






目录
聚类与分类的区别
分类是指目标已经知道了,比如进行垃圾的分类,邮件的分类等。
聚类是事先不知道变量的目标是什么,完全通过算法根据数据的相似性进行集聚的。
聚类和分类最大的不同在于:分类的目标是事先已知的,而聚类则不一样,聚类事先不知道目标变量是什么,其划分的类别也没有提前定义出来。
KMeans介绍
大量数据都有着相似性,根据他们的相似性,可以将其划分为一类或一簇。划分的基本原理就是物以聚类,人以群分。
K均值(KMeans)是聚类中最常用的方法之一,基于点与点之间的距离的相似度来计算最佳类别归属。即:根据各个数据点之间的距离大小进行划分,将距离接近的数据划分为一类。
自然被分在同一个簇中的数据是有相似性的,而不同簇中的数据是不同的。当聚类完毕之后,我们就要分别去研究每个簇中的样本都有什么样的性质,从而根据业务需求制定不同的策略。KMeans常用于客户分群、用户画像、精确营销、基于聚类的推荐系统。
KMeans原理
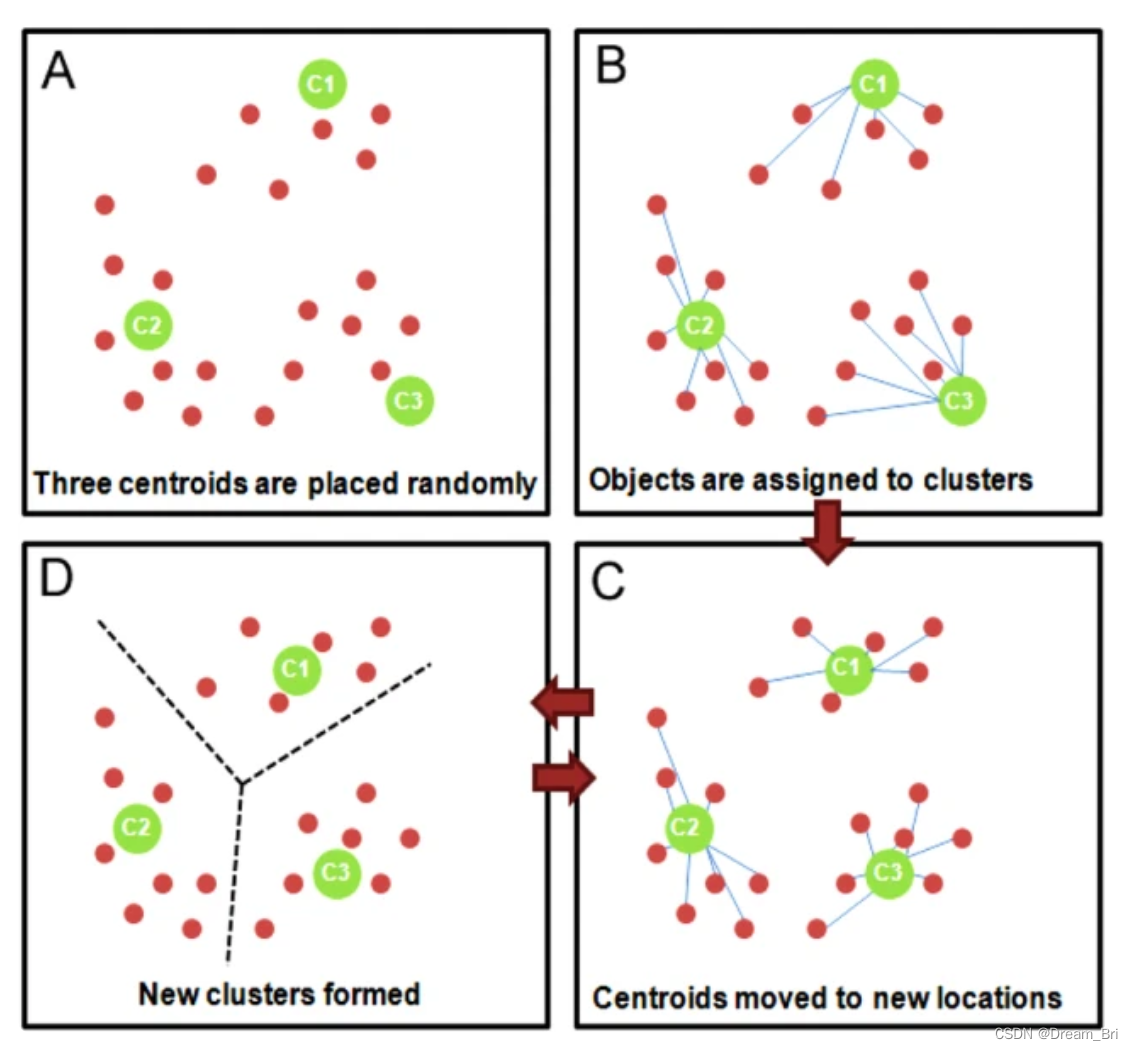
1、随机选择 k 个样本作为初始簇类中心(k为超参,代表簇类的个数。可以凭先验知识、验证法确定取值);
2、针对数据集中每个样本,计算它到 k 个簇类中心的距离,并将其归属到距离最小的簇类中心所对应的类中;
3、针对每个簇类,重新计算它的簇类中心位置;
4、重复迭代上面 2 、3 两步操作,直到达到某个中止条件(如迭代次数,簇类中心位置不变等)。
实现过程如下:
注:
1、sklearn中的KMeans使用的是欧几里得距离。
2、虽然在sklearn中只能被动选用欧式距离,但其他距离度量方式同样可以用来衡量簇内外差异。
3、在KMeans中,只要使用了正确的质心和距离组合,无论使用什么样的距离,都可以达到不错的聚类效果
KMeans有损失函数吗?
损失函数本质是用来衡量模型的拟合效果的,只有有着求解参数需求的算法,才会有损失函数。KMeans不求解什么参数,它的模型本质也没有在拟合数据,而是在对数据进行一 种探索。
另外,在决策树中有衡量分类效果的指标准确度accuracy,准确度所对应的损失叫做泛化误差,但不能通过最小化泛化误差来求解某个模型中需要的信息,我们只是希望模型的效果上表现出来的泛化误差很小。
KMeans定义
sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=None, algorithm='auto')
参数解释:
1、n_clusters=8: 要聚成的簇数,以及要生成的质心数。
2、init {‘k-means++’, ‘random’, ndarray, callable}, default=’k-means++’
这是初始化质心的方法,输入"k- means++":代表一种为K均值聚类选择初始聚类中心的聪明的办法,以加速收敛。如果输入了n维数组,数组的形状应该是(n_clusters,n_features)并给出初始质心。
3、n_init int, default=10:使用不同的质心随机初始化的种子来运行,是KMeans算法的次数。
4、max_iter int, default=300:单次运行的KMeans算法的最大迭代次数。
5、tol float, default=1e-4:两次迭代间Inertia下降的量,如果两次迭代之间Inertia下降的值小于tol所设定的值,迭代就会停下。
6、precompute_distances {‘auto’, True, False}, default=’auto’
预计算距离(更快,但需要更多内存)。
7、‘auto’: 如果 n_samples * n_clusters > 1200万,不要预先计算距离。这对应于使用双精度来学习,每个作业大约100MB的内存开销。
8、verbose int, default=0:计算中的详细模式。
9、random_state int, RandomState instance, default=None:确定质心初始化的随机数生成。使用int可以是随机性更具有确定性。
10、copy_x bool, default=True:在预计算距离时,若先中心化数据,距离的预计算会更加准确。如果copy_x为True(默认值),则不会修改原始数据,确保特征矩阵X是c-contiguous。如果为False,则对原始数据进行修改,在函数返回之前放回原始数据,但可以通过减去数据平均值,再加上数据平均值,引入较小的数值差异。
11、n_jobs int, default=None:用于计算的作业数。计算每个n_init时并行作业数。这个参数允许KMeans在多个作业线上并行运行。给这个参数正值n_jobs,表示使用 n_jobs 条处理器中的线程。值-1表示使用所用可用的处理器。值-2表示使用所有可能的处理器-1个处理器,以此类推。
12、algorithm {“auto”, “full”, “elkan”}, default=”auto”:使用KMeans算法。经典的EM风格的算法是"full"的。通过使用三角不等式,“elkan"变异在具有定义明确的集群的数据上更有效。然而,由于分配了额外的形状数组(n_samples、n_clusters),它会占用更多的内存。目前,“auto” 为密集数据选择 “elkan” 为稀疏数据选择"full”。
KMeans简单示例
代码如下:
import numpy as np
X = np.array([[1, 2], [1, 4], [1, 0],
[10, 2], [10, 4], [10, 0]])
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
print(kmeans.labels_)
# 显示的结果为:[1 1 1 0 0 0]
print(kmeans.predict([[0, 0], [12, 3]]))
# 显示的结果为[1, 0]
print(kmeans.cluster_centers_)
# 输出的结果为:[[10. 2.] [ 1. 2.]]
KMeans中K值的确定
KMeans划分为k个簇,对于不同k的情况,算法的效果可能差异就很大。
K值常用的确定方法有:先验法、手肘法等
先验法
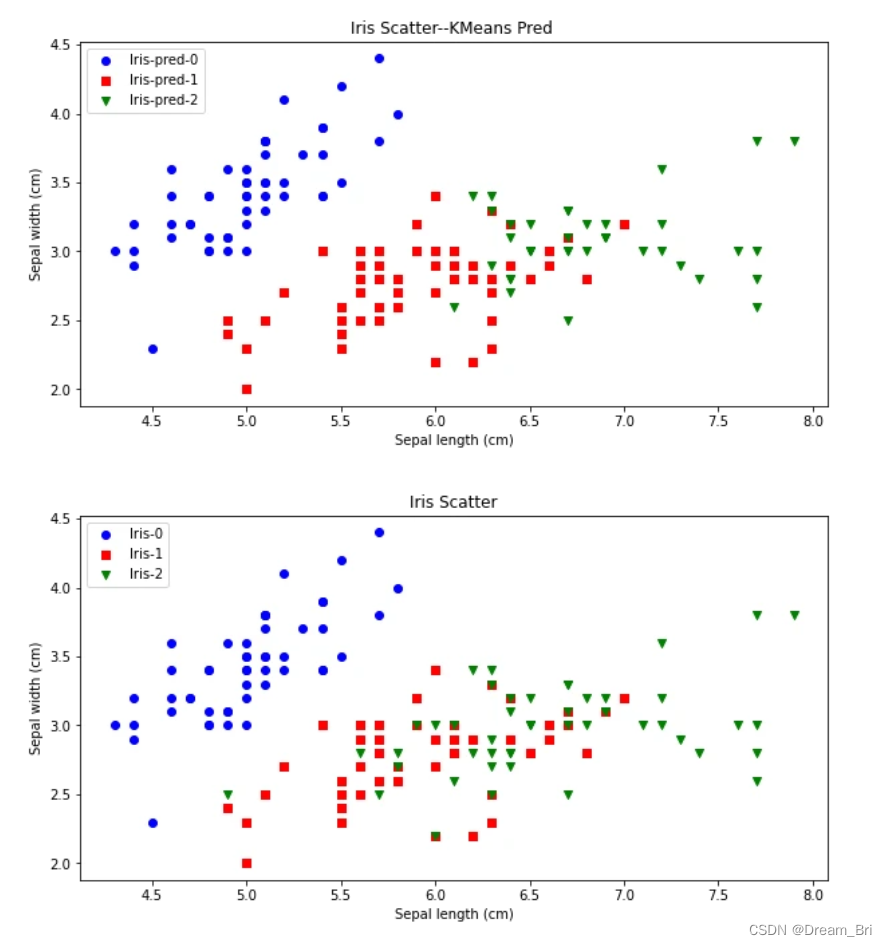
先验比较简单,就是凭借着业务知识确定k的取值。比如对于iris花数据集,我们大概知道有三种类别,可以按照k=3做聚类验证。
从下图可看出,对比聚类预测与实际的iris种类是比较一致的。
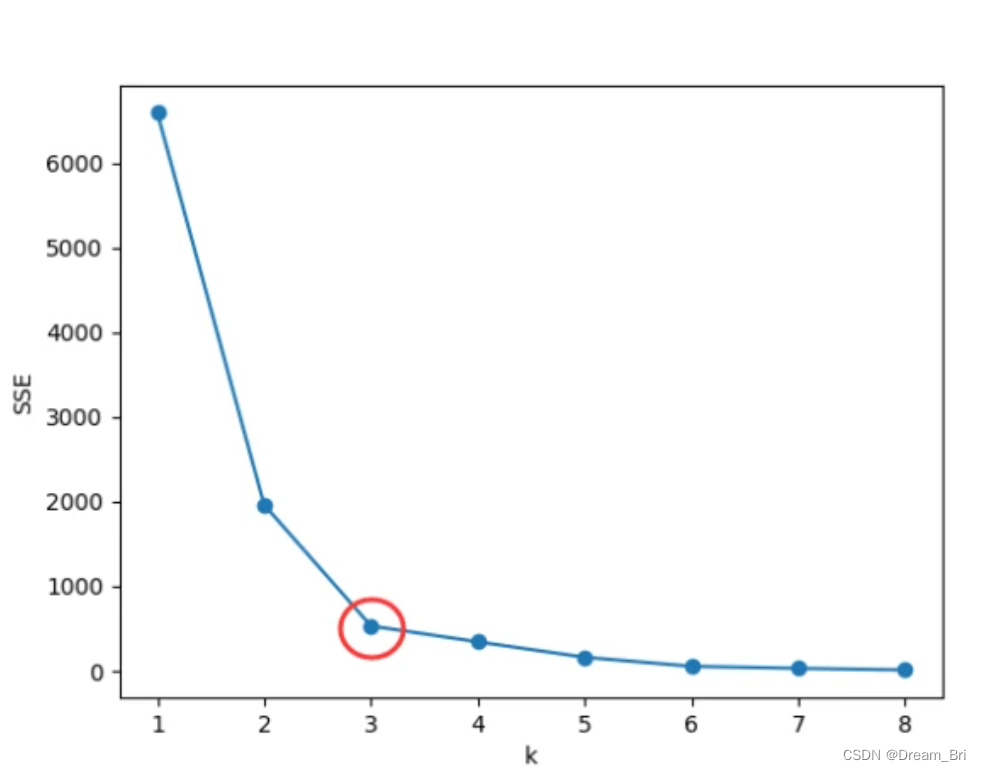
手肘法
可以知道k值越大,划分的簇群越多,对应的各个点到簇中心的距离的平方的和(类内距离,WSS)越低,我们通过确定WSS随着K的增加而减少的曲线拐点,作为K的取值。手肘法的缺点在于需要人为判断不够自动化。
KMeans算法的优缺点
KMeans算法的优点
KMeans算法是解决聚类问题的一种经典算法, 算法简单、快速 。
算法尝试找出使平方误差函数值最小的K个划分。当簇是密集的、球状或团状的,且簇与簇之间区别明显时,聚类效果较好 。
KMeans算法的缺点
KMeans方法只有在簇的平均值被定义的情况下才能使用,且对有些分类属性的数据不适合。
要求用户必须事先给出要生成的簇的数目,且对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。
不适合于发现非凸面形状的簇,或者大小差别很大的簇。
KMeans本质上是一种基于欧式距离度量的数据划分方法,均值和方差大的维度将对数据的聚类结果产生决定性影响。所以在聚类前对数据(具体的说是每一个维度的特征)做归一化(点击查看归一化详解)和单位统一至关重要。
此外,异常值会对均值计算产生较大影响,导致中心偏移,因此对于"噪声"和孤立点数据最好能提前过滤 。
KMeans算法优化
KMeans算法虽然效果不错,但是每一次迭代都需要遍历全量的数据,一旦数据量过大、计算复杂度过大、迭代的次数过多,会导致收敛速度非常慢。
由KMeans算法原来可知,KMeans在聚类之前首先需要初始化K个簇中心,因此 KMeans算法对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。因初始化是个"随机"过程,很有可能K个簇中心都在同一个簇中,这种情况 KMeans 聚类算法很大程度上都不会收敛到全局最小。
想要优化KMeans算法的效率问题,可以从以下两个思路优化算法,一个是样本数量太大,另一个是迭代次数过多。
MiniBatchKMeans 聚类算法
mini batch 优化思想很直接,既然全体样本当中数据量太大,会使得我们迭代的时间过长,那么随机从整体当中做一个抽样,选取出一小部分数据来代替整体以达到缩小数据规模的目的。
mini batch 优化非常重要,不仅重要而且在机器学习领域广为使用。在大数据的场景下,几乎所有模型都需要做mini batch优化,而MiniBatchKMeans就是mini batch 优化的一个应用。
比如一个样本量为1,000,000分别用MiniBatchKMeans和KMeans两种算法进行计算,KMeans用时接近 6 秒钟,而MiniBatchKMeans 仅用时不到 1 秒钟。
mini batch优化方法是通过减少计算样本量来达到缩短迭代时长,另一种方法是降低收敛需要的迭代次数,从而达到快速收敛的目的。因为收敛的速度除了取决于每次迭代的变化率之外,另一个重要指标就是迭代起始的位置。
参考:
https://zhuanlan.zhihu.com/p/391877604
https://view.inews.qq.com/k/20220225A0B4BJ00?web_channel=wap&openApp=false
















 7034
7034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











