






摘要:哈喽,大家好,好久不更新了。因为,最近一直在学习Seq2Seq,很多都不得其解,我自己感觉有两个月了吧,查阅了一些资料,今天给大家带来一个基于字符的英汉翻译的辛酸史。
在说机器翻译之前,需要说一下循环神经网络,因为我们需要用到它。循环神经网络,它是一类特殊的神经网络,用于处理序列数据。常见的循环神经网络包括:简单循环神经网络(Simple RNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)、双向循环神经网络(Bidirectional RNN)。这些循环神经网络模型在处理不同类型的数据时具有各自的优势和使用场景,如果小伙伴需要去学习的话,建议按照我上面列举的顺序学习,先从RNN学起,后面你会发现每个网络的根本很类似。
因为使用了LSTM,那就简单地介绍一下吧,它是一种用于解决循环神经网络中长期依赖问题的一种神经网络,传统的RNN在处理长序列数据时会面临梯度消失或者梯度爆炸的问题,导致难以捕捉到序列数据中的长期依赖关系。它的核心组成部分包括记忆单元(c)、遗忘门(f)、输入门(i)、输出门(o),它有两个重要的状态记忆单元状态(cell state)、隐藏状态(hidden state)。cell state 用于存储和传递信息,也称之为长期记忆。hidden state是LSTM在每个时间步的输出状态,也称之为短期记忆。
那么Seq2Seq又是什么呢,它是一种神经网络模型结构,用于处理序列到序列的任务,它由两个主要组件组成:编码器和解码器。编码器的作用就是将输入的序列也就是源语言句子,转换为一个固定长度的向量表示,也就是隐藏状态,其中包含了输入序列的语义信息。而解码器的任务就是使用编码器输出的向量来生成目标序列,既然是序列,那么解码器也是一个循环神经网络,它使用编码器的状态为输入的初始状态,逐步生成目标序列。它一般可以用在机器翻译、文本摘要、对话系统中。
查阅大量资料,开始着手搞机器翻译。
首先,整理下思路:
第一步:需要翻译的语料,用于训练的样本。
第二步:将语料进行预处理,裁剪。
第三步:搭建模型。
第四步:训练和推理。
注意下:这里我只使用了简单的one-hot的编码,而没有使用Embedding这种嵌入。按照理论上来说,Embedding的效果应该会更好,它是一种低维稠密向量,是通过参与到网络训练中调整单词语义的向量。使用one-hot编码,就是想看看能够通过one-hot实现机器翻译,后面还是会尝试使用embedding的方式的。
坑的整理
1、样本的选择:开始时选用了联合国提供的语料Parallel Corpora,反复训练了几次,效果特别不好,看了样本英中的平行对照太差劲了。后来找到了一个叫cmn_train的样本,不过这个样本只有3000对,样本量特别少。
2、构建one-hot:最开始的时候,打算使用nltk和jieba分别对英文和中文进行分词,使用单词和词组进行构建one-hot,后来发现是我天真了,在Parallel Corpora样本中构建出的英文单词远远大于中文词组(侧面说明中文语境远比英语语境要高)。过几十万的one-hot不是8g显存可以带动的,所以,果断换成字符和字的one-hot编码。
3、编码器和解码器推理模型:第一次接触的时候,非常的困惑,没法创建编码器模型和解码器模型。后来通过大量的训练实验,我找到了两种构建的方式:第一种,将训练好的模型进行迁移,构建出编码器模型和解码器模型。第二种,在创建模型的时候,构建出编码器模型和解码器模型,经过模型训练,保存编码器模型和解码器模型。
基本原理

我太懒了,就用笔大致画一下样子吧,需要注意的是,decoder_input这里需要在句子开头添加一下开始标记,而label需要在句子结尾添加结束标记。
创建模型
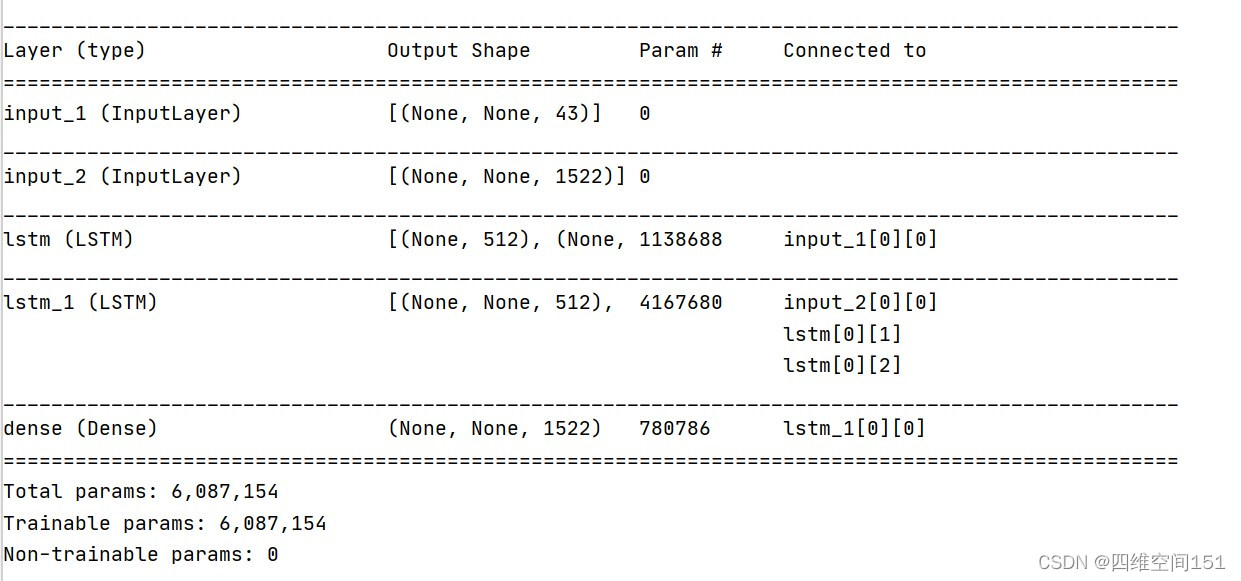
构建一个简单的模型,真的是非常简单的模型。
代码部分
def generator_data():
global sample_5000
encoders = []
decoders = []
labels = []
while True:
words = []
try:
words = sample_5000.__next__()
except StopIteration:
sample_5000 = read_sample()
continue
x = words[0].lower()
y = '\t'+words[1]+'\n'
x_token = []
[x_token.append(en_token_index[char]) for char in x]
y_token = []
[y_token.append(cn_token_index[char]) for char in y]
encoder_input = to_categorical(x_token,en_token_index_len)
decoder_input = to_categorical(y_token[:-1],cn_token_index_len)
y_label = to_categorical(y_token[1:],cn_token_index_len)
encoder = np.zeros((en_single_max,en_token_index_len))
decoder = np.zeros((cn_single_max,cn_token_index_len))
label = np.zeros((cn_single_max, cn_token_index_len))
encoder[0:encoder_input.shape[0]] = encoder_input
if decoder_input.shape[0] > cn_single_max:
with open('error.txt','a',encoding='utf-8') as f:
# f.write(''.join(y_token[:-1]))
str_y_token = str(y_token[:-1])
f.write(y+str_y_token)
decoder[0:decoder_input.shape[0]] = decoder_input
label[0:y_label.shape[0]] = y_label
encoders.append(encoder)
decoders.append(decoder)
labels.append(label)
if len(encoders)>batch_size:
yield [np.array(encoders),np.array(decoders)],np.array(labels)
encoders = []
decoders = []
labels = []还是老样子,构建出一个迭代器。
然后构建和训练模型。
def create_build_model():
# 编码器
encoder_inputs = Input(shape=(None,num_encoder_tokens))
encoder = LSTM(latent_dim, return_state= True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c]
# 解码器
decoder_inputs = Input(shape=(None,num_decoder_tokens))
decoder_lstm = LSTM(latent_dim,return_sequences=True,return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens,activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
print('decoder outputs shape',decoder_outputs.shape)
# 定义模型
model = Model([encoder_inputs,decoder_inputs], decoder_outputs)
model.summary()
opt = Adam(learning_rate=0.01)
# 训练模型
model.compile(optimizer='rmsprop', loss='categorical_crossentropy',metrics=["accuracy"])
model.fit_generator(generator_data(),
steps_per_epoch=(math.ceil(3000/batch_size)+1)
,epochs=1000)
model.save('on_fanyi.h5')这里的优化器,我更换成了rmsprop,说是比较的高级和智能^_^.
下面是推理代码。
def decode_sequence(input_seq):
state_values = encoder_model.predict(input_seq)
target_seq = np.zeros((1,1,num_decoder_tokens))
target_seq[0,0,cn_token_index['\t']] = 1.
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict([target_seq]+state_values)
sampled_token_index = np.argmax(output_tokens[0,-1,:])
sampled_char = cn_index_token[sampled_token_index]
decoded_sentence += sampled_char
if( sampled_char == '\n' or len(decoded_sentence)>20):
stop_condition = True
target_seq = np.zeros((1,1,num_decoder_tokens))
target_seq[0,0,sampled_token_index] = 1.
state_values = [h,c]
return decoded_sentence推理代码需要注意了,由于我们的长度是不固定的,所以设置一个长度,防止它无限制地返回。
看结果
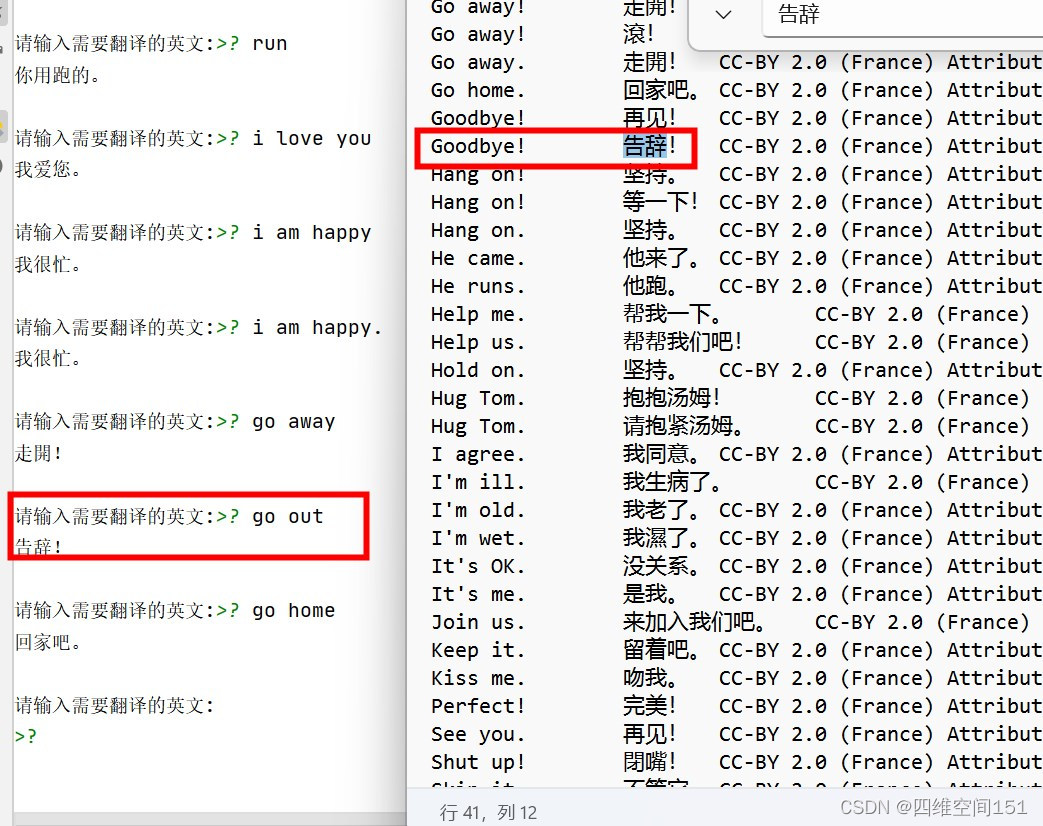
从结果上可以看到有对有错,可以实现部分的翻译。
最后,告诉大家,这个模型评估下来正确率只有48%左右,连50%都达不到,所以还有很多的优化和思考的空间。不过这是一个好的开始,除了没有足够的算力之外,其他的都在变得越来越好了。
最后向大家推荐下:
官方站点:http://faceaiua.com
球球群:195889612















 5523
5523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









