







第三章 函数
在面向过程的结构化程序中,函数是模块划分的基本单位,是对处理问题过程的一种抽象。在面向对象程序设计中,函数同样有着重要的
作用,它是面向对象程序设计中对功能的抽象。一个C++程序可以由主函数与若干个子函数组成,主函数是程序的入口,主函数可以调用子函数,子函数又可调用其他子函数。
3.1 函数的定义与使用
函数的定义
类型说明符 函数名(含类型说明的形式参数列表){
语句序列
return 表达式(属于函数类型说明符的变量或常量)
}
形式参数:作用是实现主调函数与被调函数之间的联系。通常形参是函数所处理的数据、影响函数功能的因素或者函数处理的结果。在函数没有被调用时,形参只是标志在形参出现的位置应该是一个什么类型的数据,只有在函数被调用时,主调函数会将实际参数赋值给形参。
函数返回值:函数的返回值是将处理结果返回给主调函数,函数的类型说明符确定了返回值的类型。return除了是返回处理结果之外,还有一个作用就是结束当前函数的执行。
函数的调用
1. 直接调用
在函数调用之前,需要对函数进行声明,而函数的定义就属于函数的声明,一般来说我们在进行了函数的定义之后就可以直接调用这个函数了,但是如果想要在定义这个函数之前调用它,那么需要在调用函数之前写上这个函数的声明。
//想要在定义函数之前调用该函数,需要先对函数进行声明
#include <iostream>
using namespace std;
double power(double,int);
int main()
{
int value = 0;
cout << "Enter an 8 bit binary number:" ;
for(int i =7;i>=0;i--){
char ch;
cin>>ch;
if(ch=='1'){
value+=static_cast<int>(power(2,i));
}
}
cout<< "Decimal value is :"<<value<<endl;
return 0;
}
double power(double x,int n){
double val = 1.0;
while(n--){
val*=x;
}
return val;
}
如上面代码所示,如果我们不加上power函数的声明,那么主函数是无法识别需要调用的power函数的。如果函数power在主函数之前定义的,那么久不需要再对power进行声明了。
#include <iostream>
using namespace std;
//判断是否为回文,可以用除10取余的方法,从最低位开始依次取出该数的各位数字,然后最低位充当最高位,按反序的方式重组,与原数进行比较
//判断n是否为回文
bool symm(unsigned n){
unsigned i = n;
unsigned m = 0;
while(i>0){
m = m*10+i%10; //逆序输出
i = i/10;
}
return m==n;
}
int main()
{
for(unsigned m =11;m<1000;m++){
if(symm(m)&&symm(m*m)&&symm(m*m*m)){
cout<<"m= "<<m;
cout<<" m*m= "<<(m*m);
cout<<" m*m*m="<<(m*m*m)<<endl;
}
}
return 0;
}
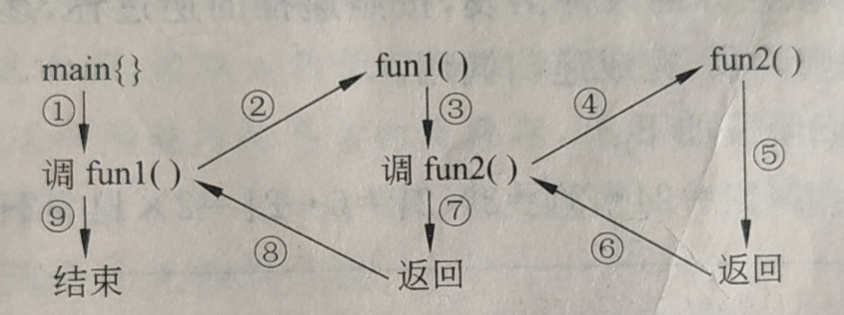
2. 嵌套调用
嵌套调用是指,如果函数1调用了函数2,函数2又调用函数3,这样形成嵌套调用。
#include <iostream>
using namespace std;
int fun2(int m ){
return m*m;
}
int fun3(int i,int j){
return fun2(i)+fun2(j);
}
int main()
{
int a,b;
cout<<"please enter a and b: ";
cin>>a>>b;
cout << "the sum of square of a and b is : " <<fun3(a,b)<<endl;
return 0;
}
3. 递归调用
函数可以直接或间接的调用自身,称之为递归调用。递归算法的实质就是将原有的问题分解成新的问题,然后新的问题又需要原来问题的解法。每次出现的新的问题都是原有问题的简化子集,最终将原有问题分解成已知解的子集。
- 递推:将原有问题不断分解成新的子问题,逐渐从未知推向已知问题,在得到已知问题后递推结束。
- 回归:从已知条件出发,按照递推的逆过程,逐一求值回归,直至从递推开始的处。
递推:5!=5x4! -> 4!=4x3! -> 3!=3x2! -> 2!=2x1! -> 1!=1x0! ->0!=1
回归:0!=1 -> 0!x1=1!=1 ->1!x2=2!=2 ->…-> 4!x5 = 5!=120
#include <iostream>
using namespace std;
unsigned fun2(unsigned m ){
if(m==0){
return 1;
}else{
return fun2(m-1)*m;
}
}
int main()
{
unsigned n;
cout<<"please enter n: ";
cin>>n;
cout <<n<< "!= " <<fun2(n)<<endl;
return 0;
}
例子:用递归算法从
n
n
n个人中选择
k
k
k个人。
n
n
n个人中选择
k
k
k个人=
n
−
1
n-1
n−1个中选择
k
k
k个人+
n
−
1
n-1
n−1个人中选择
k
−
1
k-1
k−1个人,所以我们可以用递归公式求。递归出口为
n
=
k
n=k
n=k或
k
=
0
k=0
k=0,这时候组合数为1,然后开始递归。
#include <iostream>
using namespace std;
int comm(int n,int k){
if(n<k){
return 0;
}else if(n==k||k==0){
return 1;
}else{
return comm(n-1,k)+comm(n-1,k-1);
}
}
int main()
{
int n,k;
cout << "Enter two integer n and k:";
cin>>n>>k;
cout<<"comm(n,k)= "<<comm(n,k)<<endl;
return 0;
}
//运行结果如下
Enter two integer n and k:18 5
comm(n,k)= 8568
例2:汉诺塔递归实现
将n个盘子从A移动到C可以分解成以下三个步骤:
- 将A上 的 n − 1 n-1 n−1个盘子移动到B上(通过C)
- 将A上剩余的一个盘子移动到C上
- 将B上的 n − 1 n-1 n−1个盘子移动到C上(通过A)
#include <iostream>
using namespace std;
void move(char A, char C){
cout<<A<<"--->"<<C<<endl;
}
void hanoi(int n,char A,char B,char C){
if(n==1){
move(A,C);
}else{
hanoi(n-1,A,C,B);
move(A,C);
hanoi(n-1,B,A,C);
}
}
int main()
{
int m;
cout << "Enter the number of diskes: ";
cin>>m;
cout<<"the step to moving"<<m<<"diskes: "<<endl;
hanoi(m,'A','B','C');
return 0;
}
//运行结果为:
Enter the number of diskes: 3
the step to moving3diskes:
A--->C
A--->B
C--->B
A--->C
B--->A
B--->C
A--->C
函数参数传递
在函数没有被调用的时候,函数的形参不会占用实际的内存空间,当函数被调用时,会将实参赋予形参,同时为形参分配内存。函数中的参数传递其实指的就是形参和实参的结合方式。主要分为两类:值传递和引用传递。
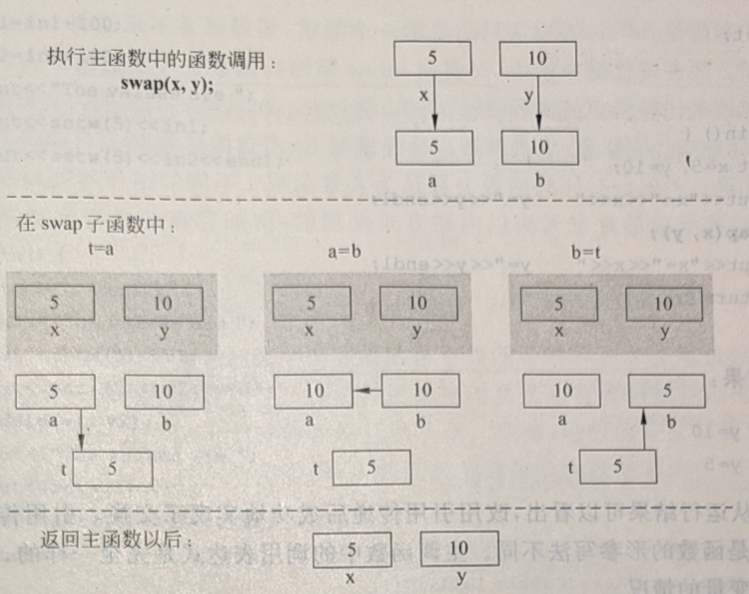
1. 值传递
值传递是指当发生函数调用时,给形参分配内存空间,并用实参来初始化形参,也就是赋值操作。值传递中只是参数值的单向传递过程,意思是一旦形参在获得值后就与实参脱离关系,之后形参不论发生什么变化,都不会影响实参。这是因为在给形参赋值后,形参在内存中有特定的位置,这样形参和实参在内存中的位置不相同,所以改变形参的值不会影响实参的值。
#include <iostream>
using namespace std;
void swap(int x,int y){
int t = x;
x = y;
y = t;
cout<<"The reslut in the function ====> ";
cout<<"x= "<<x<<"y= "<<y<<endl;
}
int main()
{
int x = 5,y = 10;
cout<<"x= "<<x<<"y= "<<y<<endl;
swap(x,y);
cout<<"x= "<<x<<"y= "<<y<<endl;
return 0;
}
//运行结果为:
x= 5 y= 10
The reslut in the function ====> x= 10 y= 5
x= 5y= 10
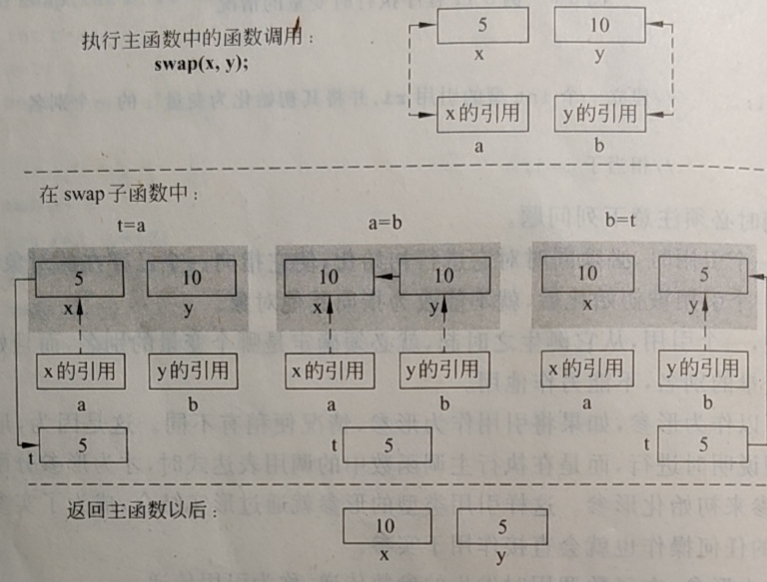
2. 值传递
引用是一种特殊类型的变量,可以被认为是另一个变量的别名。当引用作为形参时,只有在执行主调函数中的调用表达式时,才会为形参分配内存空间,同时用实参来初始化形参。引用类型的形参与实参相结合,成为了实参的一个别名,当对形参有任何操作时会直接作用于实参。
- 声明一个引用时,必须同时对它初始化,使他指向一个已存在的对象。
- 一旦一个引用被初始化后,就不能再改为指向其他对象。
#include <iostream>
using namespace std;
void swap(int &x,int &y){
int t = x;
x = y;
y = t;
}
int main()
{
int x = 5,y = 10;
cout<<"x= "<<x<<" y= "<<y<<endl;
swap(x,y);
cout<<"x= "<<x<<" y= "<<y<<endl;
return 0;
}
//运行结果为:
x= 5 y= 10
x= 10 y= 5
//值传递和引用传递的区别
#include <iostream>
#include <iomanip>
using namespace std;
void findll(int &x,int y){
x = x+100;
y = y+100;
cout<<"the values are:";
cout<<setw(5)<<x;
cout<<setw(5)<<y<<endl;
}
int main()
{
int x = 5,y = 10;
cout<<"the values are:";
cout<<setw(5)<<x; //setw(5)表示输出间隔,表示中间有4个空格。
cout<<setw(5)<<y<<endl;
findll(x,y);
cout<<"the values are:";
cout<<setw(5)<<x;
cout<<setw(5)<<y<<endl;
return 0;
}
//运行结果为:
the values are: 5 10
the values are: 105 110
the values are: 105 10
3.2 内联函数
我们使用函数是为了实现代码的重用,提高开发效率,增强程序的可靠性,也便于分工合作,便于修改维护。但是运用函数也会降低程序的运行效率,同时增加时间和空间开销。所以,对于一些功能单一的函数,我们设计为内联函数。内联函数不是在调用时发生控制转移,而是在编译时将函数体嵌入每一个调用处。
//内联函数也可以不需要inline修饰。
#include <iostream>
using namespace std;
const double PI = 3.14159265358987;
inline double calArea(double r){
return PI*r*r;
}
int main()
{
double r = 3.0;
double area = calArea(r);
cout<<area<<endl;
return 0;
}
3.3 带默认形参值的函数
函数在定义时也可以预先声明默认的形参值,如果调用时给出了实参值,那么实参将初始化形参,若没有实参进行初始化,那么将采用默认形参值。
有默认值得形参必须在参数列表的最后面,也就是说在有默认形参值得后面不能出现无默认值的形参。在相同作用域内不允许同一个函数的多个声明中对同一个参数的重复定义,即使前后定义的值相同也不行。
#include <iostream>
using namespace std;
/**
int add(int x,int y = 5,int z = 6); 表达正确
int add(int x = 5,int y = 6,int z); 表达错误
int add(int x = 5,int y,int z = 7); 表达错误
**/
int add(int x = 5,int y = 6);
int main()
{
int result;
reslut = add();
cout<<result<<endl;
return 0;
}
int add(int x/*=5*/,int y/*=6*/){ //如果这里的定义了默认值,那么不符合要求,这是因为之前声明已经赋予了函数参数的默认值。
return x+y;
}
函数重载
函数重载意思与一词多义类似,例如:擦皮鞋、擦桌子、擦车等。都是使用擦,但是擦的作用不同,使用的方法也截然不同。推及到程序设计中,我们就使用函数重载的方法来实现相同函数的不同功能。
两个以上的函数,具有相同的函数名,但是形参的个数或者类型不同,编译器根据形参的个数或类型,自动确定调用哪一个函数,这就是函数的重载。(函数是否重载不以形参名称和函数的返回值来判断,同时要注意默认参数的函数,因为容易出现二义性)
#include <iostream>
using namespace std;
int sumOfSquare(int x,int y){
return x*x+y*y;
}
double sumOfSquare(double a,double b){
return a*a+b*b;
}
int main()
{
int m,n;
cout<<"Enter two Integer:";
cin>>m>>n;
cout<<"their sum of square: "<<sumOfSquare(m,n)<<endl;
double a,b;
cout<<"Enter two real number:";
cin>>a>>b;
cout<<"their sum of square: "<<sumOfSquare(a,b)<<endl;
return 0;
}
//运行结果为:
Enter two Integer:3 5
their sum of square: 34
Enter two real number:2.3 5.8
their sum of square: 38.93
3.6 函数的运行栈
全局变量:变量的定义全部都写在函数之外,在程序运行开始就会为其分配内存地址。
局部变量:变量的定义全部都在一个函数之内,一旦函数返回后,局部变量就会失效,所以它的生存周期远小于整个程序的运行周期,同时如果出现了递归调用,那么相同的局部变量会有不同的值 ,所以像全局变量那样为局部变量分配唯一确定地址是行不通的。局部变量的存储方式使用栈这样的数据结构来进行存储。
运行栈实际上是一段区域的内存空间,与存储全局变量的空间相同,只是寻址的方式不同。运行栈中的数据被分为一个个的栈帧,每个栈帧对应一次函数调用,栈帧中包含这次函数调用的形参值、一些控制信息、局部变量值和一些临时数据。
3.7 小结
本章主要介绍的是在程序编写中函数的作用,以及函数的书写方式。函数编写好以后便可以被重复使用,使用时只关心函数的功能和使用方法,而不必关心函数的具体实现。这样有利于代码重用,提高开发效率。















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









