






项目地址:
https://github.com/hiyouga/LLaMA-Factory.git![]() https://github.com/hiyouga/LLaMA-Factory.git
https://github.com/hiyouga/LLaMA-Factory.git
项目已经有比较完善步骤,但有几个点容易出错。
环境配置
首先用Anaconda创建个环境,因为需要安装许多额外的包,并且pytorch版本和cuda也不一定对。
conda环境使用基本命令:
conda update -n base conda #update最新版本的conda
conda create -n xxxx python=3.10 #创建python3.5的xxxx虚拟环境
conda activate xxxx #开启xxxx环境
conda deactivate #关闭环境
conda env list #显示所有的虚拟环境
conda info --envs #显示所有的虚拟环境
conda remove -n xxxx --all #删除xxxx虚拟环境
conda list #查看已经安装的文件包
conda list -n xxx #指定查看xxx虚拟环境下安装的package
conda update xxx #更新xxx文件包
conda uninstall xxx #卸载xxx文件包用项目自带的requirements.txt文件先配置一下环境(配置完也不一定能用,但能配置大部分)
pip install -r requirements.txt然后先将requirements.txt文件自动配置的torch卸载掉
conda uninstall torch然后查看自己cuda最高版本和当前版本
nvidia-smi下面是查看当前cuda版本(但这个不重要,因为咱们要在conda环境中安装)
nvcc -V图1
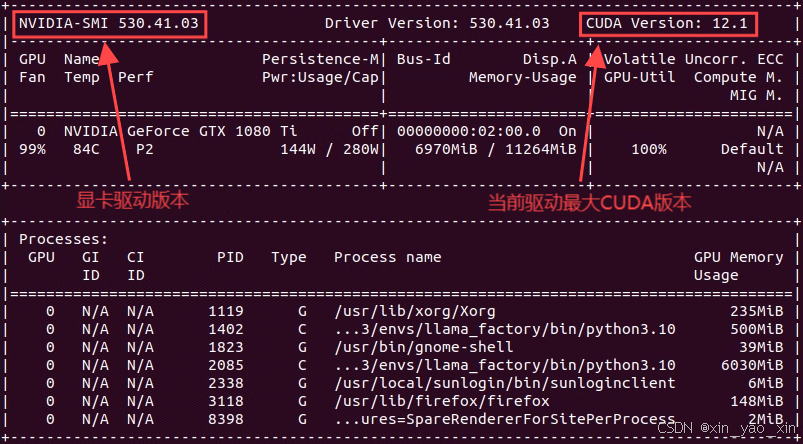
图2
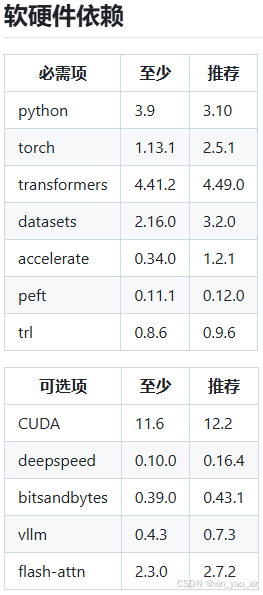
图1中是当前驱动和最大CUDA版本,
图2中是限制条件CUDA最少要求11.6不然运行时会提示没有CUDA环境
但CUDA最大版本又受NVIDIA显卡驱动版本影响
下面是安装驱动参考链接:推荐使用software & updates直接安装(省事)
【亲测有效】Linux系统安装NVIDIA显卡驱动_linux安装nvidia显卡驱动-CSDN博客
ubuntu18.04安装显卡驱动(四种方式)-CSDN博客
不同 nvidia-driver 版本大致对应的 CUDA 版本,不过实际的对应关系可能会受操作系统、硬件等因素影响,你可以参考 NVIDIA 官方 CUDA 兼容性矩阵 获取最准确信息:
1. nvidia-driver-390
此驱动系列支持的 CUDA 版本上限为 CUDA 10.1 ,同时也能向下兼容较旧的 CUDA 版本,像 CUDA 9.x 等。
2. nvidia-driver-470
该驱动系列支持 CUDA 11.4 至 CUDA 11.7 。能较好适配基于 CUDA 11 系列开发的应用程序。
3. nvidia-driver-510
支持 CUDA 11.6 到 CUDA 11.8 。此驱动版本是 CUDA 11 系列持续优化阶段的产物,可确保在这些 CUDA 版本下硬件的稳定运行。
4. nvidia-driver-515
支持 CUDA 11.7 到 CUDA 11.8 。是从 CUDA 11 系列向更新版本过渡阶段的重要驱动版本,对 CUDA 11 的后期版本兼容性良好。
5. nvidia-driver-525
支持 CUDA 12.0 及部分后续版本。它是为适应新的 CUDA 12 架构和特性而推出的驱动版本,开始支持 CUDA 12 引入的新功能。
6. nvidia-driver-530
支持 CUDA 12.1 及后续部分版本。随着 CUDA 技术的发展,该驱动进一步适配了新的 CUDA 特性和优化。然后安装PyTorch记住要安装GPU版本的
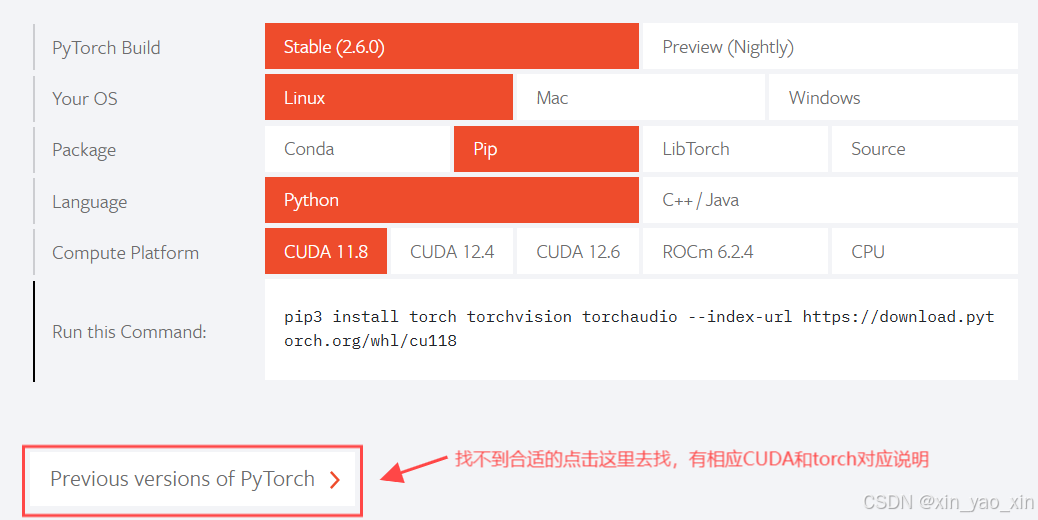
在虚拟环境中想要测试是否安装成功,不能使用nvcc -V命令测试,需要在虚拟环境中安装pytorch包进行测试。
# 虚拟环境中,进入python环境
import torch
# 查看pytorch版本
print(torch.__version__)
# cuda是否可用
print(torch.cuda.is_available())
# cuda版本
print(torch.version.cuda)
# cudnn版本
print(torch.backends.cudnn.version())运行测试
这时候尝试启动一下(web界面方式)
llamafactory-cli webui这时候可能会报一个错误:llamafactory-cli: command not found
执行这个
pip install -e .[metrics]再运行一下,就能看到web界面了。
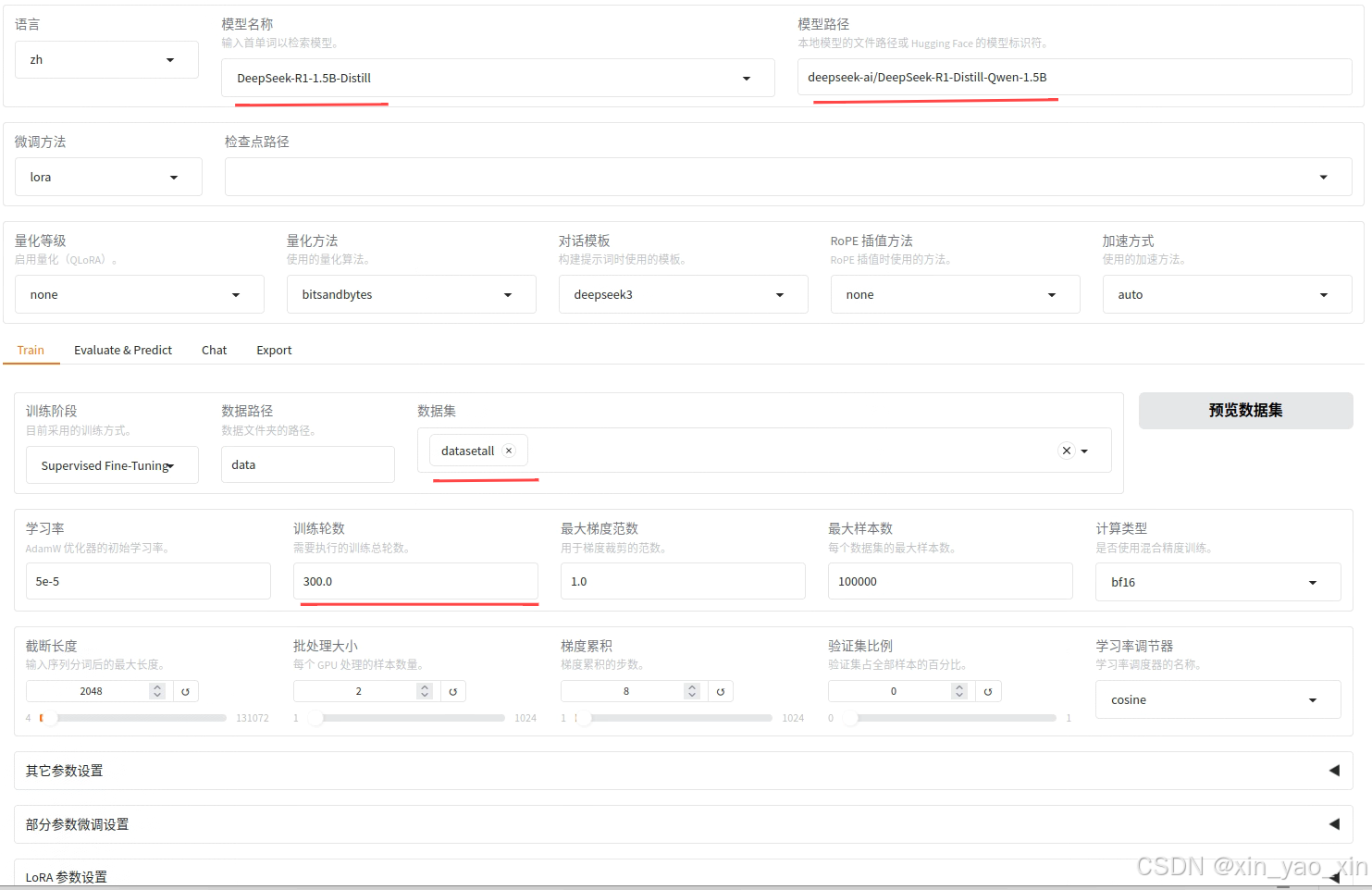
但注意执行前要注意一下自己内存,nvidia-smi,不然可能因内存不足启动失败
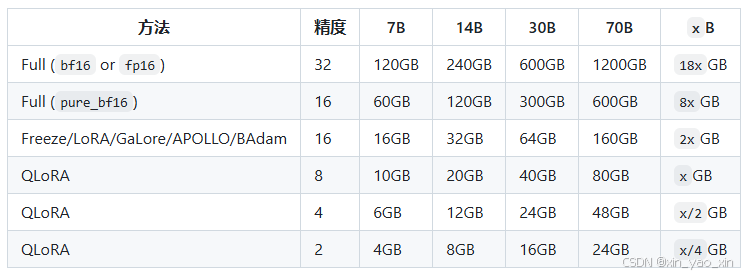
自定义数据集
具体用什么数据集要看自己的具体需求,我采用的是Alpaca 格式,需要将配置文件放到data目录下,并在dataset_info.json文件中添加数据集路径,详情参考下方链接:
参考链接:LLaMA-Factory|微调大语言模型初探索(2),训练自己的聊天机器人_ai 训练 数据集 参数 说明 "instruction":"","input":"""output-CSDN博客
如果数据集是sharegpt ,那数据集格式比较严格,在dataset_info.json文件中添加
示例:这是在dataset_info.json中添加格式
"dataset_name": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}
# system和tools是可选的,可以不添加示例:这是sharegpt 格式数据集,必须符合格式,不然运行报错
[
{
"conversations": [
{
"from": "human",
"value": "human instruction"
},
{
"from": "function_call",
"value": "tool arguments"
},
{
"from": "observation",
"value": "tool result"
},
{
"from": "gpt",
"value": "model response"
}
],
"system": "system prompt (optional)",
"tools": "tool description (optional)"
}
]
# 用户和模型键值必须是 "from": "human" 和 "from": "gpt"不然也报错,具体看说明,同样system和tools
也可选,但必须和dataset_info.json中匹配参考链接:
https://github.com/hiyouga/LLaMA-Factory/tree/main/data
开始微调
设置完自定义数据集后稍微调整参数,开始微调,注意微调时本地无模型时会先下载模型,速度很慢,建议先下载到本地。
模型下载地址,这是国内镜像,下载很快:
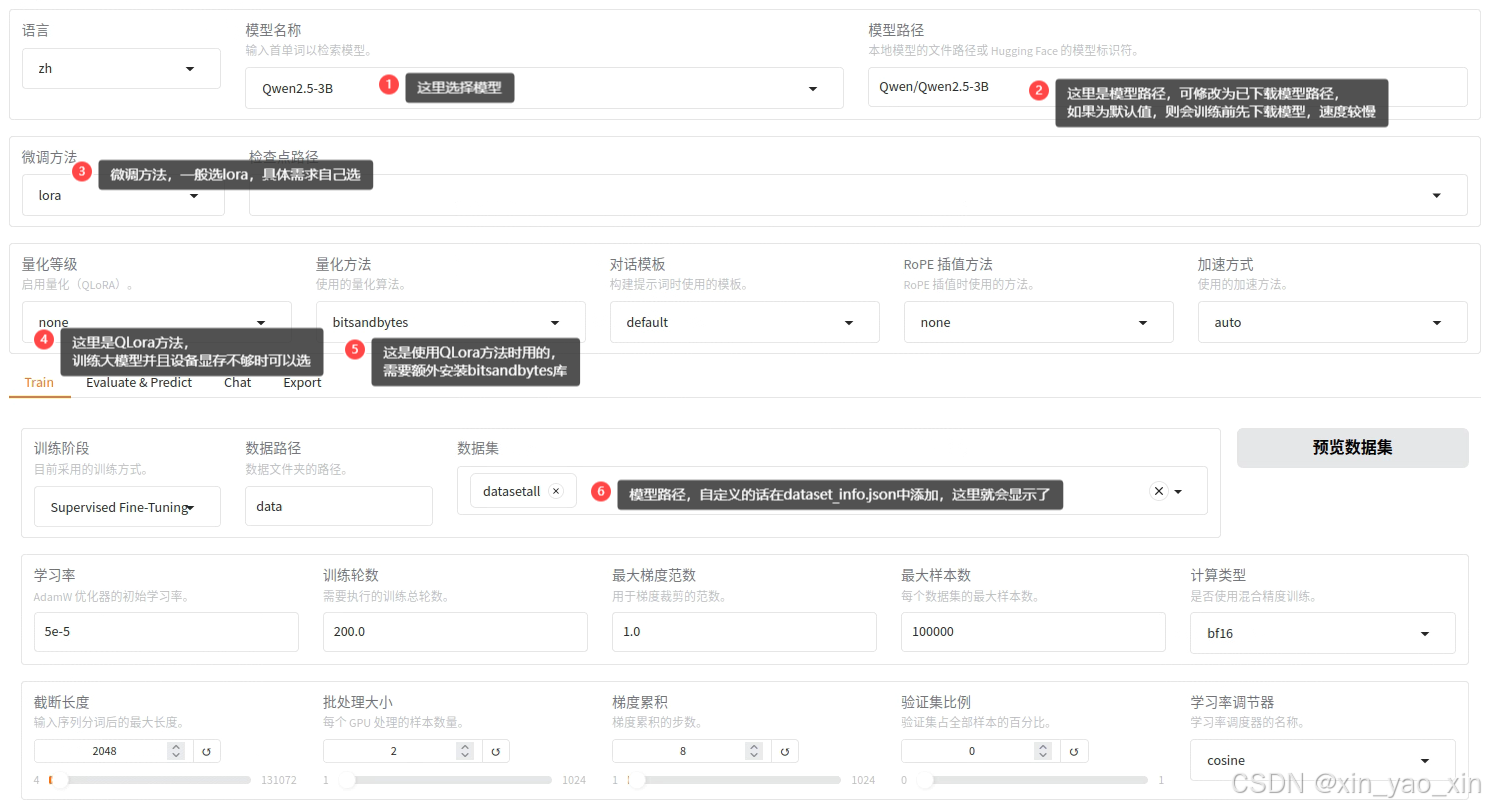
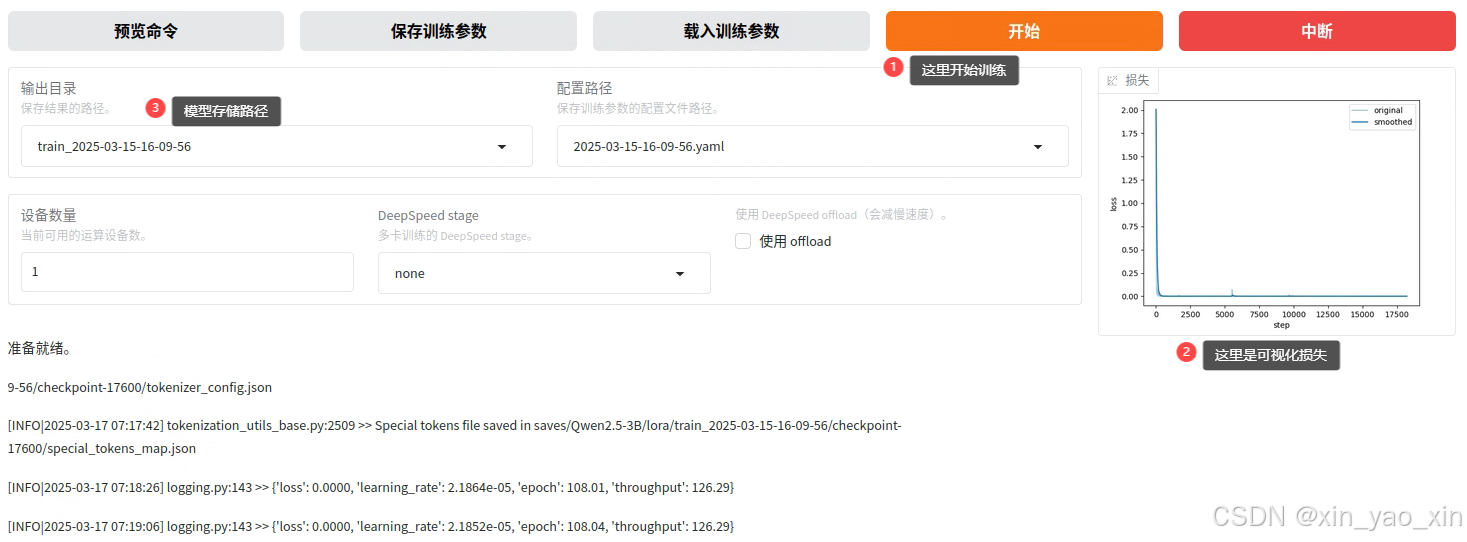
微调完后就能看到“存储的目录”,这整个文件夹是整个微调后的模型
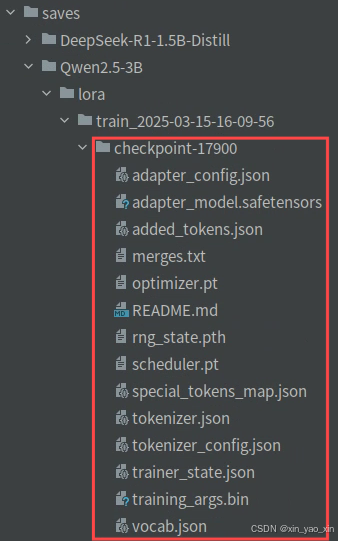
微调后模型合并
把训练的LoRA和原始的大模型进行融合,输出一个完整的模型文件
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path xxx/xxx/xxx \ #原始大模型所在文件夹路径
--adapter_name_or_path xxx/xxx/xxx \ #微调后大模型所在文件夹路径
--template llama3 \
--finetuning_type lora \ #微调类型
--export_dir megred-model-path \ #合并后模型存储路径
--export_size 2 \
--export_device cpu \
--export_legacy_format False合并完是这样的
参考链接:
ollama调用微调后的模型
方法一:使用Llama.cpp
通过LlaMA-Factory导出的模型与Ollama所需格式有区别,需要借助Llama.cpp的代码进行转换。
仓库地址:https://github.com/ggerganov/llama.cpp
安装依赖
pip install -r requirements.txt转换命令
python convert_hf_to_gguf.py xxx/xxx/xxx \ #上面转换完模型路径
--outfile /xxx/xxx/xxx.gguf \ #要导出的gguf文件路径和名称
--outtype q8_0 #模型精度:可选f32/f16/q8_0等
运行代码后会把safetensors格式转换为gguf格式,接下来创建Modelfile,用于将模型导入Ollama中,Modelfile文件中写下面内容,gguf文件所在路径:
FROM /xxx/xxx/xxx.gguf在ollama中创建模型:
ollama create model_name -f /path/to/Modelfile查看模型是否创建:
ollama list创建成功就会看到你创建的模型名称。
方法二:使用LLaMA-Factory的export(推荐)
这相当于微调后模型合并和调用微调后的模型的结合版,更方便快捷
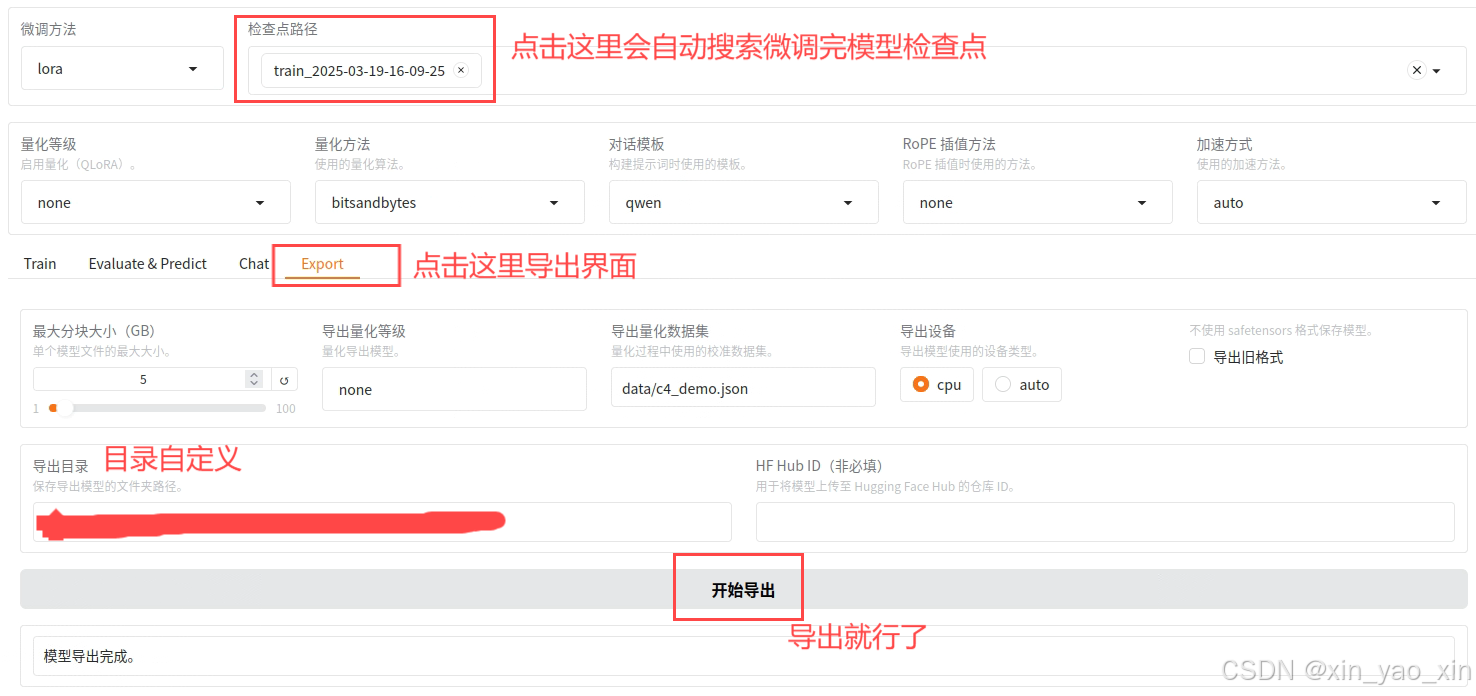
导出完模型,已经自动生成Modelfile文件了,可被ollama直接添加
然后在ollama中创建模型就行了
ollama create xxx_name -f ./Modelfile #xxx_name是自定义模型名字
参考链接:
LLaMA-Factory+Ollama:本地部署大模型流程详解-CSDN博客
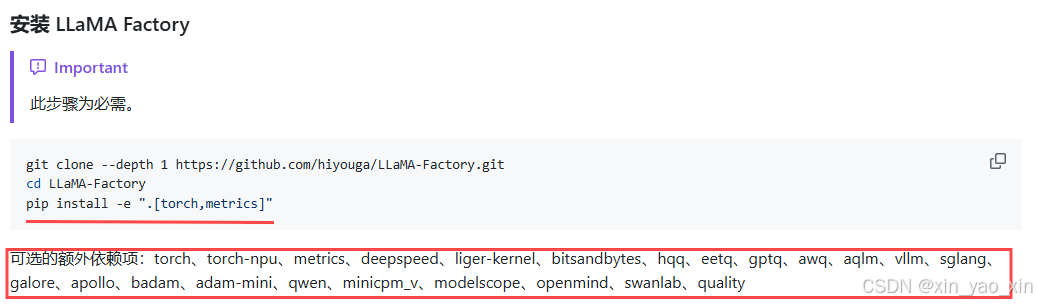
llama-factory其余参数使用时库安装
例如:bitsandbytes等,需要安装库,还是建议用:
pip install -e .[bitsandbytes]自己安装非常容易出现,各库之间不兼容,或是与cuda版本不兼容。


















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











