







最近整理Transformer和set prediction相关的检测&实例分割文章,感兴趣的可以跟一下:
- DETR: End-to-End Object Detection with Transformers
- Deformable DETR
- Rethinking Transformer-based Set Prediction for Object Detection
- Instances as Queries
- SOLQ: Segmenting Objects by Learning Queries Bin
| paper | https://arxiv.org/abs/2105.01928 |
|---|---|
| code | https://github.com/hustvl/QueryInst |
1. 总述
- 本文提出一种机遇query的实例分割方法,其中已经没有了Transformer的结构(仅保留了Multi-head attention模块),只是保留了DETR中的随机初始化N个object queries和匈牙利匹配损失函数。
- 同时,本文类似于Cascade RCNN设计了一种多阶段迭代优化的bbox和mask预测头,但是不同于Cascade RCNN 每次在下一阶段以更高IoU阈值进行重采样,本文的多个阶段的N个queries均是一一对应的,即第一个query slot在每个阶段均用来预测同样的目标。
2. 算法结构
2.1 Backbone
ResNet50+FPN输出C2, C3, C4, C5四个分辨率的特征,比如[(B, 256, 200, 200), (B, 256, 100, 100), (B, 256, 50, 50), (B, 256, 25, 25)]。
2.2 Query based Object Detector
2.2.1 Query Embedding Init
此处采用nn.Embedding初始化N个object 的queries bbox和queries features,并将初始化的bbox解码为原始尺寸的bbox表达。
# init proposal_bboxes & proposal_features
self.init_proposal_bboxes = nn.Embedding(self.num_proposals, 4)
self.init_proposal_features = nn.Embedding(self.num_proposals, self.proposal_feature_channel)
# Decode init_proposal_bboxes according to the size of images and expand batch_size dimension.
def _decode_init_proposals(self, imgs, img_metas):
proposals = self.init_proposal_bboxes.weight.clone()
proposals = bbox_cxcywh_to_xyxy(proposals) # bbox编码由中心点+宽高改为左上右下角点表示
num_imgs = len(imgs[0])
imgs_whwh = []
for meta in img_metas:
h, w, _ = meta['img_shape']
imgs_whwh.append(imgs[0].new_tensor([[w, h, w, h]]))
imgs_whwh = torch.cat(imgs_whwh, dim=0)
imgs_whwh = imgs_whwh[:, None, :]
# imgs_whwh has shape (batch_size, 1, 4)
# The shape of proposals change from (num_proposals, 4)
# to (batch_size ,num_proposals, 4)
proposals = proposals * imgs_whwh # 将归一化的坐标乘以长宽缩放因子
init_proposal_features = self.init_proposal_features.weight.clone()
init_proposal_features = init_proposal_features[None].expand(
num_imgs, *init_proposal_features.size())
return proposals, init_proposal_features, imgs_whwh
2.2.2 bbox & cls预测
由于QueryInst是多阶段的bbox和mask预测,我们先以第一阶段预测为例讲述:

如上图所示,
- x F P N x^{FPN} xFPN代表FPN输出的多分辨率特征图;
- b t − 1 b_{t-1} bt−1代表上一阶段的bbox预测;
- P b o x P^{box} Pbox代表ROI Align操作;
- x t b o x x_t^{box} xtbox代表ROI Align得到的7*7的bbox feature;
- q t − 1 q_{t-1} qt−1表示上一阶段的object query;
- M S A t MSA_t MSAt表示当前阶段的multi-head self-attention;
- q t − 1 ⋆ q_{t-1}^\star qt−1⋆代表transformed query;
- x t b o x ⋆ x_t^{box \star} xtbox⋆代表经过 D y n C o n v t b o x DynConv^{box}_t DynConvtbox增强后的bbox feature;
- B t \Beta_t Bt代表由FFN构成的bbox预测分支;
- b t b_t bt代表当前bbox预测结果;
那么,上述的公式流程就代表,给定上一阶段的bbox预测结果 ( B , N , 4 ) (B, N, 4) (B,N,4)和object query ( B , N , 256 ) (B, N, 256) (B,N,256),首先通过ROI Align操作从FPN特征图提取bbox特征 ( B , N , 256 , 7 , 7 ) (B, N, 256, 7, 7) (B,N,256,7,7);随后利用multi-head self-attention计算transformed object query;随后利用object query和bbox feature之间的动态卷积得到增强后的bbox feature和object query;紧接着在其基础上进行bbox预测和cls预测。
2.2.3 D y n C o n v b o x DynConv^{box} DynConvbox

这里是
D
y
n
C
o
n
v
m
a
s
k
DynConv^{mask}
DynConvmask的示意图,
D
y
n
C
o
n
v
b
o
x
DynConv^{box}
DynConvbox与其一致。具体来讲,给定transformed object query with shape
(
B
,
N
,
256
)
(B, N, 256)
(B,N,256)和ROI Align得到的bbox feature
(
B
,
N
,
256
,
7
,
7
)
(B, N, 256, 7, 7)
(B,N,256,7,7),首先利用一个全连接层对object query 进行映射得到两组1*1卷积参数
(
B
,
N
,
256
∗
64
+
64
∗
256
)
(B, N, 256*64+64*256)
(B,N,256∗64+64∗256),进而使用这两组卷积参数对bbox feature进行卷积得到输出
(
B
,
N
,
256
,
7
,
7
)
(B, N, 256, 7, 7)
(B,N,256,7,7),最后将其reshape为
(
B
,
N
,
256
∗
7
∗
7
)
(B, N, 256*7*7)
(B,N,256∗7∗7)再进行通道降维得到输出后的object query
(
B
,
N
,
256
)
(B, N, 256)
(B,N,256)。
此处在上面的公式中, D y n C o n v b o x DynConv^{box} DynConvbox输出了两个变量* q t q_{t} qt和 x t b o x ⋆ x_t^{box \star} xtbox⋆,但实际代码中只有一个输出object query ( B , N , 256 ) (B, N, 256) (B,N,256),bbox预测和cls预测都是在此基础上进行的。
2.3 Mask Head Architecture

此处仅介绍论文中的Dynamic Mask Head,先看下面的几行公示,其与上一小节中的bbox head几乎一致,只不过缺少了
q
t
−
1
⋆
=
M
S
A
t
(
q
t
−
1
)
q^\star_{t-1}=MSA_t (q_{t-1})
qt−1⋆=MSAt(qt−1)这一步,从上图中可以看到这是因为bbox和mask在每个阶段共用MSA。
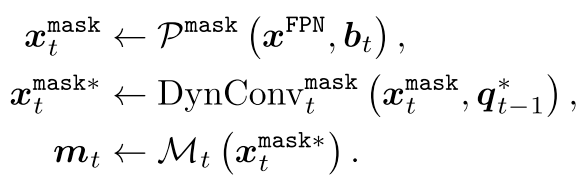
- x t m a s k x_t^{mask} xtmask代表ROI Align得到的7*7的mask feature;
- q t − 1 ⋆ q_{t-1}^\star qt−1⋆代表transformed query;
- x t m a s k ⋆ x_t^{mask \star} xtmask⋆代表经过 D y n C o n v t m a s k DynConv^{mask}_t DynConvtmask增强后的mask feature;
- M t M_t Mt代表由convs构成的mask预测分支;
- m t m_t mt代表当前阶段mask预测结果;
上面的 D y n C o n v m a s k DynConv^{mask} DynConvmask与 D y n C o n v b o x DynConv^{box} DynConvbox主要结构都是一样的,不过其最后直接输出 ( B , N , 256 , 14 , 14 ) (B, N, 256, 14, 14) (B,N,256,14,14)的特征图,而 D y n C o n v b o x DynConv^{box} DynConvbox不需要mask的空间信息,所以多了一步reshape&降维的操作。
2.4 Comparisons with Cascade Mask R-CNN and HTC
- 对于Cascade Mask R-CNN和HTC,在统计意义上细化了不同阶段proposal的质量。对于每个阶段,训练样本的数量和分布都有很大的不同,在不同阶段中,每个单独的proposal没有明确的内在对应。
- 对于QueryInst,各个阶段之间的连接是通过query中固有的一一对应自然建立的。这种方法消除了显式多阶段mask head连接和proposal分布不一致的问题。
3. 实验结果
For inference, we use the final stage masks as the predictions and ignore all the parallel DynConv mask at the intermediate stages.


















 268
268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









