






摘要:传统的深度神经网络在网络层数较深时,会出现梯度消失或者爆炸的问题,导致难以有效训练。ResNet通过引入“残差块”(Residual Block)的方式来解决这一问题。残差块中,利用跳跃连接的方式将输入的恒等映射直接加到后续的输出中,从而使得网络直接可以学习到对输入的差异性特征,避免这些信息因为多网络层的堆叠而丢失。此外,在ResNet的设计中还采用了批规范化、池化等常规技术,进一步提高了模型的性能。
大家好,上一期我介绍了VGG19这个深度神经网络,使用VGG19网络完成了一个多分类任务(手写汉字识别)。使用这样一个模型能够实现识别常用的3700多个汉字,当然,也对应着这3700个手写汉字。但是呢,VGG19也会有弊端,包括大量的参数、训练缓慢、容易过拟合、偏向于模式识别等等。
今天,我给大家带来一个新的网络ResNet-50,首先我们来看下什么是ResNet。ResNet是一种深度卷积神经网络模型,在2015年由何凯明等人提出,主要用于解决深度神经网络训练时的梯度消失问题。划重点,他是解决梯度消失或者梯度爆炸的,那么他怎么解决这个问题的呢?ResNet通过引入“残差块”(Residual Block)的方式来解决这一问题。残差块中,利用跳跃连接的方式将输入的恒等映射直接加到后续的输出中,从而使得网络直接可以学习到对输入的差异性特征,避免这些信息因为多网络层的堆叠而丢失。所以,由于他是拥有多个“残差块”和多个网络堆叠,所以他的网络层次很深,比如ResNet50(注意:这里我有点歧义,官方或者教材上给出的是50层包括卷积+全连接,但是我觉得不对,因为缺少了跨维度的4个卷积层,我数下来是54层,如果有懂的朋友可以帮我解解惑)。这样的网络比VGG19深多了,VGG19总共有大约14,714,688个参数,而ResNet50大约有25,557,032个参数,这意味着ResNet50参数量是VGG19的大约1.78倍左右。需要注意的是,模型参数数量并不完全反映一个模型的复杂程度和性能。例如,ResNet50相对于VGG19来说,在ImageNet数据集上的分类准确率要更高。这是因为ResNet50的残差结构可以帮助提高梯度传播和捕获更深入的特征表示。此外,模型的训练方法、数据量等因素也会影响模型的性能,因此选用合适的模型需要考虑多方面因素,不能仅仅依据参数数量来判断。
所以,ResNet50它是一种残差网络,想要学习推导和残差块的具体理论知识的,可以自行教程并不难,这里我们就不讲解。
上面对ResNet介绍了很多,接下来我们看下利用ResNet50来处理一个目标检测问题,简单地说就是我们检测指定的图片中是否存在指定的目标。这明显是一个二分类问题,有或者没有就行。
那我们梳理下处理这个问题的过程:
1.收集数据集===2.处理数据集===3.构建ResNet50网络模型===4.训练===5.测试===6.优化
1.收集数据集
我们使用Pascal VOC的数据集
地址:https://pjreddie.com/projects/pascal-voc-dataset-mirror/
我这里使用了2007的训练集和测试集,别问为什么,问就是因为它小啊。
2.处理数据集
解压训练集和测试集之后,我们开始处理数据了,我看了下图片接近5000张,这个如果一次性加载的话,贫穷的我应该加载不了吧,OOM应该是肯定的。不过不用担心,数据集都帮我们整理好了,我们就以汽车检测为例吧,找到压缩文件夹下的
VOCtrainval_06-Nov-2007\VOCdevkit\VOC2007\ImageSets\Main这个路径下存放着我们需要的目标索引
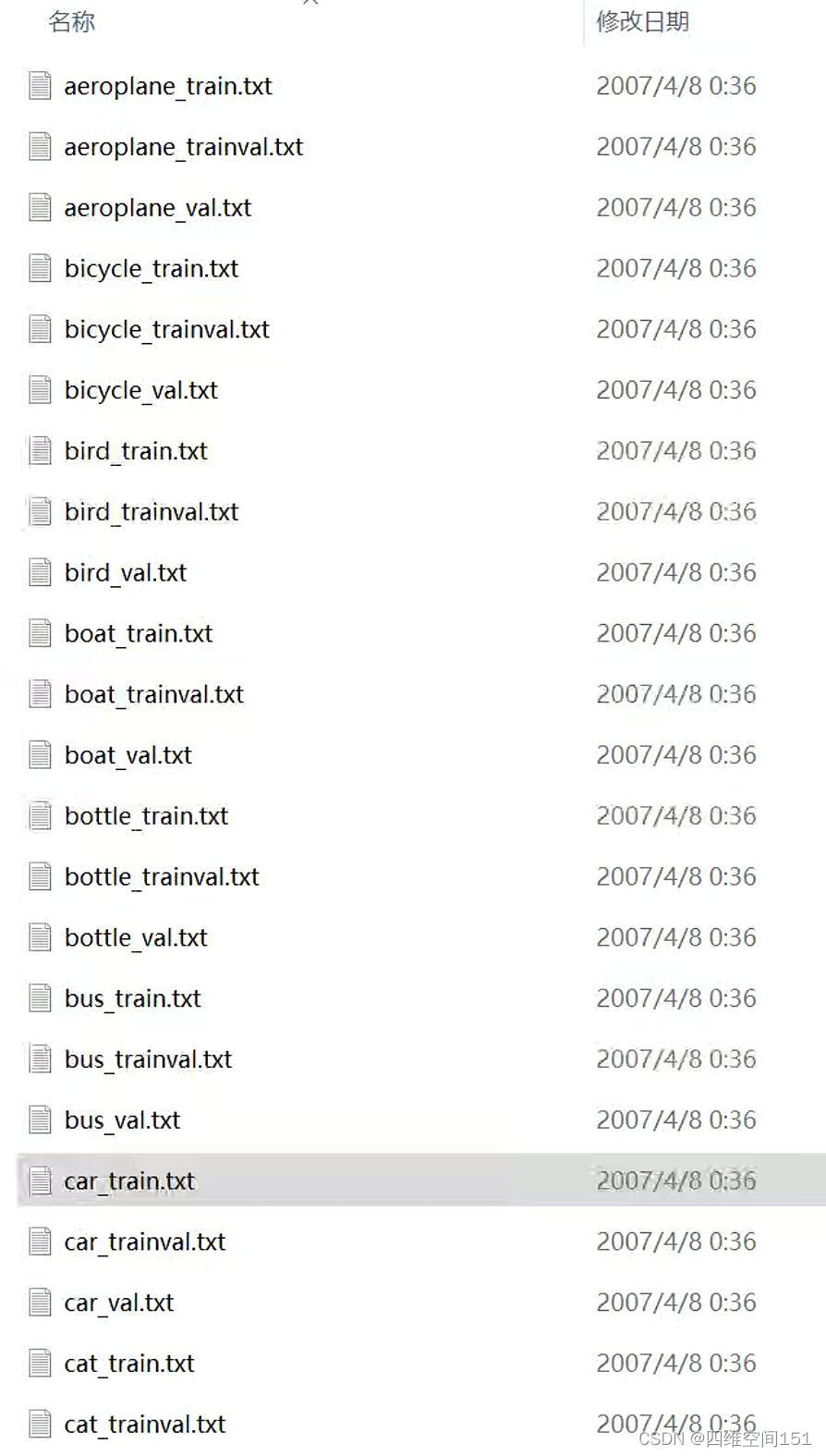
我们看到内容分类还是比较丰富的,我们选择"car_train.txt",打开文件之后,我们先了解下它的结构
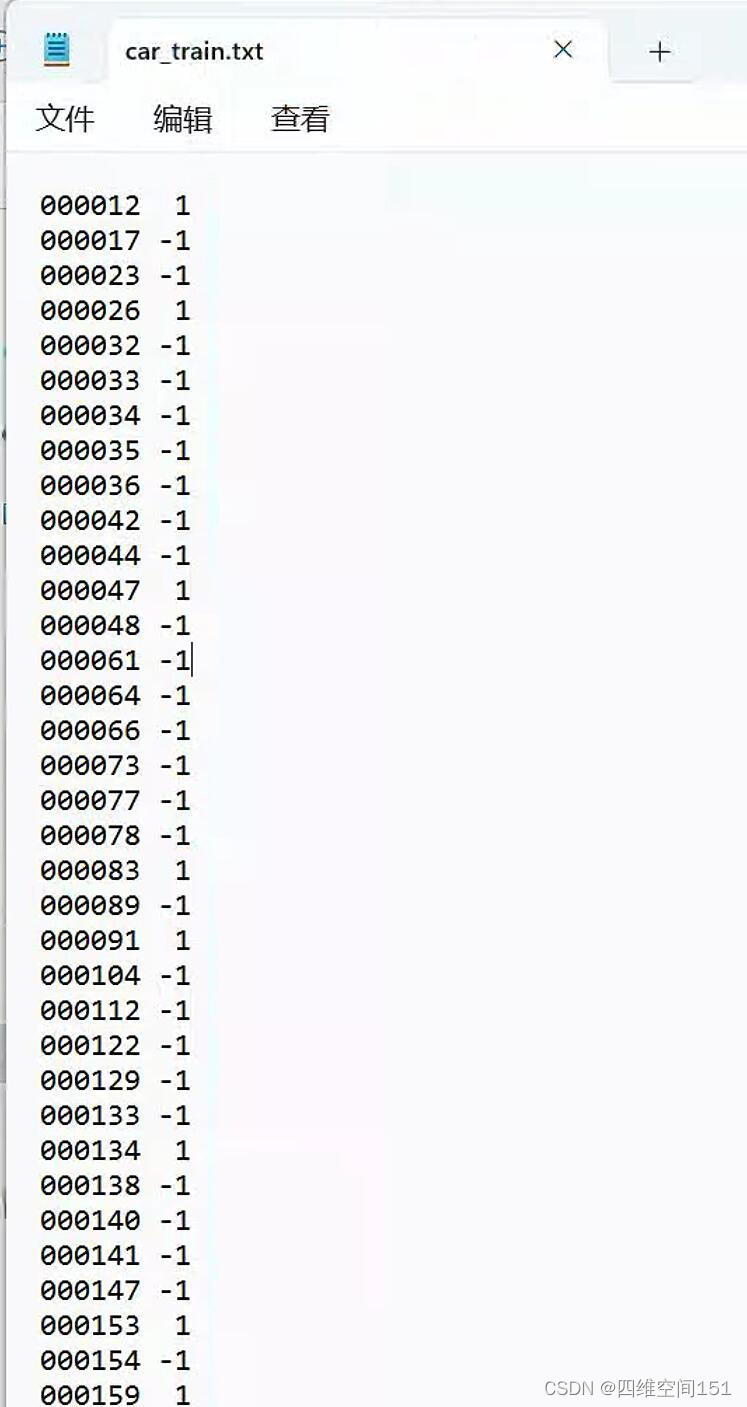
它的结构比较简单,第一列是图片的文件名 第二列是标签1表示存在,-1表示不存在。图片的位置在
\VOCtrainval_06-Nov-2007\VOCdevkit\VOC2007\JPEGImagesdef load_train(file_name):
file_name=file_name+".txt"
path=os.path.join(txt_root,file_name)
images=[]
labels=[]
global batch_size
while True:
with open(path,'r',encoding='utf-8') as f:
for line in f:
name, label =line.split()
label=int(label)
if label<0:
label=0
img_path = os.path.join(img_root,name+'.jpg')
image = cv2.imread(img_path)
image = image_plus(image)
image = cv2.resize(image,(input_size,input_size))
images.append(image)
labels.append([label])
if len(images)>=batch_size:
yield np.array(images),np.array(labels,dtype=np.uint8)
images=[]
labels=[]以上代码是加载训练集的代码,测试集也是如此,基本上一致。
3.构建ResNet50网络模型
这里我没有采用预训练的ResNet模型和权重,自己构建了一个
def resnet50_model(nb_classes=1):
global input_size
# 定义输入的tensor类型,shape于输入图像相同
X_input=Input(shape=(input_size,input_size,3))
X=ZeroPadding2D((3,3))(X_input)
#stage 1
X=Convolution2D(filters=64,kernel_size=(7,7),strides=(2,2),kernel_initializer=glorot_uniform(seed=0))(X)
X=BatchNormalization(axis=3)(X)
X=Activation('relu')(X)
X=MaxPooling2D((3,3),strides=(2,2))(X)
#stage 2
X=convolutional_block(X,f=3,filters=[64,64,256],s=1)
X=identity_block(X,f=3,filters=[64,64,256])
X = identity_block(X, f=3, filters=[64, 64, 256])
# stage 3
X=convolutional_block(X,f=3,filters=[128,128,512],s=2)
X=identity_block(X,f=3,filters=[128,128,512])
X = identity_block(X, f=3, filters=[128,128,512])
X = identity_block(X, f=3, filters=[128,128,512])
# stage 4
X = convolutional_block(X, f=3, filters=[256, 256, 1024], s=2)
X = identity_block(X, f=3, filters=[256, 256, 1024])
X = identity_block(X, f=3, filters=[256, 256, 1024])
X = identity_block(X, f=3, filters=[256, 256, 1024])
X = identity_block(X, f=3, filters=[256, 256, 1024])
X = identity_block(X, f=3, filters=[256, 256, 1024])
# stage 5
X = convolutional_block(X, f=4, filters=[512, 512, 2048], s=2)
X = identity_block(X, f=3, filters=[512, 512, 2048])
X = identity_block(X, f=3, filters=[512, 512, 2048])
# 平均池化
X =AveragePooling2D((2,2))(X)
#输出层
X=Flatten()(X)
X=Dense(nb_classes,activation='sigmoid',kernel_initializer=glorot_uniform(seed=0))(X)
model=Model(inputs=X_input,outputs=X)
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'],
)
return model当然,大家也可以采用keras自带的,这些都一样的没有什么。loss采用了binary_crossentropy 对应的激活函数 sigmoid。
4.训练
def train():
model = resnet50_model(1)
model.fit_generator(generator=load_train('car_train'),
steps_per_epoch= math.ceil(2501/batch_size)+1,
epochs=50,
validation_data=load_vaild('car_test')
)这里采用小批量训练,减少内存的消耗。
5.测试
测试的效果咋一看还行,但是,我还是发现了问题。
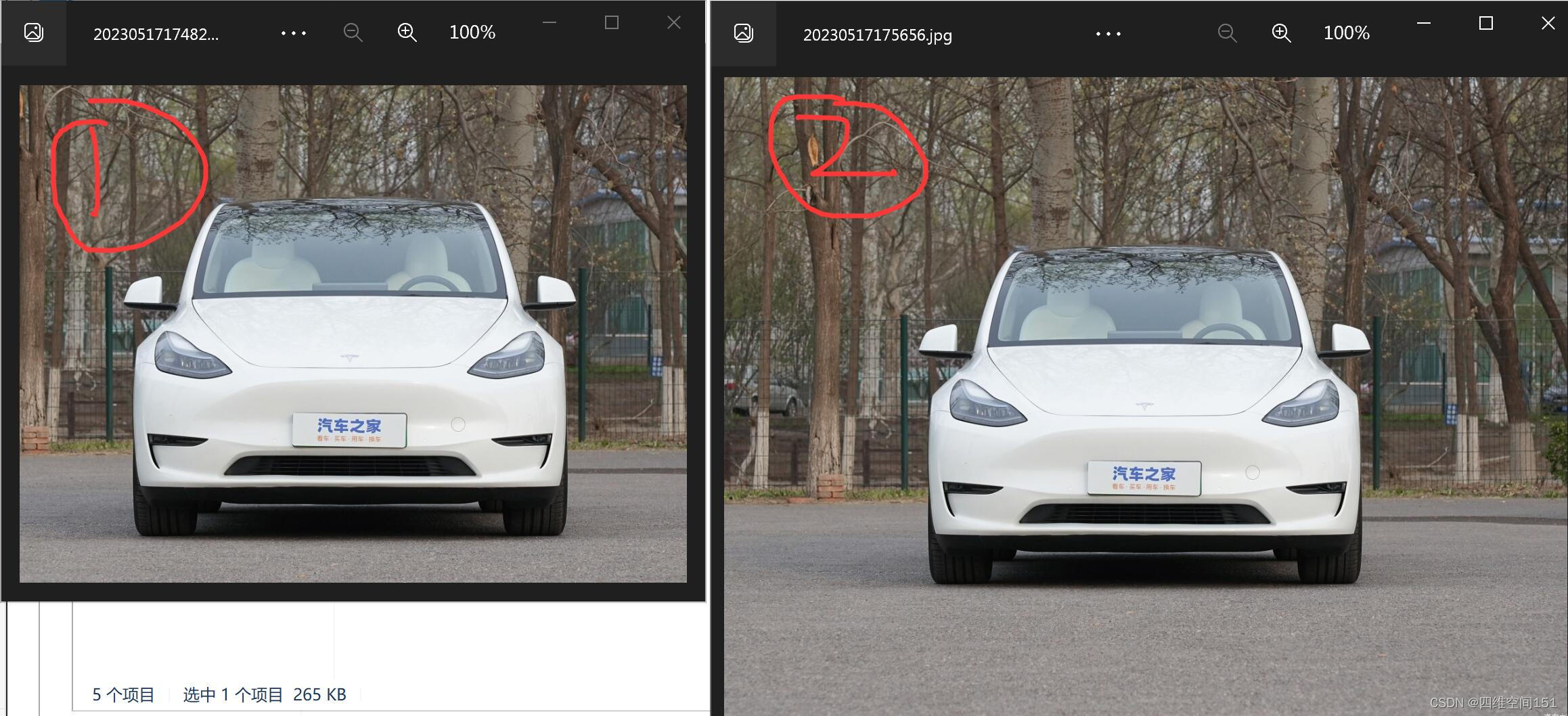
模型能够很好地识别2号图片,但是并不能很好地识别1号图片,这是为什么呢?这两张图片都来自于网络,不是来自于样本里的任何数据,出现这样的结果,说明我的模型出现了泛化能力差、鲁棒性差的现象。
6.优化
经过分析,我发现,导致这样的原因还是因为我的样本数据都比较规整,没有更多的干扰或者说训练图片特征没有学习到位。这个是时候我想到了一个词图像增强包括反转,旋转,缩放。
# 图片增强
def image_plus(img):
idx = np.random.randint(low=1,high=4,dtype=np.uint8)
if(idx==1): #随机缩放
return random_scale(img,input_size+10)
if(idx==2): #随机翻转
return random_flip(img,0.5)
if(idx==3):
angle = np.random.randint(10,360)
return random_rotate(img,angle)我的思路比较简单,在生成器生成图片的时候将图片随机进行处理,这样增加了图片的多样性。经过50轮的训练(为什么是50轮呢,因为我迫不及待地想看一下我的猜测)
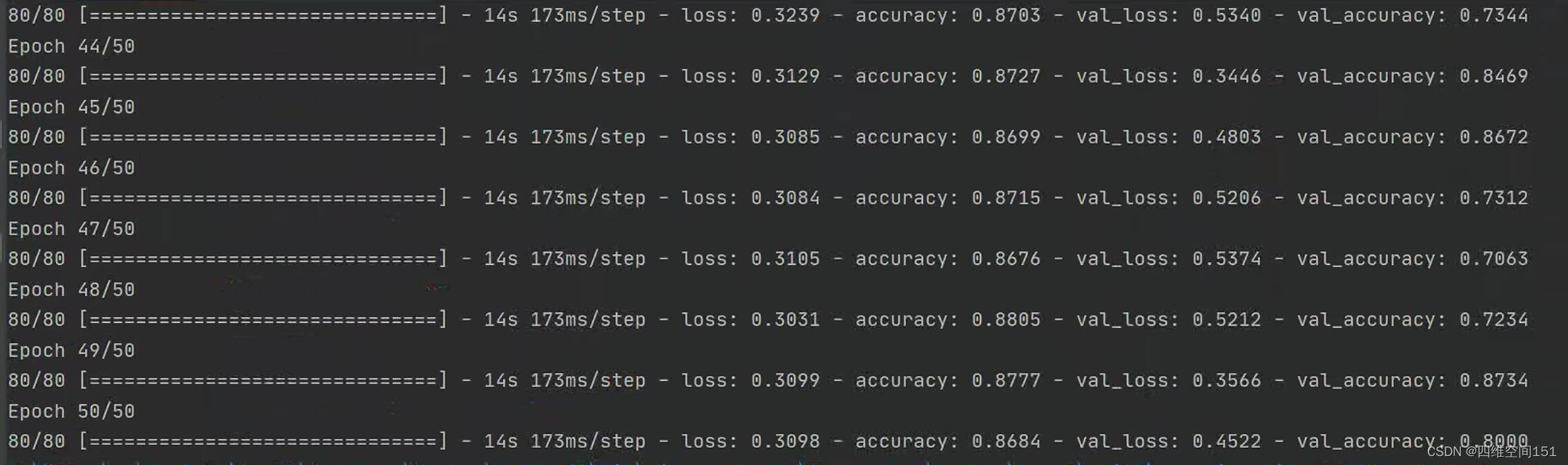
86%的正确率,这样的正确率还有上升的空间,不过这不重要。我们看下这两者图的预测情况吧。
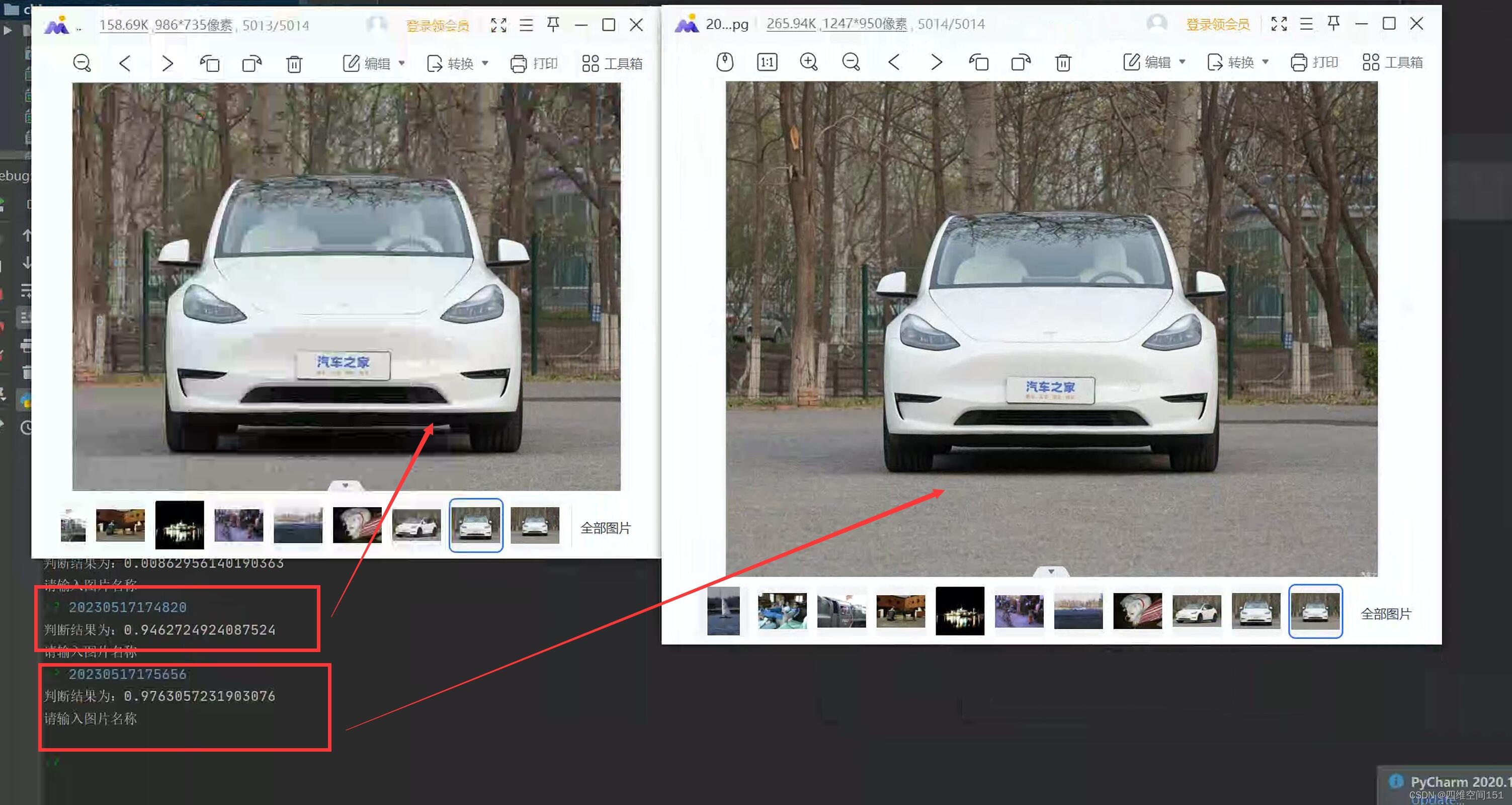
我们发现两者都是非常接近1了,尤其是1号图片,由检测错误,直接就转为成功了,两者之间的差异0.03的差异,是不是就代表着两者非常接近了呢?
好了,今天就给大家介绍完了,我对ResNet的目标检测还是非常满意的,拜拜下次见。
如有疑问请添加群:195889612

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









