








 本文详细阐述了计算机组成原理中的存储器技术,包括局部性原理、SRAM、DRAM、闪存和磁盘,以及数据校验方法如奇偶校验和汉明校验。重点介绍了Cache的基本原理,包括命中和缺失概念、直接映射与组相联的区别,以及虚拟存储器的概述。
本文详细阐述了计算机组成原理中的存储器技术,包括局部性原理、SRAM、DRAM、闪存和磁盘,以及数据校验方法如奇偶校验和汉明校验。重点介绍了Cache的基本原理,包括命中和缺失概念、直接映射与组相联的区别,以及虚拟存储器的概述。
本文目录
前言
本系列文章将梳理《计算机组成原理》这门课的相关知识点,教材使用的是《计算机组成原理:硬件/软件接口》MIPS版,原书第五版。本文所属章节为存储器章节,重点内容为Cache的基本原理和相关计算。
一. 局部性原理与相关术语
提高存储器性能的基本思路:利用局部性原理构建存储器层次结构。
- 时间局部性:如果某个数据被访问,那么在不久后的一段时间,它极有可能再次被访问。
- 空间局部性:如果某个数据被访问,那么与它地址相邻的数据极有可能也会被访问。
- 存储器层次结构:存储器的容量和访问时间随着离处理器的距离增加而增加。

- 三级存储结构:高速缓存-内存-外存
- 内存-外存:为了增大容量。构成虚拟存储器。
- Cache-内存:为了提高速度。构成主存储器。
- 相关术语:
- 命中率:在高层的存储器中找到所需数据的存储访问比例。
- 缺失率:在高层的存储器中没有找到所需数据的存储访问比例。
- 命中时间:访问高层存储器需要的时间(包含判断是否命中所需的时间)
- 缺失代价:命中缺失后,将低层次存储器中的数据替换到高层次存储器需要的时间。
- 平均访存时间(AMAT) = 命中时间 + 缺失率 * 缺失代价
- 可靠性和可用性的术语:
- 可靠性:一个系统持续为用户提供服务的能力。
- 平均无故障时间MTTF:从开始时间到失效时间的时间间隔。
- 平均维修时间MTTR:恢复一个系统所用的时间。
- 平均失效间隔时间MTBF = MTTF+MTTR
- 可用性:MTTF / MTBF,即无故障时间的比率。
二. 存储器技术(了解)
1. SRAM技术
- 原理:双稳态触发器。组织成存储阵列结构,采用随机存取的方式,对任何数据访问时间固定。
- 特点:速度快,无需刷新,价格贵,用于二级cache
2. DRAM技术
- 原理:依靠电容存储电荷。
- 特点:需要刷新,而且是按行刷新;用于内存。
3. 闪存
- 原理:电可擦除可编程只读存储器
- 特点:在线擦除和重写
4. 磁盘
- 一个磁盘包含一组圆形盘片
- 每个盘片有几万条磁道,他们是同心圆环。
- 每个磁道被划分为几千个扇区。每个扇区容量为512-4096字节。
- 每个盘片都有两个面,每个面都有一个磁头。
判断题:每个扇区通常包含一个磁头,对吗?
解答:错误。这是两个不同概念。应该是每个盘片有两个磁头。
三. 数据校验方法
数据校验的原理:在合法的数据编码之间,加进一些额外的编码,使合法的数据编码出现错误时成为非法编码,通过检测编码的合法性达到发现错误的目的。
1. 码距的概念
- 码距,又叫汉明距离,码距和查错纠错能力之间有着密切的联系。
- 如果码距d为奇数,能发现d-1位错误,或者能纠正(d-1)/2位错。
- 如果码距d为偶数,能发现d/2位错误,或者能纠正d/2-1位错。
- 常见的码距(重点):
- 普通二进制数:d=1,啥都干不了。
- 奇偶校验码:d=2,能发现1位错误,但是无法纠错。
- 汉明校验码:d=3,能发现2位错误,能纠正1位错。
2. 奇偶校验
- 概念:奇偶校验是在被传送的n位数据加上1位二进制位作为校验位,使得配置后的n+1位二进制代码中1的个数为奇数(奇校验码)或者偶数(偶校验码)。
- 例子:01110101的有奇数个1,其奇校验码是在最后加个0,其偶校验码是在最后加个1,即加上校验码后为奇数/偶数。
- 原理:异或门,如下图所示。
- 奇偶校验只能发现奇数个错误,不能发现偶数个错误。
- 只能说明有一位出错,无法指出出错位数是谁,因此无法纠错。
- 适合场景:距离CPU比较近等出错几率比较低的场景。
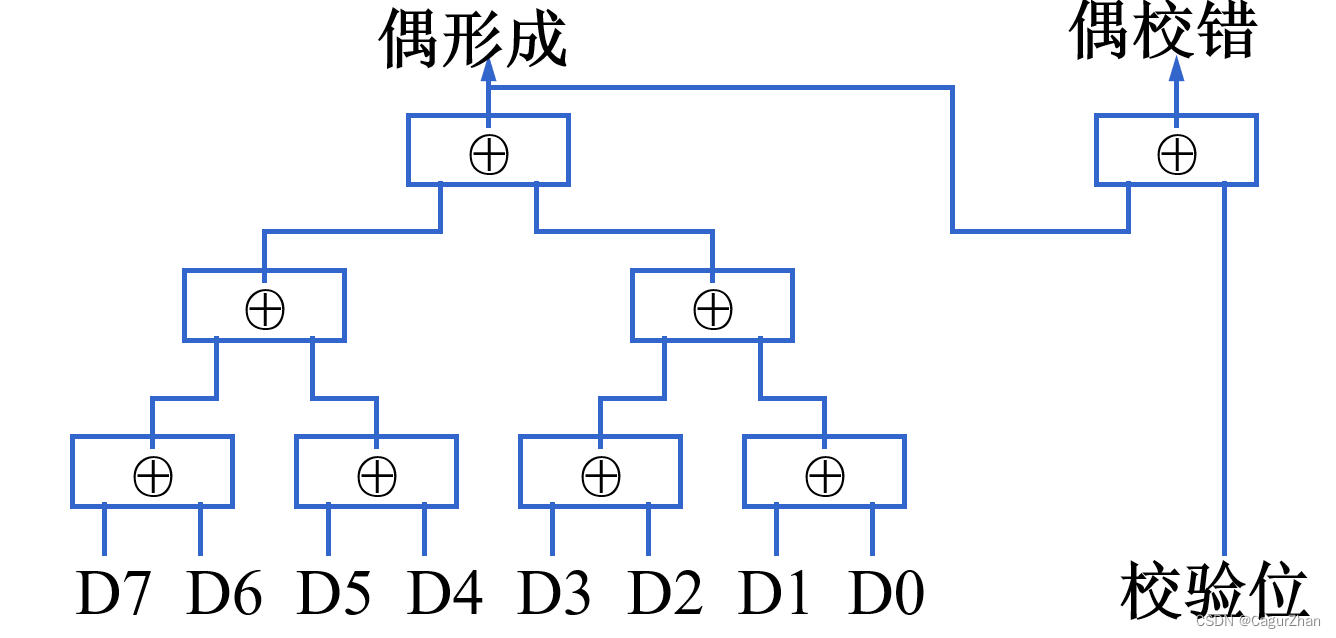
3. 汉明校验
这块内容只是看文字比较抽象,建议配合下方的手写版一起看,并且自己多画几遍。
- 实质:多重奇偶校验。
- 内容:将N位的校验码分成 k位有效信息 + r位校验信息,一共分成r组进行奇偶校验,产生出r个检错信息。显然,这r位的检错信息可以构成 2 r 2^r 2r种状态,其中全0表示无错,剩余的 2 r − 1 2^r-1 2r−1种状态可以指出哪一位出错了。即: N = k + r < = 2 r − 1 N=k+r <=2^r-1 N=k+r<=2r−1
- 案例:k=4,那么 N = 4 + r < = 2 r − 1 N=4+r <=2^r-1 N=4+r<=2r−1,所以r=3。也就是说,4位有效信息需要3位的校验位。
- 一般来讲,有效信息和校验位的位置有下面关系:

- 分组规则:以2的n次方作为校验位。剩下的作为有效信息。
- P1:最后一位是1.
- P2:倒数第二位是1.
- P3:倒数第三位是1,以此类推。
例如,第一组从1开始,每隔1个画一次;第二组从2开始,画2个,每隔2个画一次;第三组从4开始,画4个,每隔4个画一次。

3.1 手写案例辅助理解汉明校验码
下面是一个手写的求汉明校验+检错的案例,帮助读者理解汉明校验码。

3.2 改进汉明校验码:实现检测2位错
前面的汉明校验码只能实现1位的差查错和纠错。那么如何做到纠正1位错和检测2位错呢?
- 改进方法:增加1位奇偶校验码,对整个字进行校验。案例如下:

令我们的汉明校验结果H=G1G2G3,整字校验结果为G4,H=0表示前7位没错误,H不等于0表示至少1位出问题。
- H=0并且G4为偶数:表示没有错误。
- H=0并且G4为奇数:P4出了问题。
- H不等于0并且G4为奇数:出现了一位可纠正错误。
- H不等于0并且G4为偶数:出现了两位错误。
四. Cache的基本原理
1. 命中和缺失的基本概念
- 命中:CPU访问内存的时候,会优先询问cache,而不是直接去询问内存。如果数据在cache中,就称之为一次命中。
- 缺失:如果程序要跳转到很远,cache不包含所需的数据,CPU则需要去访问比较慢的内存,这产生一次cache缺失。
2. 基本原理
Cache需要解决四个问题:
- 映射规则:一个块调入cache,放在哪?
- 查找算法:如何判断要找的数据在cache中,如何查找到它?
- 替换算法:发生缺失的时候,应该替换谁?
- 写策略:写访问的时候,应该进行什么操作?
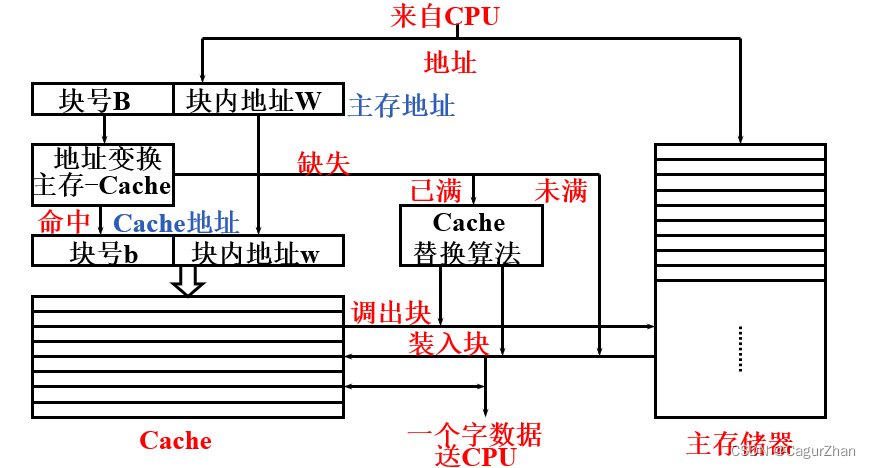
3. 直接映射法
直接映射法:每个内存地址仅仅对应到Cache中的一个位置。如下图所示
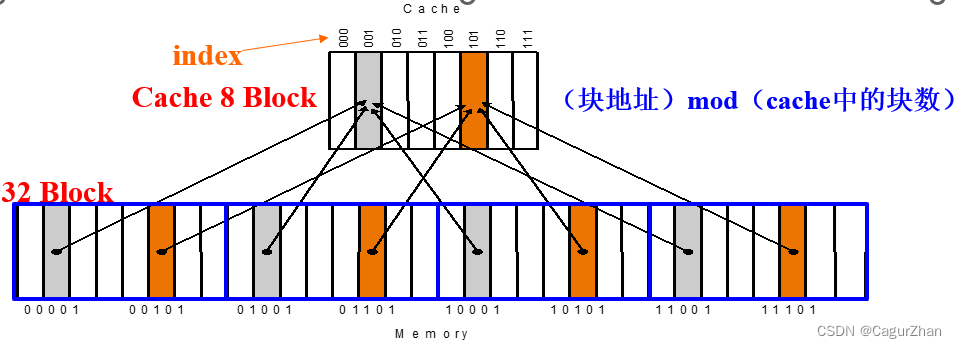
- 方法:块地址 mod 块数
- Cache的地址 = 标记位Tag + 索引位Index + 偏移位
- Cache存放的数据:有效位+标记位+数据,如下图所示。
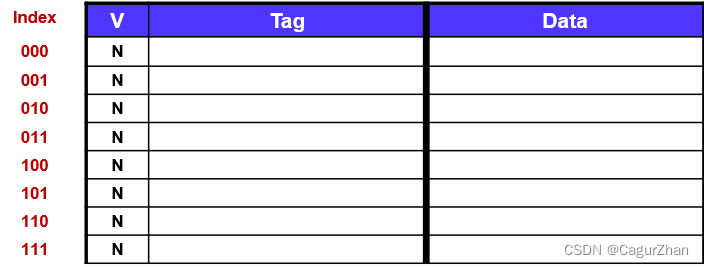
综上,直接映射的Cache结构图如图所示,地址的索引位同时存放于cache中,只有当索引位和有效位都满足的时候,才算一次命中。

- 直接映射法的优点:硬件实现简单,只需要比较标记位,速度快**
- 直接映射法的缺点:空间利用率低,每个内存只能映射到唯一的地址;块冲突率高。
3.1 直接映射法的计算
下面给出一些常见公式:
- Cache总位数=(块大小 + 标记位 + 有效位) x 总块数
- 标记位 = 地址位 - 索引位 - 字节偏移位
- 字节偏移位 = 块大小转换为二进制的指数
例1:一个直接映射的cache,可装16KB的数据,块大小为4个字,内存地址为32位,那么该cache总共需要多少位?
分析:Cache的块大小一般指的是数据部分的大小。所以Cache总位数=(块大小 + 标记位 + 有效位) x 总块数
解答:
先求总块数。数据总容量16KB,每个块4个字,所以块数 = 16KB / 16B = 1024
再求标记位。标记位 = 地址位 - 索引位 - 字节偏移位。
对于索引位,由于1024个块,所以需要10位的索引位。
对于字节偏移位,块大小有16KB,即2^4,所以字节偏移位是4.
综上,tag = 32 - 10 - 4 = 18
块大小呢?每个块4字 x 32位 = 128位
综上,总位数 = (128 + 18 + 1) x 1024 = 18.4KB
例2:假设一个cache中有64个块,每块大小为16 字节,采用直接映射。那么主存1200号单元所在主存块将被映射到cache中的哪一块?
解答:
块地址= 字节地址 ÷ 每块字节数 =1200/16=75
Cache块号 = 块地址 mod 块数 = 75 mod 64 = 11
所以映射到第11块。
注意:块地址= 字节地址 ÷ 每块字节数为向下取整,如字节地址为1211的数据,块地址仍为75。
4. 缺失分类的3C模型
- 冷启动强制缺失:首次访问cache的必然缺失。
- 容量缺失:cache不够放导致部分块被替换后再次被写入到cache。
- 冲突碰撞缺失:多个内存块竞争映射到一个cache块,导致仍需要使用的块被替换。
缺失可以分为两类:
- 指令缺失:
- 将PC-4送到存储器。
- 通知内存执行一次读操作。
- 写cache,设置有效位。
- 重新取指。
- 数据缺失:基本类似。
5. 写策略
- 写直达法:当CPU进行写操作时,在写Cache的同时也将内容写入到相应的主存单元中,即两个内容同时改写。
- 写回法:当CPU写数据时,只写Cache,不写主存;当已改写的块被替换出Cache 时,将其内容写回主存。
比较这两种方法:前者保证了数据的一致性,需要较多的buffer来存放这些数据。后者可以减少对主存的访问,更加快速,需要多个校验位。
6. 全相联和组相联
6.1 全相联映射
前面讲到的直接映射,指的是一个内存块映射到唯一的cache块,实现比较简单。而全相联映射,指的是内存块可能映射到任何一个 cache块。
这个很像哈希算法中的开放寻址法,具体而言,第一个内存块随意进入cache,只要没有满,后面的块可以见缝插针,而如果满了,则替换掉最长时间没有使用过的内存块,这种替换算法称之为最近最少使用(least recently used, LRU)
- 优点:要使用的块更不容易被替换出去,缺失率较低。
- 缺点:全相联没有索引位,全相联中的碰撞缺失实际上转换为了容量缺失。每次比较,需要将Tag位和每一块标记位进行比较,有点像顺序遍历,开销较大, 适合块数减少的cache。
6.2 组相联映射
既然如此,我们可以折中一下,开发出一种组相联的映射方法。
我们对cache进行分组,一个内存块首先直接映射到cache中的一个组,但是在组的内部是全相联映射,这种映射策略称之为组相联映射。
所谓n路组相联,指的就是一组包含n块,其相联度为n。实际上,直接映射可以理解为1路组相联。而全相联映射可视为相联度=块数的组相联
Q:组相联中的内存映射到哪组?
A:cache组号 = 内存块号 % cache组数, 2 n 2^n 2n组的cache,cache组号 = 内存二进制块号的后n位
4路组相联的原理图如下:在下图中,索引数是255,所以索引位是8位;而偏移位置是2位,剩下22位是标记位。查找Cache命中的过程,就是先根据索引位定位到某一组,再遍历组内的块,依次比较tag是否相等,如果相等,并且有效,就是命中。
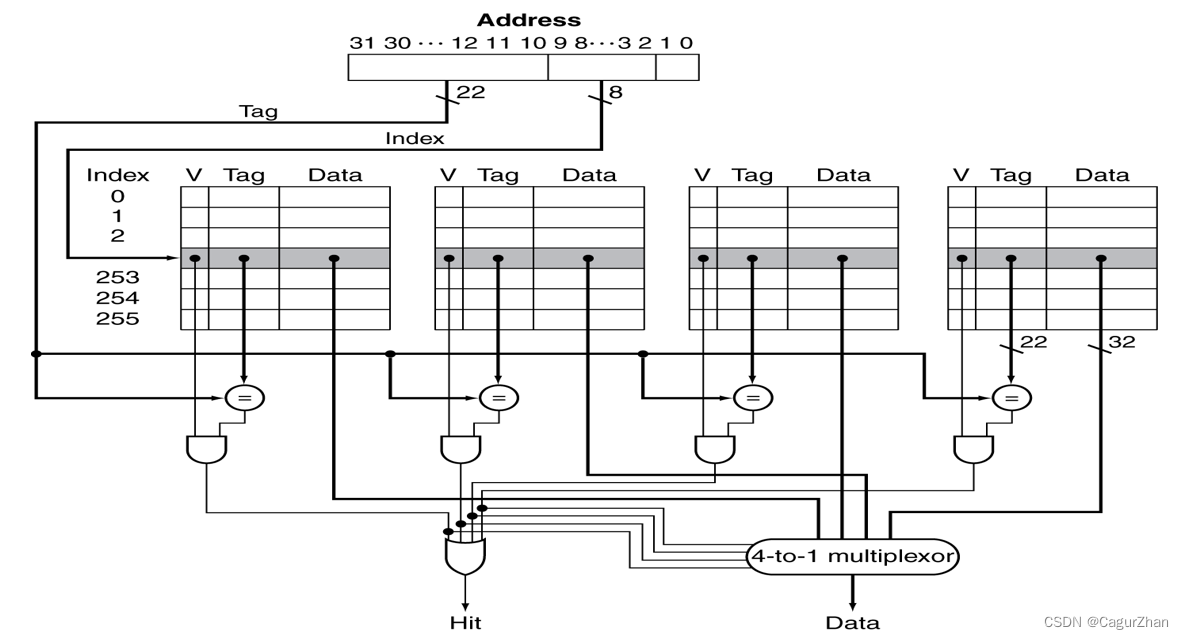
实际上,随着相联度提高,cache块更不容易产生碰撞缺失。全相联更是将这种可能性降到最低,但是提高相联度也意味着每次访问cache时,比较标记位、选择数据的开销增大,所以实际的cache相联度通常只有2、4,各类映射方式的比较如下:
- 直接映射:查找速度最快,命中时间最短,但缺失率最高。(快,但是找多次)
- 全相联映射:缺失率最低,但查找速度最慢,命中时间最长。(慢,但是找少次)
- 组相联映射:介于两者之间。
6.3 组相联的缺失处理和写策略
全相联和组相联的缺失过程和直接映射相同,都能用写直达和写回两种写策略。
如果某组已经被其它内存块占满,那么新取入的块如何处理?
在直接映射方式下,不存在块替换的算法,因为每一块的位置映象是固定的,需要哪一块数据就可直接确定地将该块数据调入上层确定位置。
而其他两种映象就存在替换策略的问题,就是要选择替换到哪一个Cache块。置换策略直接影响Cache—主存体系的命中率,我们一般记录历史使用状况,选择最久没被使用的块被替换,即LRU法。
做法:
我们可以用1位来编号记录2路组相联中最久没被使用的块,用2位来编号记录4路组相联一组最久没有使用的块,以此类推,这个编号叫做LRU位
实际上LRU的开销仍然较大,很多4路组相联的系统只是近似实现LRU
6.4 组相联相关的Cache计算题
例题:对于具有2GB主存,128KB高速缓存的32位MIPS机器,块大小为64B,当CPU访问内存地址为01000000 00010001 00001011 10000101时,如果高速缓存采用直接映射的话,此地址映射到Cache的行号是多少?如果高速缓存采用2-Way(每行2块)组相联映像的话,此地址映射到Cache的行号又是多少?
解答:
字节偏移位:块大小是64B,即 2 6 2^6 26,所以字节偏移位为6位。
块数 = 128KB / 64B = 2 11 2^{11} 211,所以索引位为11位。
因此,第一问:行号就是第6位到第18位。即1 00001011 10
如果是二路组相联,那么块数 = 128KB / (64 B *2) = 2 10 2^{10} 210,所以索引位是10位。
可以看出,对于计算题,相联度实际上影响了块数的计算,即索引位的计算。
- CPU时间 = ( CPU执行时钟周期数+存储器阻塞的时钟周期数) ×时钟周期
- 存储器阻塞的时钟周期数=存储器访问次数×缺失率×缺失代价
例题:在某任务中访存指令占20%,不考虑Cache缺失时处理器的平均CPI为2;如果指令Cache缺失率为1%,数据Cache缺失率为5%,缺失代价为120个时钟周期,请计算具备Cache缺失时的平均CPI为多少?
解答:
假设总指令数是P
那么指令缺失引起的阻塞时钟周期数 = 0.01xPx120 = 1.2P(每条指令是指令访存)
数据缺失引起的 = 0.2xPx0.05x120=1.2P(多了个20%)
总阻塞周期数 = 2.4P,所以平均CPI = (2P+2.4P)/ P = 4.4
五. 虚拟存储器
本节主要讲解TLB和页表相关的知识点,因为我校期末考试暂时不考察,因此偷个懒暂时不写了,有需要的读者可以前往Bilibili观看Up主翼云图灵的讲解视频或者查看黑书原文,感谢观看。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









