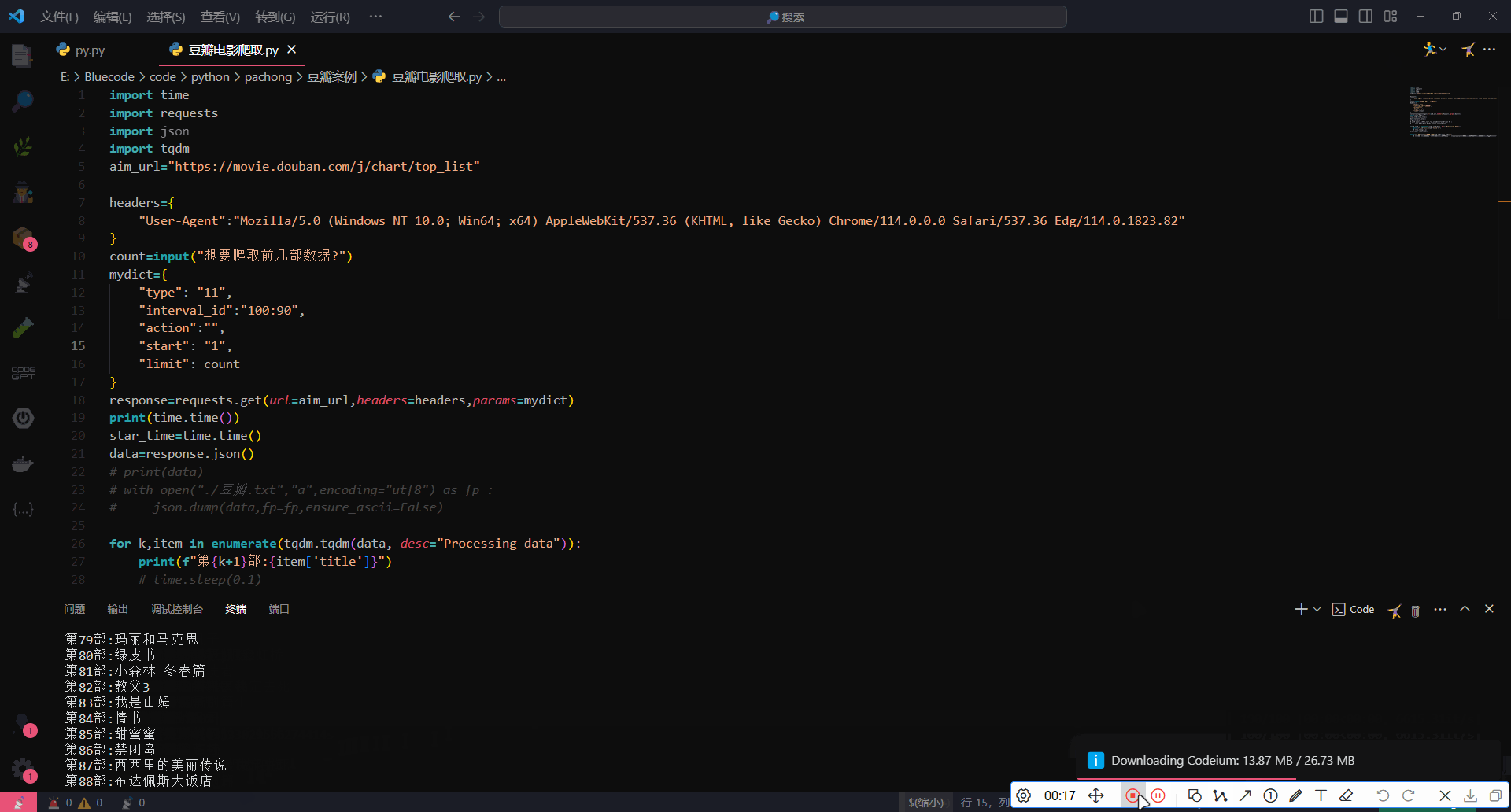














 2737
2737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









