







weka实现Apriori算法有两种方式:第一种是可视化方式,直接使用weka软件进行关联规则挖掘;第二种是调用其提供的Java API。
0. 数据准备
先将数据转化为csv或arff格式,若数据含有数值属性(numerical),则应先离散化,因为Apriori算法只能对标称属性(nominal)进行分析。样例数据如下:
@relation stu
@attribute Arbori_binari_de_cautare {TRUE, FALSE}
@attribute Arbori_optimali {TRUE, FALSE}
@attribute Arbori_echilibrati_in_inaltime {TRUE, FALSE}
@attribute Arbori_Splay {TRUE, FALSE}
@attribute Arbori_rosu_negru {TRUE, FALSE}
@attribute Arbori_2_3 {TRUE, FALSE}
@attribute Arbori_B {TRUE, FALSE}
@attribute Arbori_TRIE {TRUE, FALSE}
@attribute Sortare_topologica {TRUE, FALSE}
@attribute Algoritmul_Dijkstra {TRUE, FALSE}
@data
TRUE,TRUE,TRUE,TRUE,FALSE,FALSE,TRUE,TRUE,FALSE,FALSE
TRUE,TRUE,TRUE,TRUE,TRUE,TRUE,FALSE,TRUE,FALSE,FALSE
FALSE,TRUE,TRUE,TRUE,FALSE,FALSE,FALSE,TRUE,FALSE,TRUE
FALSE,TRUE,FALSE,FALSE,TRUE,FALSE,TRUE,TRUE,FALSE,TRUE
TRUE,TRUE,FALSE,TRUE,TRUE,FALSE,TRUE,TRUE,FALSE,TRUE
TRUE,FALSE,TRUE,FALSE,FALSE,TRUE,TRUE,TRUE,FALSE,FALSE
FALSE,TRUE,FALSE,TRUE,TRUE,FALSE,TRUE,TRUE,FALSE,TRUE
TRUE,FALSE,TRUE,TRUE,TRUE,FALSE,TRUE,TRUE,TRUE,FALSE
FALSE,TRUE,TRUE,TRUE,TRUE,FALSE,FALSE,TRUE,FALSE,FALSE
TRUE,FALSE,TRUE,FALSE,TRUE,TRUE,FALSE,TRUE,FALSE,TRUE
FALSE,FALSE,TRUE,FALSE,TRUE,FALSE,FALSE,TRUE,TRUE,TRUE
TRUE,FALSE,FALSE,TRUE,TRUE,TRUE,FALSE,TRUE,FALSE,TRUE
FALSE,TRUE,TRUE,FALSE,TRUE,TRUE,FALSE,TRUE,FALSE,TRUE
TRUE,TRUE,TRUE,FALSE,FALSE,TRUE,FALSE,TRUE,FALSE,FALSE
TRUE,TRUE,FALSE,FALSE,TRUE,TRUE,FALSE,TRUE,FALSE,FALSE
1. weka软件的方式
Explorer→Open File→Associate→Choose Apriori→Click Apriori to set→Start
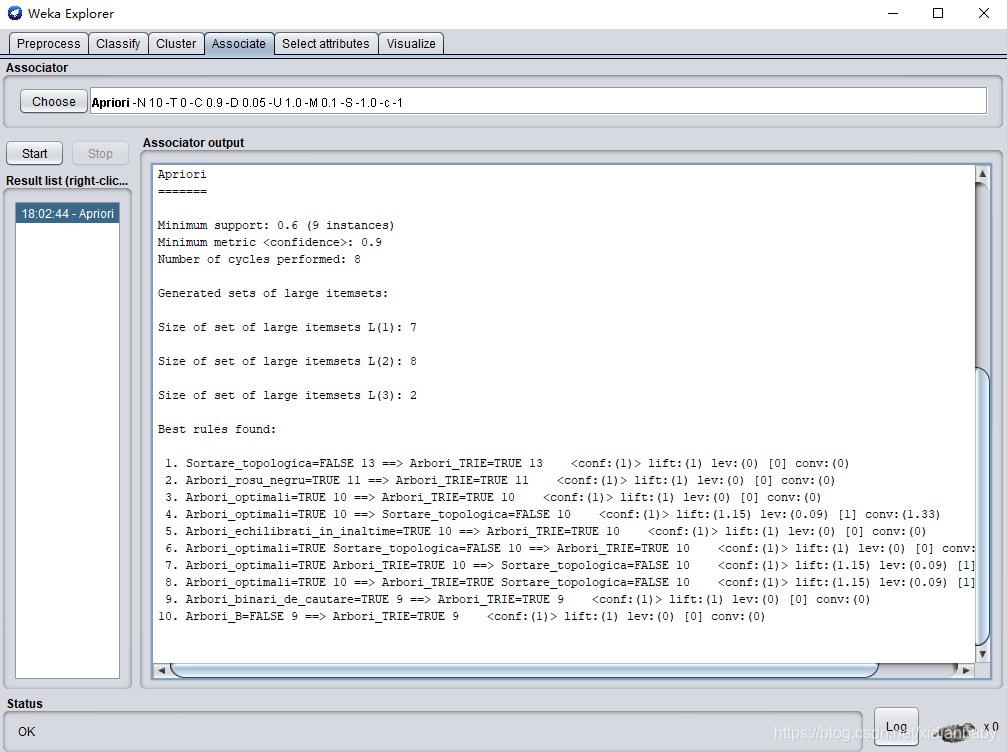
1.1 参数分析
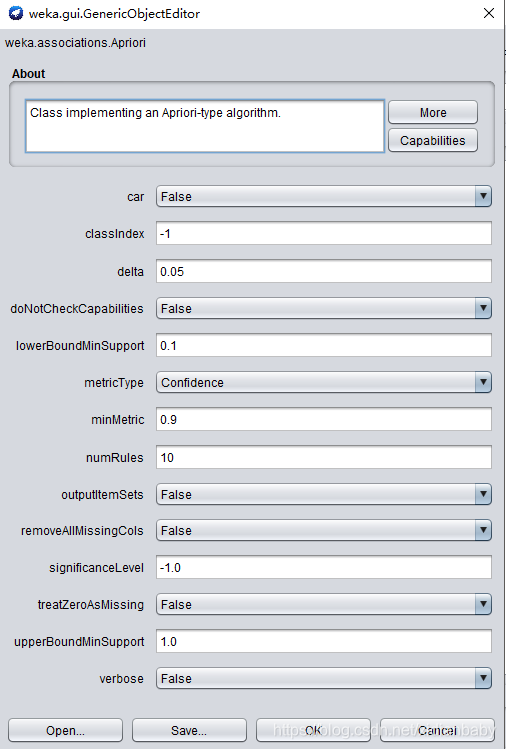
1-car : 若设置为true,则会挖掘类关联规则而不是全局关联规则;
2-classindex : 类属性索引,如果设置为-1,最后的属性被当做类属性;
3-delta : 以此数值为迭代递减单位,不断减小支持度直至达到最小支持度或产生了满足数量要求的规则;
4-lowerBoundMinSupport : 最小支持度下界;
5-metricType : 度量类型,设置对规则进行排序的度量依据,可以是置信度(类关联规则只能用置信度挖掘),提升度(lift),杠杆率(leverage),确信度(conviction);
5.1-Lift : P(A,B)/(P(A)P(B)),Lift=1时表示A和B独立,这个数越大(>1),越表明A和B存在于一个购物篮中不是偶然现象,有较强的关联度
5.2-Leverage : P(A,B)-P(A)P(B),Leverage=0时A和B独立,Leverage越大A和B的关系越密切
5.3-Conviction : P(A)P(!B)/P(A,!B),用来衡量A和B的独立性,这个值越大,A和B越关联
6-minMtric : 度量的最小值;
7-numRules : 要挖掘的规则数;
8-outputItemSets : 如果设置为真,会在结果中输出项集;
9-removeAllMissingCols : 移除全部为缺省值的列;
10-significanceLevel : 重要程度,重要性测试(仅用于置信度);
11-upperBoundMinSupport : 最小支持度上界,从这个值开始迭代减小最小支持度;
12- verbose : 如果设置为真,则算法会以冗余模式运行.
2. Java API方式
public void apriori(String path) {
Instances data = null;
try {
BufferedReader reader = new BufferedReader(new FileReader(path));
data = new Instances(reader);
reader.close();
data.setClassIndex(data.numAttributes() - 1);
} catch (IOException e) {
e.printStackTrace();
}
Apriori apriori = new Apriori();
double delta = 0.05;
double lowerBoundMinSupport = 0.1;
double upperBoundMinSupport = 1.0;
double minMetric = 0.5;
int numRules = 20;
String res;
apriori.setDelta(delta);
apriori.setLowerBoundMinSupport(lowerBoundMinSupport);
apriori.setUpperBoundMinSupport(upperBoundMinSupport);
apriori.setNumRules(numRules);
apriori.setMinMetric(minMetric);
try {
apriori.buildAssociations(data);
} catch (Exception e) {
e.printStackTrace();
}
res = apriori.toString();
System.out.println(res);
}
2.1 结果如下
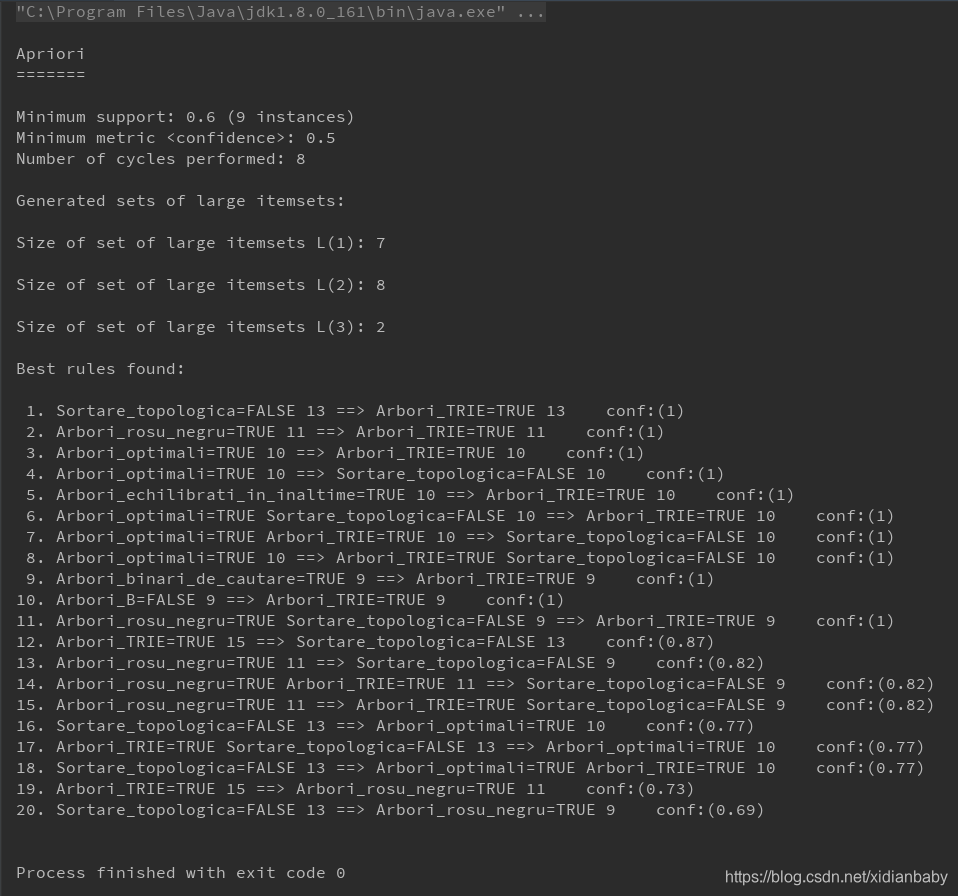

















 5457
5457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









