







量化是一种以参数或****计算中间结果精度下降换空间节省(以及同时带来的性能提升)的策略。对模型进行量化。主要包括 KV Cache 量化和模型参数量化。
-
KV Cache 量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。
- 计算 minmax。主要思路是通过计算给定输入样本在每一层不同位置处计算结果的统计情况。
- 对于 Attention 的 K 和 V:取每个 Head 各自维度在所有Token的最大、最小和绝对值最大值。对每一层来说,上面三组值都是
(num_heads, head_dim)的矩阵。这里的统计结果将用于本小节的 KV Cache。 - 对于模型每层的输入:取对应维度的最大、最小、均值、绝对值最大和绝对值均值。每一层每个位置的输入都有对应的统计值,它们大多是
(hidden_dim, )的一维向量,当然在 FFN 层由于结构是先变宽后恢复,因此恢复的位置维度并不相同。这里的统计结果用于下个小节的模型参数量化,主要用在缩放环节
-
4bit Weight 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。
-
Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
1 创建环境
# 创建环境
conda create -n lmdeploy --clone /share/conda_envs/internlm-base
# 激活环境
conda activate lmdeploy
# 安装packaging
pip install packaging
# 安装flash_attn
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
# 安装lmdeploy
pip install 'lmdeploy[all]==v0.1.0'
- 创建conda环境
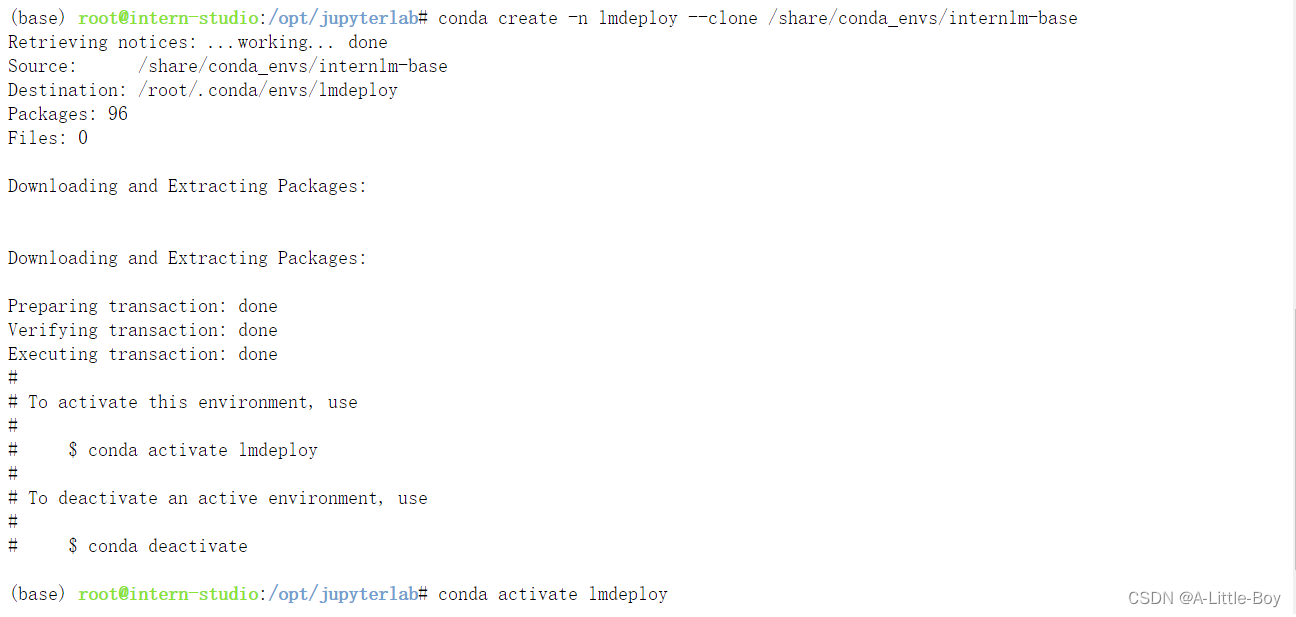
【问题1】缺少packaging包
pip install packaging
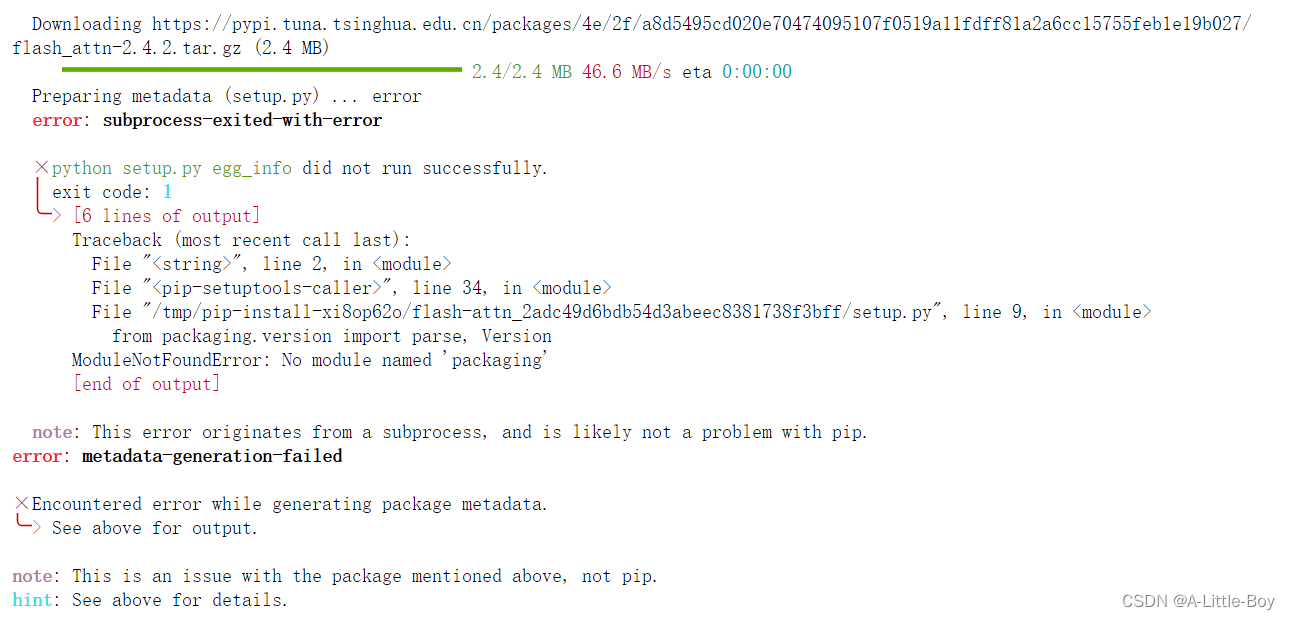
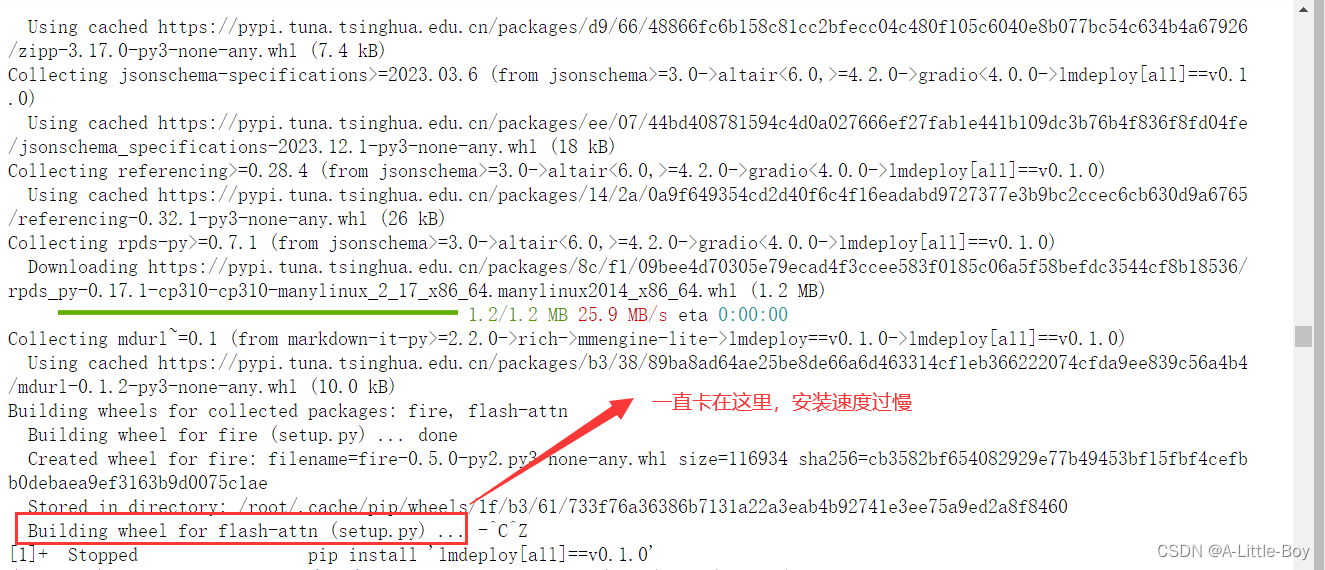
【问题2】安装速度过慢
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
2 模型转换
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。
在线转换可以直接加载 Huggingface 模型,离线转换需需要先保存模型再加载。以下以离线转换为例。
cd /root/
mkdir lmdeploy_demo && cd lmdeploy_demo
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/

执行完成后将会在当前目录生成一个 workspace 的文件夹。
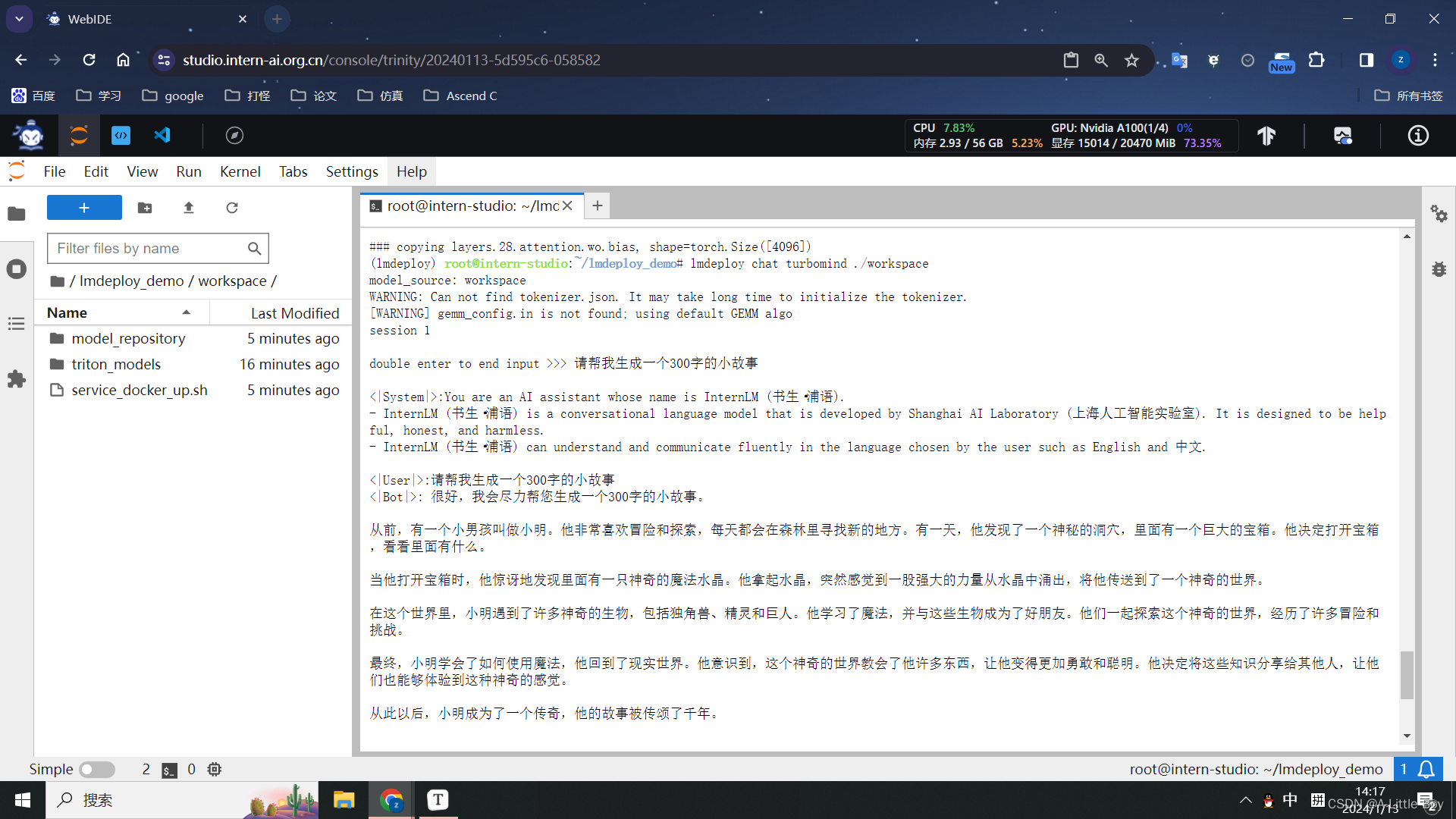
3 命令行本地对话
lmdeploy chat turbomind ./workspace
4 API服务
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 2
server_name 和 server_port 分别表示服务地址和端口;tp表示 Tensor 并行;instance_num 参数,表示实例数。
lmdeploy serve api_client http://localhost:23333
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p [端口号]
5 网页Gradio
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True














 239
239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









