






业务背景介绍
进入数字时代后,数据的有效使用成为零售企业颠覆传统的动力,也势必将改变零售业的格局。
零售业有非常多的场景需要广泛地使用机器学习来进行数据分析,例如通过对供应链数据的分析,发现库存的规律性变化,合理优化物流环节达到减少库存、提高流通率的目的。对顾客购买数据的分析可以得到顾客的画像,从而为其个性化推荐产品。也可以发现商品的销售模式,从而灵活地调整定价或销售方式。
案例描述
本案例的目的是建立一个销售预测模型,使得公司可以预测每个产品在特定商店的销售情况,从而可以提前调整物流、完善备货渠道,以较高的效率完成销售流程。
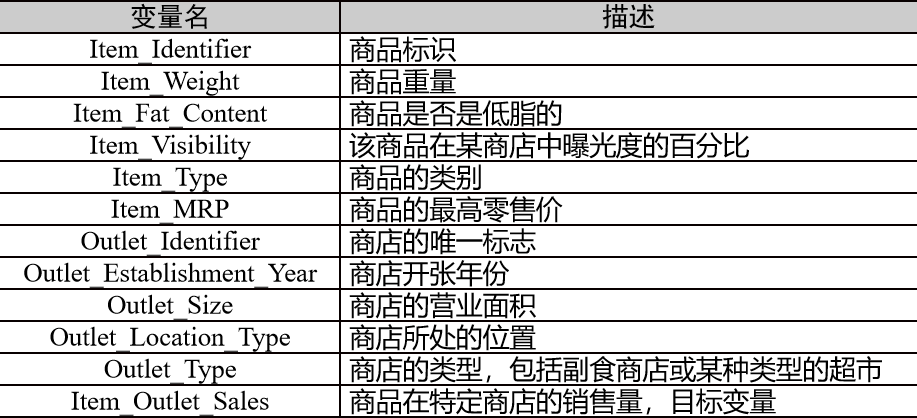
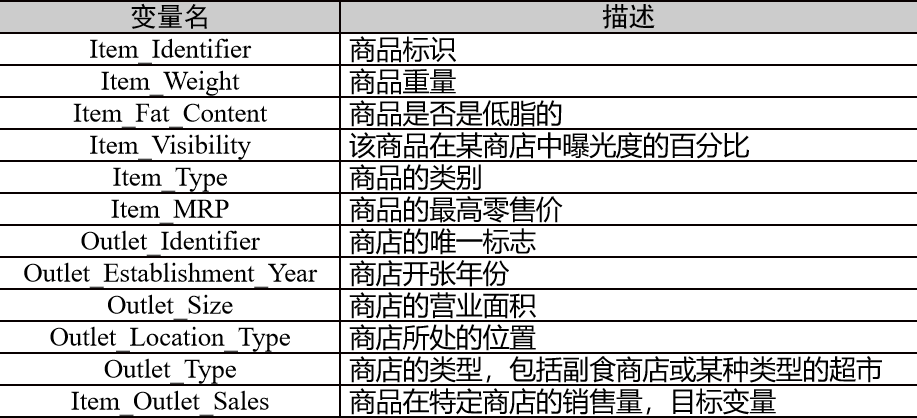
提供的数据表示不同城市10家商店的1559种产品在2013年的销售数据,还定义了每个产品和商店的属性。数据共有12个字段,其中“Item_Outlet_Sales”字段为目标预测值,下表是各个字段的描述。
任务
本案例将预测商品在各家商店的销售额。这是一个回归问题,要求使用线性回归、Ridge回归、Lasso回归算法构建模型,并对结果进行对比分析
代码演示
import pandas as pd
import numpy as np
#数据读取
train=pd.read_csv('./data/train.csv')
test=pd.read_csv('./data/test.csv')
## 查看数据中的缺失值
train.isnull().sum()
##发现存在Item_Weight 和 Outlet_Size 缺失值
#%%
## Outlet_Size
### 思路一:查看两个表中是否存在相同Outlet_Identifier的数据,用相同Outlet_Identifier的Outlet_Size值填充缺失值
### 思路二:若无思路一的情况,考虑缺失值数据量较大,对该列进行删除处理
#%%
#train
print('存着数据的Outlet_Identifier:',train[train['Outlet_Size'].notnull()]['Outlet_Identifier'].unique())
print('存在Outlet_Size 缺失的Outlet_Identifie:',train[train['Outlet_Size'].isnull()]['Outlet_Identifier'].unique())
#%%
#经过探索发现,无思路一情况,因此采取思路二,将该列删除X = X.drop(["Outlet_Size"], axis=1)
train = train.drop(["Outlet_Size"], axis=1)
#%%
##Item_Weight 的空值处理
#思路,用相同Item_Identifier的平均值填充
#%%
train['Item_Weight']=train['Item_Weight'].fillna(0)
data1=train[train['Item_Weight']!=0]
data1=data1.groupby('Item_Identifier').agg({'Item_Weight':'mean'})
#%%
Item_Weight_dict=data1.to_dict()['Item_Weight']
#%%
list_=[]
for i in train['Item_Identifier'].unique():
for j in train[train['Item_Identifier']==i]['Item_Weight']:
if j!=0.0:
list_.append(j)
else:
list_.append(Item_Weight_dict.get(i))
train['Item_Weight']=list_
train['Item_Weight']=train['Item_Weight'].round(2)
# #剩余的缺失值用平均值替换
train['Item_Weight']=train['Item_Weight'].fillna(train["Item_Weight"].mean())
#%%
#处理缺失值结果
train.isnull().sum()
#%%
# 通过探索发现Item_Visibility 列存在大量0值,不和常理,修正异常值0 把Item_Visibility 特征中大量的0值, 修正为平均数
visibility_avg = train.pivot_table(values='Item_Visibility', index='Item_Identifier')
visibility_zero = (train['Item_Visibility'] == 0)
print('Item_Visibility 为0值的总数:%d' % sum(visibility_zero))
train.loc[visibility_zero, 'Item_Visibility'] = train.loc[visibility_zero, 'Item_Identifier'].apply(lambda x: visibility_avg.loc[x])
visibility_zero = (train['Item_Visibility'] == 0)
print('Item_Visibility 为0值的总数:%d' % sum(visibility_zero))
#%%
#查看 Item_Weight,Item_MRP,Item_Outlet_Sales有无小于0的异常值
print(train[train['Item_Weight']<0].shape[0])
print(train[train['Item_MRP']<0].shape[0])
print(train[train['Item_Outlet_Sales']<0].shape[0])
#%% md
### 数值化和独热编码
对非数字型属性 进行 转化
#%%
from sklearn.preprocessing import LabelEncoder
#%%
#观察数据发现,共有一下几列为文本数据,利用LabelEncoder数值化
# Item_Fat_Content,Item_Type,Outlet_Identifier ,Item_Identifier ,Outlet_Location_Type , Outlet_Type
labelEncoder= LabelEncoder()
text_col = ['Item_Fat_Content', 'Outlet_Location_Type', 'Outlet_Type', "Item_Type", "Item_Identifier",'Outlet_Identifier']
for i in text_col:
train[i] = labelEncoder.fit_transform(train[i])
train.head()
#%%
train.to_csv('./now_data/train_now.csv')
#%% md
## test数据预处理
#%% md
### 数据探索(处理缺失值和异常值)
#%%
## 查看数据中的缺失值
test.isnull().sum()
##发现存在Item_Weight 和 Outlet_Size 缺失值
#%%
## Outlet_Size
### 思路一:查看两个表中是否存在相同Outlet_Identifier的数据,用相同Outlet_Identifier的Outlet_Size值填充缺失值
### 思路二:若无思路一的情况,考虑缺失值数据量较大,对该列进行删除处理
print('存着数据的Outlet_Identifier:',test[test['Outlet_Size'].notnull()]['Outlet_Identifier'].unique())
print('存在Outlet_Size缺失的Outlet_Identifie:',test[test['Outlet_Size'].isnull()]['Outlet_Identifier'].unique())
#%%
#经过探索发现,无思路一情况,因此采取思路二,将该列删除X = X.drop(["Outlet_Size"], axis=1)
test = test.drop(["Outlet_Size"], axis=1)
#%%
##Item_Weight 的空值处理
#思路,用相同Item_Identifier的平均值填充
test['Item_Weight']=test['Item_Weight'].fillna(0)
data1=test[test['Item_Weight']!=0]
data1=data1.groupby('Item_Identifier').agg({'Item_Weight':'mean'})
Item_Weight_dict=data1.to_dict()['Item_Weight']
list_=[]
for i in test['Item_Identifier'].unique():
for j in test[test['Item_Identifier']==i]['Item_Weight']:
if j!=0:
list_.append(j)
else:
list_.append(Item_Weight_dict.get(i))
test['Item_Weight']=list_
test['Item_Weight']=test['Item_Weight'].round(2)
#剩余的缺失值用平均值替换
test['Item_Weight']=test['Item_Weight'].fillna(test["Item_Weight"].mean())
#处理缺失值结果
test.isnull().sum()
#%% md
### 数值化和独热编码
对非数字型属性 进行 转化
#%%
from sklearn.preprocessing import LabelEncoder
#观察数据发现,共有一下几列为文本数据,利用LabelEncoder数值化
# Item_Fat_Content,Item_Type,Outlet_Identifier ,Item_Identifier ,Outlet_Location_Type , Outlet_Type
labelEncoder= LabelEncoder()
text_col = ['Item_Fat_Content', 'Outlet_Location_Type', 'Outlet_Type', "Item_Type", "Item_Identifier",'Outlet_Identifier']
for i in text_col:
test[i] = labelEncoder.fit_transform(test[i])
test.head()
#%%
test.to_csv('./now_data/test_now.csv')
#%% md
## 创建模型
#%%
from sklearn.linear_model import LinearRegression, Ridge
from xgboost import XGBRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import pandas as pd
from sklearn import metrics
import numpy as np
#读取数据
train=pd.read_csv('./now_data/train_now.csv',index_col='Unnamed: 0')
test=pd.read_csv('./now_data/test_now.csv',index_col='Unnamed: 0')
def mae(y_true, y_pred):
"""平均绝对误差"""
return np.mean(abs(y_true - y_pred))
#数据标准化
y = train["Item_Outlet_Sales"]
X = train.drop(["Item_Outlet_Sales"], axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
#%% md
### RandomForestRegressor
#%%
rfs=RandomForestRegressor()
rfs.fit(X_train,y_train)
y_predict = rfs.predict(X_test)
error = mae(y_test, y_predict)
print("平均绝对误差为:\n", error)
print("均方根误差 : %.4g" % np.sqrt(metrics.mean_squared_error(y_test, y_predict)))
#%% md
### Ridge回归
#%%
ridge=Ridge()
ridge.fit(X_train,y_train)
y_predict = rfs.predict(X_test)
error = mae(y_test, y_predict)
print("平均绝对误差为:\n", error)
print("均方根误差 : %.4g" % np.sqrt(metrics.mean_squared_error(y_test, y_predict)))
#%% md
### LinearRegression
#%%
lrg=LinearRegression()
lrg.fit(X_train,y_train)
y_predict = lrg.predict(X_test)
error = mae(y_test, y_predict)
print("平均绝对误差为:\n", error)
print("均方根误差 : %.4g" % np.sqrt(metrics.mean_squared_error(y_test, y_predict)))
#%% md
### XGBRegressor
#%%
xgb=XGBRegressor()
xgb.fit(X_train,y_train)
y_predict = xgb.predict(X_test)
error = mae(y_test, y_predict)
print("平均绝对误差为:\n", error)
print("均方根误差 : %.4g" % np.sqrt(metrics.mean_squared_error(y_test, y_predict)))
#%%
##综合考虑,使用RandomForestRegressor
#%%
rfs=RandomForestRegressor()
rfs.fit(X,y)
#预测
test_predict=rfs.predict(test)
test['Item_Outlet_Sales']=test_predict
#保存数据
test['Item_Outlet_Sales']=test_predict
test.to_csv('./now_data/test_predict.csv')
#%%


















 1828
1828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











