










 本文介绍了一个基于k-最近邻(kNN)算法的图像分类实践案例。通过使用Jupyter Notebook进行训练与测试,演示了如何利用kNN算法进行CIFAR-10数据集的分类任务。文中详细解释了算法原理、实现细节及性能优化方法。
本文介绍了一个基于k-最近邻(kNN)算法的图像分类实践案例。通过使用Jupyter Notebook进行训练与测试,演示了如何利用kNN算法进行CIFAR-10数据集的分类任务。文中详细解释了算法原理、实现细节及性能优化方法。
自己写的,水平有限,有错和可以改进的地方,希望指出来
作业一详细内容地址:assignment1
jupyter notebook内容:
k-Nearest Neighbor (kNN) exercise
Complete and hand in this completed worksheet (including its outputs and any supporting code outside of the worksheet) with your assignment submission. For more details see the assignments page on the course website.
The kNN classifier consists of two stages:
- During training, the classifier takes the training data and simply remembers it
- During testing, kNN classifies every test image by comparing to all training images and transfering the labels of the k most similar training examples
- The value of k is cross-validated
In this exercise you will implement these steps and understand the basic Image Classification pipeline, cross-validation, and gain proficiency in writing efficient, vectorized code.
# Run some setup code for this notebook.
import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
import os
print os.getcwd()
# This is a bit of magic to make matplotlib figures appear inline in the notebook
# rather than in a new window.
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# Some more magic so that the notebook will reload external python modules;
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2# Load the raw CIFAR-10 data.
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# As a sanity check, we print out the size of the training and test data.
print 'Training data shape: ', X_train.shape
print 'Training labels shape: ', y_train.shape
print 'Test data shape: ', X_test.shape
print 'Test labels shape: ', y_test.shapeTraining data shape: (50000, 32, 32, 3)
Training labels shape: (50000,)
Test data shape: (10000, 32, 32, 3)
Test labels shape: (10000,)
# Visualize some examples from the dataset.
# We show a few examples of training images from each class.
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
samples_per_class = 7
for y, cls in enumerate(classes):
idxs = np.flatnonzero(y_train == y)
idxs = np.random.choice(idxs, samples_per_class, replace=False)
for i, idx in enumerate(idxs):
plt_idx = i * num_classes + y + 1
plt.subplot(samples_per_class, num_classes, plt_idx)
plt.imshow(X_train[idx].astype('uint8'))
plt.axis('off')
if i == 0:
plt.title(cls)
plt.show()
# Subsample the data for more efficient code execution in this exercise
num_training = 5000
mask = range(num_training)
X_train = X_train[mask]
y_train = y_train[mask]
num_test = 500
mask = range(num_test)
X_test = X_test[mask]
y_test = y_test[mask]# Reshape the image data into rows
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
print X_train.shape, X_test.shape(5000, 3072) (500, 3072)
from cs231n.classifiers import KNearestNeighbor
# Create a kNN classifier instance.
# Remember that training a kNN classifier is a noop:
# the Classifier simply remembers the data and does no further processing
classifier = KNearestNeighbor()
classifier.train(X_train, y_train)We would now like to classify the test data with the kNN classifier. Recall that we can break down this process into two steps:
- First we must compute the distances between all test examples and all train examples.
- Given these distances, for each test example we find the k nearest examples and have them vote for the label
Lets begin with computing the distance matrix between all training and test examples. For example, if there are Ntr training examples and Nte test examples, this stage should result in a Nte x Ntr matrix where each element (i,j) is the distance between the i-th test and j-th train example.
First, open cs231n/classifiers/k_nearest_neighbor.py and implement the function compute_distances_two_loops that uses a (very inefficient) double loop over all pairs of (test, train) examples and computes the distance matrix one element at a time.
# Open cs231n/classifiers/k_nearest_neighbor.py and implement
# compute_distances_two_loops.
# Test your implementation:
dists = classifier.compute_distances_two_loops(X_test)
print dists.shape(500, 5000)
# We can visualize the distance matrix: each row is a single test example and
# its distances to training examples
plt.imshow(dists, interpolation='none')
plt.show()
Inline Question #1: Notice the structured patterns in the distance matrix, where some rows or columns are visible brighter. (Note that with the default color scheme black indicates low distances while white indicates high distances.)
- What in the data is the cause behind the distinctly bright rows?
- What causes the columns?
Your Answer: maybe they are noise, so they are distinctly different with training dataset/test dataset, or sum objects that are not in training dataset
# Now implement the function predict_labels and run the code below:
# We use k = 1 (which is Nearest Neighbor).
y_test_pred = classifier.predict_labels(dists, k=1)
# Compute and print the fraction of correctly predicted examples
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print 'Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy)Got 137 / 500 correct => accuracy: 0.274000
You should expect to see approximately 27% accuracy. Now lets try out a larger k, say k = 5:
y_test_pred = classifier.predict_labels(dists, k=5)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print 'Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy)Got 142 / 500 correct => accuracy: 0.284000
You should expect to see a slightly better performance than with k = 1.
# Now lets speed up distance matrix computation by using partial vectorization
# with one loop. Implement the function compute_distances_one_loop and run the
# code below:
dists_one = classifier.compute_distances_one_loop(X_test)
# To ensure that our vectorized implementation is correct, we make sure that it
# agrees with the naive implementation. There are many ways to decide whether
# two matrices are similar; one of the simplest is the Frobenius norm. In case
# you haven't seen it before, the Frobenius norm of two matrices is the square
# root of the squared sum of differences of all elements; in other words, reshape
# the matrices into vectors and compute the Euclidean distance between them.
difference = np.linalg.norm(dists - dists_one, ord='fro')
print 'Difference was: %f' % (difference, )
if difference < 0.001:
print 'Good! The distance matrices are the same'
else:
print 'Uh-oh! The distance matrices are different'Difference was: 0.000000
Good! The distance matrices are the same
# Now implement the fully vectorized version inside compute_distances_no_loops
# and run the code
dists_two = classifier.compute_distances_no_loops(X_test)
# check that the distance matrix agrees with the one we computed before:
difference = np.linalg.norm(dists - dists_two, ord='fro')
print 'Difference was: %f' % (difference, )
if difference < 0.001:
print 'Good! The distance matrices are the same'
else:
print 'Uh-oh! The distance matrices are different'Difference was: 0.000000
Good! The distance matrices are the same
# Let's compare how fast the implementations are
def time_function(f, *args):
"""
Call a function f with args and return the time (in seconds) that it took to execute.
"""
import time
tic = time.time()
f(*args)
toc = time.time()
return toc - tic
two_loop_time = time_function(classifier.compute_distances_two_loops, X_test)
print 'Two loop version took %f seconds' % two_loop_time
one_loop_time = time_function(classifier.compute_distances_one_loop, X_test)
print 'One loop version took %f seconds' % one_loop_time
no_loop_time = time_function(classifier.compute_distances_no_loops, X_test)
print 'No loop version took %f seconds' % no_loop_time
# you should see significantly faster performance with the fully vectorized implementationTwo loop version took 54.732456 seconds
One loop version took 42.280427 seconds
No loop version took 0.444748 seconds
Cross-validation
We have implemented the k-Nearest Neighbor classifier but we set the value k = 5 arbitrarily. We will now determine the best value of this hyperparameter with cross-validation.
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
################################################################################
# TODO: #
# Split up the training data into folds. After splitting, X_train_folds and #
# y_train_folds should each be lists of length num_folds, where #
# y_train_folds[i] is the label vector for the points in X_train_folds[i]. #
# Hint: Look up the numpy array_split function. #
################################################################################
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
################################################################################
# END OF YOUR CODE #
################################################################################
# A dictionary holding the accuracies for different values of k that we find
# when running cross-validation. After running cross-validation,
# k_to_accuracies[k] should be a list of length num_folds giving the different
# accuracy values that we found when using that value of k.
k_to_accuracies = {}
################################################################################
# TODO: #
# Perform k-fold cross validation to find the best value of k. For each #
# possible value of k, run the k-nearest-neighbor algorithm num_folds times, #
# where in each case you use all but one of the folds as training data and the #
# last fold as a validation set. Store the accuracies for all fold and all #
# values of k in the k_to_accuracies dictionary. #
################################################################################
for k_c in k_choices:
k_to_accuracies[k_c]=[]
for i in xrange(num_folds):
X_cv_train = []
y_cv_train = []
X_cv_test = X_train_folds[i]
y_cv_test = y_train_folds[i]
num_cv_test = y_cv_test.shape[0]
for j in xrange(num_folds-1):
X_cv_train.append(X_train_folds[(i+1+j)%num_folds])
y_cv_train.append(y_train_folds[(i+1+j)%num_folds])
X_cv_train = np.concatenate(tuple(X_cv_train))
y_cv_train = np.concatenate(tuple(y_cv_train))
classifier = KNearestNeighbor()
classifier.train(X_cv_train, y_cv_train)
dists = classifier.compute_distances_no_loops(X_cv_test)
y_test_pred = classifier.predict_labels(dists, k=k_c)
num_correct = np.sum(y_test_pred == y_cv_test)
accuracy = float(num_correct) / num_cv_test
k_to_accuracies[k_c].append(accuracy)
################################################################################
# END OF YOUR CODE #
################################################################################
# Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print 'k = %d, accuracy = %f' % (k, accuracy)k = 1, accuracy = 0.263000
k = 1, accuracy = 0.257000
k = 1, accuracy = 0.264000
k = 1, accuracy = 0.278000
k = 1, accuracy = 0.266000
k = 3, accuracy = 0.241000
k = 3, accuracy = 0.249000
k = 3, accuracy = 0.243000
k = 3, accuracy = 0.273000
k = 3, accuracy = 0.264000
k = 5, accuracy = 0.258000
k = 5, accuracy = 0.273000
k = 5, accuracy = 0.281000
k = 5, accuracy = 0.290000
k = 5, accuracy = 0.272000
k = 8, accuracy = 0.263000
k = 8, accuracy = 0.288000
k = 8, accuracy = 0.278000
k = 8, accuracy = 0.285000
k = 8, accuracy = 0.277000
k = 10, accuracy = 0.265000
k = 10, accuracy = 0.296000
k = 10, accuracy = 0.278000
k = 10, accuracy = 0.284000
k = 10, accuracy = 0.286000
k = 12, accuracy = 0.260000
k = 12, accuracy = 0.294000
k = 12, accuracy = 0.281000
k = 12, accuracy = 0.282000
k = 12, accuracy = 0.281000
k = 15, accuracy = 0.255000
k = 15, accuracy = 0.290000
k = 15, accuracy = 0.281000
k = 15, accuracy = 0.281000
k = 15, accuracy = 0.276000
k = 20, accuracy = 0.270000
k = 20, accuracy = 0.281000
k = 20, accuracy = 0.280000
k = 20, accuracy = 0.282000
k = 20, accuracy = 0.284000
k = 50, accuracy = 0.271000
k = 50, accuracy = 0.288000
k = 50, accuracy = 0.278000
k = 50, accuracy = 0.269000
k = 50, accuracy = 0.266000
k = 100, accuracy = 0.256000
k = 100, accuracy = 0.270000
k = 100, accuracy = 0.263000
k = 100, accuracy = 0.256000
k = 100, accuracy = 0.263000
# plot the raw observations
for k in k_choices:
accuracies = k_to_accuracies[k]
plt.scatter([k] * len(accuracies), accuracies)
# plot the trend line with error bars that correspond to standard deviation
accuracies_mean = np.array([np.mean(v) for k,v in sorted(k_to_accuracies.items())])
accuracies_std = np.array([np.std(v) for k,v in sorted(k_to_accuracies.items())])
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()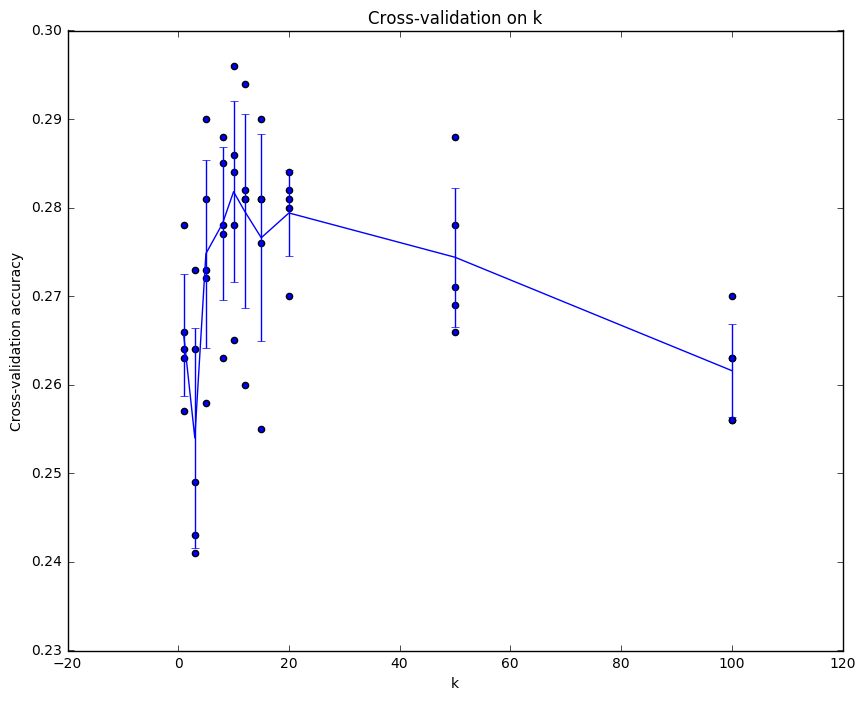
# Based on the cross-validation results above, choose the best value for k,
# retrain the classifier using all the training data, and test it on the test
# data. You should be able to get above 28% accuracy on the test data.
best_k = 7
classifier = KNearestNeighbor()
classifier.train(X_train, y_train)
y_test_pred = classifier.predict(X_test, k=best_k)
# Compute and display the accuracy
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print 'Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy)Got 141 / 500 correct => accuracy: 0.282000
k_nearest_neighbor.py内容:
import numpy as np
class KNearestNeighbor(object):
""" a kNN classifier with L2 distance """
def __init__(self):
pass
def train(self, X, y):
"""
Train the classifier. For k-nearest neighbors this is just
memorizing the training data.
Inputs:
- X: A numpy array of shape (num_train, D) containing the training data
consisting of num_train samples each of dimension D.
- y: A numpy array of shape (N,) containing the training labels, where
y[i] is the label for X[i].
"""
self.X_train = X
self.y_train = y
def predict(self, X, k=1, num_loops=0):
"""
Predict labels for test data using this classifier.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data consisting
of num_test samples each of dimension D.
- k: The number of nearest neighbors that vote for the predicted labels.
- num_loops: Determines which implementation to use to compute distances
between training points and testing points.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
if num_loops == 0:
dists = self.compute_distances_no_loops(X)
elif num_loops == 1:
dists = self.compute_distances_one_loop(X)
elif num_loops == 2:
dists = self.compute_distances_two_loops(X)
else:
raise ValueError('Invalid value %d for num_loops' % num_loops)
return self.predict_labels(dists, k=k)
def compute_distances_two_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a nested loop over both the training data and the
test data.
Inputs:
- X: A numpy array of shape (num_test, D) containing test data.
Returns:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
is the Euclidean distance between the ith test point and the jth training
point.
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in xrange(num_test):
for j in xrange(num_train):
#####################################################################
# TODO: #
# Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension. #
#####################################################################
diff = X[i] - self.X_train[j]
diff_sqr = diff**2
dists[i,j] = np.sum(diff_sqr)
#####################################################################
# END OF YOUR CODE #
#####################################################################
return dists
def compute_distances_one_loop(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a single loop over the test data.
Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in xrange(num_test):
#######################################################################
# TODO: #
# Compute the l2 distance between the ith test point and all training #
# points, and store the result in dists[i, :]. #
#######################################################################
diff = self.X_train - X[i]
diff_sqr = np.square(diff)
dists[i] = np.sum(diff_sqr, axis=1)
#######################################################################
# END OF YOUR CODE #
#######################################################################
return dists
def compute_distances_no_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using no explicit loops.
Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
#########################################################################
# TODO: #
# Compute the l2 distance between all test points and all training #
# points without using any explicit loops, and store the result in #
# dists. #
# #
# You should implement this function using only basic array operations; #
# in particular you should not use functions from scipy. #
# #
# HINT: Try to formulate the l2 distance using matrix multiplication #
# and two broadcast sums. #
#########################################################################
X_test_squ_array = np.sum(np.square(X), axis = 1)
X_test_squ = np.tile(X_test_squ_array.reshape(num_test,1), (1,num_train))
#print X_test_squ.shape
X_train_squ_array = np.sum(np.square(self.X_train), axis = 1)
X_train_squ = np.tile(X_train_squ_array, (num_test,1))
#print X_train_squ.shape
x_te_tr = np.dot(X, self.X_train.T)
#print x_te_tr.shape
dists = X_test_squ + X_train_squ_array - 2*x_te_tr
#########################################################################
# END OF YOUR CODE #
#########################################################################
return dists
def predict_labels(self, dists, k=1):
"""
Given a matrix of distances between test points and training points,
predict a label for each test point.
Inputs:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
gives the distance betwen the ith test point and the jth training point.
Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in xrange(num_test):
# A list of length k storing the labels of the k nearest neighbors to
# the ith test point.
closest_y = []
#########################################################################
# TODO: #
# Use the distance matrix to find the k nearest neighbors of the ith #
# testing point, and use self.y_train to find the labels of these #
# neighbors. Store these labels in closest_y. #
# Hint: Look up the function numpy.argsort. #
#########################################################################
argsrotDist = np.argsort(dists[i])
closest_y = self.y_train[argsrotDist][:k]
#########################################################################
# TODO: #
# Now that you have found the labels of the k nearest neighbors, you #
# need to find the most common label in the list closest_y of labels. #
# Store this label in y_pred[i]. Break ties by choosing the smaller #
# label. #
#########################################################################
y_vote = {}
for j in xrange(k):
if closest_y[j] in y_vote:
y_vote[closest_y[j]] += 1
else:
y_vote[closest_y[j]] = 0
y_pred[i] = max(y_vote.items(), key=lambda x: x[1])[0]
#########################################################################
# END OF YOUR CODE #
#########################################################################
return y_pred
2

















 3892
3892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









