






原文:https://blog.csdn.net/wyhz56/article/details/95777651
本文仅为翻译手册,留以自己查看,若需要深入交流,可以在个人分类中查找解析与实践内容(可能未发布),或与作者联系
概述
SRIO KeyStone设备中使用的RapidIO外设称为串行RapidIO(SRIO)
RapidIO是一种非专有的高带宽系统级互连。它是一种分组交换互连,主要用作以每秒千兆字节性能级别进行芯片到芯片和板对板通信的系统内接口。该架构可用于连接的微处理器,内存和内存映射的I / O设备,这些设备在网络设备,内存子系统和通用计算中运行。
RapidIO被定义为三层架构层次结构。
•逻辑层:指定端点处理事务所需的协议,包括数据包格式。
•传输层:定义寻址方案以在系统内正确路由信息包。
•物理层:包含设备级接口信息,例如电气特性,错误管理数据和基本流量控制数据。
在RapidIO架构中,传输层的一个规范与逻辑层和物理层的不同规范兼容。
意指 SRIO协议中,仅有传输层的协议时不变的,逻辑层与传输层的规范可以通过实际情况来做出改变。
逻辑层: I/O SYSTEM、Message Passing、Globally shared memory
物理层:8/16LP-LVDS、1x/4xLP Serial
笔者在此暂定使用IO system 4x LP Serial 协议
SRIO使用互连体系
独立于物理层实现的分组交换协议,类似于串行总线?
物理层接口协议
8/16 LP-LVDS规范是点对点同步时钟源DDR接口
1x / 4x LP-Serial规范是一种点对点交流耦合时钟恢复接口。(SerDes 串行器/解码器技术)
RapidIO物理层1x / 4x LP-Serial规范目前涵盖四个频率点:1.25,2.5,3.125和5 Gbps。这定义了每个差分对I / O信号的总带宽。一个8位/ 10位编码方案确保时钟恢复电路有足够的数据转换。由于8位/ 10位编码开销,每个差分对的有效数据带宽分别为1.0,2.0,2.5和4 Gbps。串行RapidIO仅为1x和4x端口指定这些速率。1x端口定义为一个TX和一个RX差分对。4x端口是这些对中的四个的组合。本文档描述了一个4x RapidIO端口,也可以配置为4个1x端口;这提供了一个可扩展的接口,能够支持1到16 Gbps的数据带宽。
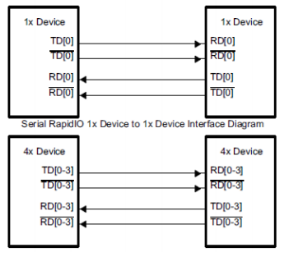
SRIO 功能支持
符合LP-Serial规范REV2.1.1
•具有4X Serial RapidIO
- 1X端口,(4)1X端口的可选操作
- 2X端口,(2)2X端口的可选操作
- 2X端口和1X端口操作,(1)2X端口和(2)1X端口的可选操作
- 4个端口,操作(1)4x端口
•采用TI SerDes的集成时钟恢复 ?
•能够以不同的波特率运行不同的端口(仅支持整数倍速率:支持2.5G和5G,不支持3.125G和5G)
•硬件错误处理,包括CRC
•支持AC和DC耦合的差分CML信号
•支持1.25,2.5,3.125和5 Gbps速率
•未使用端口的Powerdown选项
•读取,写入,写入响应,流式写入,外出的Atomic,维护操作 //Atomic??
•CPU的中断生成(Doorbell数据包和内部调度)
•支持8b和16b设备ID
•支持接收34b地址
•支持生成34b,50b和66b地址
•支持数据大小:字节,半字,字,双字
•定义为Big Endian
•直接IO传输
•消息传递传输
•数据有效负载为256B
•单个消息生成最多16个数据包
•用于时钟域切换的弹性存储FIFO
•符合短期运行和长期运行
•支持错误管理扩展
•支持拥塞控制扩展
•支持多播ID
•支持短控制符号和长控制符号
•支持IDLE1序列,最大波特率为5 Gbps
•基于优先级和CRF,跨协议单元进行严格的优先级段交织
以下功能不支持
•符合全球共享内存规范(GSM)
•兼容8/16 LP-LVDS
•RapidIO原子操作的目标支持
Long run和Short run
长期规范适用于长背板应用,具有至少50厘米的迹线和两个或更多连接器。
短期规范专为低功耗应用而设计。它通常用于同一板上的链路或短背板连接。
两个类之间的区别是驱动程序的Vod。 //VOD??暂定硬件问题
Atomic operations
L2存储器不满足
主要包括递增递减测试交换
DATA FLOW
SRIO可以作为主机的接受端,外部设备可以突发写入DSP,可以不必向CPU产生中断,不依赖与EDMA
数据包的最大值为256字节,每条消息最多16个包,每个包产生一个请求(DMA将数据传到L2),但是只有消息发完才会产生中断。
SRIO也可以作为端点设备,通过DestID与DeviceID匹配来接受包,也可以通过广播的形式
广播设置:使用RapidIO Multicast ID寄存器
数据流图
高速数据通过SerDes解码,SerDes需要一个低频参考时钟,数据速率的1/10或1/20,该时钟由片上晶振提供
S2P模块将数据分解服用为10位或20位字
20位SerDes模块支持5G
随后 数据进入8b/10b解码块,在此删除了20%的编码,因此数据传输的速率为80%
下一步是时钟同步和数据对齐。这些功能由FIFO和通道去偏移块处理。FIFO提供弹性存储机制,用于在恢复的时钟域和公共系统时钟之间进行切换,FIFO深8字。
CRC在此进行错误校验
在分组到达逻辑层之后,分组字段被解码并且有效载荷被缓冲。
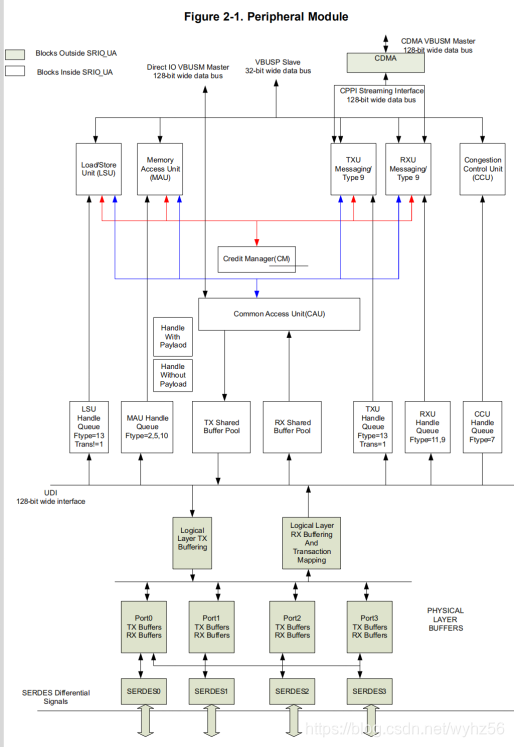
根据接收数据包的类型,数据包路由由控制DMA访问的功能块处理。下图显示了这些块。
加载/存储单元(LSU)控制直接I / O数据包的传输,
存储器访问单元(MAU)控制直接I / O数据包的接收。
LSU还控制维护包的传输。
消息包由TXU发送并由RXU接收。
这四个单元使用内部DMA与内部存储器通信,它们使用缓冲区和接收/发送端口与外部设备通信。
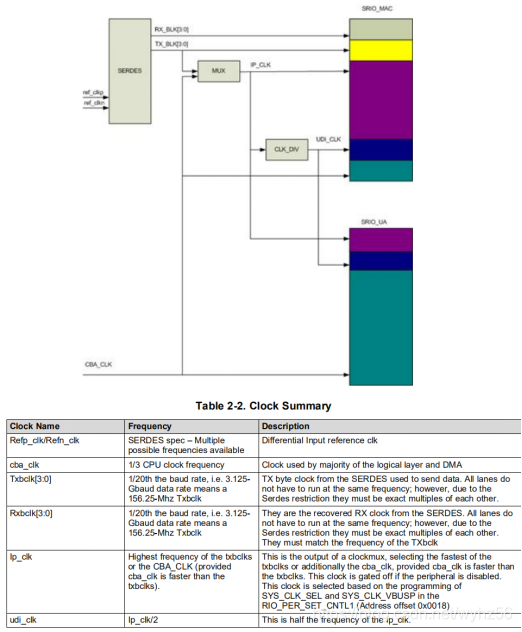
总配置时钟图
在此暂不赘述
包结构
RapidIO数据流由与逻辑层,传输层和物理层有关的数据字段组成。
•逻辑层由标头(定义访问类型)和有效负载(如果存在)组成。
•传输层在某种程度上取决于系统中的物理拓扑,包括发送和接收设备的源ID和目标ID。
•物理层依赖于物理接口(例如串行与并行RapidIO),并包括优先级,确认和错误检查字段。
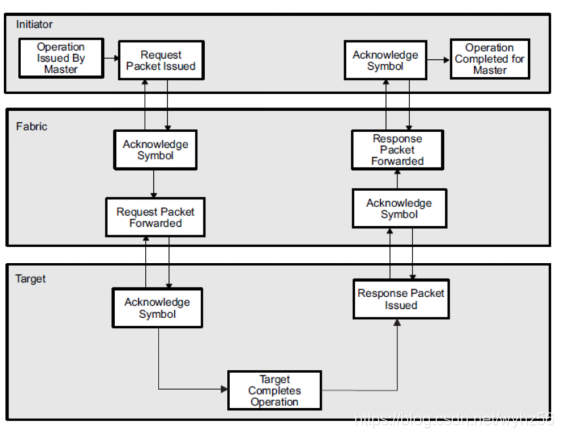
传输过程
传输过程主要有发出请求、相应数据包两个过程
SRIO端点并不直接连接,而是通过中间的Fabric设备,Control symbols用于数据包确认,流控制信息和维护功能。
//Control symbol??
Example Packet
下图显示了作为两个数据流的示例数据包。第一种是有效载荷大小为80字节或更少,而第二种适用于有效载荷大小为80到256字节。SRIO数据包的长度必须是32位的偶数整数。如果物理层,逻辑层和传输层的组合具有16位整数的长度,则在CRC(未示出)之后将值为0000h的16位填充添加到分组的末尾。定义为保留的位字段在生成时分配给逻辑0,并在接收时忽略。RapidIO输入/输出逻辑规范和消息传递逻辑规范中描述了所有请求和响应数据包格式。
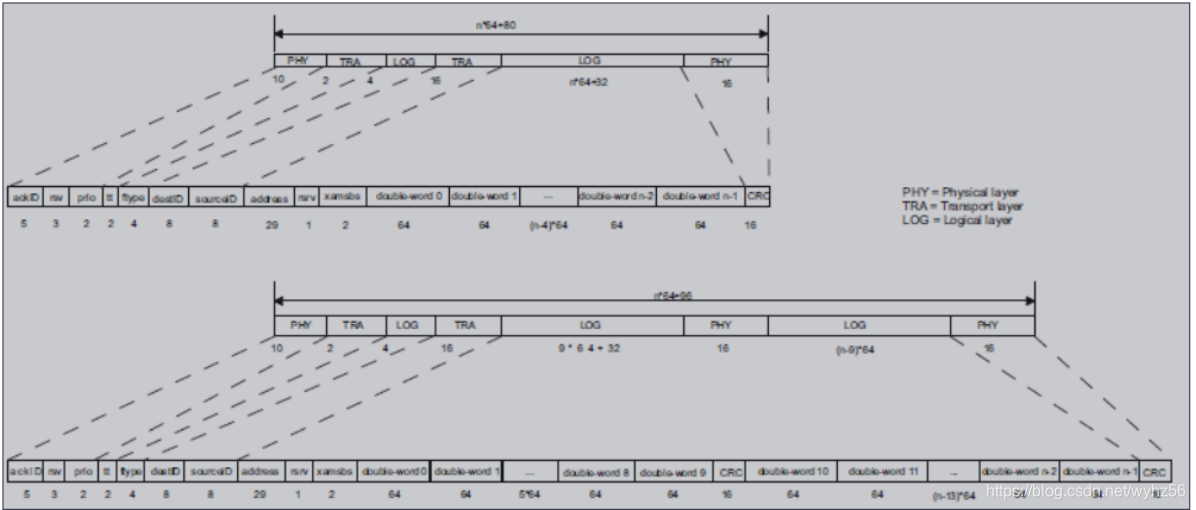
(TI的图还能在清楚一点吗- -)
除了ackID和保留PHY字段的一位之外,CRC值保护整个数据包。不对重传。
Control Symbols
物理层消息,受自身CRC保护。控制符号提供两个功能:stype0符号表示发送符号的端口的状态,stype1符号表示对接收端口或传输分隔符的请求。
![]()
Deilmiter 分隔符
控制符号由符号开头的特殊字符分隔。如果控制符号包含数据包分隔符(数据包开始,数据包结束等),则使用特殊字符PD(K28.3)。如果控制符号不包含数据包分隔符,则使用特殊字符SC(K28.0)。这种特殊字符的使用提供了控制符号内容的早期警告。CRC不保护特殊字符,但识别非法或无效字符并将其标记为不接受数据包。由于控制符号是已知长度,因此不需要结束分隔符。
接收数据包的类型决定了数据包路由的处理方式。保留或未定义的数据包类型在被逻辑层功能块处理之前被销毁。这可以防止错误地分配资源。不支持的数据包类型会收到错误响应数据包。
Control Symbols类似于物理层自身通信的包??
SRIO Packet Type
SRIO数据包的类型由数据包中Ftype和Ttype字段的组合决定。

没看懂Ttype在哪儿- -
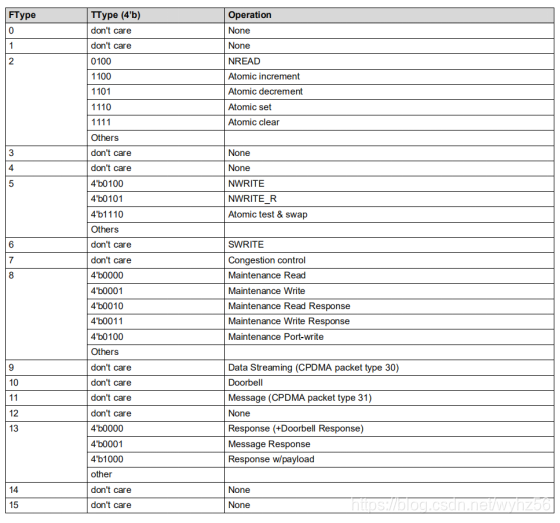
配置操作
SerDes配置操作
SerDes包括发送器(TX),接收器(RX),锁相环(PLL),时钟恢复,串行到并行(S2P)和并行到串行(P2S)块。内部PLL乘以用户提供的参考时钟。PLL的所有环路滤波器组件都在片内。同样,差分TX和RX缓冲器包含片内终端电阻。唯一的片外元件要求是隔直电容。
使能内置PLL
倍增的高速时钟仅在SerDes内部产生
SerDes配置有寄存器SRIO_SERDES_CFGPLL,SRIO_SERDES_CFGRX [30],SRIO_SERDES_CFGTX [3-0]和SRIO_SERDES_RSVD。要使能内部PLL,必须设置SRIO_SERDES_CFGPLL的ENPLL位。设置该位后,必须允许1s稳压器稳定。此后,如果RIOCLK和RIOCLK稳定,PLL将花费不超过200个参考时钟周期来锁定所需频率。查询SRIO_SERDES_STS寄存器的LOCK位得知PLL是否锁定
使能接收
要使接收器能够串转并,必须将相关SERDES_CFGRX n_CNTL寄存器的ENRX位设置为高电平。
ENRX为低,接收关闭。
CDR位中列出的时钟恢复算法用于调整用于对接收到的消息进行采样的时钟,以便在数据转换之间的中间获取数据样本。可以选择禁用二阶算法,并且可以配置两者以优化其动态。两种算法使用相同的基本技术来确定采样时钟是否理想地放置,如果不是,则是否需要提前或稍后移动。当两个连续的数据样本不同时,检查两者之间的相位样本。采集8个数据样本和9个阶段样本,每个结果计为投票,以便更早或更晚地移动样本点。这八个数据位构成投票窗口。然后对8张选票进行计数,如果有大多数早期或晚期选票,则会采取调整采样时钟位置的动作。一阶算法按多数投票进行单相调整。二阶算法根据早期和晚期多数票之间的净差异重复行动,从而调整阶段的变化率。//整不明白,大概就是时钟错误,调整时钟的?
将ALIGN字段设置为01可以与IEEE定义的8b:10b数据编码方案中包含的K28逗号符号对齐,并由多种传输标准使用。对于不能使用基于逗号的符号对齐的系统,单比特对齐点动功能提供了直接从ASIC核心中实现的逻辑控制接收器的符号重新排列特征的手段。该逻辑可以被设计为支持所需的任何对准检测协议。
EQ位允许启用和配置包含在所有接收信道中的自适应均衡器,这可以通过相对于信号的高频分量衰减低频分量来补偿信道插入损耗,从而减少符号间干扰 。
•没有自适应均衡。
均衡器在最大增益下提供平坦响应。如果接收器的抖动主要由于串扰而不是频率相关的损耗而发生,则该设置可能是适当的。
•完全自适应均衡。
通过分析接收数据中的数据模式和转换位置,在算法上确定均衡器的低频增益和零位置。此设置应用于大多数应用程序。
•部分自适应均衡。
通过分析接收数据中的数据模式和转换位置,在算法上确定均衡器的低频增益。零位固定在八个零位之一。
对于任何给定的应用,最佳设置是信道的损耗特性和信号的频谱密度以及数据速率的函数,这意味着不可能仅通过数据速率来识别最佳设置; 虽然一般来说,线路速率越低,所需的零频率越低。
使能发送
要使能发送器进行串行化,必须将相关SERDES_CFGTX n_CNTL寄存器的ENTX位设置为高电平。当ENTX为低电平时,发送器内的所有数字电路都被禁用,时钟关闭,但发送时钟(TXBCLK [n])输出除外,它继续正常工作。发送器内的所有电流源都将完全断电,但电流模式逻辑(CML)驱动器除外,如果选择了边界扫描,它将保持上电状态。
寄存器展示
SERDES_CFGRX n_CNTL寄存器

TESTPATTERN 启用并选择测试模式。启用并选择三种PRBS模式之一,用户定义模式或时钟测试模式的验证。
000b =禁用测试模式。
LOOPBACK ENABLE
ENOC 启用偏移补偿
EQHLD 保持均衡器。将均衡器保持在当前状态。
EQ 启用和配置自适应均衡器以补偿传输介质中的损耗。
CDR 时钟/数据恢复。配置时钟/数据恢复算法。
LOS 信号丢失。通过两个可选阈值实现信号丢失检测。
ALIGN 符号对齐。启用内部或外部符号对齐。
TERM输入终止。该字段唯一有效的值是001b
INVPAIR 反转极性。反转RIOTXn和RIOTXn的极性。
RATE 选择全速率,半速率,四分之一或八分之一速率操作
BUSWIDTH 总线宽度 写010
ENTX 使能传输
例程对此配置为00440495 004408A5 0x004404B5
// (0) Enable Receiver
// (1-3) Bus Width 010b (20 bit)
// (4-5) Half rate. Two data samples per PLL output clock cycle 根据不同速率改变值
// (6) Normal polarity
// (7-9) Termination programmed to be 001
// (10-11) Comma Alignment enabled
// (12-14) Loss of signal detection disabled
// (15-17) First order. Phase offset tracking up to +-488 ppm
// (18-20) Fully adaptive equalization
// (22) Offset compensation enabled
// (23-24) Loopback disabled
// (25-27) Test pattern mode disabled
// (28-31) Reserved
SERDES_CFGTX n_CNTL寄存器

TESTPATTERN 启用并选择测试模式。启用并选择三种PRBS模式之一,用户定义模式或时钟测试模式的验证。
000b =禁用测试模式。
LOOPBACK ENABLE
MSYNC 1h =同步主站。启用通道作为主通道以进行同步。对于单通道应用,将MSYNC置于高电平。多通道时最小通道置为1
FIRUPT 0h =发送前后光标FIR滤波器更新。更新FIRtap weights的控制。当SerDes字节时钟和该输入均为高电平时,可以更新TWPRE和TWPST1字段。
TWPST1 TWPRE TX波形调节
SWING Output swing
INVPAIR 反转极性。反转RIOTXn和RIOTXn的极性。
RATE 选择全速率,半速率,四分之一或八分之一速率操作
BUSWIDTH 总线宽度 写010
ENTX 使能传输
例程配置
// (0) Enable Transmitter
// (1-3) Bus Width 010b (20 bit)
// (4-5) Half rate. Two data samples per PLL output clock cycle
// (6) Normal polarity
// (7-10) Swing max.
// (11-13) Precursor Tap weight 0%
// (14-18) Adjacent post cursor Tap weight 0%
// (19) Transmitter pre and post cursor FIR filter update
// (20) Synchronization master
// (21-22) Loopback disabled
// (23-25) Test pattern mode disabled
// (26-31) Reserved
上文提到可以将多个通道配置为同一个端口
由RapidIO PLM Port {0..3} Path Control 寄存器配置
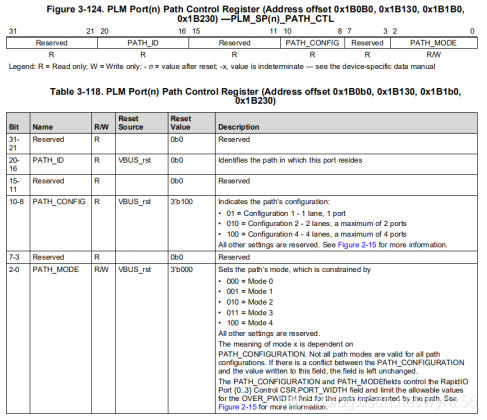
Direct I/O Operation
直接I / O(加载/存储)模块用作所有传出直接I / O数据包的源。对于直接I / O,RapidIO数据包包含应在目标设备中存储或读取数据的特定地址。直接I / O要求RapidIO源设备为目标设备中的内存保留本地地址表。建立这些表后,RapidIO源控制器使用此数据计算目标地址并将其插入数据包标头。RapidIO目标外设从接收的数据包头中提取目标地址,并通过DMA将有效负载传输到内存。
LSU
当CPU进行数据交互时,LSU会为RIO外设提供有关传输的重要信息,例如DSP存储器地址,目标器件ID,目标目标地址 ,数据包优先级等等数据包的所有头字段。加载/存储模块提供了一种机制,通过一组作为传输描述符的MMR来处理这种信息交换。(MMR存储器映射的寄存器)
总共有8个LSU。每个LSU都有自己的七个寄存器。LSU_Reg0-4用于存储控制信息,LSU_reg5-6用于存储命令和状态信息。
但某些字段(例如RapidIO srcTID / targetTID字段)由硬件分配,并且没有相应的命令寄存器字段。
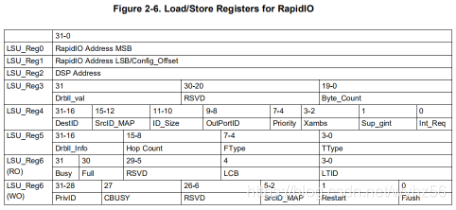
相应细节,请自行参阅用户手册
此处需要注意REG3中Byte_Count寄存器 共有20位,指最大值为1MB
LSU有两个推荐模板
LSU setup by cores:
LSU setup by EDMA//暂时看不懂
LSU影子寄存器
每个LSU后面都有一组影子寄存器。可以对每个影子寄存器进行编程,以便提前设置事务。
可分配给每个LSU的总影子寄存器是可配置的,总共32组寄存器。在32个影子寄存器中,16个用于LSU0-3,而另外16个只能用于LSU4-7。分配给LSU的总影子寄存器通过RIO_LSU_SETUP_REG0建立。只有在LSU禁用,外设使能的双重前提下该配置寄存器才可以被编辑。
Step 1. Write 1 to the BLK0_EN register (ensure GBL_EN is set to 1 before this step).
Step 2. Disable the LSU block by writing 0 to the BLK1_EN register.
Step 3. Poll for the BLK1_EN_STAT register to be 0 to make sure that the LSU is disabled.
Step 4. Write to the LSU_SETUP_REG0.
Step 5. Enable the LSU by writing 1 to the BLK1_EN registers.
每个影子寄存器集都有一个LSU_Reg0-5的副本。对于特定的LSU,LSU_Reg6在它们之间共享。
影子寄存器类似于队列,当LSU HW(HW指hardware)完成传输时,加载下一个影子寄存器的值。
FILL BIT&BUSY BIT
FILL BIT:是否还有空白的影子寄存器,LSU_REG6中查看
BUSY BIT:两个CPU访问同一组寄存器。
关于LTID与LCB的描述(核心辨别所需要的ID)
LSU Context Bit. This information is used by the transaction to identify if the context of theCC is with respect to the current transaction or not.
LSU Transaction Index. An LSU can support more than 1 transaction. This index helpsidentify the completion code (CC) information for the transaction.
简单来说当设备需要使用LSU时,需要查询FULL和BUSY两个位 都为0时才能写入LSU的值,同时将BUSY置1,写到REG5时busy则自动归0,值得注意:Busy位和Full位是要一起被读取的,因为如果CPU读取了Full位并获取了LSU寄存器的使用权,busy位马上就会被置1,试图查看busy位之后就会马上导致busy位被置1。所以Busy位和Full位一定要一起读取。自动归0后观察是否能发送数据,如果不能发送数据,则将配置信息存在影子寄存器中。
如果核心出现一些问题导致BUSY位不能清零 则需要REG6的CBUSY位通过其他核心清0。同时LTID和LCB则会发生变化。
跟踪状态寄存器
寄存器RIO_LSU_STAT_REG0-2来跟踪各种事务的完成代码(CC)
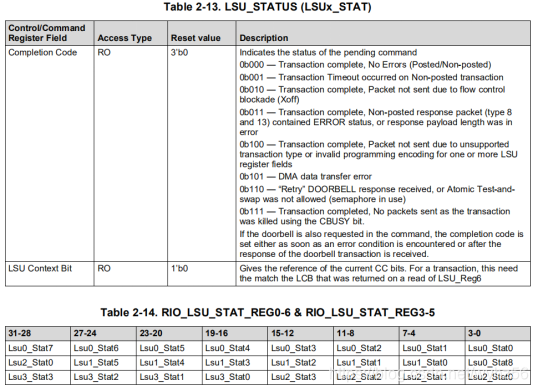
具体数据路径描述
上面说的高大上的一堆话,总结一下Load/Store模块的作用就是产生directIO包。
这种接口不支持消息传递接口。插一句嘴,外向传送的DOORBELL(门铃)包也是通过这个接口产生的。每个LSU最多能支持16个SRCIDs,所以LSU0能够用SRCID0-15产生传输,LSU1能用SRCID16-31产生传输等等。每次LSU发出一个新的命令,就重新计算SRCID的数量,所以每次发出新的命令的时候,LSU1的SRCID总是从16开始的。
该模块的数据路径是以VBUSM总线作为DMA接口的。SRIO的payload最大值是256B,每个LSU都有可能产生多于一个VBUSM传输,为的是并行得到超过256B的payload。这些payload之后可以用UDI接口发送,当然为了区分这些传输,就要利用不同的SRCID,即使是发送给同一个LSU的,当响应包从UDI接口返回的时候还是能够分辨不同的transaction。
Figure2-12显示了发送数据的端口操作流程图。
用户通过配置LSU寄存器出发LSU传输
LSU检查流控列表来确定哪个DestID是可以用的
LSU检查每一个port的TX_FIFO状态
如果TX_FIFO可用并且没有正在进行的传输,CAU就发送VBUSM Read Commands来读取来源信息,并且将来源信息移动到共享TX Buffer池;如果TX_FIFO可用和没有正在进行的传输,这两个条件有一个不存在,就回到检查流控列表确定DestID可用那一步。
CPU利用VBUSP配置总线和控制/命令寄存器。这些寄存器包含传输描述符,这些传输描述符需要初始化读/写包的产生。在传输描述符被初始化写好之后,就要确认流控状态。确认流控状态的模块检测命令寄存器的DESTID和PRIORITY域来确定流通道是否已经被占用,还有,TX FIFO的空闲状态也要被检查,该操作是通过检查命令寄存器的OutPortID实现的。只有在流控通道被打开,TX FIFO被分配缓存之后,才会产生一个VBUSM读命令,该读命令作用于将被移入到TXbuffer池的payload数据。数据以简单的顺序从共享buffer池移动到合适的输出TX FIFO,这种顺序基于VBUSM传输的completion情况。只要数据被传输到FIFO中,数据就一定能通过管脚发送。
Figure2-13显示了支持Load/store模块所需的数据路径和缓存。
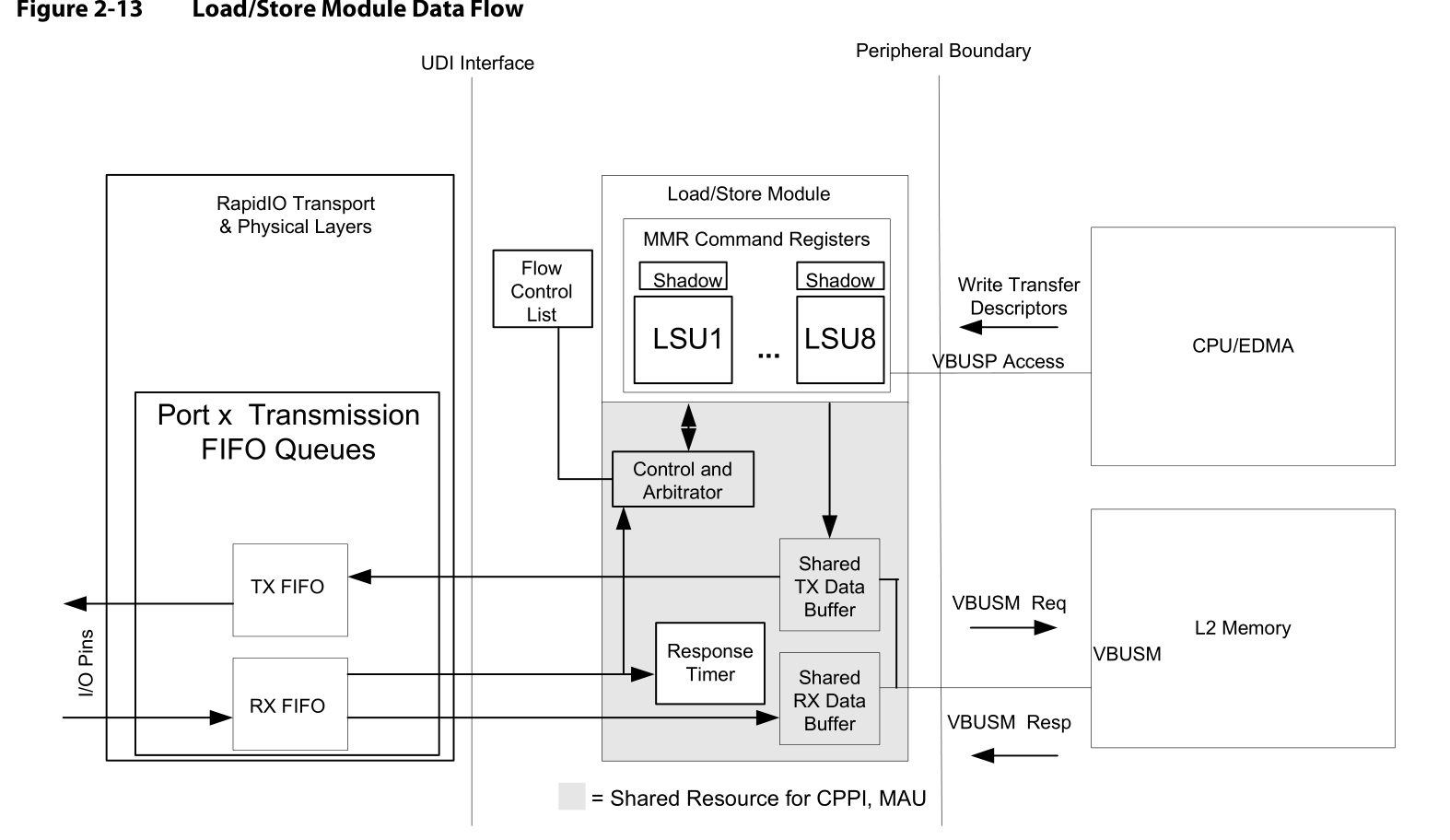
TX操作
写传输
Figure2-14显示了SRIO内部的缓存机制。
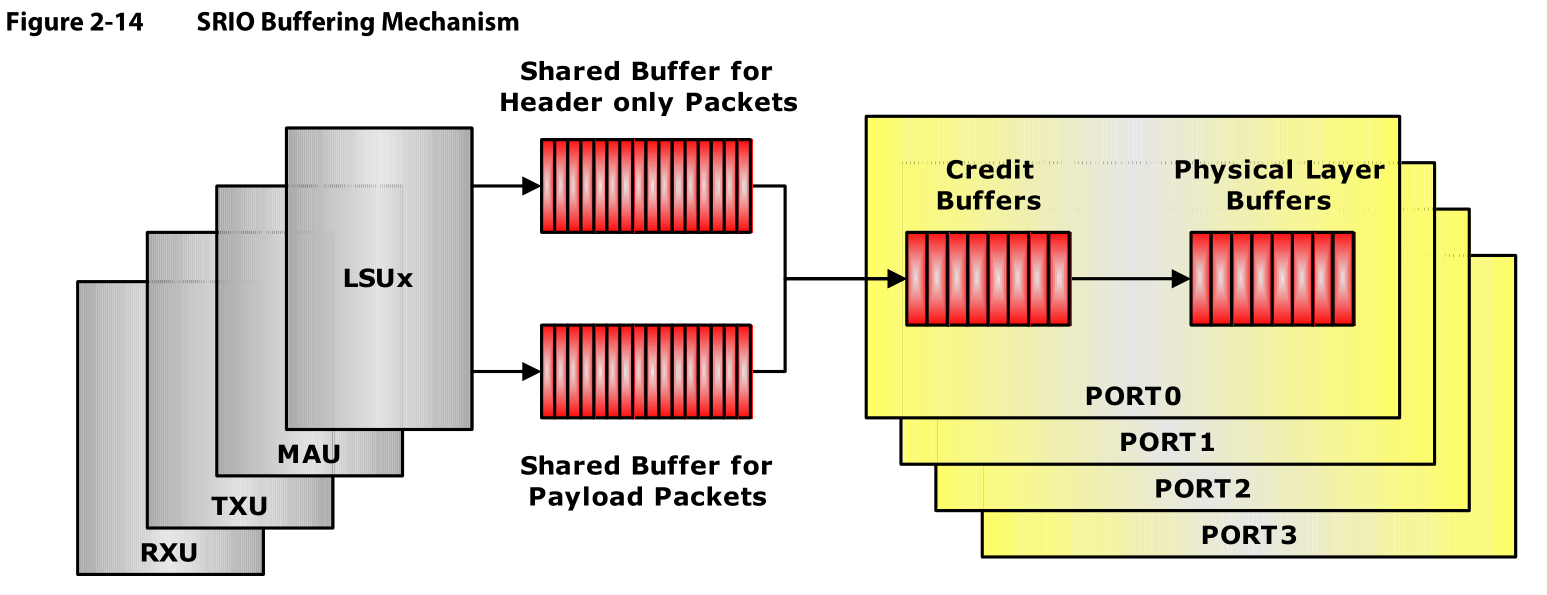
多核之间共用Shared TX Data Buffer。一个状态机在LSU和其他协议单元之间进行仲裁和分配可用的buffer。只有在来自VBUSM的payload的最后一个字节被写入Shared TX Data buffer之后,Load/Store模块才会把包送到TX FIFO,一旦包被送到TX FIFO,共享缓存就可以释放,并且用于其他transaction了。
TX缓冲区在所有输出源之间动态共享,这些输出源包括LSU,TX CPPI,来自RX CPPI和MAU的响应包。所以缓存空间存储需要分段对带payload的包和不带payload的包进行处理。
一条消息最多有16个包,每个包的最大尺寸是256B,同时还可以有不带payload只含header的包。数据以接收的顺序离开共享缓存,离开时不需要确认包的优先级,但是数据离开TX FIFO时需要考虑到优先级。
对于提交的WRITE操作不需要RapidIO响应包,一个核有可能提交各种各样的输出请求。例如,一个单一的核可能在任何给定的时间内让流写数据包进行缓存,并且提供了输出源。在这个例子中,一旦数据包写入共享TX缓存池,LSU就会释放给影存器。如果请求被流控,外设将设置completion code status register并且使用中断位ICSR。当中断路由完成的时候,控制/命令寄存器就会被释放。
对于未提交的WRITE操作需要RapidIO响应包,任何给定的时间里每个核只能有一个向外的请求。消息包会写入TX缓存池,当然,一直到响应包路由到原来的模块,并且状态寄存器中恰当的completion code被设置之后,LSU才可以释放。在原子输出测试和交换包中有一种特殊情况,这种包是唯一 一种需要有带有payload的响应的Write类型的包,这种响应的payload被路由到LSU,然后payload被检查以确认信号是否被收到,随后对completion code进行适当的设置。payload并没有通过VBUSM传出外设。
所以一般的流程是:
通过VBUSP(配置总线)配置控制寄存器
流控确认
TX FIFO(TX共享缓存池)可用确认
VBUSM读取对数据payload的请求
VBSUM在共享TX缓存区域响应给特定模块缓存的写数据
VBSUM读响应被监控,等待payload的最后一位
命令寄存器的header数据写入共享TX缓存空间
将payload和header传递给TX FIFO
如果不需要RapidIO响应,载入下一个影存器
基于优先级从TX FIFO传递数据给外部
读传输
产生读传输的流程和产生带有响应的未提交的WRITE传输相似。不过还是有两个主要的不同,首先,READ包包含不带数据的payload;其次,READ响应是带payload的。所以读命令只需要TX缓存池中的一块无负载缓存,当然,还需要一块共享RX缓存,这块缓存不是在READ包传输开始之前就分配好的,因为这会造成其它输入包去其它模块的交通阻塞。
重复一遍,一直到响应包路由到原来的模块,并且状态寄存器中恰当的completion code被设置之后,LSU才可以释放。
因此一般的流程是这样的:
通过配置总线VBUSP配置命令寄存器
流控确认
分配TX FIFO缓存
命令寄存器中的header数据写入到共享TXbuffer
传递header数据给TX FIFO
基于优先级从TX FIFO相外部传递数据
当数据返回UDI接口时,通过VBUSM总线将数据发送出去
对于所有的传输,共享TX缓存都会在包被推送到TX FIFO之后就立即释放,如果接收到了一个未提交传输(non-posted transaction)的ERROR或者RESPONSE信号,CPU必须重新配置REG6或者重新开始这个传输。
包分段
LSU对向外的请求有两种分段方法。一种是请求的Byte_Count超过256B,另一种是请求的RapidIO地址是非64位的。这两种情况下,向外的请求都要被分解成多个RapidIO请求包。例如,CPU相对外部的RapidIO设备进行1KB的存储操作,配置好LSU寄存器之后,CPU对REG5命令寄存器进行了一个简单的写入操作,然后外设硬件将存储操作分为4个RapidIO写包,每个都是256B大,然后计算每个包的64位RapidIO地址,WRSIZE和 WDPTR。在所有提交包传递给TX FIFO之后,释放LSU。对于未提交操作,像CPU载入,在LSU释放之前,必须受到所有的包响应。
RX操作
响应包的类型一直是RapidIO包类型13。所有带有传输类型的响应包不等于0b0001,并且不超过128个SRCTID以接收顺序路由给LSU。这些包是否带有payload取决于相应的请求包。由于RapidIO交换系统的性质,响应包可以以任何顺序到达。数据payload(如果有的话)和数据header是从RX FIFO移动到共享RX缓存中去。包的TargetID域用以确定等待响应的核和相应的寄存器。记住,每个核只能有一个外向请求。通过VBUSM总线操作,所有的payload数据从共享RX缓存池移动到存储区域。
MAU管的是所有进来的DirectIO包,包括 NREAD,SWRITE, NWRITE 和 NWRITE_R 传输。不支持进来的原子操作,如果进来会以ERROR的形式响应。对于DirectIO包,MAU负责路由DOORBELL消息给中断处理器,MAU也负责包的前向传输。
所有进来的DirectIO包包含一个存储地址域,该地址是设备的存储映射,决定数据将会写在哪里或者从哪里读取数据。不支持通过外设翻译RX地址。RapidIO包的地址将被应用于DMA传输。这种方式需要DirectIO传输知道目标设备的映射地址信息。当然,我们必须知道对目标地址的覆盖写,是没有一种硬件保护机制的。这种保护必须在系统级的软件层面进行管理。一些存储访问可能在设备级层面被限制到监督协议中,即设备自身带有监督协议,来管理存储访问。大多数存储访问通过用户允许就能使用。MAU给每一个接收到的DMA传递来的包配置用户许可证,除非包的SOURCEID和RIO_SUPRVSR_ID的值相匹配。如果匹配RIO_SUPRVSR_ID的值,就会被颁发监督许可证。
复位和掉电
通过reset,Load/Store模块将所有寄存器的域置为默认状态的值,等待CPU的处理。
如果DirectIO协议在应用中不被支持,那么Load/Store模块就可以掉电。例如,如果使用Message协议进行传输,那么就可以对Load/Store模块进行掉电操作,以达到省电的目的,在这种情况下命令寄存器应该掉电并设置为不能访问。在掉电状态下,这些模块的时钟就要被gate掉。
特殊情况
对于这些特殊情况,大家在遇到时再去查手册即可,不必了解过深,此处只写出目录,以保证在出错时能够按图索骥。
时间用尽
输入错误响应
软件处理基于LSU错误的SRCID中断
门铃的输入重试响应
时序
对于 传输来说,任何时候LSU都能准备就绪。在传输确定时序之前,下面的情况要被提供。
优先级,CRF:只有最高等级的优先级和CRF的传输才会为每个port考虑时序
流控:transaction的DESTID不应该被流控
未提交传输的SRCID:如果这个SRCID正在被一个未提交传输使用,而新的为提交传输来自同一个SRCID,那么新的传输就会被挂起,直到旧的传输完成
SRIO VBUSM总线限制:VBUSM接口最多支持4个写和4个读传输同时进行,VBUSM被MAU、LSU和TXU共享,如果LSU想在VBUSM接口发送一个命令,那么VBUSM接口应该处于空闲状态。
FIFO : FIFO中应该有足够的空间容纳一次传输
如果多个LSU达到了以上条件,scheduler将以环形签字方式决定谁先谁后。
错误处理
不同的错误都会发生,表现为RIO_LSU_STAT_REGx的CC位所报告的不同的值。还有,如果Int_req和Sup_gcomp(只影响良好的完成中断)位无效,位在LSU_REG4中被置位,中断就会路由回CPU或者DMA。为每个特定的SRCID在REG3中产生信息,在8个LSU中都是这样的情况。在这些设备中错误信息只在每个LSU上可用。当然如果不同的核在使用LSU,LSU就会中断所有的核,即使这个完成情况只是针对于某个单一的核。因此,区分每个核的LSU中断非常重要,因为EDMA专用于LSU,所以每个核都有自己的信息也很重要。RIO_LSU_SETUP_REG1寄存器是用来确定是否LSU在被EDMA使用。只有在LSU没有在工作时,该寄存器才是可以编辑的。
Figure2-15是RIO_LSU_SETUP_REG1寄存器的图,Table2-14是RIO_LSU_SETUP_REG1寄存器的功能描述。

可以看到RIO_LSU_SETUP_REG1有两种域,一种是LSUx_edma,当LSUx_edma位是0的时候,表示好的完成(good completion)将基于SRCID被驱动给中断;当LSUx_edma位是1的时候,表示好的情况中断将被驱动给LSU的特定位。
另一种域是 Timeout_cnt,如果该域是00,表示在一次错误情况之后,在该传输被丢弃和新的传输开始之前,时间码只变了一次;如果该域是01,表示在一次错误情况之后,在该传输被丢弃和新的传输开始之前,时间码只变了两次,以此类推。
对于每一个传输下面的中断都会产生。软件决定使用这些中断中的哪个并且看情况路由到其它地方:
基于table2-14中的setup位的,每个LSU或者SRCID的好的完成
-在LSU_REG4中定义的每个SRCID的错误完成
如果发生LSU没有自动装载下一个影存器中的内容,那么它就需要软件的介入。当CPU得到一个中断, 它就会读取相关的RIO_LSU_STAT_REGx位,了解error的细节。目前软件可以做到如下情况:
软件可以选择不理这个中断
在这种情况下,有一个时钟将会失效。LSU将会抛弃所有的传输,包括当前来自同一个SRCID的传输。然后LSU会自动装载下一组影存器中的内容,如果LSU是为一个EDMA配置的,LSU还会发送一个完成中断给EDMA,这会使能EDMA自动的装载下一组寄存器。
软件修复这个问题(例如使能为XOffed的port),并且将相关的LSU的restart位置1 ,LSU将会中断当前传输并装载下一组影存器。
软件决定清除当前传输
在这种情况下,软件将LSU的flush位置1,所有来自同一个SRCID的传输包括当前还在影存器中的传输都会被清除。这会花费超过一个时钟周期来完成清除工作。
在以上的几种情况下,LSU_REG6的flush位和restart位都是写模式。
MESSAGE PASSING
传递消息时,未指定目标地址。而是在RapidIO数据包中使用邮箱标识符

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









