




一.CUDA线程模型概览
首先要搞清楚的就是线程网格(grid),线程块(block)和线程(thread)之间的关系.
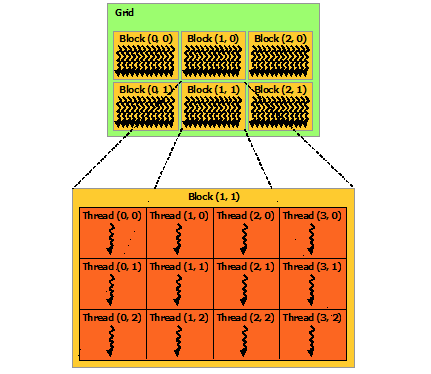
在前面的文章里面就已经看到了核函数kernel<<<xxxx>>>但是并不知道这个核函数启动的背后的一些原理,接下来就结合这幅图来说一说基础的东西.
图中有一个线程网格,网格中有2*3=6个线程块,而每一个线程块里面又有3*4=12个线程.这时候注意他们的索引.很容易算出这里一共有6*12=72个线程.这里说这个没有什么其他的意思,仅仅是想让你形象的体会一下….
CUDA内部定义了一些量来保存一个模型的各种索引:
gridDim.x:线程网络X维度上线程块的数量
gridDim.y-线程网络Y维度上线程块的数量
blockDim.x-一个线程块X维度上的线程数量
blockDim.y-一个线程块Y维度上的线程数量
blockIdx.x-线程网络X维度上的线程块索引
blockIdx.y-线程网络Y维度上的线程块索引
threadIdx.x-线程块X维度上的线程索引
threadIdx.y-线程块Y维度上的线程索引那么结合上面那幅图和给出的内置量.你可以自己也练习一下,得到:
gridDim.x=3
gridDim.y=2
blockDim.x=4
blockDim.y=3上面这个例子应该让你对于线程那些东西有了一个基本形象的认识,但是肯定还不知道具体环境中怎么使用.慢慢来…..
有了上面的一些基本的概念(不需要完全掌握),接下来就正式开始讲线程模型.
说到这里,我们回到核函数kernel<<<.....>>>,我们可以把核函数写为更加通用的方式,kernel<<<Dg,Db,Ns,S>>>:
Dg:定义整个grid的维度,类型Dim3,但是实际上目前显卡支持两个维度,所以,dim3<<Dg.x, Dg.y, 1>>>第z维度默认只能为1,而从最开始的图中可以看出grid的维度主要是决定block的数量的.而且,有最大数量限制.后面回来具体分析数量上面的限制.通俗一点,这个参数就是放的线程块的形状
Db:定义了每个block的维度,block的维度是决定thread数量和分布的.类型Dim3,比如512*512*64,这个可以定义3维尺寸,但是,这个地方是有讲究了,三个维度的积是有上限的,后面会细讲.通俗一点,这个参数就是放的线程的形状
Ns:是可选参数,设定最多能动态分配的共享内存大小,比如16k,单不需要是,这个值可以省略或写0。
S:也是可选参数,表示流号,默认为0。流这个概念以后讲。然后发现上面又出现了一个dim3类型又是什么鬼….你可以把dim3认为是一个结构体,是包含3个变量x,y,z的结构体,”一般”来说,初学者用的很频繁的是前两维x,y因为它定义了一个”矩阵”型的模型.就是上面那幅图中的一模一样.而且在基本的任务中用到二维已经很够了.这里并不是不推荐用更加高维的,而且在初学的时候简化问题.这个用熟了,高维的自然能够拓展上去.扯了这么多,到底怎么用?
我们还是以上面那幅图为例子,
首先定义一个blocks的dim3:dim3 blocks(2,3).发现什么规律没有?没有发现的话,继续,定义一个threads的dim3:dim3 threads(3,4).定义好这两个之后,直接丢到kernel中启动kernel<<<blocks,threads>>>.然后设备就会帮你启动像图里面那样类型的一个线程模型.
说到这里,你肯定对于基本的线程模型和核函数的意义有了一定的了解.也许了解不能够算是很深入也没有关系.这里本来就是一个很绕的地方.
然后接下来就是最后一个,是想告诉你还有一个东西叫做各种索引和他们的应用.但是要是这里直接列出来的话,基本上是不知道意义在哪里,所以我准备在后面根据具体的例子来描述各种索引的使用.然后最后再总结.
二.矢量求和运算
首先要声明,之前我们讲了很多很”理论”的东西,所以后面的内容就是通过非常经典的例子来讲怎么在之战中使用那些思想.
Ⅰ.概述
背景是是这样的.假设有两个长度相同的数组A和B,把两个数组的元素分别相加.放到数组RES中去.
假如你不多多线程,就用基本的c/c++,你的第一想法是不是用for循环?哈哈哈,但是for循环你想都想得到一次只能够操作一个元素.所以,矢量求和的问题是一个非常简单非常经典的并行问题.从这个问题说起,能够引出很多很多基本的概念.所以理解这个经典的框架是很有意义的.
在这里,就简单的把两个数组设为
a={0,1,2,3,4,5,6,7,8,9}
b={0,1,2,3,4,5,6,7,8,9}
我们应该得到的答案应该是
res={0,2,4,6,8,10,12,14,16,18}
Ⅱ.基于CPU的矢量求和
代码:
#include <iostream>
using namespace std;
const int MAX=10;
void add(int *a,int *b,int *res)
{
int tid=0;
while(tid<MAX)
{
res[tid]=a[tid]+b[tid];
tid+=1;
}
}
int main()
{
int a[MAX],b[MAX],res[MAX];
//随便赋一些值
for(int i=0;i<MAX;i++)
{
a[i]=i;
b[i]=i;
}
//调用函数
add(a,b,res);
//输出结果
cout<<"result:"<<endl;
for(int i=0;i<MAX;i++)
cout<<res[i]<<" ";
return 0;
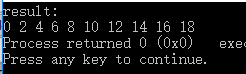
}运行结果:
解释:
代码很简单,就是设了三个数组,其中一个是用来接收答案的,还有两个是待相加的数组.然后就分别各自位置上面的相加.add()函数写成那个样子也是模拟多CPU的情况,为了对于接下来的GPU的并行有一个更好的了解….
Ⅲ.基于GPU的矢量求和
这里和之前一样,先直接给出代码,然后在分析体会其中的概念。
代码:
#include <cuda_runtime.h>
#include <iostream>
using namespace std;
const int MAX = 10;
//核函数创建
__global__ void add(int *a, int *b, int *res)
{
res[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}
int main()
{
int res[MAX], a[MAX], b[MAX];
//用户来存储设备内存地址
int *dev_res, *dev_a, *dev_b;
//随便赋值
for (int i = 0; i < MAX; i++)
a[i] = b[i] = i;
//显存上面分配空间
cudaMalloc((void **)&dev_res, MAX*sizeof(int));
cudaMalloc((void **)&dev_a, MAX*sizeof(int));
cudaMalloc((void **)&dev_b, MAX*sizeof(int));
//将a和b复制到GPU(注意标签时候HostToDevice)
cudaMemcpy(dev_a, a, MAX*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, MAX*sizeof(int), cudaMemcpyHostToDevice);
//调用核函数
add << <MAX, 1 >> > (dev_a, dev_b, dev_res);
//复制回主机内存
cudaMemcpy(res, dev_res, MAX*sizeof(int),cudaMemcpyDeviceToHost);
//输出
for (int i = 0; i < MAX; i++)
cout << res[i] << " ";
cout << endl;
//释放设备上面的内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_res);
return 0;
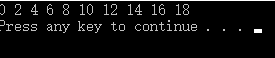
}运行结果:
分析:
其实这里关于前面开辟内存的一些前面已经讲到过了,等一下再分析.最重要的也是变化最大的首先讲.那就是核函数的意义和调用核函数时候的样式.
首先看核函数的定义方式.
//核函数创建
__global__ void add(int *a, int *b, int *res)
{
res[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}__global__什么的这些就不讲了,这些都是表明这是在设备上面运行的代码.函数的意义也是很明显,就是传递3个地址进去(地址肯定是位于GPU上面),这些地址是我们之前在GPU上面开辟的内存的地址.而且有两块地址我们已经赋值了.这些都很简单.
最不同的就是res[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];这句话.初学者会觉得很疑惑.但是你能够看到blockIdx.x这个东东是我们前面提到过的.表示一个线程块的索引.目前为止,你知道这些就够了.
接下来结合调用的语句:add << <MAX, 1 >> > (dev_a, dev_b, dev_res);这里其实之前也讲到过了第一个参数是启动的线程块的数量,第二个参数是每个线程块中线程的数量.也就是说,这里我们一次性”创建”了10(MAX)个线程块.我们这时候可以认为,我们创建了10*1个核函数的副本.不负责任的说,你可以认为有10个一模一样的函数在同时跑,之前一个函数要执行10次的操作,现在10个函数一下就跑完了.
在第一部分我们就知道blockIdx.x是起到了区分不同的线程块的作用,因为我们这里只用到了一维,所以索引只需要blockIdx.x就行了.是不是突然觉得很简单?而且对于每一个线程块(副本),线程块的blockIdx.x是系统弄好了的.你不用瞎操心.知道每个都有一个索引就行.比如”创建”4个线程块.那么索引就是从0到3..创建了2个线程块,索引就是从0到2.这个太简单了,看第一部分复习一下.
最终,把不同的线程块的索引作为一个数组的索引.自然就使得所有的10个加法一次性完成了.这就是他的本质思想了.
再回过头去看一下,是不是有体会?
那既然可以创建10个包含一个线程的线程块,那能不能创建一个线程块,其中包含10个线程?答案是可以的!
直接给代码:
#include <cuda_runtime.h>
#include <iostream>
using namespace std;
const int MAX = 10;
//核函数创建
__global__ void add(int *a, int *b, int *res)
{
res[threadIdx.x] = a[threadIdx.x] + b[threadIdx.x];
}
int main()
{
int res[MAX], a[MAX], b[MAX];
//用户来存储设备内存地址
int *dev_res, *dev_a, *dev_b;
//随便赋值
for (int i = 0; i < MAX; i++)
a[i] = b[i] = i;
//显存上面分配空间
cudaMalloc((void **)&dev_res, MAX*sizeof(int));
cudaMalloc((void **)&dev_a, MAX*sizeof(int));
cudaMalloc((void **)&dev_b, MAX*sizeof(int));
//将a和b复制到GPU(注意标签时候HostToDevice)
cudaMemcpy(dev_a, a, MAX*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, MAX*sizeof(int), cudaMemcpyHostToDevice);
//调用核函数
add << <1, MAX >> > (dev_a, dev_b, dev_res);
//复制回主机内存
cudaMemcpy(res, dev_res, MAX*sizeof(int),cudaMemcpyDeviceToHost);
//输出
for (int i = 0; i < MAX; i++)
cout << res[i] << " ";
cout << endl;
//释放设备上面的内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_res);
return 0;
}我就改了两处地方一个是核函数定义里面的,改为了res[threadIdx.x] = a[threadIdx.x] + b[threadIdx.x];把线程块的索引改为了线程的索引.思想其实是一样的.
另外一个就是调用核函数的时候add << <1, MAX >> > (dev_a, dev_b, dev_res);创建一个线程块,其中有10个线程.得到的结果也是一样的.就不是解释更多了,自己去体会.
讲到这里,这个例子就讲完了.你可以当做是在一维的情况下面对于索引方式的一个实战.可以启发以后碰到一维的并行怎么去设计.
未完待续…..


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









