









文章目录
【获取资源请见文章第5节:资源获取】
1. 原始蚁狮优化算法
蚁狮优化算法模模仿了自然界中蚁狮在捕猎蚂蚁时的智能行为。
1.1 蚂蚁随机游走公式
随机游走在数学上的表达式为:
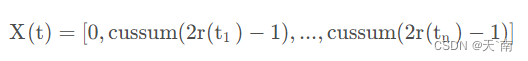
其中,cussum为计算累加和,n为最大迭代次数,t为随机步长,r(t)取0或者1。
为了保证在搜索空间内随机游走,而不超出搜索空间,对其进行归一化:
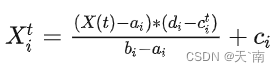
其中,ai和bi表示第i个变量随机游走的最小和最大值,cit和dit表示第t次迭代第i个变量的最小值和最大值。
1.2 设置陷阱
蚂蚁的游走行为受到蚁狮陷阱的影响,模型这一行为的数学表达式为:
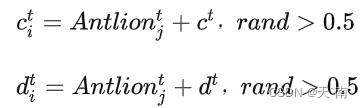
其中,ct和dt分别表示第t次迭代所有变量的最小值和最大值,Antlionjt表示第t次迭代第j个蚁狮的位置。
1.3 陷阱诱惑蚂蚁
针对此行为有如下数学公式:

1.4 捕获猎物并重建洞穴
蚁狮把蚂蚁拉到沙子里吃掉,为了模仿这一过程,假设当蚂蚁变得比相应的蚁狮更适合捕食时(进入沙地)。然后,蚁狮需要更新自己的位置到被捕食蚂蚁的最新位置:
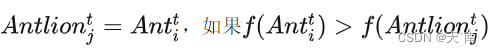
2. 改进蚁狮优化算法
2.1 连续性边界收缩因子
在基本 ALO 算法中蚂蚁围绕陷阱游走阶段,其边界即搜索范围逐渐缩小,以开发陷阱邻域最优值。但是边界收缩因子 I 的变化呈现间断增大趋势,其间断式增大易导致蚂蚁遗漏部分区域,使算法易错过最优值。针对以上问题,为了增强算法的遍历性,使其更全面地搜索求解空间以及提高算法收敛速度,提出一种随着算法迭代进化而快速连续增大的边界收缩因子。
新的蚂蚁游走边界更新公式为:
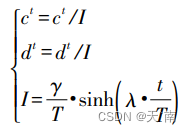
2.2 位置更新动态权重系数
在精英化阶段,蚂蚁根据轮盘赌选择蚁狮和精英蚁狮行为以更新位置,但是由于精英蚁狮具有最优适应度值,有较大概率被选作轮盘赌选择蚁狮,导致蚂蚁只绕精英蚁狮游走,而降低算法全局探索能力。针对上述问题,将基于迭代次数的动态权重系数引入蚂蚁位置更新公式:

权重系数k1 在迭代前期较大,使蚂蚁在搜索空间内探索更优区域; 而在后期,精英蚁狮邻近最优区域,其权重系
数 k2 逐渐增大,使蚂蚁在最优区域邻域开发,以此提高算法全局探索与局部开发的平衡能力。
3. 部分代码展示
I=(400/max_iter)*sinh(20*current_iter/max_iter); %% 改进1:连续性边界收缩因子
% Dicrease boundaries to converge towards antlion
lb=lb/(I); % Equation (2.10) in the paper
ub=ub/(I); % Equation (2.11) in the paper
for i=1:size(ant_position,1) % 返回ant_position的行数,就是蚂蚁数量
% Select ant lions based on their fitness (the better anlion the higher chance of catching ant)
Rolette_index=RouletteWheelSelection(1./sorted_antlion_fitness); % RouletteWheelSelection意思是轮盘赌
if Rolette_index==-1
Rolette_index=1;
end
% RA is the random walk around the selected antlion by rolette wheel
RA=IAOL_Random_walk_around_antlion(dim,Max_iter,lb,ub,Sorted_antlions(Rolette_index,:),Current_iter);
% RA is the random walk around the elite (best antlion so far)
[RE]=IAOL_Random_walk_around_antlion(dim,Max_iter,lb,ub, Elite_antlion_position(1,:),Current_iter);
k1=...;%% 改进2:位置更新动态权重系数
k2=...;
ant_position(i,:)= ...;
end
4. 结果图展示
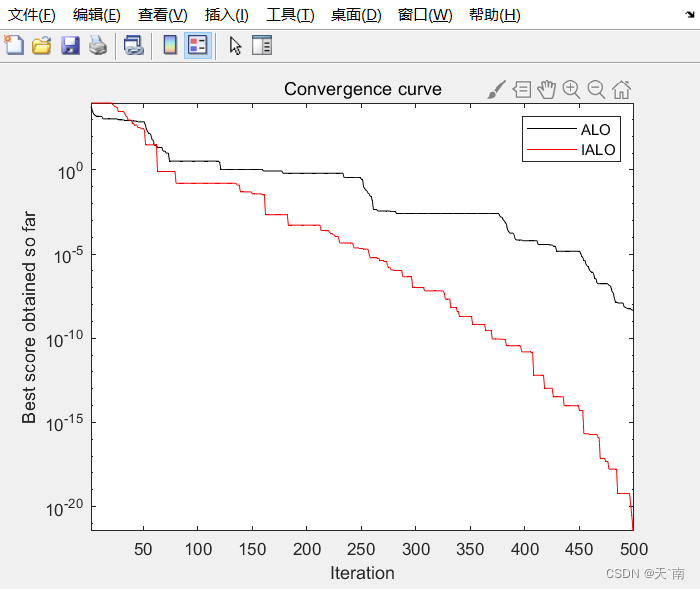
The best solution obtained by ALO is : 1.752e-06 -6.6015e-06 -4.5149e-05 3.3942e-05 2.8805e-05 4.5751e-06 -8.5604e-06 1.9466e-05 -4.9646e-07 1.2015e-05
The best optimal value of the objective funciton found by ALO is : 4.6847e-09
The best solution obtained by IALO is : 0 0 0 0 0 0 0 0 0 0
The best optimal value of the objective funciton found by IALO is : 0
5. 资源获取
可以获取完整代码资源。
















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











