








背景
本文主要介绍内存性能优化相关知识,以及遇到相关问题的分析思路及优化思路。
内存问题,一般体现在两个方面。
-
内存泄漏。
-
性能不足。
内存泄露,我们可以通过观察内存剩余量的变化,很容易判断是否发生了内存泄漏。
内存性能不足,从而导致应用程序运行效率降低,或者阻塞,这一点是我们不容易分辨的。经过《CPU性能优化——“瑞士军刀“-CSDN博客》,《I/O性能优化——这一篇就足够啦-CSDN博客》章节的介绍。内存一旦出现性能瓶颈,一般也引起CPU或I/O的负载增加。比如缓存不足时,可能会导致磁盘I/O的读写增加,从而I/O 读写频率增加,CPU 的iwait 时间增加。对于这种场景,我们该一步步分析呢?
概念介绍
首先需要熟悉以下概念,只有了解linux 对内存的定义,以及内部的实现原理,我们才能从调试数据背后发现其原因,针对“下药”。
为什么引入虚拟内存
虚拟内存相对应的则是物理内存。这两个概念也是我们老生常谈的话题。但是我们真正了解过,虚拟内存的意义和作用吗?
回答这个问题前,我们不妨做这样的一个假设,如果没有虚拟内存,程序员操作的都是物理内存,会带来怎样的问题?【在编译原理中,曾介绍过,早期的计算机是没有虚拟内存概念的】
从我的角度而言,我觉得会产生以下两点问题:
-
进程运行时,会尽可能的将程序所用到的资源全部加载到内存中。然而内存资源是稀缺的。当越来越多的进程需要内存时,某些进程会因为得不到内存而无法运行。
-
内存容易被破坏,影响其它进程的运行。无形给程序员编码增加了难度,让编程不再这么简单。
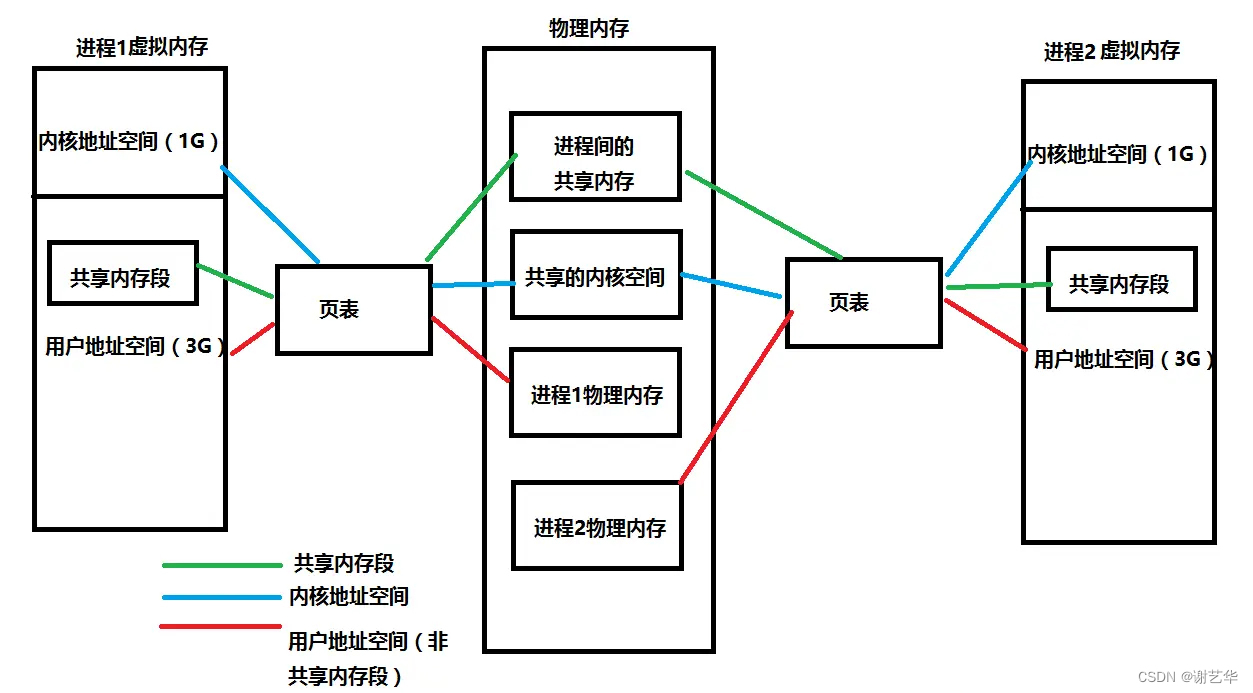
我们知道虚拟内存是物理内存和进程(程序员)之间的中间层。它为我们隐藏了物理内存的概念,从而提供三大能力。
-
高效使用内存。VM将主存看成是存储在磁盘上的地址空间的高速缓存,主存中保存热数据,根据需要在磁盘和主存之间传输数据。
-
简化内存管理。VM为每一个进程提供了一致的4G空间,从而简化了链接,加载,内存共享等过程。比如,程序的起始运行地址为0x080480000(0x080400000)。
-
内存保护。保护每个进程的地址空间不被其它进程破坏。每个进程所关联的物理内存由内核管理。若越界访问,会产生异常,不影响其它程序。
页表的工作原理:
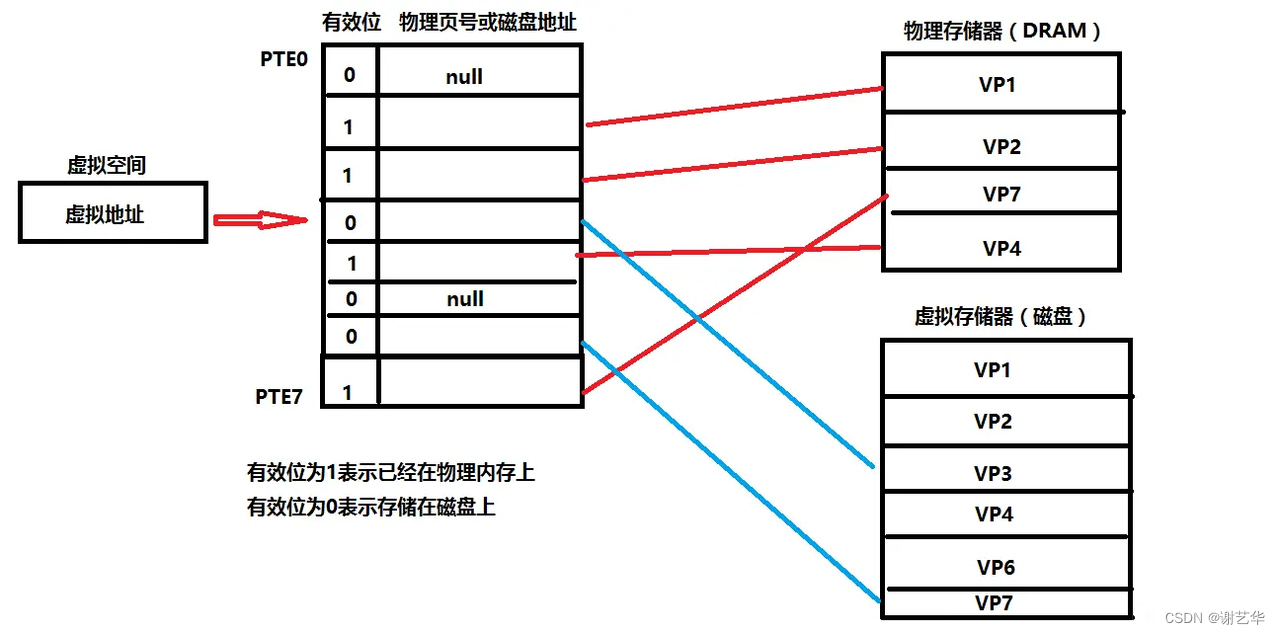
-
cpu想访问虚拟地址所在的虚拟页(VP3),根据页表,找出页表中对应的页表项,判断有效位。
-
若有效位为1,则DRMA缓存命中,根据物理页号,找到物理页当中的内容,返回。
-
若有效位为0,则发生缺页异常,调用内核缺页异常处理程序。内核通过页面置换算法选择一个页面作为被覆盖的页面,将该页的内容刷新到磁盘空间当中。然后把VP3映射的磁盘文件内容缓存到该物理地址对应的页上面(这个过程会涉及到磁盘的读写操作,因此程序运行过程中,若发生多次缺页异常,则会大大影响应用层序运行效率)。然后将页表项中的有效位变成1,第二部分存储了对应的物理内存也的地址。
-
缺页异常处理完毕后,返回中断前的指令,重新执行,此时缓存命中,执行1。
-
将找到的内容映射到高速缓存当中,CPU从高速缓存中获取该值,结束。
综上所知:
当进程创建时,内核会为进程分配4G的虚拟内存,当进程还没有开始运行时,这只是一个内存布局。实际上不会立刻把虚拟内存中的代码段,数据段拷贝到物理内存中。只是建立好虚拟内存和磁盘文件(elf文件格式)之间的映射关系(存储器映射)。这个时候.data,.text还在磁盘上。运行时发生缺页异常。于是将磁盘上的数据拷贝到物理内存中。这便是虚拟内存提供的魅力。
内存碎片
内存碎片的概念常被人提及,但是很少会有确切的感受。我们在申请内存时,一般都是通过C标准库malloc接口实现,但它底层实现的系统调用,估计很多人没有在意过,其原理则是造成内存碎片的原因。
1. malloc 在申请小于128k的内存时,使用brk系统调用分配内存,将_edata往高地址推。
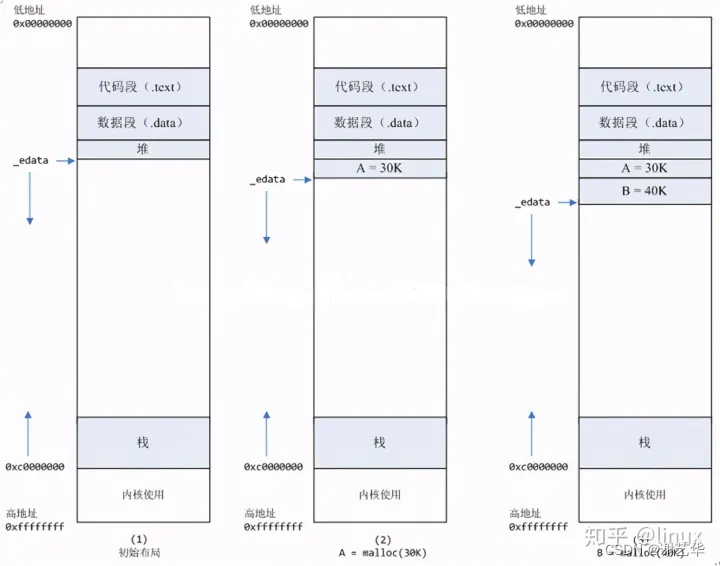
2. malloc 在申请大于128K的内存时,使用mmap系统调用分配内存,在堆和栈之间找一块空闲内存分配。
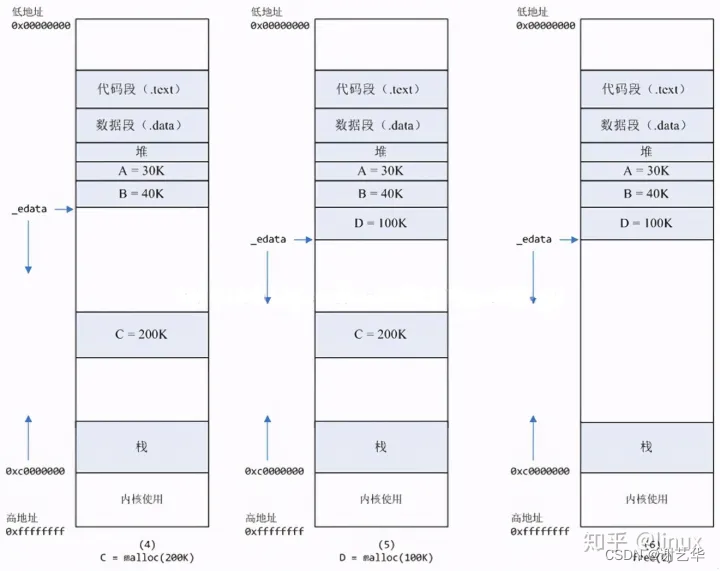
这两种系统调用发生之后,并没有真正分配内存。只有在首次访问时才分配,也就是通过缺页异常进入内核,再由内核分配内存。
区别:使用brk()申请的内存,这些内存在释放后不会立刻归还系统,而是被缓存起来(当系统资源紧张时,也可以回收);而mmap方式分配的内存,会在释放时立刻归还系统。请注意,这里的内存释放包括物理内存和虚拟内存。如下图:
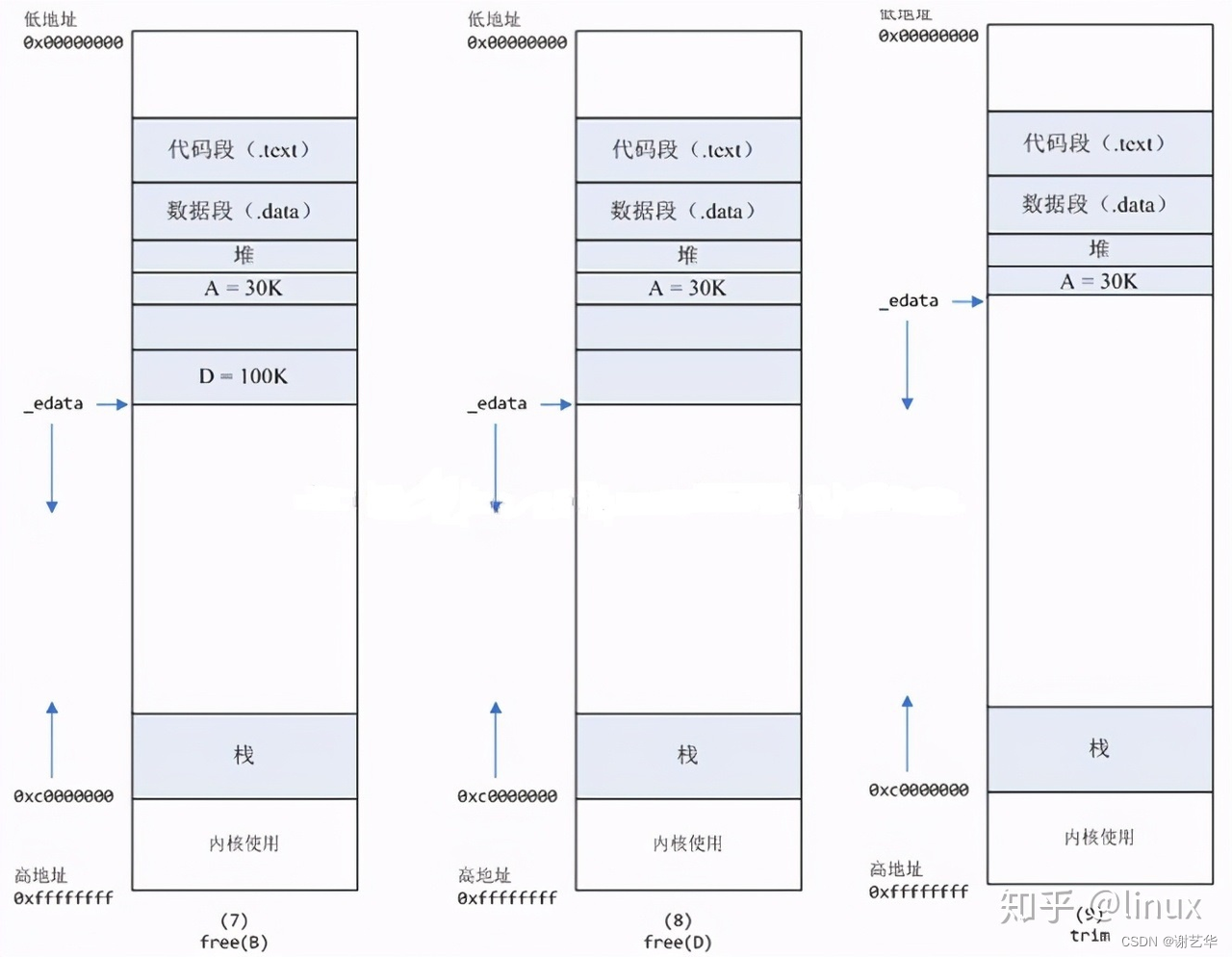
优缺点:
-
brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
-
而 mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常。
由上可知:
内存碎片的出现是因为应用程序频繁的申请,释放大小不一的小内存导致的。内存碎片问题可能不会立即导致明显的性能下降,但长期积累可能会对系统的稳定性和性能产生不良影响。
缺页异常也会导致程序性能降低。
内存的回收机制
系统不会任由程序将内存消耗殆尽。在发生内存紧张时,系统会通过一系列机制来回收内存。
-
回收内存。
-
杀死进程。
第一种回收内存的方式有两类:
1. 回收缓存和缓冲区。在《I/O性能优化》章节中,讲述了虚拟文件系统为了增加数据的读写速度,会将磁盘中的数据在内存中进行缓存。也就是我们buffer/cahce参数。操作系统可以将该部分内存回收,从而提高剩余可用内存。
yihua@ubuntu:~$ free -h
total used free shared buff/cache available
Mem: 3.8G 1.3G 619M 31M 1.9G 2.2G
Swap: 2.0G 111M 1.9G2. 交换分区。将不常访问的内存,保存至磁盘中。等下次访问时,再将这部分数据,从磁盘拷贝到内存中。
第二种是杀死进程的方式,就是内核的一种保护机制(OOM),它监控简称的内存使用情况,并且使用oom_score 为每个进程的内存使用情况进行评分。
-
一个进程消耗的内存越大,oom_score 就越大;
-
一个进程运行占用的 CPU 越多,oom_score 就越小。
这样,进程的 oom_score 越大,代表消耗的内存越多,也就越容易被 OOM 杀死,从而可以更好保护系统。
但是若应用程序本身的业务需求导致内存使用较高。如何确保在发生OOM时,不优先kill 该核心进程呢?
可以通过/proc 文件系统,手动设置进程的oom_adj,从而调整进程的oom_sore。比如将核心进程的oom_adj调整为-16,这样就不容易被OOM杀死。
echo -16 > /proc/$(pidof otamaster)/oom_adj由上可知:
回收内存的方式,会导致程序的运行效率降低。
由于OOM机制的存在,若核心进程占用内存较多,需要调整进程的oom_adj值
性能指标
对于内存性能分析,我们要知道从哪些指标可以分析内存性能。
系统内存指标
系统的内存性能,我们可以关注以下指标。
-
已用内存。系统已使用的内存,free 命令可查看。
-
剩余内存。系统未使用的内存,free 命令可查看。
-
可用内存。新进程可用的内存,free 命令可查看。
-
缺页异常。缺页异常分为两个场景。可以通过ps 和top 命令查看。top 命令默认不会展示缺页异常,可以通过
F->nMaj&nMin选择。-
可以直接从物理内存中分配时,被称为次缺页异常。
-
需要磁盘 I/O 介入(比如 Swap)时,被称为主缺页异常。
-
yihua@ubuntu:~$ ps -ef -o majflt,minflt,pid,user,comm
MAJFLT MINFLT PID USER COMMAND
0 1905 59570 yihua bash
0 236 59737 yihua \_ ps
0 38832 24665 yihua bash
-
缓存/缓冲区。buff/cache的大小,可以被系统回收。free 命令可查看。
-
其中buff,表示对磁盘的读写缓存。
-
cache,表示对文件的读写缓存以及slab的缓存。
-
-
slabs。应用程序在释放小内存时,slab 分配器不会立即释放给操作系统,而是缓存起来。提高内存利用率,以及减少内存碎片。
进程内存指标
进程的内存性能,我们可以关注以下指标。
-
VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
-
RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享内存。
-
SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及程序的代码段等。
-
%MEM 是进程使用物理内存占系统总内存的百分比。
-
Swap 内存,是指通过 Swap 换出到磁盘的内存。

由上可知:
通过
free命令,可以快速查看系统的内存使用情况。通过top 命令,可以分析进程内存的使用情况。
性能分析工具
free
yihua@ubuntu:~$ free -h
total used free shared buff/cache available
Mem: 3.8G 1.3G 596M 31M 1.9G 2.2G
Swap: 2.0G 111M 1.9G
-
第一列,total 是总内存大小;
-
第二列,used 是已使用内存的大小,包含了共享内存;
-
第三列,free 是未使用内存的大小,;
-
第四列,shared 是共享内存的大小,包括动态库;
-
第五列,buff/cache 是缓存和缓冲区的大小;
-
最后一列,available 是新进程可用内存的大小;不仅包含了未使用内存,也包含了可回收内存buff/cache;
free可以知道当前系统内存的静态状况。
vmstat
yihua@ubuntu:~$ vmstat 1 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 114176 611012 325036 1698592 0 0 4 11 1 10 0 0 100 0 0
0 0 114176 611012 325036 1698592 0 0 0 0 48 82 0 0 100 0 0
0 0 114176 611128 325036 1698592 0 0 0 0 53 91 0 0 100 0 0
0 0 114176 611128 325036 1698592 0 0 0 0 47 78 0 0 100 0 0
0 0 114176 611128 325036 1698592 0 0 0 0 55 86 0 0 100 0 0关注以下参数:
-
swap的换入/换出。
si/so -
内存部分的
buff和cache -
I/O的读写。
bi/bo
vmstat可以知道当前系统内存变化情况。
cachestat
$ cachestat 1 3
TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB
2 0 2 1 17 279
2 0 2 1 17 279
2 0 2 1 17 279 -
TOTAL ,表示总的 I/O 次数;
-
MISSES ,表示缓存未命中的次数;
-
HITS ,表示缓存命中的次数;
-
DIRTIES, 表示新增到缓存中的脏页数,即slab未释放给系统的缓存;
-
BUFFERS_MB 表示 Buffers 的大小,以 MB 为单位;
-
CACHED_MB 表示 Cache 的大小,以 MB 为单位。
cachestat 可以查看当前系统的缓存命中率。
cachetop
$ cachetop
11:58:50 Buffers MB: 258 / Cached MB: 347 / Sort: HITS / Order: ascending
PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT%
13029 root python 1 0 0 100.0% 0.0%-
MISSES ,表示缓存未命中的次数;
-
HITS ,表示缓存命中的次数;
-
DIRTIES, 表示新增到缓存中的脏页数,即slab未释放给系统的缓存;
-
READ_HIT%,读缓存命中率。
-
WRITE_HIT%,写缓存命中率。
cachetop 可以查看进程的缓存命中率状况。
pcstat
$ ls
$ pcstat /bin/ls
+---------+----------------+------------+-----------+---------+
| Name | Size (bytes) | Pages | Cached | Percent |
|---------+----------------+------------+-----------+---------|
| /bin/ls | 133792 | 33 | 33 | 100.000 |
+---------+----------------+------------+-----------+---------+pcstat查看文件在内存中的缓存大小以及缓存比例
内存优化套路
关于内存的问题,我们常遇到的一般就是内存泄漏。而缺页异常,swap机制,缓存不足等导致的性能问题,一般很少遇到。
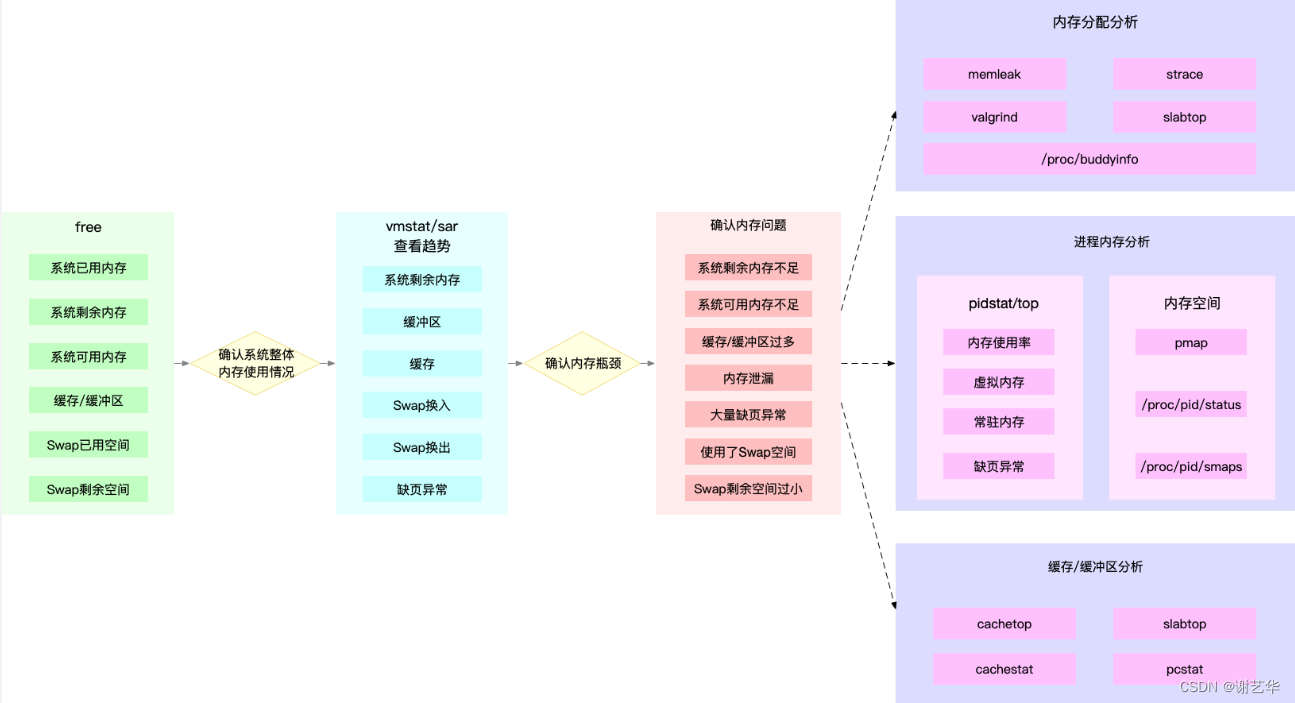
-
内存泄漏问题。
-
通过
free命令查看系统剩余内存是否充足。若持续减少,且不趋于稳定,则说明出现内存泄漏。 -
通过
top或pidstat命令查看哪一个进程内存持续增加。 -
通过
memleak或valgrind查看进程中内存分配点。 -
定位到代码,进行分析。
-
-
性能问题。内存性能问题一般的体现就是运行效率降低,对于实时性要求不高的程序也很难感知。
-
通过
free或top命令,查看系统的剩余内存,缓存/缓冲区,swap资源等。 -
通过
vmstat命令,查看系统内存资源的变化趋势,确认内存问题类型。-
若是swap导致的性能问题。可以尝试关闭swap机制。
-
若是缓存/缓存区过多。可以尝试设置
/proc/sys/vm/min_free_kbytes调整定期回收内存的繁殖。 -
若是大量发生缺页异常。可以在编码过程中建立缓存。
-
-
其中内存泄漏的排查套路,可参考《【精选】快速定位内存泄漏的套路_内存泄露log找哪些关键字-CSDN博客》。
性能问题案例,后续待补充。
常见优化方向
内存泄漏问题属于代码bug,需要我们修改代码。但是内存相关的优化,可以提高我们程序的运行效率。在我看来,内存调优最重要的就是:保证应用程序的热点数据放到内存中,并尽量减少换页和交换。
-
最好禁止 Swap。如果必须开启 Swap,降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
-
减少内存的动态分配。比如,可以使用内存池、大页(HugePage)等。
-
尽量使用缓存和缓冲区来访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者用 Redis 这类的外部缓存组件,优化数据的访问。
-
使用 cgroups 等方式限制进程的内存使用情况。这样,可以确保系统内存不会被异常进程耗尽。
-
通过 /proc/pid/oom_adj ,调整核心应用的 oom_score。这样,可以保证即使内存紧张,核心应用也不会被 OOM 杀死。
总结
工作中我们常遇到的内存问题就是内存泄漏。若是内存导致的效率问题,一般情况会比较少。即使遇到了,希望本文也能给予你分析和解决的思路。
若我的内容对您有所帮助,还请关注我的公众号。不定期分享干活,剖析案例,也可以一起讨论分享。
我的宗旨:
踩完您工作中的所有坑并分享给您,让你的工作无bug,人生尽是坦途


















 8091
8091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











