










背景
还记得在入职第一天,领导分配了两个遗留bug给我。两个问题都比较有挑战性。分别是:
stTsp进程重启。该问题的根因是因为数据库操作,导致短时间内导致内存骤增。触发linux OOM机制,内核将进程杀死。详细的分析思路可参考:【案例分析】入职第一天,如何让同事对我刮目相看。icpRcv进程未喂狗。由于该问题是偶现问题,所以一直没有积极跟进,但是当时经过与测试人员简单沟通,以及走读代码,初步感觉是线程阻塞了,导致没有持续喂狗。
因为还有项目需求开发,问题二一直被搁置了。这两天稍微有点时间,准备再回过头看看。运气很不错,很快就出现了。经过调试、分析。最终发现其原因是:线程死锁,导致各进程阻塞。本文主要分享我的分析思路和方法,希望能够帮助到您。🥰🥰🥰
架构简介
为了帮助您快速理解问题,我先向您简单介绍一下软件架构(架构以及基础件的设计非常不合理🤕,勿喷!!!)。
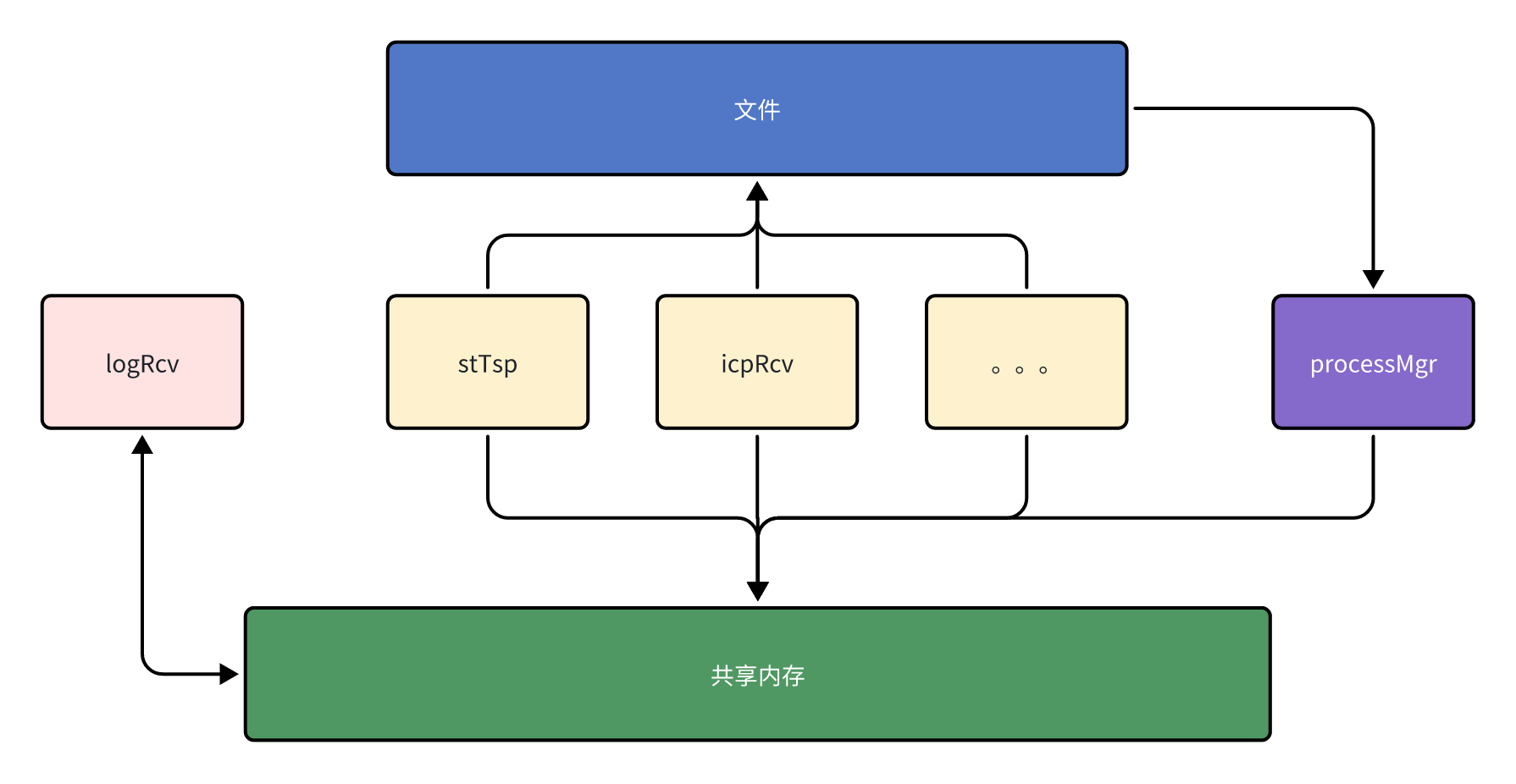
介绍:
- 我们采用多进程服务方式。不同类型的业务由不同的进程去实现。
- 为了日志分析方便。后续决定将不同进程的log打印输入到同一个文件中。于是就产生了
logRcv进程。它的作用就是通过读取共享内存中,来自其它业务线程的日志。将其写入统一的日志文件中。
其中共享内存结构定义如下:
#define UVLOG_BUF_MAX_SIZE (1024*20)
typedef struct uvLogCacheStruct
{
int valid;
char buf[UVLOG_BUF_MAX_SIZE];
int tail;
pthread_mutex_t mutex;
uint16_t owner_dpid;
int err_cnt;
} uvLogCacheStruct;
uvLogCacheStruct *uvlog_cache = NULL;
业务进程,进行日志打印伪代码:
/** 1.获取共享内存锁*/
pthread_mutex_lock(&uvlog_cache->mutex);
/** 2.将日志写入buf*/
memcpy(uvlog_cache->buf,logstr,sizeof(logstr));
/** 3.释放共享内存中的线程锁*/
pthread_mutex_unlock(&uvlog_cache->mutex);
logRcv进程,写日志文件伪代码:
/** 1.获取共享内存锁*/
pthread_mutex_lock(&uvlog_cache->mutex);
/** 2.1 内部逻辑处理:比如日志文件覆盖、备份等
2.2 将共享内存中的buf写入文件*/
...
write(fd,uvlog_cache->buf,sizeof(uvlog_cache->buf));
/** 3.释放共享内存中的线程锁*/
pthread_mutex_unlock(&uvlog_cache->mutex);
其实从上述逻辑可知,若logRcv在内部逻辑处理时,出现了阻塞。那么就会导致其它业务进程全部异常(只要调用了日志打印接口),我认为这是非常不合理的。
- 业务进程通过写文件的方式与守护进程
processMgr进行喂狗。
问题现象描述
测试同事描述的现象:icpRcv进程未喂狗,导致守护进程重启。
经过走读喂狗线程,伪代码如下:
while(true)
{
sleep(5);
...
/** 喂狗*/
wirte(fd,"#",1);
...
uv_log("PMGR_feedDog")
...
}
守护进程processMgr的伪代码:
while(true)
{
sleep(3);
/** 若进程未启动,则重启进程*/
/** 若超过15秒,为喂狗,则kill进程,并拉起*/
}
分析:
- 守护进程提示未喂狗,将
icpRcv进程重启。那么就很有可能是因为icpRcv的喂狗线程没有喂狗。 - CPU的调度单位是线程,即使是其它子线程阻塞了。也应该会调用到喂狗线程,进行喂狗。因此,我的想法是怀疑喂狗线程中出现了阻塞。
排查死锁的方式,我一般有两个方向:
- 走读代码。前提是对代码架构比较熟悉。
- gdb调试。问题复现时,通过gdb查看各进程的堆栈信息,分析锁资源状态。
我采用了后者,中间也出现了一些插曲——设备里面的gdb工具无法正常使用。其解决思路可以参考gdb 环境问题:Backtrace stopped: previous frame identical to this frame (corrupt stack?)。
调试
很幸运,大约拷机2个小时左右,该现象就出现了(版本做了特殊处理:喂狗超时,不重启进程,仅打印,目的是保留现场,方便我调试)。于是我查看icpRcv的堆栈信息,如下:
/ # gdb -p 1314
GNU gdb (GDB) 7.9.1
Copyright (C) 2015 Free Software Foundation, Inc.
...
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/libthread_db.so.1".
Reading symbols from /lib/libc.so.6...done.
Reading symbols from /lib/ld-linux.so.3...done.
0xb6e233d4 in nanosleep () from /lib/libc.so.6
(gdb) bt
#0 0xb6e233d4 in nanosleep () from /lib/libc.so.6
#1 0xb6e56ea0 in usleep () from /lib/libc.so.6
#2 0x7f55bba4 in mq_listen_timeout ()
#3 0x7f557354 in main ()
由上可知,主线程的堆栈打印都是正常的。于是通过info thread查看其它线程信息。如下:
(gdb) info thread
Id Target Id Frame
5 Thread 0xb6d80460 (LWP 1319) "icpRcv" 0xb6edef18 in __lll_lock_wait ()
from /lib/libpthread.so.0
4 Thread 0xb6580460 (LWP 1320) "icpRcv" 0xb6e233d4 in nanosleep ()
from /lib/libc.so.6
3 Thread 0xb5d80460 (LWP 1321) "icpRcv" 0xb6edbbfc in pthread_cond_wait@@GLIBC_2.4 () from /lib/libpthread.so.0
2 Thread 0xb5580460 (LWP 1322) "icpRcv" 0xb6e5f638 in msgrcv ()
from /lib/libc.so.6
* 1 Thread 0xb6f26210 (LWP 1314) "icpRcv" 0xb6e233d4 in nanosleep ()
from /lib/libc.so.6
由上可知,线程ID 1319(喂狗线程)似乎在等待锁,于是再进一步查看其堆栈信息,如下:
(gdb) thread 5
[Switching to thread 5 (Thread 0xb6d80460 (LWP 1319))]
#0 0xb6edef18 in __lll_lock_wait () from /lib/libpthread.so.0
(gdb) bt
#0 0xb6edef18 in __lll_lock_wait () from /lib/libpthread.so.0
#1 0xb6ed7d3c in pthread_mutex_lock () from /lib/libpthread.so.0
#2 0x7f5589d0 in printLogS ()
#3 0x7f559cb8 in _addToLogCache ()
#4 0x7f55a1c8 in uv_log ()
#6 0xb6ed50bc in start_thread () from /lib/libpthread.so.0
#7 0xb6e5dda0 in ?? () from /lib/libc.so.6
#8 0x00000000 in ?? ()
Backtrace stopped: previous frame identical to this frame (corrupt stack?)
由该堆栈信息分析,大致可以知道喂狗线程在通过uv_log接口打印时,获取锁资源时,一直无法获取到。导致该线程阻塞,无法进行喂狗操作。
那么问题来了,我们怎么知道该锁被谁占用呢?其实,根据pthread_mutex_t定义,我们可以方便的知道谁持有。
typedef union
{
struct __pthread_mutex_s
{
int __lock;
unsigned int __count;
int __owner;
unsigned int __nusers;
int __kind;
short __spins;
short __elision;
__pthread_list_t __list;
} __data;
char __size[__SIZEOF_PTHREAD_MUTEX_T];
long int __align;
} pthread_mutex_t;
- __lock:锁的状态,0 表示未锁定,1 表示已锁定。
- __count:锁的计数器,用于支持递归锁。如果是普通锁,则该值为 0;如果是递归锁,则该值表示锁的嵌套层数。
- __owner:持有该锁的线程 ID,如果锁当前未被任何线程持有,则该值为 0。
- __nusers:等待该锁的线程数。
- __kind:锁的类型,包括 PTHREAD_MUTEX_NORMAL(普通锁)、PTHREAD_MUTEX_RECURSIVE(递归锁)和 PTHREAD_MUTEX_ERRORCHECK(检错锁)。
于是我尝试通过p uvlog_cache->mutex打印结构体成员值。但是因为没有符号表的原因,导致无法进行输出。如下:
(gdb) p (pthread_mutex_t)uvlog_cache->mutex
No symbol "pthread_mutex_t" in current context.
于是我通过打印内存地址的方式,获取线程锁的内容,如下:
(gdb) p &uvlog_cache->mutex
$2 = (<data variable, no debug info> *) 0x7f5635a0 <uvlog_cache->mutex>
(gdb) x/32dw 0x7f5635a0
0x7f5635a0 <uvlog_cache->mutex>: 2 0 1298 22
0x7f5635b0 <uvlog_cache->mutex+16>: 1 0 2136314360 2136314376
0x7f5635c0 <__module+8>: -1226410084 1 1 0
0x7f5635d0 <echo_str>: 1701869940 667709 794913124 1633903731
0x7f5635e0 <echo_str+16>: 1815045234 1831823215 1814984048 1864394607
0x7f5635f0 <echo_str+32>: 544367990 1702521203
由上可知,该锁被ppid=1298(logRcv)持有,并且有22个线程在等待(多个业务进程,每个进程都有多个线程会调用uv_log接口)。
其实到这里基本就可以确定是:logSrv进程持有了共享内存中的线程锁,并且没有释放。导致其它进程、线程只要调用了uv_log接口,就会导致申请锁失败,阻塞。
那么问题就延伸为:logSrv进程,为什么没有释放锁?
同样的套路(关于gdb的进阶使用,可以参考【小白进阶】Linux 调试大法——gdb):
gdb -p pid,调试指定进程。info thread查看各线程堆栈信息,可知有三个线程存在阻塞情况(等待线程锁)。如下:
(gdb) info thread
Id Target Id Frame
6 Thread 0xb6e1e460 (LWP 1299) "logSrv" 0xb6efd638 in msgrcv ()
from /lib/libc.so.6
5 Thread 0xb661e460 (LWP 1300) "logSrv" 0xb6efd638 in msgrcv ()
from /lib/libc.so.6
4 Thread 0xb5e1e460 (LWP 1301) "logSrv" 0xb6f7cf18 in __lll_lock_wait ()
from /lib/libpthread.so.0
* 3 Thread 0xb561e460 (LWP 1302) "logSrv" 0xb6f7cf50 in __lll_lock_wait ()
from /lib/libpthread.so.0
2 Thread 0xb4aff460 (LWP 8284) "logSrv" 0xb6f7cf50 in __lll_lock_wait ()
from /lib/libpthread.so.0
1 Thread 0xb6fc4210 (LWP 1298) "logSrv" 0xb6ec13d4 in nanosleep ()
from /lib/libc.so.6
thread n+bt查看阻塞线程的堆栈信息,确认等待的线程锁。p var或x address查看线程锁被哪个线程占用。- 分析占用资源线程的代码逻辑
最终通过代码分析,是因为某线程对在特定情况下,会对同一个线程锁连续执行两次pthread_mutex_lock操作,即:
pthread_mutex_lock(&mutex); //first
...
/** do something*/
if(condition)
{
pthread_mutex_lock(&mutex); //second
...
/** do something*/
pthread_mutex_unlock(&mutex);
}
...
/** do something*/
pthread_mutex_unlock(&mutex);
当执行到第二次pthread_mutex_lock时,会被阻塞。导致无法释放共享内存中的线程锁。异常流程大致如下:
/** 1.获取共享内存锁*/
pthread_mutex_lock(&uvlog_cache->mutex);
/** 2.1 内部逻辑处理:*/
pthread_mutex_lock(&mutex); //first
...
/** do something*/
if(condition)
{
pthread_mutex_lock(&mutex); //second error
...
/** do something*/
pthread_mutex_unlock(&mutex);
}
...
/** do something*/
pthread_mutex_unlock(&mutex);
/** 2.2 将共享内存中的buf写入文件*/
...
write(fd,uvlog_cache->buf,sizeof(uvlog_cache->buf));
/** 3.释放共享内存中的线程锁*/
pthread_mutex_unlock(&uvlog_cache->mutex);
最终通过修改申请锁,释放锁时序即可。
总结
本文通过工作中的真实案例,向大家分享如何分析、排查、调试、线程死锁的问题。从而发现多次连续调用pthread_mutex_lock会导致异常,为我们以后编码提高警觉。希望我的分享能够给您带来帮助。
若我的内容对您有所帮助,还请关注我的公众号。不定期分享干活,剖析案例,也可以一起讨论分享。
我的宗旨:
踩完您工作中的所有坑并分享给您,让你的工作无bug,人生尽是坦途





















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











