






首先要自己在win10下的idea中可以导入spark相关的包,并且可以运行
然后这个要监听端口的,我们要下载一个netcat这个软件
netcat下载地址
然后把这个里面的nc64.exe放到电脑的C:\Windows下面
运行下面的程序的时候可以先打开电脑的cmd,输入nc64 -l -p 9999
运行idea中的代码
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object test_sparkStreaming {
def main(args: Array[String]): Unit = {
// val conf = new SparkConf().setMaster("local").setAppName("text")
//1、初始化Spark配置信息
val sparkConf = new SparkConf().setAppName("sparkStreaming").setMaster("local[*]")
val sc = new SparkContext(sparkConf)
//2、初始化SparkStreamingContext
val ssc = new StreamingContext(sc,Seconds(3)) //三秒一次循环
//把数据进行处理,以空格分开,把后面的true和false转变为布尔型
val mingdan=sc.textFile("file:/F:\\mingdan.txt").map{x=>val y=x.split(" ");(y(0),y(1).toBoolean)}
println("true表示在黑名单里,最后过滤的结果不会显示出来")
mingdan.foreach(x=>println(x)) //打印mingdan里的内容
sc.setLogLevel("WARN") //设置日志,只出现WARN的警告
//设置为本地地址,端口号为9999
val lineStreams = ssc.socketTextStream("localhost", 9999) //输入监听端口的内容
// lineStreams.print()
val users=lineStreams.map(x=>(x.split(" ")(1),x)) //分离出输入内容的第二个,然后和原来的形成一个元组
// users.print()
//打印mingdan里的内容
val validRddDS=users.transform(x=>{
//进行左外连接,users里的第一个元组进行匹配,然后将mingdan后面的true这些连接到users的第二个元组的后面
val joinRdd=x.leftOuterJoin(mingdan)
// println("joinRDD")
// joinRdd.foreach(x=>println(x))
//进行过滤,判断,对新连接的joinRdd的这个数据进行操作,对第二个元组中的第二个元组进行判断过滤
val fRdd=joinRdd.filter(y=>{
if(y._2._2.getOrElse(false)) {false} //把是false的保留
else {true}
})
// println("fRdd")
// fRdd.foreach(x=>println(x))
//这里只输出过滤后的在监听端口输入的内容
val validRdd=fRdd.map(y=>y._2._1)
validRdd
})
validRddDS.print() //打印过滤结果
//启动StreamingContext,采集
ssc.start()
//Drvier等待采集器的执行
ssc.awaitTermination()
}
}
在cmd中输入
11111 spark
1111 hadoop
2222 hive
3333 hadoop
4444 hbase
3333 flume
4444 oozie
5555 flume
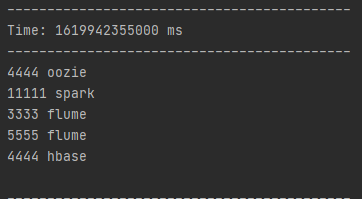
这个在idea运行之前输入的内容,在这里不会显示出来,要代码运行后才会显示
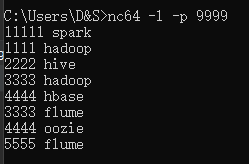
在idea中可以看到过滤的结果
将名字放到前面,方便后面和mingdan有相同的键值可以左外连接起来
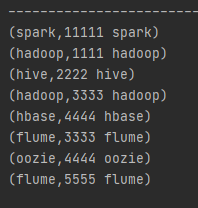
joinRdd和fRdd的结果,前面的是已经连接后的,后面的经过过滤了的
















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









