







这是我的课程论文,写的时候发现针对性的内容很少,因此写完后放出来供大家参考。水平欠佳,劳烦赐教。
公式原来是用 latex 敲的,因为有些语法是扩展的,懒得再和 markdown 折腾了
面向深度学习的缓存替换算法
摘要:本文针对深度学习的落地痛点进行了分析并提出通过改善高速缓存替换算法的方式来提升深度学习的落地能力。具体而言,我们从降低能耗、存储介质材料、降低算法实现难度、综合考虑各级存储、结合机器(深度)学习等方面都进行了详细的分析并给出了几种可行的改进思路。
关键字:缓存;替换算法;深度学习;机器学习
1. 引言
今天的人工智能可以取得如此辉煌的进步,很大程度上要归功于深度学习的蓬勃发展。虽然近几年来深度学习在图像识别、语音处理、机器翻译、智慧城市等领域都取得了一些落地成果,但无比庞大的计算量仍然是深度学习难以得到广泛推广应用的痛点之一。
在高性能计算机系统中,内存性能往往是最为关键的问题之一,其中对高速缓存的改进更是提升内存性能最简单、最经济有效的方法[1]。幸运的是,训练深度学习模型的过程体现了非常强的空间局部性和时间局部性(如对计算机视觉领域的卷积神经网络而言,当核遍历到某个位置时,核周围的数据紧接着就会被访问;自然语言处理领域广泛使用的自注意力机制、长短期网络等都会综合考虑以往访问过的数据),这使得我们可以针对性地对现有的缓存替换算法进行改进,从而有效提高深度学习的落地能力。
2. 降低能耗
2.1 背景
20 年前,一个仅提供数据存储和内容分发的数据中心的电力需求就能以每年 100W/ft2 的速度增长,对应的能源成本几乎以每年 25% 的速率增长[2]。对现代存储体系结构(图 2.1.1)的数据中心而言,存储器几乎是最大的能源消耗,各种开销大约占据了总能源消耗量的 27%[3]。

图 2.1.1 现代存储体系结构
20 年后深度学习蓬勃发展,各类大数据应用层出不穷的今天,存储器市场的需求每年还保持着不低于 60% 的攀升比例[4]。近几年 Google、Microsoft、Nvidia、阿里巴巴、腾讯等互联网公司在深度学习、大数据等领域掀起了一股超巨大模型的风气,仅 2017 年 Google 提出 Transformer 模型到 2021 年短短的 4 年间,深度学习模型的参数大小已经断崖式上涨到了 10 万亿(2021 年 11 月阿里巴巴达摩院以分布式的方式使用 512 张 Nvidia Tesla 训练 10 天得到的超大规模通用性人工智能模型 M6-10T)。
Nvidia 在 2021 年 5 月曾经公布过一个 2.5T 参数大小的模型训练成本,其中仅电力需求就相当于一个小型核电厂的全年发电量。更糟糕的是,存储器性能的提高会导致更高的功率和更多的通信耗费,一个用于信号处理的嵌入式应用程序仅内存通信就耗费了总功率的 50~80%[5]。因此,降低能耗是深度学习发展必须直面的一个关键问题。
2.2 传统方法存在的问题
针对缓存和存储器存在的高能耗问题,传统方法主要有两种解决方式,一种是根据运行情况让存储器在休眠和运行两种状态间切换,另一种是以高计算量为代价对存储器进行动态管理。
采用休眠-运行策略的存储器只能工作在全功率模式下的运行状态,虽然休眠状态下的能耗远低于运行状态,但存储器从休眠状态转变为运行状态时会产生非常大的延迟和能耗[6]。此外,受到传统功率模型的限制,采用休眠-运行策略的存储器访问空闲时间过短,不适应其昂贵的开机、休眠成本[7–10]。
以高计算量为代价的算法通常比较复杂,还需要对每个工作负载进行繁琐的参数调优,难以应用于实际系统。PA-LRU[11]是这类算法中的一个典型例子,它至少有四个参数,每个参数都需要根据当前工作负载、运行情况等进行动态调整,因此很难找到一组适用范围较广的参数。此外,PA-LRU 算法的许多参数与存储器能耗、响应时间等没有直接关系,很难通过对原有算法的扩展来实现自适应参数调优。
2.3 算法方面的改进
对于休眠-运行策略,当下主流的方法是通过引入多级中间态进行动态管理[9,10]。与休眠-运行策略下的全功率模型相比,多级中间态模型能耗更低,不同转速间切换所需的延迟和能耗也远低于全功率模型。遗憾的是,多级中间态模型在硬件实现上还存在一些难题,难以缓解当下的高计算量问题。
对现实存储系统运行情况的大量统计结果表明,性能最优(命中率最高)的缓存替换算法并非是能耗最优的,存储系统运行过程中各级子系统、各分区的负载也并不服从均匀分布[11]。因此在不影响缓存性能的前提下,可以通过牺牲部分缓存命中率的方式来降低存储器能耗。PB-LRU[6]给出了一种可行的改进思路,它提出针对各级子系统、各级分区设计缓存替换算法来降低整个系统的失效率,进而能量最优问题[11]转换为多重背包问题采用动态规划求解。
假设整个存储系统的大小为 S,首先将整个存储系统划分为 n 个子系统 {1…n},再将每个子系统划分为 m 个分区,对应大小 0 < p1 < p2 < …< pm <= S。令 xij 表示子系统 i 是否存在大小为 j 的分区,E(i, s) 为 s 大小的存储器所对应的能耗,整个问题转换为:
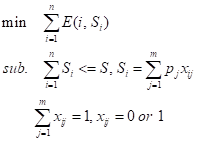
由于多重背包是一个 NP-Hard 问题,因此当前还无法在多项式时间复杂度内完成求解。PB-LRU[6]使用动态规划完成了求解,对应状态转移公式如下所示:
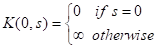
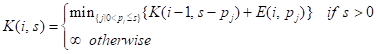
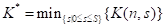
算法中各分区的大小是影响最后结果的一个重要因素,对此 PB-LRU 做了大量仿真实验,得到的最优划分如图 2.3.1 所示
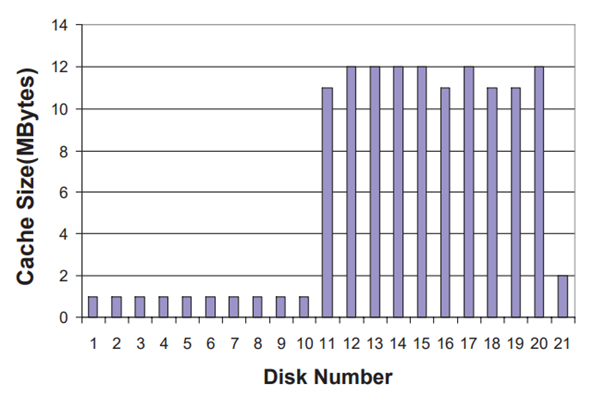
图 2.3.1 PB-LRU 最优分区划分
动态存储器管理的另一个难点在于如何综合功耗、失效率、命中率等各个指标来合理、实时地评估现在的效益。马特森栈算法以跟踪文件的方式来实时确定所有不同大小的缓存的命中率曲线[12,13],但并不能给出不同分区大小下的能耗曲线[6]。PB-LRU 在马特森算法的基础上进行了改进,较好地解决了这一问题,估计值较真实值的误差仅有 1.8%(图 2.3.2),具体步骤如下所示:
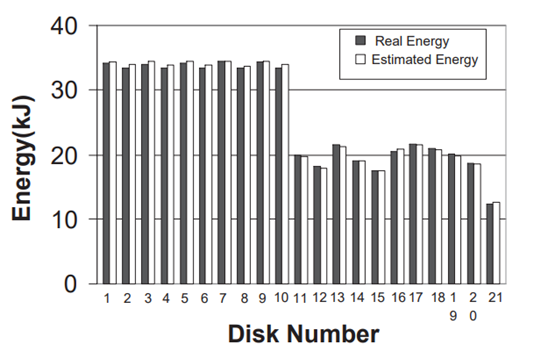
图 2.3.2 PB-LRU 改进马特森栈算法的能耗估计结果对比
首先使用马特森栈算法确定不同分区大小的请求是否会导致缓存命中或错过。如果一个请求在大小为 p 及其所有更小的分区中未命中,那么该请求将会访问相应的存储器。当我们知道了对这个存储器的最后访问时间,我们就可以根据底层电源管理方案估计出从最后一次操作到当前操作的能源消耗。如果确定了实际的的功耗管理方案,我们就可以计算空闲期间消耗了多少能量,包括从休眠状态切换到全速状态所需的能量。
在每次更新栈的时候完成下列操作
① 在适当存储器的堆栈中搜索请求的块编号,如果它是堆栈顶部的第 i 个元素,即把它的深度设置为 i;如果没有找到,那么将其深度设置为 ∞。
② 对于所有小于当前深度的分区大小都增加他们的能源消耗估计,并且将之前累计的失效时间合并到当前的访问时间中。
③ 使用与真实缓存相同的替换策略更新堆栈并将请求的块编号带到堆栈的顶部。
PB-LRU 在不同的基准程序上的实验结果如图 2.3.3 ~ 图 2.3.8 所示
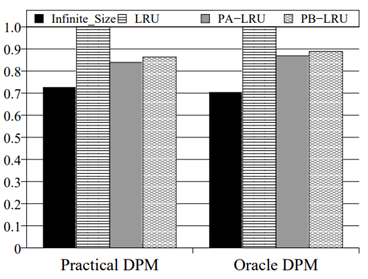
图 2.3.3 能耗对比 (OLTP)
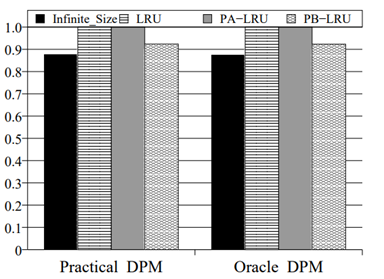
图 2.3.4 能耗对比 (Cello96)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2443
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









