









在之前的文章对象检测之行人检测(2)中介绍了Piotr Dollar的聚合通道特征算法,在今天我们则来谈一谈检测界另一位大牛Ross B. Girshick的RCNN算法以及在它基础上的改进。这位大神也是提出处理遮挡很有效的可形变模型Deformable part models的作者之一。
- RCNN简介
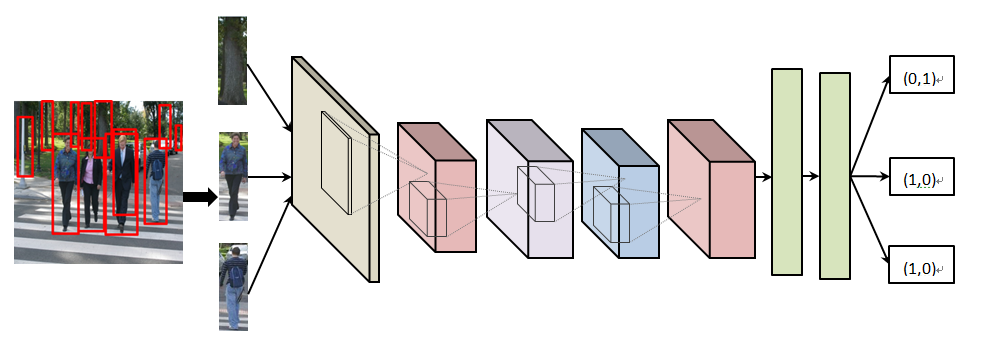
在传统的检测过程中,使用滑动窗口把图片扫描一遍,就把检测和分类一起做了,但是由于滑动窗口中使用的级联分类器要尽量简单,因此使得分类效果很好的算法无法发挥性能优势。后来人们在研究检测的过程中转换思路,我们能不能先对每张图像都用一种方法来提取N个框,并且不用去管每个框里面内容到底是什么,而对这些框的要求就是尽可能多的召回图片中的正样本。之后再对每个框都做归一化之后,送入到一个卷积神经元网络来完成分类。经过这样的设置,检测问题和图像分类问题不就很好的结合了吗,而那些分类性能非常厉害的AlexNet、VGGNet、GoogLeNet就都可以用了哈。在这个过程中,提框的方法有Selective Search,BING,EdgeBox等。在行人检测里则可以用聚合通道特征算法(参考上一篇对象检测之行人检测2)来做提框的这一步。使用这种方法的示意图见图1。
图1 ACF+RCNN方法示意图 - SPP-Net设置
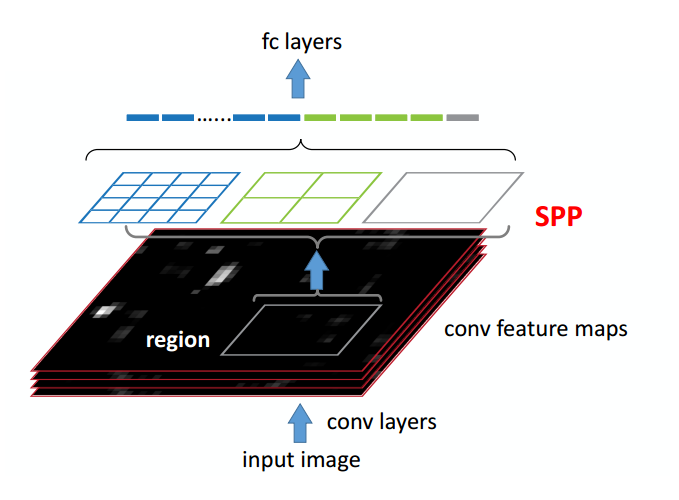
使用了RCNN的方法之后,在分类过程中可以充分发挥卷积神经元网络的性能,而前期的提框算法则只需要关注受检行人的召回率。因此这样的设置让各个阶段的优化目标更加清晰,从而可以达到更好的检测效果。但是在RCNN的方法中需要将每个窗口都做一遍尺寸归一化,再把这些窗口放到CNN里做分类,这样对于很多相互重叠的窗口,他们的重叠部分就被计算了很多遍的卷积特征,从而拖慢检测的速度。因此,微软的大神们就想,计算卷积特征时是没有限定输入维度的,只是分类的时候需要统一维度的向量,那么可不可在前期将整幅图像(而非每个待分类窗口)丢到CNN里计算,同时把所有候选框也丢入网络中做映射,然后直接在网络中卷积层的最后一层通过一定手段统一不同窗口的维度,而空间金字塔Spatial Pyramid Matching,SPM刚好可以起到统一不同尺寸窗口的特征维度的作用。因此SPP就这样做了。示意图见图2。
图2 SPP-Net示意图
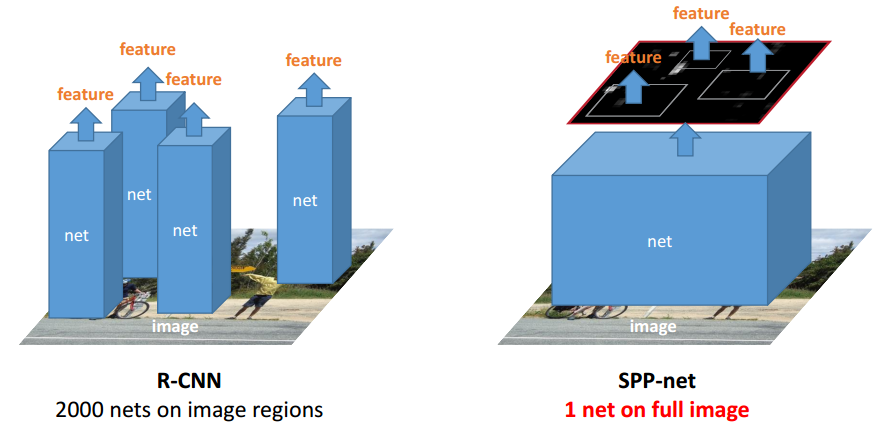
其中RCNN与SPP-Net的最大区别就在于是否对重叠窗口做了重复的卷积特征提取。二者的不同如示意图3描述。
图3 RCNN与SPPNet对比图 - Fast-RCNN
在SPPNet之后,RGB大神根据它修改了RCNN的设置,发布了Fast-RCNN,他与RCNN的主要不同点就在于纳入了SPPNet中空间金字塔池化层的加速策略。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









