







 本文介绍了知识图谱的概念,起源于Google用于提升搜索引擎功能。知识获取涉及网络爬虫和半/非结构化文本抽取;知识构建涵盖实体融合、实体链接和属性/关系抽取;知识存储通常使用Spo三元组、RDF和OWL;知识表示和推理则包括一阶谓词逻辑和表示学习。知识图谱已应用于搜索引擎和语义交互,如Google的搜索结果和百度、搜狗的知识图谱。
本文介绍了知识图谱的概念,起源于Google用于提升搜索引擎功能。知识获取涉及网络爬虫和半/非结构化文本抽取;知识构建涵盖实体融合、实体链接和属性/关系抽取;知识存储通常使用Spo三元组、RDF和OWL;知识表示和推理则包括一阶谓词逻辑和表示学习。知识图谱已应用于搜索引擎和语义交互,如Google的搜索结果和百度、搜狗的知识图谱。
概念介绍
知识图谱的概念,由google于2012年率先提出,其初衷是用以增强自家的搜索引擎的功能和提高搜索结果质量,使得用户无需通过点击多个连接就可以获取结构化的搜索结果,并且提供一定的推理功能,但以目前各种chatbot的发展趋势来看,语义交互可能也会成为后期一个重要的搜索入口。我们可以看一个例子。
在google中输入:杭州景点,能够得到结构化的展现
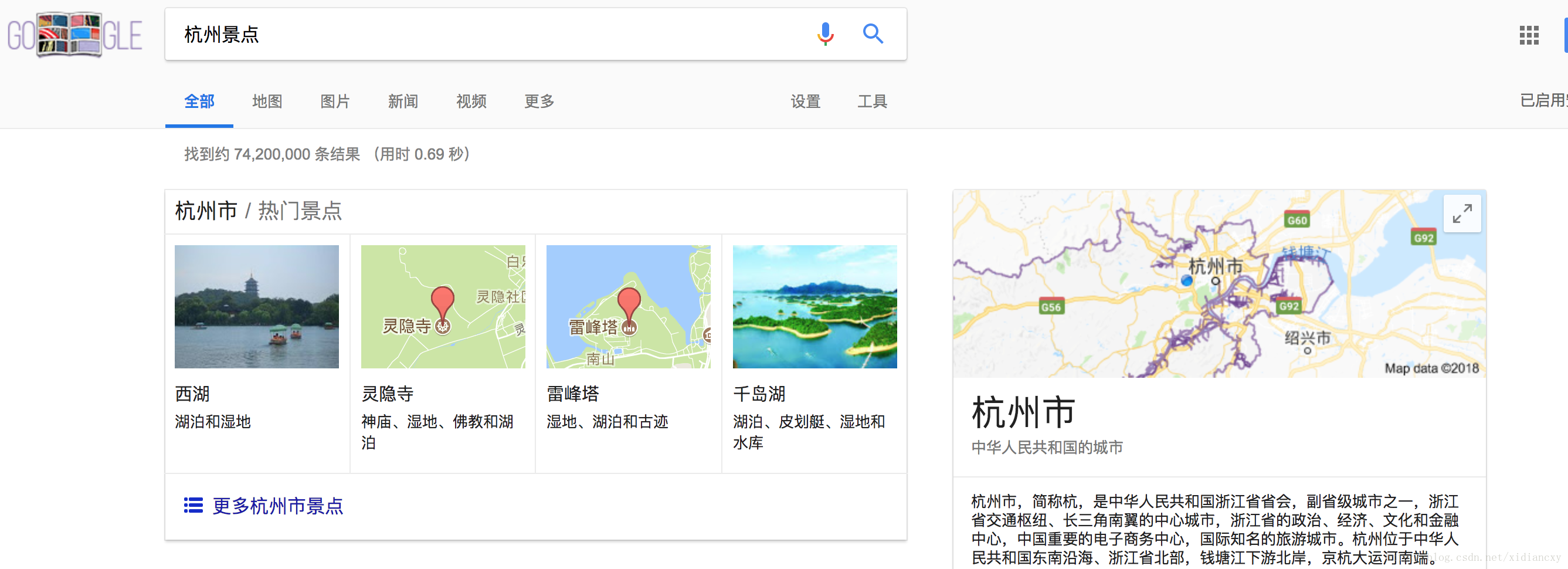
google知识图谱图谱的前身是雅虎的研究员在09年提出的概念网络,其数据来源除了自身的搜索日志,还有其收购的freebase(2014年关闭),wikipedia等。目前已经广泛应用在其搜索引擎,并不断融合多领域的知识(目前已知的除了基本的ner五大要素之外,还有健康图谱和购物图谱)。另外,微软也在做自己的概念图谱probase,目前提供了升级的测试功能。目前来看,国内真正可以称为拥有了图谱化数据的只有两家,百度知心和搜狗知立方。
关键点:
基于现有的知识图谱相关的技术点,可以把知识图谱相关的技术抽象为如下4点,包含了算法和部分工程所需,其中1-3主要是知识库构建的相关工作,可以看做是离线的部分,而4可以作为在线使用知识的方式。
1.知识获取
结构化信息:网络爬虫
通过爬虫,可以爬到网页的infobox信息,其中已经有结构化的部分信息,通过网页链接,也可以得到部分较准确的关系链接
以科比的infobox为例:

半/非结构化文本:bootstrap模板+keyword的方式抽取
一般来讲,通过我们爬取到的信息,还能够得到关于实体的摘要和描述性文本,以下面刘德华为例,我们在得到了一段描述性文本后,通常能够在其中发现大量的实体信息,将其作为keyword,我们能够通过统计得到大量关系和属性描述模板,以此使用bootstrap框架不断扩充数据集合。

2.知识构建
知识图谱的构建,作为离线数据的最重要的部分,其主要工作是从自然语言文本中抽取指定类型的实体、关系、时间等事实信息,形成结构化输出。从知识图谱构建的角度来说,我们可以把其分为三个方向:实体识别,实体链接和关系(属性)挖掘,下面说一下它们各自的主要工作是什么。
实体融合
因为我们的数据往往是多源异构的,同一个string刘德华,在百度百科上都有十个义项(也就是对应到了10个实体),怎么把各个数据源(虾米,优酷,百度,淘宝)的数据整合在一起,并且将其对应到合理的entity_id,就是一个实体融合的过程,那么对于通过知识获取已经结构化的实体信息,我们怎样把他们融合在一起呢
- 属性相似度计算
- 关键属性对比(特别是数字,日期类的属性,一般可以唯一确定)
- 关系链接对比(链接的关系实体名称等是否一致)
- 摘要的文本相似性 一般来说,摘要的文本jaccard也是一个比较方式
- 向量距离 如后文会说的RL,如果向量空间距离接近,也可能是同一个实体
实体链接
一般来说,我们处理的都是文本信息,当时实体链接需要坐到id到id的映射,怎样当前的文本指代中知道一个实体的关系是另个实体的id呢
- 网页linking关系
使用实体指代作为查询条件模拟搜索请求,可以得到该实体相关信息,然后采用双向校验的方式完成linking - PRA
利用现有的数据,用下面会说的PRA方式,找到执行度高的entity_id作为候选,然后进行关系的分类
属性/关系抽取
- 目前一般采用的是bootstrap的方式,首先用现有实体在文本中生成大量的伪标注,然后在当前标注区域附近提取大量文本特征,最终把关系挖掘变成一个二分类或者多分类问题。
- 还有一些方式是通过伪标注数据生成类似ner的标注样本,通过bi_lstm+crf的方式,对属性值标注为1,非属性值标注为0,扩大集合
- *
3.知识存储和查询
存储方式:spo三元组,rdf,owl
- spo
是最简单也是最灵活的一种存储方式,其把图谱的基本结构看做的三元组,所有的linking都通过这种kkv的形式完成。 - rdf
简单一点说,就是把spo表示成了一种资源描述符的方式,并且能方便灵活的通过网页存储,目前的图存储和查询,大部分都是采用了这种方式。
<?xml version="1.0"?>
<RDF>
<Description about="http://www.yahoo.com/">
<资源作者>Yahoo!公司</资源作者>
<资源名称>Yahoo!首页</资源名称>
</Description>
</RDF> - owl
可以看做r
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4334
4334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









