






ITSM基础框架开发维护指南
目 录
3.5 框架配置文件(uniframework.properties) 10
4.3.2 多数据源(Multiple Data Source) 14
4.3.4 持久层基类及数据操作封装(PersistWare) 14
6.3.2 创建标签库描述文件(Tag Library Description) 77
-
前言
-
编写目的
-
Uniframework,即ITSM基础开发框架,以下简称"ITSM基础框架"。
作为ITSM产品的快速开发框架,Uniframework提供众多在运维项目中常用的基础服务以及专用功能封装,是ITSM产品研发的一个重要部分。
ITSM框架汇集了众多项目和骨干开发人员的开发经验,才最终形成现在的3.2版本。此前ITSM基础框架的开发和维护,通常集中在少部分骨干开发人员手上,因此不便以框架的应用和持续改进。现编写本文档对ITSM基础框架功能和设计进行较为全面性的讲解,以帮助部门开发人员和实习生深入掌握基础框架的应用和开发维护。使得ITSM基础框架可以不断改进完善,以应对新项目新业务带来的机遇和挑战,提高ITSM产品质量和定制开发效率。
-
适用对象
适用对象 | 适用范围 | 熟练程度 |
ITSM基础框架开发人员 | 框架开发维护 | 深入理解 |
ITSM产品设计人员 | 产品功能设计 | 熟练掌握 |
ITSM产品开发人员 | 功能模块开发 | 了解应用 |
-
快速上手
-
概述
-
ITSM基础构架基于主流的SSH框架开发,集成了一系列第三方产品及组件,经过不断演化完善已经成为一个功能强大相对成熟稳定的Web开发框架。有以下特点:
-
MVC分层架构设计
-
支持Servlet 2.5以上标准
-
支持JDK 1.6以上
-
创建项目
ITSM基础架构采用SVN进行版本控制,采用Maven进行版本管理。从SVN取出工程代码后,需要按常规的做法转换工程属性为Dynamic Web Project和Maven Project。这里不再详述。
项目创建后,IDE视图如下:
-
设置工程属性:
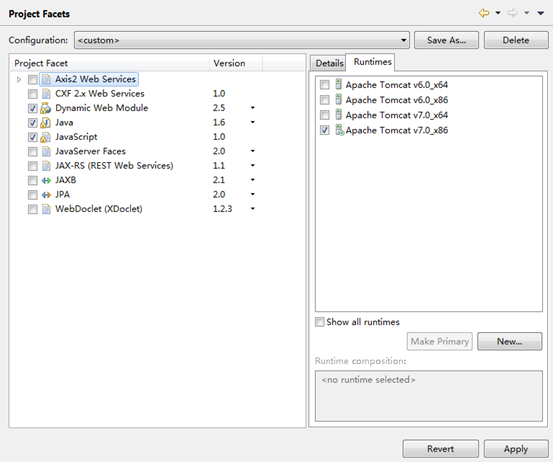
-
设置部署装配项:
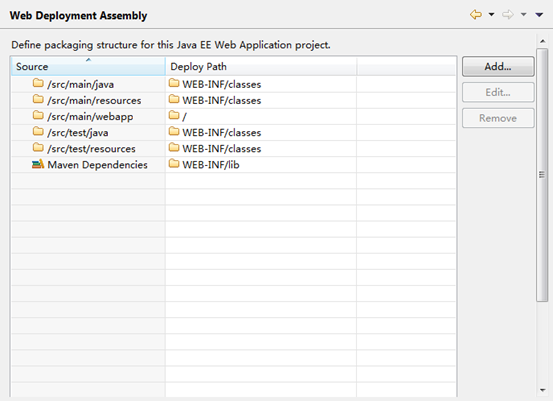
-
设置JRE运行时库:
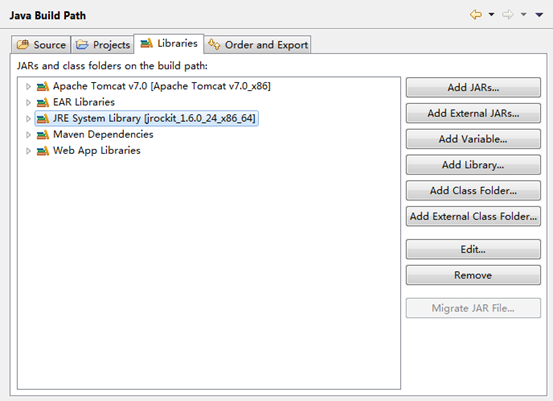
-
设置JDK编译器编译水平:
-
框架启动(Tomcat6/7)
ITSM基础框架,支持Tomcat6/7,Weblogic11g等32位和64位应用容器运行,同时支持Windows和Linux平台(经项目验证)。
在使用IDE中使用Tomcat进行ITSM基础框架开发调试时,需要注意几个问题。
-
设置Tomcat服务器的启动/关闭超时时间:

-
通过Add Web Modules配置ITSM基础架构启动方法:
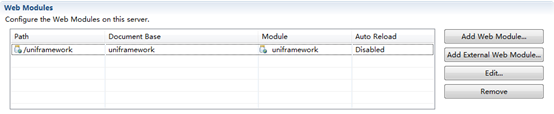
由于使用了Maven进行版本管理的缘故,目前框架只支持通过Web Modules的方式进行Publish&Startup,不支持直接通过指定Web目录进行热部署(ITSM产品工程则可以)。
-
框架入门
-
概述
-
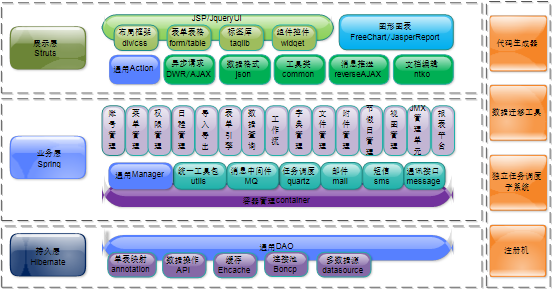
如上图,ITSM基础框架基于三层设计,整体可分为表现层,业务层,持久层。此外,还包含一些辅助支持工具。
-
框架启动过程(J2EE)
-
Web.xml
-
Web.xml里面有将2个listener、10个Filter、12个Servlet的配置。集成的功能很多,这里也不一一去介绍,大家可以去看下注释。主要把有关框架启动的几个重要配置进行说明。
-
应用系统启动监听器,ITSM框架启动的入口:
<listener>
<listener-class>org.wbase.framework.core.facade.UniContextListener
</listener-class>
</listener>
-
Struts请求分发过滤器,ITSM基础框架响应请求的方法:
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.wbase.framework.core.facade.UniStruts2Dispatcher
</filter-class>
</filter>
-
UniContextListener
监听器负责以下几件事情:
-
执行UniContextLoader类定义的Context初始化内容,包括有加载Spring配置主文件applicationContext.xml,加载应用模块和基础功能的spring定义文件等;
-
Context初始化后,开始初始化Logger日志组件;
-
然后初始化AppContext实例,写入应用名称、启动时间信息等;
-
接着执行由ContextInitBean标注的系统级启动初始类定义,框架大部分功能都在这里进行初始化,如加载外部数据源InitData,加载内置定时任务调度LoadUniframeworkJobs,准备Struts使用的HelperMethod配置集合等;
-
最后由RunWhenStartedBean标注的应用级启动初始类定义,应用层功能可以在这里进行初始化,如加载流程模块的扩展按钮操作定义OperationsLoader;
-
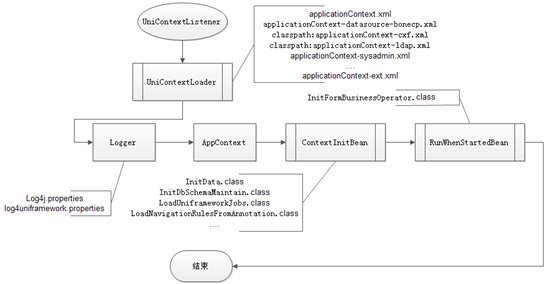
整个启动过程,可以通过一个流程图来描述:
图 ITSM基础框架启动过程流程图
-
UniStruts2Dispatcher
ITSM基础框架除支持Struts的声明式和全注解式配置功能外,自身也提供了一套原创的请求响应定义规则注解——HelperMethod。通过HelperMethod注解配置的Struts定义,由UniStruts2Dispatcher过滤器负责解释和装载。
UniStruts2Dispatcher过滤器启动流程如下:
-
-
过滤器初始化开始;
-
初始化内部类UniInitOperations,取得框架所有被ModuleConfig标注的模块化定义类,并加载其模块化定义信息中的Struts-xxx.xml配置文件所定义的导航信息;
-
重建Struts的dispatcher,并合并写入由ContextInitBean早就准备好的HelperMethod标注的导航信息;
-
过滤器初始化结束。
-
框架依赖库(Dependency)
ITSM基础框架所提供的众多功能,基本上都是由第三方库和组件提供。因此依赖jar包也是非常的多,这里就对现在版本引入的组件类型和对应jar文件做一个粗略的描述(由于使用Maven来管理,许多附加组件包相关或不相关的也会被引入,有些我也不知道是干嘛用的)。
这些第三方依赖库的具体用途和版本,可以直接到框架对应SVN工程中查看POM.xml配置文件。里面有较详细的注释说明(以下为POM定义片断):
-
框架模块化(Modular)
ITSM基础框架集成较多功能模块和基础服务,为增强框架可定制性提高启动速度及运行效率,框架本身基于模块化思想设计了一套功能模块和基础服务的动态配置加载方案。
-
模块定义
模块定义注解:@ModuleInfo,用于标注一个模块定义类。
模块定义接口:IUniModule,用于规范一个模块定义类应包含的基本信息。
public interface IUniModule
{
public String getModuleName();
public String getModuleVersion();
public String getModulePath();
public String getModuleAuthor();
public boolean isModuleLoadable();
}
-
模块加载
类ScanCustomPackages充当框架模块类加载器,在系统启动时UniContextLoader调用并装载所发现的所有模块定义类所定义的功能模块。所以,如果新开发的功能模块,不能被ITSM基础架构装载时,有可能就是对应的模块定义类没有正确配置。
示例,一个完整的模块定义类代码:
package org.wbase.framework.attach;
import org.wbase.framework.core.Constants;
@ModuleInfo
public class UniModuleInfo extends AbstractModuleInfo {
@Override
public String getModuleName() {
return "附件管理";
}
@Override
public boolean isModuleLoadable() {
return Constants.MODULE_ATTACH_LOADED;
}
}
-
框架配置文件(uniframework.properties)
ITSM框架采用统一的配置文件对系统初始化及运行时各种可定制功能进行配置。框架提供配置项已多达300多项,导致配置文件变得复杂。因此在定义新的配置项时,需要进行全局考虑及属性设置,不可盲目新增。
按功能分,系统配置项,可按以下分类,每个分类内容太多,将不再一一列出。有兴趣,可以查看框架配置文件,里面各配置项有详细的英文注释。
-

-
初始化
-
登录登出
-
开发模式/运行模式
-
Displaytag/xheditor全局设置
-
数据权限/功能权限
-
基础服务配置,如:AOP、JMX、短信/邮件/短消息、数据源连接信息、全文检索、任务调度、WebService、消息队列(MQ)、FTP服务器、Mina服务器、LDAP等
-
基础功能模块开关,如:日程管理、附件管理、工作日管理、文件管理、简表管理等
-
框架主体实现(SSH)
-
前端实现(Struts2)
-
概述
-
-
ITSM基础框架基于Struts2实现展示层架构,其中在Struts Filter/Interceptor/Processor等进行过程定制,同时,原创开发了一套基于自定义注解的请求分发机制(类似于Struts的全注解配置)。
以下展示了用户查看附件请求产生后,经过Struts2展示层"MVC模式"处理的总体过程示例。
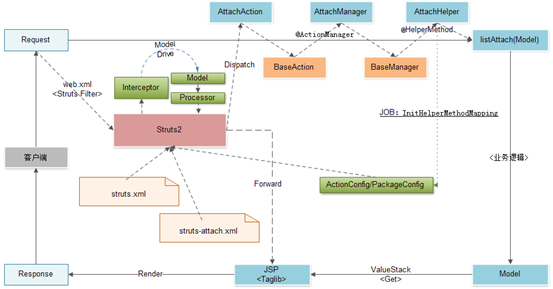
总体过程示例仅为帮助理解,详细的处理过程需要参看相关框架代码。
-
安全问题
应用Struts2作为框架展示层,那么就要考虑到Struts2可能带的安全设计问题。相关资料可参加Wiki内容:
http://192.168.1.55/pages/viewpage.action?pageId=119113170
-
业务层实现(Spring)
-
概述
-
了解基于Struts2的展示层请求分发过程后,就可以业务层Manager/Helper类开发业务处理逻辑了。那么ITSM框架基于Spring3实现的业务层支撑又是怎么个实现过程呢?
众所周知,Spring工作原理都是基于反射,并提供几个重要功能:IOC、DI(依赖注入)、AOP、Proxy(动态代理)。具体这些功能如何工作的,就不在这里细说,可以参考Spring相关技术文档。
以下,是附件管理(Attach)业务层实现的概览,反映了在ITSM基础框架上开发基于依赖注入实现的xml声明式配置以及使用上更加自由的注解式配置的依赖关系视图。
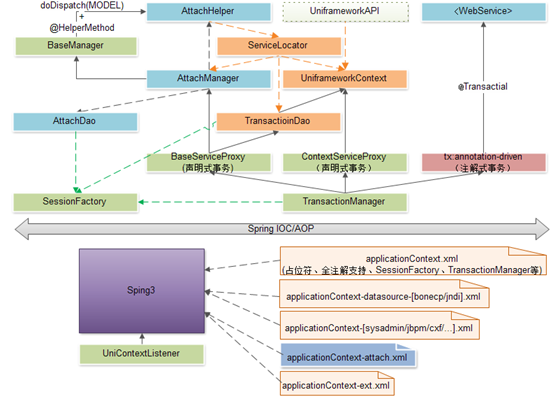
图中,蓝色部分体现了自定义开发功能所处的位置。其它颜色标记的部分,为基础框架所提供。总体过程示例仅为帮助理解,详细的处理过程需要参看相关框架代码及配置文件。
-
事务管理
要注意的一点是,框架在业务层的Manager类进行总体事务控制,Helper不进行声明事务,而在DWR方法或WebService方法中如需使用事务,需要采用@Transactional注解。
-
持久层实现(Hibernate)
-
概述
-
ITSM基础框架持久层,基于Hibernate3实现,支持hbm配置和全注解配置。
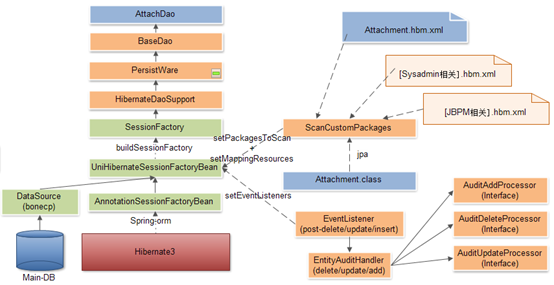
如图,显示了数据库通过bonecp连接池,注入到Hibernate3框架,并由Hibernate载入关系表映射文件或注解类,最后实例化为一个开发能使用的AttachDao Bean的主要过程。
其中,蓝色标记的部分,为平时开发所关注的内容;黄色部分为基础框架的支撑实现;绿色部分为第三方组件提供的功能服务。
-
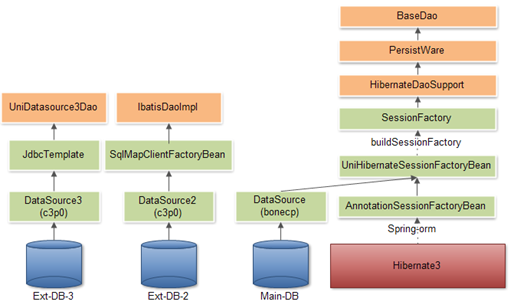
多数据源(Multiple Data Source)
ITSM框架提供多数据源支持。多数据源的框架可以体现为:
-
Bonecp提供的主数据源dataSource,由Hibernate使用;
-
C3p0提供的外部数据源二dataSource2,由iBaties使用;
-
C3p0提供的外部数据源三dataSource3,由Spring JDBC使用;
-
对象映射(Object Mapping)
支持hbm声明式配置和注解式配置两种方式,并且以注解式配置优化。
-
持久层基类及数据操作封装(PersistWare)
ITSM基础框架数据层基类PersistWare继承自HibernateDaoSupport,并进行适用于ITSM系统开发的核心数据操作API封装。
同时,在PersistWare的基础之上进行了BaseDao数据工具API的封装,对核心数据操作API进行了补充。
因此,我们在开发一个功能的持久层Dao类时,只要从BaseDao继承就可以得到基本满足持久层的大部分常见业务数据操作。代码犹为简洁,如下图所示:
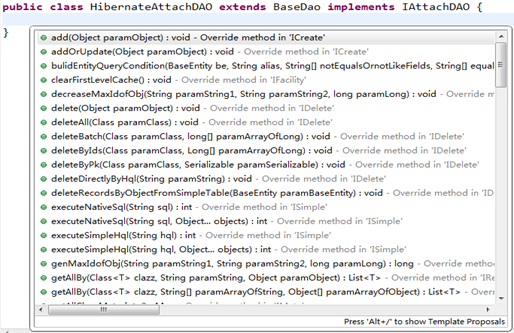
-
数据监听(Listener)
持久层由Hibernate托管,那么就可以使用Hibernate的实体监听功能。目前,ITSM框架对Hibernate的Post-Insert、Post-Delete、Post-Update事件进行了监听,相应的Event和Entity通过监听器传入EntityAuditHandler(实体审核处理器)。该处理器提供了对应ADD、Delete、Update的实体审核接口。可以根据需求通过实现对应的接口来注入业务功能。
通过Uniframework配置文件注入监听接口实现类:
ds.listener.delete.processor.class=org.wbase.framework.core.listener.audit.impl.DefaultAuditDeleteProcessor
ds.listener.update.processor.class=org.wbase.framework.core.listener.audit.impl.DefaultAuditUpdateProcessor
ds.listener.add.processor.class=org.wbase.framework.core.listener.audit.impl.DefaultAuditAddProcessor
-
一二级缓存(Cache)
ITSM基础框架使用EhCache为Hibernate3提供缓存支持。SessionFactory配置时,注入以下缓存配置属性:
<prop key="hibernate.cache.provider_class">${hibernate.cache.provider_class}</prop>
<prop key="hibernate.cache.region.factory_class">${hibernate.cache.region.factory_class}
</prop>
<prop key="hibernate.cache.use_query_cache">${hibernate.cache.use_query_cache}</prop>
<prop key="hibernate.cache.use_second_level_cache">${hibernate.cache.use_second_level_cache}
</prop>
其中,一级缓存(查询缓存)已默认生效。对于二级缓存,要使之生效,还需要在PersistWare持久层数据操作API封装类中,重写HibernateDaoSupport的相关方法,实现可配置的二级缓存启用开关:
protected HibernateTemplate createHibernateTemplate(SessionFactory sessionFactory) {
HibernateTemplate template = new HibernateTemplate(sessionFactory);
template.setCacheQueries(Constants.UNIFRAMEWORK_DAO_CACHE_ENABLED);
return template;
}
protected void enableSecondLevelCache() {
getHibernateTemplate().setCacheQueries(true);
}
protected void disableSecondLevelCache() {
getHibernateTemplate().setCacheQueries(false);
}
至此,在测试时可以发现,第一次执行语句查询时,Console会打印相关SQL的执行过程,但当第二次执行相同的查询语句时,Console将不会再打印相关的SQL语句。说明此时,二级缓存已生效。
-
框架基础服务(Service)
-
框架注解类(Annotation)
-
注解 | 功能 |
ActionManager.java | Action类注解,用于向其传递所关联的Manager实体Bean名称。 |
CommandBean.java | 通用服务可通过此注解,实现对外提供开放的功能,如验证码。其实就是类似于Servlet。 |
ContextDestroyBean.java | 框架停止时,执行指定操作。如关闭Quartz。 |
ContextInitBean.java | 框架启动时,执行指定操作。如记录启动时间。 |
EntityAuditable.java | Hibernate进行实体操作时,注入审核规则。如,删除用户时,检查操作人权限。 |
EntityBean.java | 持久层实体类的通用基类。 |
HelperEscape.java | 标注为非Helper类,以避开被Manager扫描到。 |
HelperMethod.java | 被Manager扫描到的Helper类,将根据本注解的配置信息生成Struts导航定义。 |
InitMethod.java | 框架启动时,查询并执行所有被本注解标注的方法。 |
MethodDataLimit.java | 通过本注解标注方法执行所需要的数据权限,由AOP拦截使用。(未完成) |
ModelArray.java | 将表单上的数组值传入Model对象的数组。 |
ModelCheckBox.java(*) | 将表单checkboxstr命名复选框数组值传入Model对象Strs变量。 |
ModelDate.java(*) | 将当时日期时间以yyyy-MM-dd hh:mm:ss传入Model对象curDateStr变量。 |
ModelDelete.java(*) | 将表单checkbox命名复选框数据值传入Model对象ids变量。 |
ModelMapping.java | 将表单中所有包含本注解配置信息所指定名称(默认为selectPvws)的对象域id数组值传入Model对象MapIds变量。 |
ModelMultiValue.java | 功能同ModelMapping,但本注解为将对象域(默认为selectPvws)的字符数组值传入Model对象MapVals变量。 |
ModelOrganize.java | 将当前会话中的登录人所在部门id传入Model对象curDepartmentId变量。 |
ModelReport.java | model.setExportFileName(ann.exportFileName()); model.setTemplateRelFullpath(ann.templateRelFullpath()); |
ModelRequest.java(*) | 将原始请求传入Model。 |
ModelResponse.java(*) | 将原始响应传入Model。 |
ModelSearch.java(*) | 将CompassSearchService、LuceneSearchService对象传入Model。 |
ModelServletContext.java(*) | 将当前ServletContext传入Model。 |
ModelSession.java(*) | 将当前会话传入Model。 |
ModelStaff.java(*) | 将当前会话中的登录人id传入Model对象curStaffId变量。 |
ModelFullFeature.java | 如果以上打(*)号的功能你都想要,可以直接使用本注解。 |
ModelTokenEnabled.java | 启用Struts的表单Token校验功能,用于防止表单重复提交。 |
ModuleConfig.java | Action类注解,用于指定该action所对应的Spring和Struts配置文件。 |
ModuleInfo.java | 基础框架功能模块入口类注解,每个模块通过本注解被框架发现。 |
QueryCondition.java | 未知 |
RunWhenStartedBean.java | 被本注解标注的类,将在基础框架启动完成后,自动执行jobName定义的操作。 |
SearchEntity.java | 被本注解标注的持久层类,将加入compass和lucene索引行列,实时进行索引构建和更新。 |
-
框架服务类(AnyWare)
好几个框架基础服务类,被实现为抽象接口,可以由目标类直接实现(implement)并使用其中提供的基础服务。
基础服务类 | 功能 |
EhCacheAnyWare | 使用框架提供EhCache服务 |
EmailAnyWare | 使用框架邮件发送服务 |
LogAnyWare | 使用框架日志打印服务 |
ServiceAnyWare | 使用框架Spring服务定位器(serviceLocator) |
SimpleCacheAnyWare | 使用简单HashMap缓存服务 |
SmsAnyWare | 使用框架短信发送服务 |
-
登录认证框架(Signon)
-
登录认证过程
-
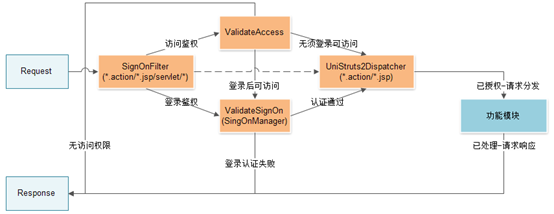
-
拦截
请求拦截由过滤器SignOnFilter完成,该过滤器在Web.xml中配置在Hibernate会话管理器(UniOpenSessionInViewFilter)之后,Struts2请求分发过滤器之前,作为最重要的过滤器。
这种做法,其实是为提高系统安全性考虑。可以进一步降低因Struts2安全问题而直接暴露系统漏洞的风险。
-
鉴权
-
访问鉴权
框架提供ValidateAccess类提供访问权限鉴定功能,实现无须登录访问及登录后访问两种url访问方式的处理。同时,在访问鉴权环节,也预留了接口,提供可扩展的访问策略接口支持,用于实现与第三方系统集成和登录认证,如LDAP。
-
登录鉴权
对于指定的登录URL请求和来自访问鉴权验证器传来的登录后访问URL请求,进入登录鉴权类ValidateSignon进行登录认证。登录鉴权类,提供多种登录鉴权方式,包括:Portal登录,E3SSO登录,LDAP域登录等。
成功通过登录认证的请求,将会记录下请求的最新时间,并调用FilterChain传入下一个过滤器UniStruts2Dispatcher进行请求分发处理。
-
登录认证
系统登录认证过程,由SignonManager类完成。该类,将接收到ValidateSignon类传入的登录类型和登录信息到数据库进行匹配验证。验证通过后,登录信息写入Session,并更新缓存中的在线用户信息,最后发送用户成功登录事件至登录监听器。
以上为用户登录认证过程的处理机制示意图:
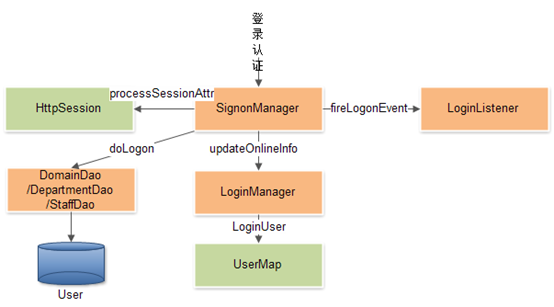
-
任务调度框架(Quartz)
-
基本概念
-
Quartz是一个开源的作业调度框架,它完全由java写成,并设计用于J2SE和J2EE应用中。它提供了巨大的灵活性而不牺牲简单性。你能够用它来为执行一个作业而创建简单的或复杂的调度。它有很多特征,如:数据库支持,集群,插件,EJB作业预构建,JavaMail及其它,支持cron- like表达式等等。
-
Job(接口)
用Quartz 的行话讲,作业是一个执行任务的简单java类。一旦实现了Job接口和 execute()方法,当Quartz确定该是作业运行的时候,它将调用你的作业。下面有一些你要在作业里面做事情的例子:
· 用JavaMail(或者用其他的像Commons Net一样的邮件框架)发送邮件
· 获取Hibernate Session,查询和更新关系数据库里的数据
· 使用Workflow并且从作业调用一个工作流
· 使用FTP到别处移动文件
· 调用Ant构建脚本开始预定构建
这种可能性是无穷的,正事这种无限可能性使得框架功能如此强大。Quartz给你提供了一个机制来建立具有不同粒度的、可重复的调度表。
-
JobDetail(任务表)
JobDetail表示一个具体的可执行的调度程序,Job是这个可执行程调度程序所要执行的内容,另外JobDetail还包含了这个任务调度的方案和策略。
-
Trigger(触发器)
Quartz 设计者做了一个设计方案来将调度跟作业分离开。Quartz中的触发器用来告诉调度程序作业应该什么时候触发。框架提供了很多类型触发器,其中最常用的是 SimpleTrigger和CronTrigger。
SimpleTrigger为需要简单触发调度而设计。典型地,如果你需要在给定的时间和重复次数或者两次触发之间等待的秒数触发一个作业,那么SimpleTrigger适合你。此外,如果你有许多复杂的作业调度安排,那么就需要 CronTrigger。
CronTrigger是基于Calendar-like调度的。当你需要在除星期六和星期天外的每天上午10点半执行作业时,那么应该使用CronTrigger。正如它的名字所暗示的那样,CronTrigger是基于Unix克隆表达式的。
-
Scheduler调度器
Quartz 框架的核心是调度器。调度器负责管理Quartz应用运行时环境。调度器不是靠自己做所有的工作,而是依赖框架内一些非常重要的部件。Quartz不仅仅是线程和线程管理。为确保可伸缩性,Quartz采用了基于多线程的架构。启动时,框架初始化一套worker线程,这套线程被调度器用来执行预定的作业。这就是Quartz怎样能并发运行多个作业的原理。
一个调度容器中可以注册多个JobDetail和Trigger。当Trigger与JobDetail组合,就可以被Scheduler容器调度了。
Quartz 框架有两种调度方式,编程调度和声明式调度。编程调度指的是我们用java代码来设置作业和触发器;Quartz框架也支持在xml文件里面声明式的设置作业调度。声明式方法允许我们更快速地修改哪个作业什么时候被执行。
-
quartz.properties文件
Quartz 有一个叫做quartz.properties的配置文件,它允许你修改框架运行时环境。缺省是使用Quartz.jar里面的 quartz.properties文件。当然,你应该创建一个quartz.properties文件的副本并且把它放入你工程的classes目录中以便类装载器找到它。使用Quartz配置文件,可能对Quartz的运行模式进行全局的配置,如集群分布式方式,单机内存和持久化模式等。
-
执行原理
1、scheduler是一个计划调度器容器(总部),容器里面可以盛放众多的JobDetail和trigger,当容器启动后,里面的每个JobDetail都会根据trigger 按部就班自动去执行。
2、JobDetail是一个可执行的工作,它本身可能是有状态的,也可以是无状态的。(状态是指任务前后相关度)
3、Trigger代表一个调度参数的配置,什么时候去调。
4、当JobDetail和Trigger在scheduler容器上注册后,形成了装配好的作业(JobDetail和Trigger所组成的一对儿),就可以伴随容器启动而调度执行了。
5、scheduler是个容器,容器中有一个线程池,用来并行调度执行每个作业,这样可以提高容器效率。
6、将上述的结构用一个图来表示,如下:
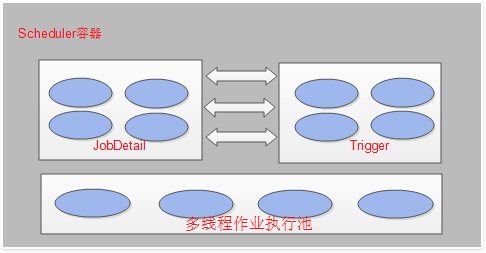
-
Quartz集成
以下是ITSM基础架构集成Quartz任务调度器的概要视图:
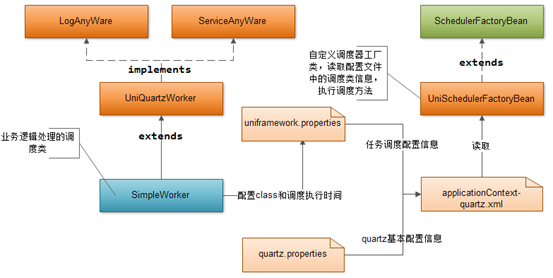
ITSM基础框架通过Spring提供的MethodInvokingJobDetailFactoryBean、SimpleTriggerBean、SchedulerFactoryBean与Quartz进行集成。Spring会在Spring容器启动时候,启动Quartz框架。
下面介绍图中的基础类和配置文件中的有关调度的配置信息
UniQuartzWorker.java:任务调度基础类,有两个基本方法doJobInUniframework、work,此类一般是用于被实际的任务调度类所继承。
protected abstract void doJobInUniframework();
public void work()
{
logger.info("Uniframework开始调度执行{}任务", getClass());
doJobInUniframework();
logger.info("Uniframework完成调度执行{}任务", getClass());
}
Quartz.properties:Quartz基础信息配置文件:
# 配置 Main Scheduler Properties
org.quartz.scheduler.instanceName = DefaultQuartzScheduler
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
# 配置执行线程池
#=====================================================================
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 10
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
# 配置 JobStore
org.quartz.jobStore.misfireThreshold = 60000
#内存中JobStore, 服务器重启时执行记录会丢失
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
Uniframework.properties:系统基础配置文件,配置自定义调度类中的调度数目、调度类、调度类触发时间。
#uniframework quartz schedule configurations
#下面配置调度类可以被执行的数目
quartz.cron.numbers=0
#配置任务调度类
quartz.cron.worker_class1=org.wbase.framework.core.extend.schedule.quartz.SimpleWorker
#任务调度类执行时间
quartz.cron.cronExpression1=0 0/1 * * * ?
quartz.cron.worker_class2=org.wbase.framework.core.extend.schedule.quartz.SimpleWorker
quartz.cron.cronExpression2=0 0 0 ? * *
quartz.cron.worker_class3=org.wbase.framework.core.extend.schedule.quartz.SimpleWorker
quartz.cron.cronExpression3=0 0 0 ? * *
...
applicationContext-quartz.xml:Quartz任务调度的spring配置文件,读取uniframework.properties配置的调度类信息、加载quartz.properties文件的调度基本配置信息:
<!--配置UniSchedulerFactoryBean自定义调度容器工厂类对象-->
<bean name="quartzScheduler" class="org.wbase.framework.core.facade.UniSchedulerFactoryBean" destroy-method="destroy">
<property name="triggers">
<list>
<ref local="cronTrigger1"/>
...
</list>
</property>
<property name="configLocation" value="classpath:quartz.properties"/>
</bean>
<bean id="cronTrigger1" class="org.springframework.scheduling.quartz.CronTriggerBean">
<property name="jobDetail" ref="jobDetail1"/>
<property name="cronExpression" value="${quartz.cron.cronExpression1}"/>
</bean>
<!--交由spring的处理类处理创建jobDetail1的bean对象-->
<bean id="jobDetail1" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="worker1"/>
<property name="targetMethod" value="work"/>
<property name="concurrent" value="false"/>
</bean>
<!--读取uniframework.properties中的信息配置一个bean对象-->
<bean id="worker1" class="${quartz.cron.worker_class1}" lazy-init="true"></bean>
UniSchedulerFactoryBean.java:自定义调度容器工厂类,继承spring工厂类。读取配置文件中的信息,启动对应的调度器:
List<Trigger> triggers = (List<Trigger>) ByteCodeUtil.getObjectFieldValue(this, SchedulerAccessor.class, "triggers");
List<Trigger> realTriggers = new ArrayList<Trigger>();
if((!Constants.RUN_AS_WEBAPPLCATION_IN_CONTAINER)|| (Constants.IS_DEV_MODE)) {
long cron_num = Constants.getParaIntValInUniframeworkProperties("quartz.cron.numbers");
Long simple_num=Constants.getParaIntValInUniframeworkProperties("quartz.simple.numbers");
.....省略若干代码......
for (Trigger trigger : triggers) {
if (trigger.getName().equals("simpleTriggerScheduleNotify")) {
if (!Constants.MODULE_SCHEDULE_NOTIFY_ENABLED) continue;
realTriggers.add(trigger);
} else if (trigger.getName().equals("simpleTriggerBuildIndex")) {
if (!Constants.SEARCH_INDEXBUILDER_ENABLED) continue;
realTriggers.add(trigger);
} else if ((trigger.getName().startsWith("cronTrigger")) && (getCronSeq(trigger.getName()) <= cron_num)) {
realTriggers.add(trigger);
} else {
if ((!trigger.getName().startsWith("simpleTrigger")) || (getSimpleSeq(trigger.getName()) > simple_num)) continue;
realTriggers.add(trigger);
}
}
}
setTriggers((Trigger[]) realTriggers.toArray(new Trigger[0]));
super.afterPropertiesSet();
-
Quartz应用
从集成Quartz任务调度器框架总体图中可以知道任务调度器执行时流程流转的整个过程,那实际开发过程中是不是需要去涉及那么多文件呢?答案是否定的,因为系统已经把一些通用的功能进行封装,而实际开发一个任务调度器只需两步,创建任务调度类、在uniframework.properties文件中配置调度类。
-
创建任务调度类
创建任务调度类需继承UniQuartzWorker类,重写doJobInUniframework方法,这里以SimpleWork调度类作介绍,此类业务逻辑很简单,只是打印一条信息。
public class SimpleWorker extends UniQuartzWorker
{
protected void doJobInUniframework()
{
logger.info("示例Quartz调度执行类!");
}
}
-
配置uniframework.properties文件
在uniframework.properties文件中配置SimpleWorker调度类,同时需把numbers属性值改为1
quartz.cron.numbers=1
quartz.cron.worker_class1=org.wbase.framework.core.extend.schedule.quartz.SimpleWorker
quartz.cron.cronExpression1=0 0 1 * * * ? //调度执行时间
配置完后,重启服务器,SimpleWorker任务调度器就会在指定的时间执行。
-
消息通知框架(Message)
-
概述
-
消息通知框架分为MQ、Email、SMS三个知识点,其中SMS目前只提供接口,需根据不同的项目要求添加不同的实现类。
-
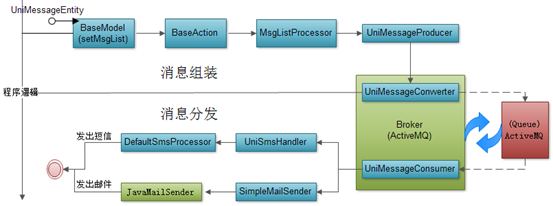
总体过程图
-
消息队列(MQ)
框架中通常使用消息队列(Message Queue)做为系统消息总线,以将业务运算和消息发送进行解耦。通过向MQ注入相应的监听器实现消息处理,发送邮件或发送短信,又或者向移动客户端推送消息等。以下是系统消息(Email、SMS)通过Spring与MQ整合方式进行集成。整合步骤:
-
定义MQ的消息监听实体类:
IJmsMessageProducer:生产者接口;
UniMessageProducer:生产者类,用于生产发送到mq的信息;
UniMessageEntity:实体类,存放信息的数据结构类;
UniMessageConverter:转换类,用于JAVA实体对象到MQ信息对象的转换。
UniMessageConsumer:消费者类,用于接受mq传来的信息并坐具体的动作;
-
ActiveMQ提供了多种BrokerURL配置,可实现嵌入式和独立运行模式。这两种模式的主要不同在于独立运行模式,可实现多Broker协作实现分布式HA方案。在框架中也同时提供了这两模式的集成。
-
嵌入式的Spring配置文件,详细信息参考如下文件:
-
独立运行模式对应Spring的配置文件,详细信息可以参考文件:applicationContext-mqindepended.xml。
-
邮件发送(Email)
邮件发送使用的是Spring的集成的JavaMail技术,并且通过xml的配置方式进行整合。实现步骤如下:
1、配置XML文件,XML配置详情如下文件:
-
-
编写邮件发送类,目前框架中的基础邮件发送实现类为SimpleMailSender。SimpleMailSender类目前提供了两种发邮件的方式:


-
sendSimpleMessage简单的邮件发送方式,通过目的邮件地址、主题、内容来发送邮件;
-
sendFtlMessage模板邮件发送方式,通过模板名称、目的邮件地址、主题、模板对象值发送邮件。
-
短信发送(SMS)
目前框架中的短信功能只提供了一个接口(SmsProcessor),以及一个内容体为空的实现类(DefaultSmsProcessor),需要在项目中根据不同的要求添加相应的短信发送代码。
-
服务器端Ajax框架(DWR)
ITSM框架采用DWR异步处理技术,利用它可以使AJAX开发变得很简单。它可以允许在浏览器里的代码调用运行在WEB服务器上的JAVA函数,达到局部刷新的作用。DWR的集成方式如下图所示:
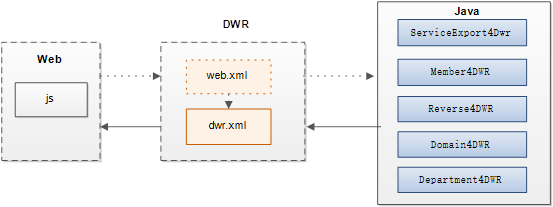
配置步骤:
1、Web.xml中的配置,添加对DWRServlet的配置:
<servlet>
<servlet-name>dwrService</servlet-name>
<servlet-class>org.wbase.framework.core.facade.UniDwrFacade
</servlet-class>
<!-- 关闭跨域安全检查 -->
<init-param>
<param-name>crossDomainSessionSecurity</param-name>
<param-value>false</param-value>
</init-param>
<!-- 启动反向AJAX -->
<init-param>
<param-name>activeReverseAjaxEnabled</param-name>
<param-value>true</param-value>
</init-param>
<!-- 对DWR scriptSession 自定义管理 -->
<init-param>
<param-name>
org.directwebremoting.extend.ScriptSessionManager
</param-name>
<param-value>
org.wbase.framework.core.extend.dwr.UniScriptSessionManager
</param-value>
</init-param>
</servlet>
2、dwr.xml文件中配置,让dwr知道在运行的时候应该给哪些JavaBean生成相应的javascript库,格式如:
<create creator="new" javascript="servicelocator4dwr">
<param name="class"value="org.wbase.framework.core.extend
.dwr.ServiceExport4Dwr"></param>
</create>
<convert converter="bean" match="org.wbase.framework.sysadmin.dao.pojo.*" />
配置说明:converter="bean"属性指定转换的方式采用JavaBean命名规范,match=""com.dwr.TestBean"属性指定要转换的javabean名称,标签指定要转换的JavaBean属性。*号表示pojo下的所有类.
包括以下调用服务方法:
接口名 | 功能 |
servicelocator4dwr | 服务输出相关接口 |
member4dwr | 人员相关操作调用接口 |
reverse4dwr | 实现的反射消息推送接口 |
domain4dwr | 单位相关操作接口 |
department4dwr | 部门相关操作接口 |
js页面调用示例:
member4dwr.isExistSameStaffCode(domainId,staffCode,function(data){
// 数据处理
});
-
JMX(MX4j)
-
MBean注册
-
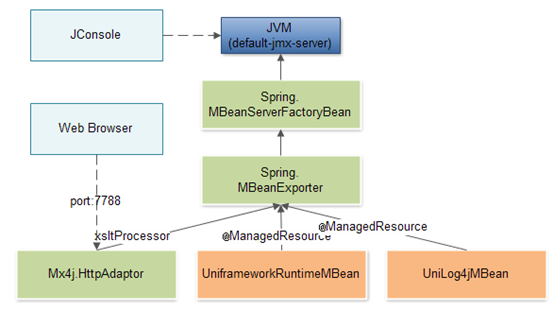
如上图,基础框架采用Spring提供的MBean Exporter功能,动态加载由@ManagedResource标注的MBean实现类,并通过Spring提供的MBean Server工厂方法将已发现的MBean实例发布到JVM中默认存在的MBeanServer中。该默认存在的MBeanServer由JVM默认生成并可通过JConsole对MBean进行管理。
此外,基础框架同时采用Mx4j提供的Http适配器,将Spring发现的MBean实例通过HTTP协议发布。因此,也可以通过web端访问7788端口对MBean进行管理。
-
运行时管理功能
-
UniframeworkRuntimeMBean
取得系统运行时的一些参数,如最大最小内存、已用空闲内存、系统启动时间、在线用户数量等。可考虑通过此途径与ITM监控系统集成,实现非侵入式的系统业务监控。这也是本模块内容编写的重要目的。
-
UniLog4jMBean
主要用于对Logger进行动态的配置,包括Root日志级别设置及读取、指定Logger的日志级别设置及读取等,可实现不停机日志级别调整,方便问题跟踪和调试。在重要问题在线跟踪时用到,如交警二期定时当机事件调查。
-
润乾报表(Quiee)
-
J2EE环境下的应用
-
润乾报表作为一个100%纯java报表工具,能够在J2EE环境下提供非常好的集成性,而且运行环境非常简单,只要有JDK即可工作,可与应用非常紧密的集成,轻易部署在各种操作系统下。
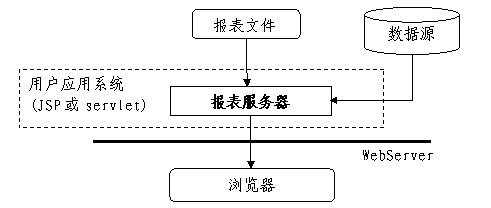
在J2EE环境下,润乾报表的服务器是个逻辑概念,并没有一个物理的服务器在运行。它是作为应用服务器上的一个应用提交的,或者直接向应用程序员提交JAR包。一般有如下两种方式集成:
-
Taglib
简单的方式就是采用标记。润乾报表提供了一个taglib定义,在JSP中直接使用该标记即可发布报表,在标记中填入报表文件名及及相关的参数。数据库连接将直接到应用服务器的连接池中去取,在应用的web.xml中配置好相应信息即可。
另外,润乾报表还提供了参数面板的taglib,用户可以绘制填报报表作为参数输入的界面,在JSP中与报表发布的部分结合起来。
-
JAVA API
在JSP或servlet中直接调用类包中的方法进行报表运算,这样可以有更深入的控制力度,比如更换数据库连接方案、自定义的数据源,设定参数等。报表服务器作为一个JAR包提供,和应用程序员自己编写的代码在地位上没有差别,集成起来非常容易,而且有较高的运行效率,并且可以充分利用应用服务器的各种能力,如平衡负载、统一部署等。
下图是润乾报表服务器提供的JAVA API结构图。
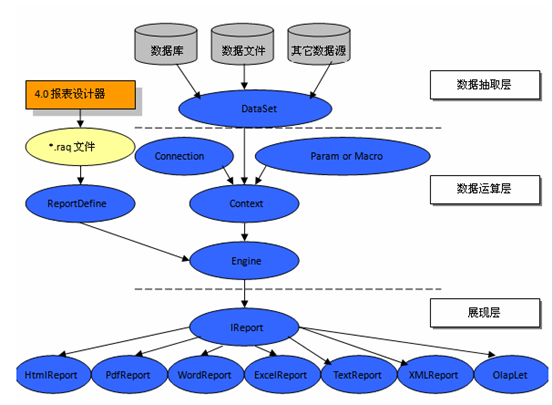
API在结构上分成了三层:数据层、运算层和展现层;每个层面都有相应的API允许程序员进行重载。图中椭圆圈中的名字都是实际的JAVA类名,而圆角矩形中的都是类的函数名。
数据层负责获得数据,一般情况下报表的数据来自数据库或规定格式的数据文件,但有时可能由应用程序自行组织数据或其它格式的数据文件,这时程序员可将数据填入DataSet类,再传给下一级的运算程序。
在运算层中可以设置报表的数据连接和参数,如果应用程序是自行管理连接池,就可以在这里把连接设置进来进行运算,否则报表运算器会自动到应用服务器的连接池中取。
完成运算后,还可以通过程序去修改某些属性再进行输出,或输出后的结果不一定发布到网页上,而可以自行处理,如写进文件或数据库。
-
框架集成
目前ITSM3.2框架只集成了Taglib方式,而在ITM的监控框架中则是Taglib和java API的方式都集成了,这里我们只讲述Taglib方式。
-
文件目录结构
report目录下存放的都是润乾报表有关的文件,下面将逐一介绍。
-
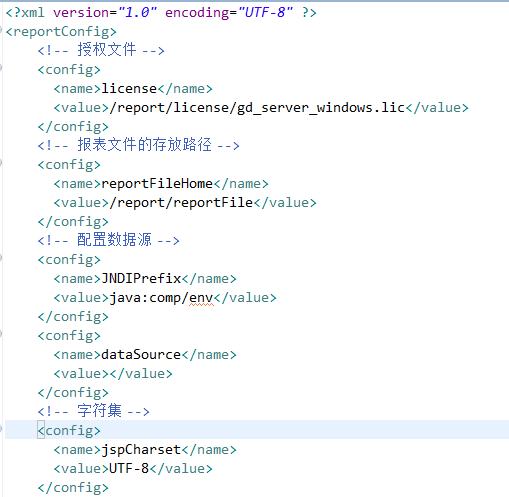
report/config目录下的reportConfig.xml是润乾报表的配置文件,runqianReport4.tld是Taglib标签的属性定义文件。
-
report/images,以及report/license,分别存放图片以及license,而license有windows和linux的版本区分。
-
report/reportFile目录存放所有的报表文件,当我们用润乾报表工具做好报表之后,生成的raq文件都需要放到改目录下,这样,我们的jsp文件才能访问到。
-
最后applet4print.jar和j2re-1_4_1-windows-i586-i.exe润乾的客户端打印必须使用的APPLET程序和JRE环境。
-
集成步骤
下面将介绍框架集成润乾报表的详细步骤。
-
-
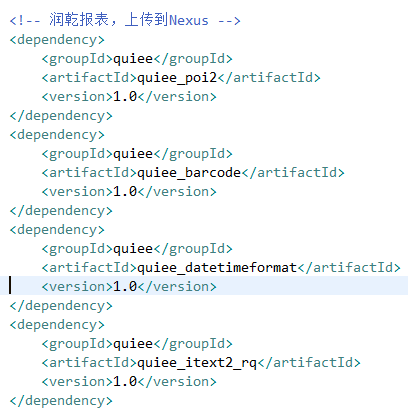
pom.xml,这里面可以看到润乾报表所需要的jar包。每个jar包的主要功能这个不再详细说明。
-
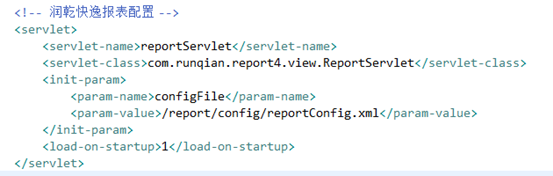
web.xml将配置润乾的servlet。
-
在web.xml中servlet中配置了参数文件reportConfig.xml,reportConfig.xml是润乾报表的核心配置文件。主要配置了报表的授权license,报表存放路径等。
-
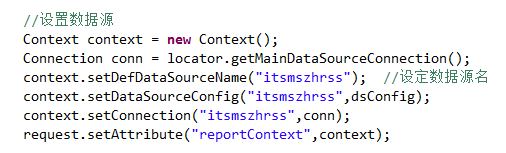
report_show.jsp,这个jsp是展示报表的jsp,主要分为三块,首先连接数据源。
然后组装参数,所有报表需要的参数都将组装为key=value;的方式传递到标签使用。
最后标签展示报表,主要属性有name:标签名,contextName:报表数据源,reportFileName:加载的报表名,即raq文件,params:报表需要的参数。
-
文件上传(Uploader)
-
概述
-
基础框架服务端采用Spring整合Struts2实现文件上传。Struts2通过拦截器FileUploadInterceptor识别MultiPartRequestWrapper请求进行文件数据提取缓存,并将相关文件数据(如文件名、文件长度、文件数据等)注入到请求上下文(ActionContext)中,最后由ModelDriven对请求上下文中的数据注入生成的Model实体。从而我们就能够以本地文件方式的操作浏览器上传的文件。
前端则采用SWFUpload实现。SWFUpload是一个客户端文件上传工具,它由flash和js相结合而成的文件上传插件,对传统上传标签而言具有更丰富的功能,主要包括:
-




-
实现无刷新上传
-
可以同时上传多个文件
-
具有良好的浏览器兼容性
-
兼容其他JS库(如jQuery)
插件所在目录:
/uniframework/src/main/webapp/widget/SWFUpload
上传处理过程:
-
集成配置
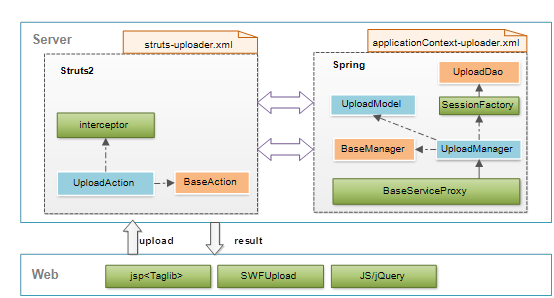
1、struts-uploader.xml配置文件:
<!-- 配置上传文件的action -->
<action name="uploader" class="org.wbase.framework.uploader.web.action.UploadAction">
<!-- 上传拦截器 -->
<interceptor-ref name="fileuploadInterceptor"/>
<!-- 上传成功,直接输出文本到指定上传配置页面 -->
<result name="upload" type="plainText"/>
</action>
2、applicationContext-uploader.xml配置文件:
<!-- 配置文件上传Dao -->
<bean id="uploadDao" class="org.wbase.framework.uploader.dao.support.UploadDao">
<property name="sessionFactory">
<ref bean="SessionFactory"/>
</property>
</bean>
<!-- 配置文件上传Manager -->
<bean id="uploadManagerTarget" init-method="initManager" class="org.wbase.framework.uploader.service.support.UploadManager">
<property name="dictDAO">
<ref bean="dictDAO"/>
</property>
<property name="uploadDao">
<ref local="uploadDao"/>
</property>
</bean>
<!-- 定义上传文件管理器,继承父类代理 -->
<bean id="uploadManager" parent="BaseServiceProxy">
<property name="target">
<ref local="uploadManagerTarget"/>
</property>
</bean>
-
基本使用
集成配置后,就可以编写上传代码了。
-
UploadAction编写
使用注解引用文件上传管理模块及配置文件初始化文件。
// 引用文件管理模块
@ActionManager(beanName = "uploadManager")
// 初始化配置文件引入
@ModuleConfig(applicationContext = "applicationContext-uploader.xml",webNavigation="struts-uploader.xml")
public class UploadAction extends BaseAction<UploadModel>
{
}
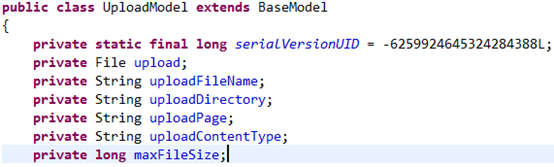
我们可以看到Action中继承了文件上传实体类UploadModel,该属性如下:
那这些属性在请求的时候是如何接收参数的呢?
因为有文件上传拦截器FileUploadInterceptor,它的工作先是进行验证(如文件上传大小限制、上传类型限制等),然后以表单的名字来构造三个参数,
例如:你上传文件表单的name为upload,则这三个参数应该为upload,uploadFileName和uploadContentType。然后保存到ActionContext的Parameters中。最后系统的ParametersInterceptor拦截器会将ActionContext的getParameters()得到的各个参数映射并赋值给Action的各个属性。
所以在execute方法,就可以直接通过调用getXxx()方法来获取上传文件的文件名、文件类型和文件内容。所以我们在开发文件上传的时候一定要在Action中提供与表单名相同的File对象。
三个参数命名格式:
-
类型为File 的文件属性名: xxx
-
类型为String的文件名称属性名:xxxFileName
-
类型为String的文件类型属性名:xxxContentType
-
上传页面编写
格式:
<!-- enctype 必须设置为"multipart/form-data",默认为 "application/x-www-form-urlencoded" -->
<form name="form" method="post" enctype="multipart/form-data" action="uploadAction">
......
<!-- 表单名称应与Action中的File对象名称相同 -->
<input type="file" name="upload" />
<input type="submit" value="上传"/>
</form>
-
附件上传
在基础框架中,我们单独把"附件上传"封装为一个附件上传模块并为节省JSP页面代码而专门建立专用标签,其原理与上述介绍中一致,这里不再重复阐述,附件上传模块的配置文件包括:
applicationContext-attach.xml
struts-attach.xml
附件标签的使用请参阅"平台框架开发指南(ITSM分卷).doc"
-
Ldap支持
-
基本概念
-
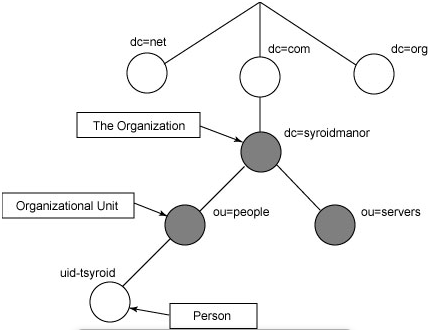
LDAP(轻量级目录访问协议,Lightweight Directory Access Protocol)是实现提供被称为目录服务的信息服务。LDAP目录是树形结构,目录有条目组成。条目是具有区别名DN(Distinguished Name)的属性(Attribute)集合,条目相当于表,DN相当于关系数据库表中的关键字(Primary Key),属性由类型(Type)和多个值(Values)组成。
DN-Distinguished Name,区别名,具有唯一性;DC-District,所属区域;OU-Organization Unit,所属组织;CN/UID-Common Name/Unique ID 名字。
如下图,uid-tsyroid的DN就是cn=tsyroid,ou=people,dc=syroidmanor,dc=com
框架中我们使用了Spring LDAP框架进行用户验证。
Spring LDAP 是一个用于操作 LDAP 的 Java 框架。它是基于 Spring 的 JdbcTemplate 模式建立的。
-
集成配置
applicationContext-ldap.xml配置:
<bean id="contextSource" class="org.springframework.ldap.core.support.LdapContextSource">
<property name="url" value="${ldap.url}" />
<!-- Ldap基结点 -->
<property name="base" value="${ldap.base}" />
<!-- 用户区别名,格式应该为cn=xxx,ou=xxx,dc=xxx -->
<property name="userDn" value="${ldap.userDn}" />
<property name="password" value="${ldap.password}" />
</bean>
<!-- 配置操作Ldap服务器数据的类 -->
<bean id="ldapTemplate" class="org.springframework.ldap.core.LdapTemplate">
<constructor-arg ref="contextSource" />
</bean>
<bean id="staffLdapDAO" class="org.wbase.framework.core.extend.ldap.spring.StaffLdapDao">
<property name="ldapTemplate" ref="ldapTemplate" />
</bean>
contextSource中的变量均在uniframework.properties配置文件中配置,如下:
##Sysmanager module--LDAP configuration
ldap.is_ldap_loaded=false
ldap.url=ldap://192.168.13.69:389
ldap.base=o=ibm,c=us
ldap.userDn=cn=Manager,o=ibm,c=us
ldap.password=manager
提供接口方法:
方法名
功能
create
新增职员
update
修改职员
delete
删除职员
findStaffByStaffCode
查找职员
getList
获取职员集合
-
DisplayTag简表
-
基本架构原理
-
基本数据结构
-
-
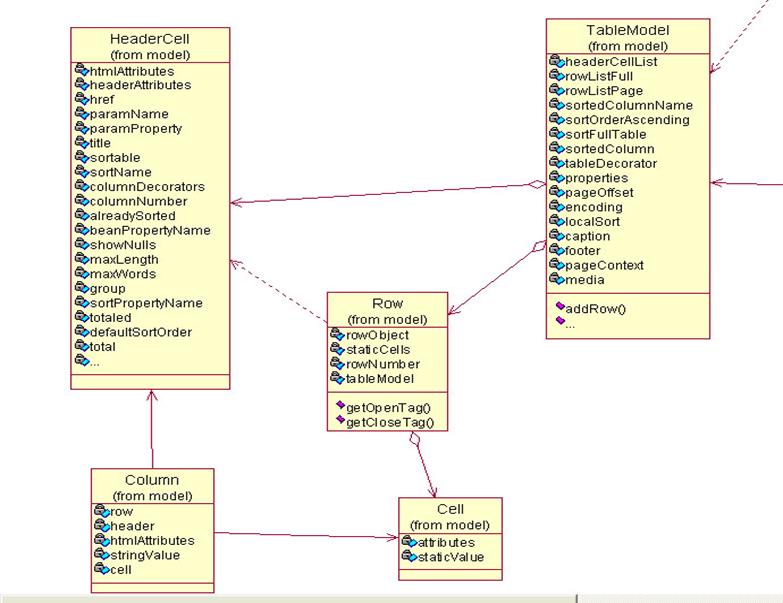
DisplayTag主要的原理是对于呈现的数据表格进行了抽象,抽象成一个TableModel的格式。此model结构比较简单,如图1将整个分成三个主要的功能模块,一个是标签部分,用来组装模型的数据,一部分是模型部分,但是是核心内容,另外一部分就是用来显示的view部分,这样将DisplayTag整体按照MVC的思想进行了系统结构设计。
-


-
TableModel:持有列表显示的所有数据信息。
headerCellList:用于保存HeaderCell对象的集合。
rowListFull:显示的所有行的列表,List中对象是Row对象
-
HeaderCell::table中列的信息,包括列标题、对应属性名和属性值等.
-
Row:代表一行,持有HeaderCell和TableModel的引用。rowObject为当期行的对象,也就是showList中的对象;staticCells单元格Cell的对象集合;rowNumbe当前的行号。
-
Column:封装列的信息。
-
Cell:table中的一个单元格,包括参数名称和参数值,一个Row中包含有多个Cell。
-
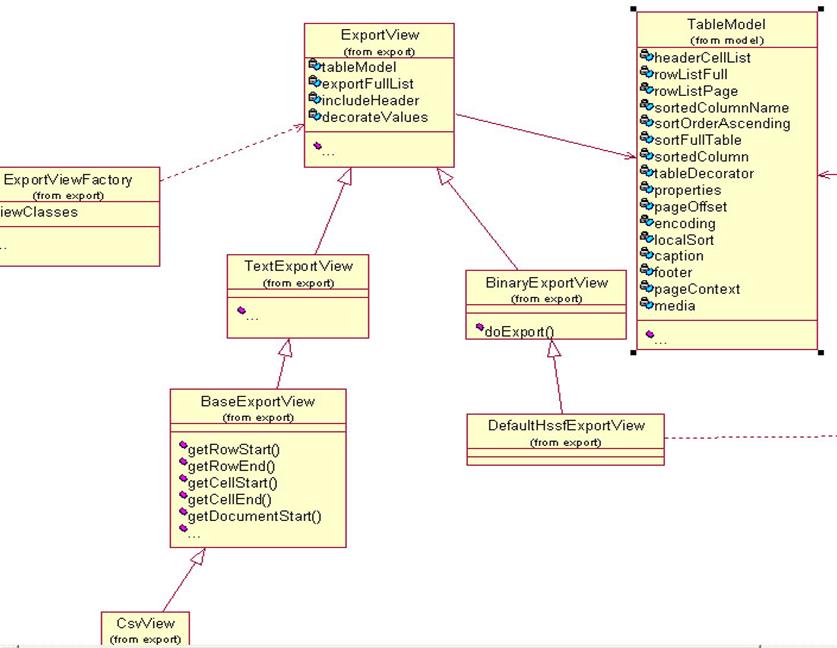
导出类的关系图
Displaytag的导出为了防止过多的类继承,采用了装饰器模式作为类继承的替代,对导出的view做了增强,下图显示了他们的继承关系
-
标签解析过程分析
Displaytag的标签采用了模板模式,TemplateTag.java类作为其他标签类的超类,为如下的标签提供了模板方法:
TableTag.java对应<display:table>标签
ColumnTag.java对应<display:column>标签
CaptionTag.java对应<display: caption >标签
TableFooterTag.java对应<display: footer >标签
SetPropertyTagjava对应<display:setProperty >标签
每一个标签都有对应的doStartTag()和doEndTag()方法。这两个方法分别在解析开始标签和结束标签时触发。其中通过doStartTag()方法的返回值来判断是否要解析标签体的内容。
用ColumnTag标签来进行举例,jsp代码如下:
<display:column title="发起人" sortProperty="INPUT_OPERATOR" sortable="true" style="width:8%" media="html xml excel" customProperty="INPUT_OPERATOR" isShowColumn="false">
<un:convert type="staff" value="#attr.row.INPUT_OPERATOR"/>
</display:column>
第一步:标签解析遇到<display:column>则触发ColumnTag.java的doStartTag()方法,在该方法中获得sortProperty、sortable、style等属性的值,并将其进行封装,保存属性值到TableModel或者pageContext中。
第二步:如果第一步中方法返回SKIP_BODY,则不解析标签体中的内容,直接跳到doEndTag()方法去解析</display:column>,否则会接着解析标签体"<un:convert type="staff" value="#attr.row.INPUT_OPERATOR"/>"的内容,得到标签体的值。
第三步: 解析完标签体后,直接触发doEndTag()方法去解析</display:column>。
在dispplayTag标签中最重要的标签就是<display:table>标签,他控制整个的标签解析,包括将解析的结果输出到JSP页面中。其中前面提到的那些标签都是为了<display:table>标签封装和提供数据。下面具体的分析这个标签。
<display:table>标签非常类似struts自带的<ww:iterator value="showList" />标签,都是起到迭代输出的作用。在解析<display:table>标签的时候,会对标签中name="showList"的List对象中的每一个对象进行迭代,每迭代一个对象都会全部遍历解析位于<display:table></display:table>之间的标签体内容,也就是<display:column>和其他的标签,并将遍历的结果进行保存到TableModel或者pageContext中,用于后面输出到JSP时使用。具体的迭代方法见TableTag.java的doIteration()方法。
TableTag.java中的方法doStartTag()中调用initParameters();方法进行参数的初始化,主要是解析<display:table>中属性,并保存到TableModel中。最后开始遍历showList中的第一个对象。
根据TableTag.java中的方法doStartTag()方法返回值,决定是否调用doAfterBody()方法。该方法中的doIteration()方法会被反复调用,迭代解析<display:table></display:table>之间标签体内容。将解析<display:column>和其他的标签,而在解析<display:column>的过程中后会调用ColumnTag.java的doStartTag()、doEndTag()方法,进行列数据的封装。
doAfterBody()方法结束后调用doEndTag()方法。这个方法会根据页面的media="html xml excel",是否包含有"html"来决定是都调用writeHTMLData();方法来进行页面JSP 的输出。
writeHTMLData()方法主要是通过调用org.displaytag.rende包中的HtmlTableWriter类的writeTable(TableModel model, String id)方法来实现。该类的继承关系如下面所示:HtmlTableWriterTableWriterAdapterTableWriterTemplate。这里使用了模板设计模式,writeTable(TableModel model, String id)方法的基本方法是在TableWriterTemplate类中定义,子类通过继承或者实现这些抽象方法完成自己的业务逻辑。
-
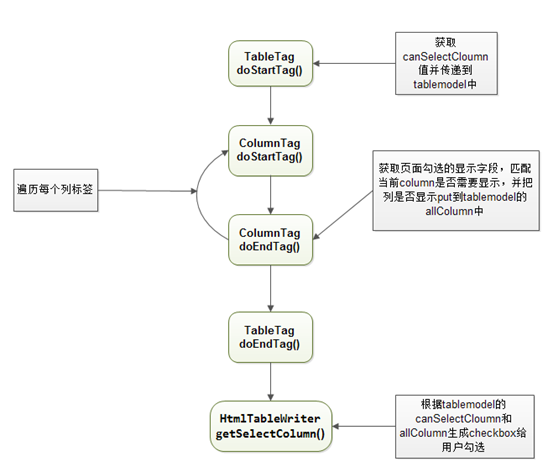
标签的自定义扩展示例
下面将举例说明标签的功能扩展,必须清楚struts2自定义标签的一些基本步骤,这里不再赘述。由于之前的displaytag显示页面的列是固定,下面将演示如何改造成用户可自定义勾选显示列功能,总体示意如图。
-
首先我需要在<display:table标签内加一个属性canSelectColumn来定义这个页面是否可以自定义勾选列true时表示可勾选,false时表示不可勾选,第一步就是在displaytag的tld文件上添加属性"canSelectColumn",然后在TableTag和TableModel类中添加属性canSelectColumn及get、set方法。
-
页面解析标签时,调用doStartTag()方法,获取到页面的canSelectColumn值再传递保存到TableModel中,这样在整个上下文环境中,都可以访问到canSelectColumn的值了,最后在生成html内容的 HtmlTableWriter类中去判断 canSelectColumn的值,如果为true则为每个字段生成相应的checkbox代码到页面。
-
每个checkbox的name属性都是"displayTagName",value则是对应的字段名,用户勾选希望显示的列后,会把勾选好的所有的列的value传入到后台。当displaytag调用doEndTag时,判断当前列是否在勾选的列当中,在则把当前列已map<字段名,boolean>的方式put到全局的AllColumn属性中,map中已字段名为key,已true和false为value,true表示该列需要显示,false则不显示。
/**
* xiaofawei
* if this column is need to hidden ,then do nothing
* */
boolean flag = false;
if(!this.alwaysShow && s != null){
for(String str : s){
if(str.equals(this.title)){
flag = true;
tableTag.getAllColumn().put(this.title, true);
}
}
if(!flag)return super.doEndTag();
}
/**
* if this column is need to show ,then go on
* */
-
缓存框架(EhCache)
-
缓存集成
-
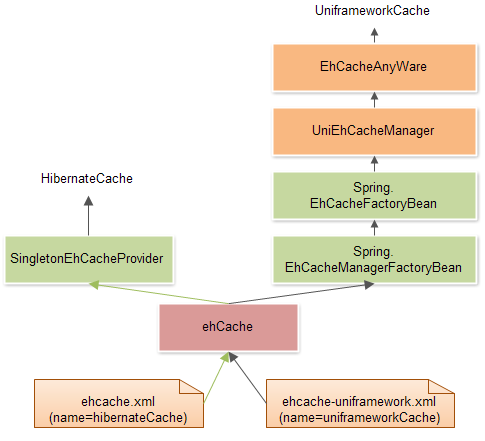
ITSM基础框架以EhCache作为系统缓存框架,包括Hibernate的二级缓存以及Uniframework缓存服务。
如图,左侧为使用默认ehcache.xml配置文件初始化的HibernateCache缓存服务,向Hibernate提供服务。配置方法,参看Hibernate二级缓存一节。
右侧为使用ehcache-uniframework.xml配置文件初始化的UniframeworkCache缓存服务,通过EhCacheAnyWare基础服务类向基础框架所有功能提供缓存服务。配置方法,参看框架配置文件"applicationContext-cache.xml"。
-
缓存应用
-
-
Hibernate实体缓存
虽然Hibernate对未进行独立配置的实体使用默认缓存空间,但是应该为每个持久层实体配置对应的缓存空间和更新策略,以得到比使用默认缓存配置更优的系统性能。
以下为ehcache.xml中的实体缓存配置片断:
<cache name="org.wbase.framework.sysadmin.dao.pojo.Dict"
maxElementsInMemory="2000" eternal="false" timeToIdleSeconds="120"
timeToLiveSeconds="120" overflowToDisk="true" />
<cache name="org.wbase.framework.sysadmin.dao.pojo.Department"
maxElementsInMemory="500" eternal="false" timeToIdleSeconds="120"
timeToLiveSeconds="120" overflowToDisk="true" />
<cache name="org.wbase.framework.sysadmin.dao.pojo.Domain"
maxElementsInMemory="100" eternal="false" timeToIdleSeconds="120"
timeToLiveSeconds="120" overflowToDisk="true" />
-
EhCacheAnyWare基础服务
使用框架提供的缓存服务,显得非常的方便,示例代码如下:
public class HibernateAttachDAO extends BaseDao implements IAttachDAO,EhCacheAnyWare {
public void doSave(Attachments attach){
cacheManager.addToCache("attach", attach);
}
public void doGet(String key){
cacheManager.getFromCache(key);
}
....
}
-
License机制
-
基本原理
-
简单概括起来主要分为两部分,1、启动tomcat时,做一次注册码验证。2、启动tomcat时,会加载一个进程管理器,这个进程管理器会把执行注册码验证的类加入到进程集合中,注册码验证类会每个十分钟定时执行一次,检测注册码是否有效。
-
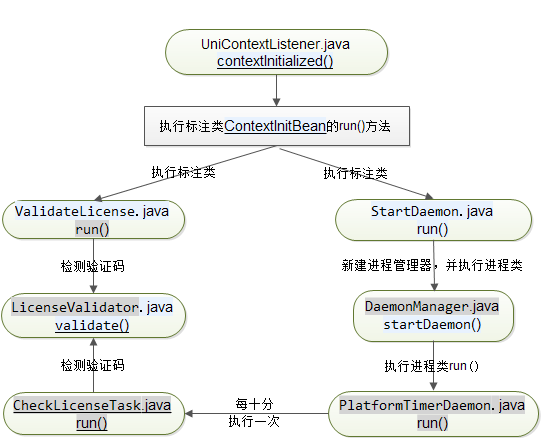
过程概述
1、启动UniContextListener监听初始化方法时,会执行AnnotationUtil.executeAnnotationClassSpecMethodsInThesePackagesWithAnnPresent(),将执行标注类的指定方法。该方法将执行org.wbase.framework.core.initialize包中所有标注为ContextInitBean的类中的run方法。

-
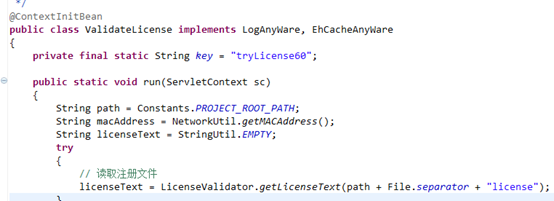
ValidateLicense.java就在打了ContextInitBean标注,所有它的run(),方法将会执行,进而去获取license文件。
-
获取注册码中的内容之后,将解码,然后和本机的MAC地址进行验证。解码的算法这里不再详细说明。至此,启动tomcat时的注册码验证结束。
-
StartDaemon.java 也打了 ContextInitBean标注,它的run()方法会启动加载一个进程管理器类DaemonManager.java
-
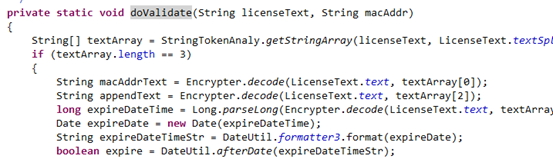
DaemonManager.java 使用单例模式,初始化时将检测注册码的定时任务类 PlatformTimerDaemon.java 加入到集合中, startDaemon()函数将遍历所有进程类,并执行。
-
PlatformTimerDaemon.java的run()方法将每十分钟执行CheckLicenseTask.java,从而检测注册码是否失效。具体的检测方法这里不再说明。


-
总体示意图
-
对象序列化(OXM)
-
关于OXM
-
这里为什么要讲OXM呢?主要是在项目开发过程中,使用JSON和XML进行对象流化的需求不少见。
O/X 映射器这个概念并不新鲜,O 代表 Object,X 代表 XML。它的目的是在 Java 对象(几乎总是一个 plain old Java object,或简写为 POJO)和 XML 文档之间来回转换。ITSM基础架构使用 Spring 的 O/X Mapper 的一个最直接的好处是可以通过利用 Spring 框架的其他特性简化配置。
-
OXM用法
-
O/X mapping
实体文件SimpleOxmObject.java
public class SimpleOxmObject extends BaseOxmObject {
private int intField;
private boolean boolField;
private String stringField;
public int getIntField() {
return this.intField;
}
public void setIntField(int intField) {
this.intField = intField;
}
public boolean isBoolField() {
return this.boolField;
}
public void setBoolField(boolean boolField) {
this.boolField = boolField;
}
public String getStringField() {
return this.stringField;
}
public void setStringField(String stringField) {
this.stringField = stringField;
}
}
Mapping文件uniframework-oxm.xml:
<mapping>
<class name="org.wbase.framework.core.oxm.SimpleOxmObject">
<map-to xml="simpleOxm" />
<field name="intField" type="integer">
<bind-xml name="intField" node="element" />
</field>
<field name="boolField" type="boolean">
<bind-xml name="boolField" node="element" />
</field>
<field name="stringField" type="string">
<bind-xml name="stringField" node="element" />
</field>
</class>
</mapping>
-
编组和解组
进行 O/X 映射时,您经常会看到编组(marshalling)和解组(unmarshalling) 这两个术语。
编组,指将 Java bean 转换成 XML 文档的过程,这意味着 Java bean 的所有字段和字段值都将作为 XML 元素或属性填充到 XML 文件中。有时,编组也称为序列化(serializing)。
解组,是与编组完全相反的过程,即将 XML 文档转换为 Java bean,这意味着 XML 文档的所有元素或属性都作为 Java 字段填充到 Java bean 中。有时,解组也称为反序列化(deserializing)。
通过Spring注入,可以方便的配置出要进行OXM的对象实例的编组器和解组器,以及方便进行转换操作的处理类UniObjXmlProcessor实例。如下面示例代码所示,在基础框架中,使用Spring服务定位器,便可以取得oxmProcessor并进行目标对象的编组和解组了。
<bean id="oxmProcessor" class="org.wbase.framework.core.oxm.UniObjXmlProcessor">
<property name="marshaller" ref="castorMarshaller" />
<property name="unmarshaller" ref="castorMarshaller" />
</bean>
<bean id="castorMarshaller" class="org.springframework.oxm.castor.CastorMarshaller">
<property name="mappingLocation" value="classpath:uniframework-oxm.xml" />
</bean>
-
流程引擎(JBPM)
-
jBPM集成和扩展
-
ITSM基础框架基于JPBM-jPDL 3.x系列进行集成和扩展,目前集成的版本为jBPM-jDPL-3.3.1GA。由于已对该版本进行定制并将修改版本上传到部门Maven资源库,所以在更新升级该jar时需要注意兼容性。
以下为ITSM基础框架通过Spring集成jBPM流程引擎的基本原理图。
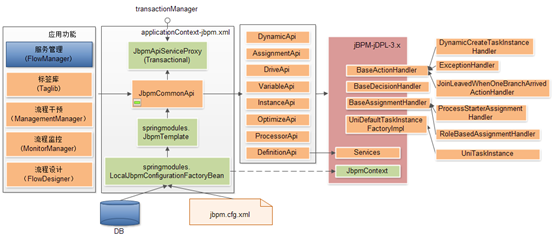
图中显示了基于jBPM进行扩展定义与API封装的主要设计思路,包括:
-
jBPM集成
基础框架通过Spring提供jBPM集成模块spring-modules-jbpm31-0.9.jar进行jBPM3.x的集成。具体的集成配置方法,可以参看"applicationContext-jbpm.xml"及"jbpm.cfg.xml"。
-
jBPM API封装
基础框架将流程驱动操作、任务分配操作、环节动态操作、任务实例操作、运行时优化、处理人操作、流程定义操作等与jBPM基本工作流操作结合并加入自定义功能,最终形成一系列的CommonAPI封装。这些封装后的API注入到BaseManager中向各个应用功能模块中,为在业务层操作工作流提供了便利。
-
jBPM服务封装
基础框架对jBPM工作流的服务提供层(ServiceFactory)进行了封装,如日志服务,消息通讯服务,持久层服务,任务调度服务,任务实例创建服务,操作授权服务,流程会话等基础支撑服务。通过以上服务封装集成可以支持工作流正常运转。
-
jBPM运行时扩展
基础框架通过实现jBPM提供的三个处理器接口,实现业务与流程的互动关联,分别为BaseActionHandler、BaseAssignmentHandler、BaseDecisionHandler。最终实现基于业务需求的动态任务分派(DynamicCreateTaskInstanceHandler),基于角色的任务分派(RoleBasedAssignmentHandler)等业务功能。
-
jBPM业务扩展
基础框架对jBPM进行的业务扩展,主要是对jBPM任务实例表TaskInstance进行了字段扩充,形成了UniTaskInstance业务任务实例表。以下是扩充的字段及其类型,可以看出大部分都是通用型字段并未指定用途。
<hibernate-mapping auto-import="false" default-access="field">
<subclass name="org.wbase.framework.jbpm.srv.UniTaskInstance" discriminator-value="T" extends="org.jbpm.taskmgmt.exe.TaskInstance">
<property name="ITEM_TYPE" type="long" />
<property name="ITEM_ID" type="long" />
<property name="ITEM_CODE" type="string" />
<property name="PROCESS_STARTER" type="long" />
<property name="PROCESS_START_DEPARTMENT" type="long" />
<property name="PROCESS_START_DOMAIN" type="long" />
<property name="PROCESS_START_TIME" type="string" />
<property name="PROCESS_DESC" type="string" />
<property name="PROCESS_CLOSE_TIME" type="string" />
<property name="INT_VAR1" type="long" />
<property name="INT_VAR2" type="long" />
<property name="INT_VAR3" type="long" />
<property name="INT_VAR4" type="long" />
<property name="INT_VAR5" type="long" />
<property name="INT_VAR6" type="long" />
<property name="STRING_VAR1" type="string" />
<property name="STRING_VAR2" type="string" />
<property name="STRING_VAR3" type="string" />
<property name="STRING_VAR4" type="string" />
<property name="STRING_VAR5" type="string" />
<property name="STRING_VAR6" type="string" />
<property name="CUR_NODE" type="string" />
<property name="GLOBAL_VAR1" type="string" />
<property name="GLOBAL_VAR2" type="string" />
<property name="GLOBAL_VAR3" type="string" />
<property name="GLOBAL_VAR4" type="string" />
<property name="GLOBAL_VAR5" type="string" />
<property name="GLOBAL_VAR6" type="string" />
<property name="GLOBAL_VAR7" type="string" />
<property name="GLOBAL_VAR8" type="string" />
<property name="GLOBAL_VAR9" type="string" />
<property name="GLOBAL_VAR10" type="string" />
</subclass>
</hibernate-mapping>
此外,除了对jBPM的TaskInstance业务实例表进行扩充外,还通过视图建立了基于业务实例表的待办任务实例表和已办任务实例表。这两个视图都建立了相应的查询POJO类:UniTodoTaskInstance和UniDoneTaskInstance。
-
流程设计(Design)
流程设计功能,并未采用jBPM提供的功能强大但使用复杂的流程设计器,而采用基于jGraph 2D绘画技术实现的一个在线流程设计器Flow Designer Applet。该流程设计器对jpdl语言的支持,并进行了功能简化以降低用户使用复杂度。以下是流程设计器的整体架构:
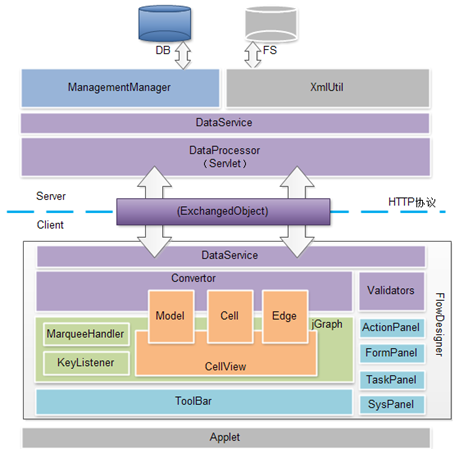
-
流程管理(Management)
基于jBPM API封装实现的流程图保存、删除、部署、定义查看、环节代办人设置等流程定义及配置类管理功能的Web模块。
-
流程监控(Monitor)
基于jBPM API封装实现的流程启动、暂停、结束、删除、更换处理人等流程运行时干预功能的Web模块。
-
AOP(Aspectj)
-
基本概念
-
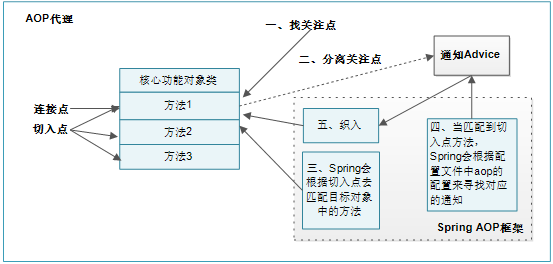
AOP(Aspect Orient Programming),也就是面向切面编程,它是面向对象编程的有力补充,通过方面就可以聚合在应用中形成可重用模块。也可以这样理解,面向对象编程(OOP)是从静态角度考虑程序结构,面向切面编程(AOP)是从动态角度考虑程序运行过程。
AOP涉及的基本概念:
-
关注点(concern):
可以认为是所关注的任何东西,一个特定的目的,一块我们感兴趣的区域;
-
方面/切面(Aspect):
一个关注点的模块化,这个关注点实现可能另外横切多个对象,可以认 为是通知、引入和切入点的组合;表示为"在哪里做和做什么集合";
-
连接点(Joinpoint):
表示需要在程序中插入横切关注点的扩展点,连接点可能是类初始化、方法执行、方法调用、字段调用或处理异常等等,Spring只支持方法执行连接点,表示为"在哪里做";
-
通知(Advice):
在连接点上执行的行为,通知提供了在AOP中需要在切入点所选择的连接点处进行扩展现有行为的手段;包括前置通知(before advice)、后置通知 (after advice)、环绕通知 (around advice),在Spring中通过代理模式实现AOP,并通过拦截器模式以环绕连接点的拦截器链织入通知 ;表示为"要做什么";
各通知的类型:
-
前置通知(Before Advice):
在一个连接点之前执行的通知,但这个通知不能阻止连接点前的执行(除非它抛出一个异常)
-
后置返回通知(After returning):
在连接点正常完成后执行的通知,例如,一个方法正常返回,没有抛出异常
-
环绕通知(Around Advice):
包围一个连接点的通知,如方法调用。这是最强大的一种通知类型。 环绕通知可以在方法调用前后完成自定义的行为。它也会选择是否继续执行连接点或直接返回它们自己的返回值或抛出异常来结束执行
-
异常通知(Throws Advice):
在方法抛出异常时执行的通知
-
切入点(Pointcut):
选择一组相关连接点的模式,即可以认为连接点的集合,Spring支持perl5正则表达式和AspectJ切入点模式,Spring默认使用AspectJ语法,在A表示为"在哪里做的集合";
-
目标对象(Target Object):
需要被织入横切关注点的对象,即该对象是切入点选择的对象,需要被通知的对象,从而也可称为"被通知对象";由于Spring AOP 通过代理模式实现,从而这个对象永远是被代理对象,表示为"对谁做";
-
AOP代理(AOP Proxy):
AOP框架使用代理模式创建的对象,从而实现在连接点处插入通知(即应用切面),就是通过代理来对目标对象应用切面。在Spring中,AOP代理可以用JDK动态代理或CGLIB代理实现,而通过拦截器模型应用切面。
-
织入(Weaving):
织入是一个过程,是将切面应用到目标对象从而创建出AOP代理对象的过程,织入可以在编译期、类装载期、运行期进行
-
引入(Introduction):
也称为内部类型声明,为已有的类添加额外新的字段或方法,Spring允许引入新的接口(必须对应一个实现)到所有被代理对象(目标对象), 表示为"做什么(新增什么)";
- AOP运行流程
-
Spring对AOP的支持
Spring 中 AOP 代理由 Spring 的 IoC 容器负责生成、管理,其依赖关系也由 IoC 容器负责管理。因此,AOP 代理可以直接使用容器中的其他 Bean 实例作为目标,这种关系可由 IoC 容器的依赖注入提供。Spring 默认使用 Java 动态代理来创建 AOP 代理, 这样就可以为任何接口实例创建代理了。当需要代理的类不是代理接口的时候, Spring 自动会切换为使用 CGLIB 代理,也可强制使用 CGLIB。
-
Spring中AOP的实现
Spring 有如下两种选择来定义切入点和通知处理:
-
基于 Annotation 的"零配置"方式:
使用@Aspect、@Pointcut等 Annotation 来标注切入点和通知处理。
-
基于 XML 配置文件的管理方式:
使用 Spring 配置文件来定义切入点和通知点。
-
集成配置
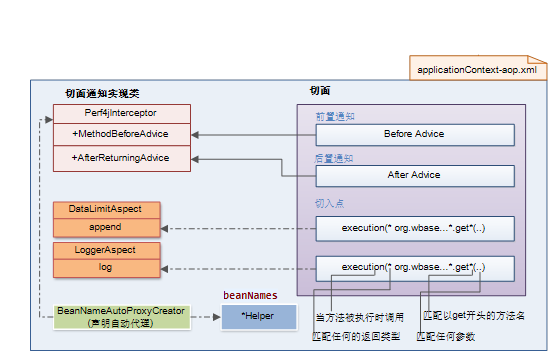
切入点的表达式(expression)均在uniframework.properties配置文件中配置。
-
AOP使用
AOP 编程,程序员参与的只有三个部分:
-
定义普通业务组件。
-
定义切入点,一个切入点可能横切多个业务组件。
-
定义通知处理,通知处理就是在 AOP 框架为普通业务组件织入的处理动作。
所以进行 AOP 编程的关键就是定义切入点和定义通知处理。一旦定义了合适的切入点和通知处理,AOP 框架将会自动生成 AOP 代理。
框架中的使用实例,基于 Annotation 的"零配置"方式:
(1)、首先启用 Spring 对 @AspectJ 切面配置的支持
<!-- 启动对@AspectJ注解的支持 -->
<aop:aspectj-autoproxy />
(2)、定义切面 Bean
<!-- 使用@Aspect 定义一个切面类 -->
@Aspect
public class AroundAspect {
// 定义该类的其他内容
......
}
(3)、定义Around通知处理
// 匹配org.wbase.framework.core.aop.LoggerAspect.log()方法作为切入点
@Around("org.wbase.framework.core.aop.LoggerAspect.log()")
public Object doLoggerPointCut(ProceedingJoinPoint jp) throws Throwable {
// 处理内容
}
(4)、定义切入点
// 使用@Pointcut Annotation 时指定切入点表达式
@Pointcut("execution(@org.wbase.framework.core.aop.annotation.AroundPointCut public *.*(..))")
public void aroundPointCut() {
}
2、基于XML配置文件的方式
(1)、定义切面 Bean
<bean id="timingAspect" class="org.perf4j.slf4j.aop.TimingAspect" />
<bean id="dataLimitAspect" class="org.wbase.framework.core.aop.DataLimitAspect" />
<bean id="loggerAspect" class="org.wbase.framework.core.aop.LoggerAspect" />
(2)、切面配置
<aop:config proxy-target-class="true">
<aop:aspect ref="dataLimitAspect">
<!-- 定义个Around通知处理,直接指定切入点表达式,以切面 Bean 中的append()方法作为通知处理方法-->
<aop:pointcut id="datalimit" expression="${aop.dataLimitAspect.expression}" />
<aop:around method="append" pointcut-ref="datalimit" />
</aop:aspect>
<!-- 定义个Before通知处理,直接指定切入点表达式,以切面 Bean 中的log()方法作为通知处理方法-->
<aop:aspect ref="loggerAspect">
<aop:pointcut id="logger" expression="${aop.loggerAspect.expression}" />
<aop:before method="log" pointcut-ref="logger" />
</aop:aspect>
</aop:config>
(3)、定义自动代理配置
<bean class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator">
<property name="beanNames">
<list>
<value>*Helper</value>
</list>
</property>
<property name="interceptorNames">
<list>
<value>perf4jInterceptor</value>
</list>
</property>
</bean>
说明:不被spring管理的bean不能被发现通知
-
加密解密(Encrypter)
框架中我们使用的了MessageDigest工具类,该类为应用程序提供信息摘要算法的功能,包括MD5、SHA、RIPE等。我们主要使用的是MD5算法进行加密解密。
工具类Encrypter提供的方法
方法名 | 功能 |
hashByMD5 | MD5加密方法 |
encrypt | 简单的字符串加密 |
decode | 解密码方法 |
加密调用实例:
Encrypter.hashByMD5(passwd)
解密调用实例:
Encrypter.decode(passwd)
工具类所提供的都是静态方法,直接调用,无需再new一个对象。
-
全文检索(FTS)
-
关于Lucene
-
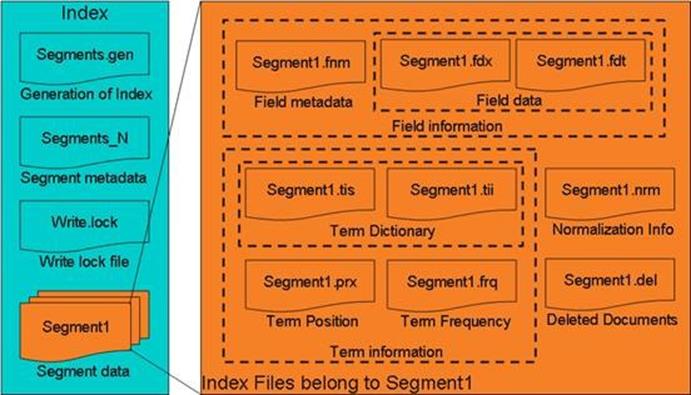
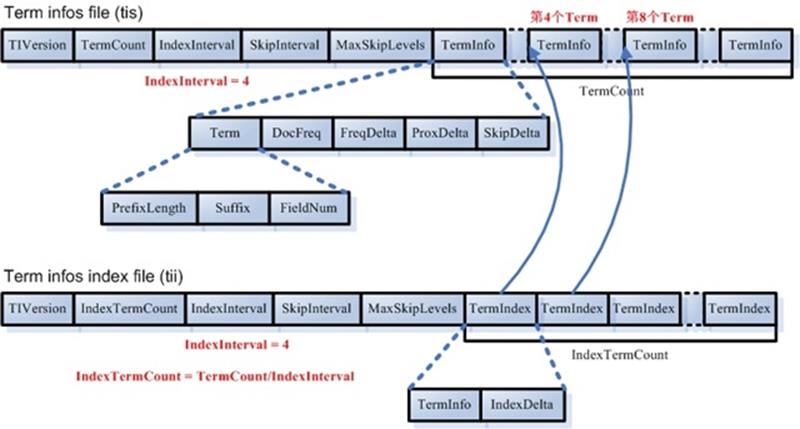
Lucene的索引结构从大到小分为以下几个概念:index、segments、document(以下可能简称为doc)、field、term。
Index(索引),一个索引,包括所有需要的信息内容;
Segments(段),可以理解为一个子索引(sub-index),每当往index中新加入一个doc时,都会新生成一个segments保存这个doc,然后通过判断,合并部分segments,最后通过优化索引的命令,把所有的segments合并成一个index;如下图所示:
Document(文档),一般以document为单位往index中添加记录,一个document可以是一个txt,一个html或者是数据库的一条记录。一个document由几个field的组成;
Field(域),一个document通常被分为几个field,用于保存不同的信息,如数据库的一条记录,不同的字段就是不同的field,当搜索时,可以指定在哪个field进行搜索,field由一组term组成;
Term(词条),是最基本的索引单位,一般每个field由很多个term组成;term由一对值组成,一个值表示他属于哪个field,另一个表示他本身的值,所以两个不同的field里相同的string并不是一个term。如下图所示:
-
关于Compass
Compass是一流的开放源码JAVA搜索引擎框架,对于你的应用修饰,搜索引擎语义更具有能力。依靠顶级的Lucene搜索引擎,Compass 结合了像 Hibernate和 Spring的流行的框架,为你的应用提供了从数据模型和数据源同步改变的搜索力。并且添加了2方面的特征,事物管理和快速更新优化。
Compass的目标是:把java应用简单集成到搜索引擎中。编码更少,查找数据更便捷。
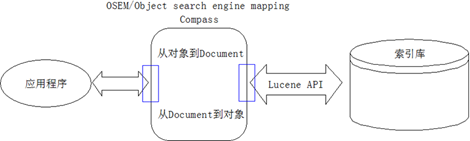
我对Compass的定义是面向域模型的搜索框架,面向域模型意味着必须支持对对象的搜索,对持久化对象的搜索,和对XML文档对象的搜索,同时还必须支持事务的处理,包括对创建、更新、保存、删除进行事务级别的处理.。所以, Compass是基于Lucene, 高于Lucene的。有个形象的比喻:Compass对于Lucene就像Hibernate对于JDBC,太有才了!Compass的开发路数完全参照Hibernate。
-
索引创建
-
Lucene手动创建索引
-
-
过程概要图
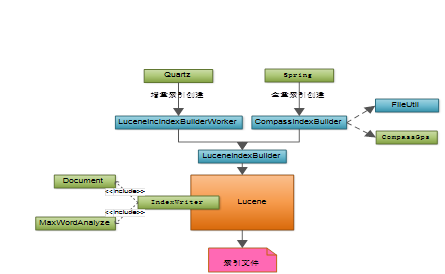
索引创建分为全量索引和增量索引,全量索引在Spring加载的时候调用执行,增量索引则通过任务调度来调用执行。全量索引首先将原有的索引文件删除,然后重新创建索引文件;增量索引则通过索引文件中最大的附件id与数据库中的附件id进行比较,为未创建索引的附件添加索引。
-
Lucene创建索引代码简要说明
1、创建一个IndexWriter对象,lucene生成index主要围绕这个对象进行,具体代码如下:
IndexWriter writer = new IndexWriter(this.luceneIndexPath, new MaxWordAnalyzer(), CREATE_INDEX, IndexWriter.MaxFieldLength.UNLIMITED);
第1个参数为生成index文件的目录,第2个参数为索引时采取的分析器,第3个参数决定是重新索引还是增量索引,true为重新索引,false则为增量索引了,第四个参数表示最大字段长度无限制;
生成一个doc对象,对象内容可以从txt文档,html,数据库等多种途径获得,现举从数据库获得的例子,具体代码如下:
doc.add(new Field("address", filepath, Field.Store.YES, Field.Index.NO));
每个doc对象可以有多个域,可以通过newField对这个域指定属性。参数说明如下:
第一个参数是指定建立索引域名(识别名),其下面有很多词条;
第二个参数是要分词的内容,可以是文档里面的内容,也可以是与文档完全没关的内容,建立索引后这些词条都会指向该文档;
第三个参数表示是否存储索引,其中有以下值:
Field.Store.YES表示存储字段值(未分词前的字段值)
Field.Store.NO表示不存储,存储与索引没有关系
Field.Store.COMPRESS表示压缩存储,用于长文本或二进制,但性能受 损;
第四个参数表示是否建立分词、索引,其中有以下值:
Field.Index.ANALYZED表示分词建索引
Field.Index.ANALYZED_NO_NORMS表示分词建索引,但是Field的值不像通常那样被保存,而是只取一个byte,这样节约存储空间
Field.Index.NOT_ANALYZED表示不分词且索引
Field.Index.NOT_ANALYZED_NO_NORMS表示不分词建索引,Field的值去一个byte保存。
2、把要索引的doc加入IndexWriter对象,具体代码如下:
if (doc != null){
writer.addDocument(doc);
}
3、优化IndexWriter对象,这样就完成了index的生成,然后关闭IndexWriter对象,具体代码如下:
writer.optimize();
writer.close();
-
Compass扫描实体类创建索引
-
过程概要图
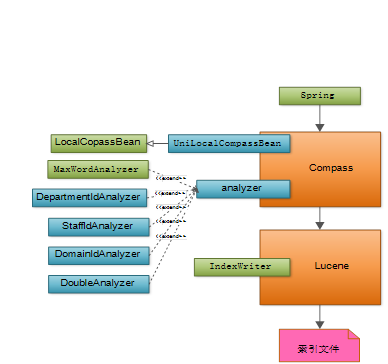
框架中使用Spring集成Compass,然后通过Compass扫描需要添加索引的实体类和配置一些特定属性,最后Compass底层调用Lucene生成索引文件。其中UniLocalCompassBean:用于扫描需要添加索引的实体类(添加了@Searchable注解的类);Analyze:分词器,确定索引中词条组成格式;
-
Spring配置
Compass是通过Spring进行集成,其中定义了生成索引的CompassGps,设置了不同的分词器,并且添加了高亮展示的功能。详细配置建下图:

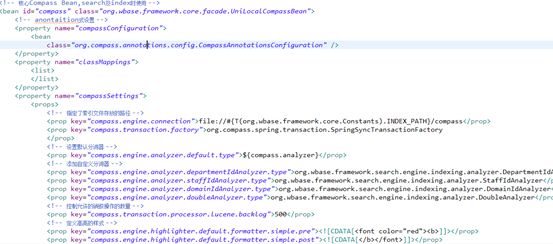
-
注解说明
Compass集成成功后,我们将通过注解的方式添加需要扫描的实体类,选择不同的分词器以及配置其他一些属性。下面将讲解几个常用的注解。
@Searchable:这个注解把该类声明为搜索实体,映射到lucene中的document;
@SearchableId:compass标注为标识属性;
@SearchableMetaData:设置为常量属性;
@SearchableProperty:标记为需要创建索引的字段,其中analyzer属性表示指定分词器,缺省表示使用默认分词器;index属性表示是否分词;store表示是否存储分词。
实例:

-
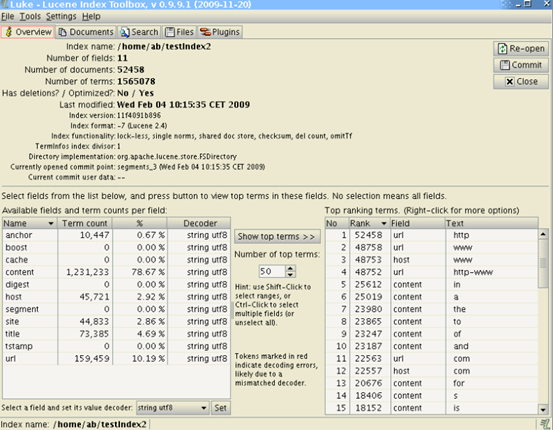
索引文件查看
Lucene生成的索引文件存放路径:\indexes\lucene;
Compass生成的索引文件存放路径:\indexes\compass。
索引文件的查看需要借助第三方工具,推荐是用luke。Luke是一个用于Lucene搜索引擎的,方便开发和诊断的第三方工具,它可以访问现有Lucene的索引,并允许您显示和修改。界面展示如下:
-
索引查询
-
过程概要图
-
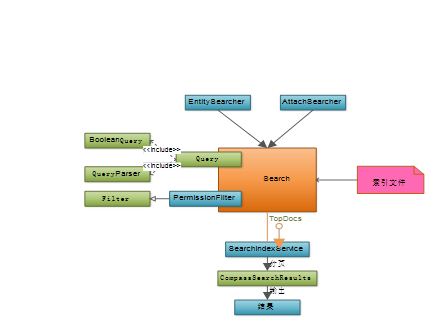
框架中包括两个索引查询方法(EntitySearcher、AttachSearcher),两者都是通过Lucene的Search对象来进行多索引文件的扫描,然后输出查询结果。其中两个索引查询方法的区别在于使用了不同的查询语句,EntitySearcher使用的是BooleanQuery,AttachSearcher使用的是QueryParser。
Search将查询出来的数据通过TopDocs对象封装,并且通过SearchIndexService类进行分页,最后通过CompassSearchResults进行最后的数据组装。
-
查询语句说明
TermQuery:查询某个特定的词,常用于查询关键字;
RangeQuery:用于查询范围,通常用于时间;
PrefixQuery:用于搜索是否包含某个特定前缀,常用于Catalog的检索;
BooleanQuery:用于测试满足多个条件,支持多个条件之间组装与条件和或条件;
ParserQuery/QueryParser:查询短语,这里面主要有一个slop的概念, 也就是各个词之间的位移偏差, 这个值会影响到结果的评分。PhraseQuery对于短语的顺序是不管的,这点在查询时除了提高命中率外,也会对性能产生很大的影响, 利用SpanNearQuery可以对短语的顺序进行控制,提高性能。
-
主要代码说明
1、组装Searcher对象
searcher = new IndexSearcher(indexReader);
-
组合查询语句
String[] queryStrings = searchCommand.getQuery().split(" ");
BooleanQuery booleanQuery = new BooleanQuery();
if(queryStrings.length != 0){
for(int i = 0;i < queryStrings.length;i++){
Query query = parseQueryString(queryStrings[i]);
booleanQuery.add(query, BooleanClause.Occur.MUST);
}
}
-
添加过滤器,这里是将不存在过滤器的数据过滤掉
public static Filter getPermissionFilter(long[] ids){
return new PermissionFilter(ids);
}
public PermissionFilter(long[] ids){
this.ids = ids;
}
-
索引并且返回结果集
topDocs = searcher.search(booleanQuery, filter, topDocs.totalHits );
-
结果集分页
protected List<Document> pagingIndex(int curPage, int totalHits, ScoreDoc scoreDocs[], Searcher searcher) throws Exception{
/** pageSize=0检索所有的结果 */
if (pageSize == 0)
return detach(0, totalHits, scoreDocs, searcher);
/** 起始的条目大于搜索到的条目 (最后一页) */
if (curPage * pageSize > totalHits)
return detach((curPage - 1) * pageSize, totalHits, scoreDocs, searcher);
/** 结束的条目大于搜索到的结果 */
if ((curPage + 1) * pageSize > totalHits)
return detach(curPage * pageSize, totalHits, scoreDocs, searcher);
/** 中间的页码,直接取出相应的条目 */
return detach(curPage * pageSize, (curPage + 1) * pageSize, scoreDocs, searcher);
}
private List<Document> detach(int start, int end, ScoreDoc scoreDocs[], Searcher searcher) throws Exception{
List<Document> documents = new ArrayList<Document>();
for (; start < end; start++)
{
documents.add(searcher.doc(scoreDocs[start].doc));
}
return documents;
}
-
组装成CompassSearchResults对象
CompassSearchResults searchResults = new CompassSearchResults(SearchResultHandler.convertResult(resultList), costTime, pageSize);
searchResults.setPages(pageInfoBuilder.setPageInfo(pageSize, (int) Math.ceil((float) topDocs.totalHits / pageSize), topDocs.totalHits, searchCommand.getPage()));
-
异常处理
-
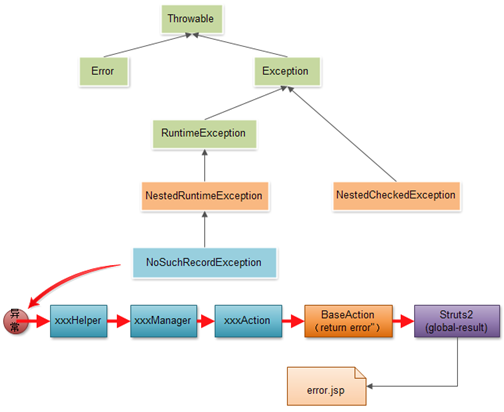
异常体系结构
-
-
异常处理原则
-
-
尽量使用RuntimeException,使代码干净整洁
-
集中统一处理异常,使架构简洁清晰
-
使用客户化的异常描述术语和异常代码
-
框架标签库实现(Taglibs)
-
实现原理
-
ITSM基础框架把一些常用的功能封装成标签供开发人员调用,以便节省开发时间、提高开发效率。
在开发标签之前,首先我们需要大致了解开发自定义标签所涉及到的接口与类的层次结构(其中SimpleTag接口与SimpleTagSupport类是JSP2.0中新引入的),如下图所示。ITSM基础框架所有标签均基于JSP1.2提供的标签库基类实现。
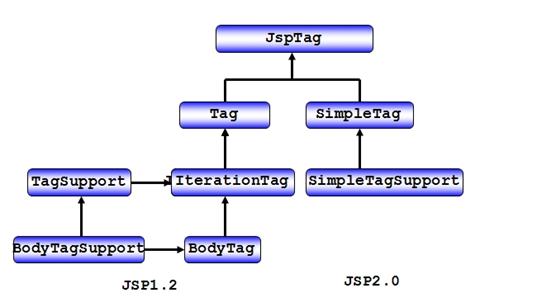
自定义标签实现原理,是先把标签的控制属性值,传送到控制层自定义标签类中,标签类根据控制属性进行进行逻辑处理,并把生成的字符串通过out.print方式输出到前台jsp页面中,最终解析成浏览器可以识别的HTML代码。
-
标签库设计
以下是AjaxSelectDepartment标签开发及应用的概要视图。
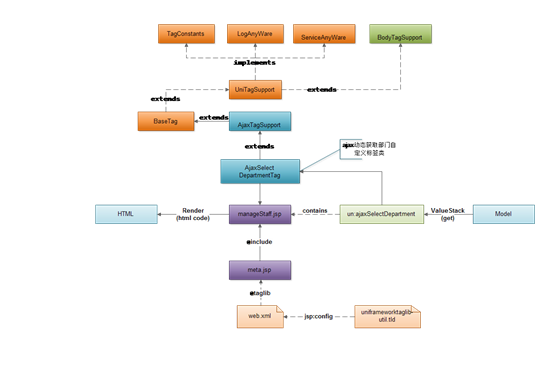
从上图可以看出系统是采用继承BodyTagSupport的方法创建自定义标签类的,为了提高代码复用性,系统将一些通用、基础的功能封装在UniTagSupport、BaseTag两个基础类中,系统根据标签的功能和类型不同,在这两个基础类上创建了一批不同功能类型的基础类包括(AjaxTagSupport、AttachTagSuport、EditorTasSupport等等),创建自定义标签类只需要根据类型功能不同对应继承不同的基础类。
目前已有的标签库如下所示:
标签库名称 | 功能说明 |
uniframeworktaglib-auth.tld | 存放有关权限功能的标签,如permission 是否显示内容的标签等等 |
uniframeworktaglib-form.tld | 存放有关表单功能的标签,如form表单生成标签等等 |
uniframeworktaglib-help.tld | 存放有关帮功能的标签,如helpEntity显示Help的实体对象标签等等 |
uniframeworktaglib-jbpm.tld | 第三方标签库文件,存放有关基于jbpm流程功能的标签,如showgraph绘制Jbpm流程图标签等等 |
uniframeworktaglib-jmesa.tld | 第三方标签库文件,存放有关table样式渲染的标签 |
uniframeworktaglib-query.tld | 目前没有任何实际功能 |
uniframeworktaglib-util.tld | 存放系统常用工具类功能标签, 如un:selectDepartment选择部门,un:dict 字典解析标签等等 |
uniframeworktaglib-wdgt.tld | 第三方标签库文件,存放有关日历选择器功能的标签,如date日历显示标签等等 |
-
开发步骤
-
创建自定义标签类
-
ajaxSelectDepartment标签是通过ajax方式获取部门信息,因此需要创建AjaxSelectDepartmentTag继承AjaxTagSupport类即可,doStartTag()方法中是具体的业务逻辑,核心代码如下所示。
public int doStartTag() hrows JspException
{
initTagEnv();
StringBuffer sb = new StringBuffer();
. . . //省略一些业务逻辑
//以下代码是拼接字符串的过程,用于输出到前台jsp页面
sb.append("<script type=\"text/javascript\">").append("\n");
sb.append("function initCombo_").append(random).append("(){").append(LN);
sb.append(" /** 判断是否已经注册autocomplete事件 */ ").append("\n");
. . . . //省略部分拼接代码
sb.append("<input type=\"hidden\" id=\"" + this.id + "\" name=\"" + this.id + "\" object=null value=\"" + (isEmpty(idvalue) ? "0" : idvalue) + "\" >").append("\n");
printToPage(sb.toString());
return super.doStartTag();
}
-
创建标签库描述文件(Tag Library Description)
uniframeworktaglib-util.tld包括文件头部和多个tag标签对组成。
文件头部描述的是此文件的基本信息(包括display-name、tlib-version、short-name、uri等),uri表示此标签库描述文件的缩写,代码如下所示
<?xml version="1.0" encoding="UTF-8"?>
<taglibxmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="2.0"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-jsptaglibrary_2_0.xsd">
<display-name>"Uniframework common tags"</display-name>
<tlib-version>3.0</tlib-version>
<short-name>uniframework tags</short-name>
<uri>/uniframework/util/tags</uri>
tag标签对中描述的是具体标签的详细信息(包括name、tag-class、body-content、description、attribute标签对等),由于系统中已有标签库描述文件,因此在实际开发过程中,只需在uniframeworktaglib-util.tld描述文件中添加tag标签对配置标签的属性和基本信息,ajaxSelectDepartment标签配置的部分如下所示,描述文件详细信息请参考系统。
<tag>
<name>ajaxSelectDepartment</name> <!--标签名称-->
<!--自定义标签类全路径,即上一步创建的自定义标签类AjaxSelectDepartmentTag-->
<tag-class>org.wbase.framework.taglib.tags.AjaxSelectDepartmentTag</tag-class>
<body-content>empty</body-content>
<description>部门选择输入框标签</description>
<attribute>
<name>id</name>
<required>true</required>
<rtexprvalue>true</rtexprvalue>
<description>
部门ID,根据该名字生成一个hidden并且在选中部门后自动赋值
</description>
</attribute>
<attribute>
<name>name</name>
<required>true</required>
<rtexprvalue>true</rtexprvalue>
<description>部门名称,根据该名称生成text用来显示部门名称</description>
</attribute>
<attribute>
<name>cascadeTip</name>
<required>false</required>
<rtexprvalue>true</rtexprvalue>
<description>根据单位过滤时,文本框给出的提示</description>
</attribute>
<tag>
注意,描述文件创建完成后,需要配置加载。ITSM基础框架把所有的标签库描述文件存放在WEB-INF\tld\文件夹中,以便系统启动时,由JSTL验证器扫描并加载。除了利用WEB-INF目录,也可以在web.xml文件中的jsp-config标签对中进行标签库引入配置。
但有些未存放在在WEb-INF\路径下的标签库描述文件,就必须在web.xml文件中进行配置,如润乾报表标签库描述文件(runqianReport4.tld)在web.xml配置信息如下所示:
<jsp-config>
<taglib>
<taglib-uri>runqianReport4</taglib-uri>
<taglib-location>/report/config/runqianReport4.tld</taglib-location>
</taglib>
</jsp-config>
-
引入标签库描述文件
在需要使用自定义标签的jsp页面头部引入
<%@ taglib prefix="un" uri="/uniframework/util/tags"%>
//这里的uri必须和uniframeworktaglib-util.tld标签库描述文件的头部的uri保持一致
由于meta.jsp文件已经引入了所有的标签库描述文件,因此在实际开发中,只需在使用自定义标签的jsp页面引入meta.jsp即可,meta.jsp部分代码如下:
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
<%@ taglib prefix="ww" uri="/struts-tags" %>
<%@ taglib prefix="un" uri="/uniframework/util/tags"%>
<%@ taglib prefix="unjmesa" uri="/uniframework/jmesa/tags"%>
<%@ taglib prefix="unjbpm" uri="/uniframework/jbpm/tags"%>
<%@ taglib prefix="unwgit" uri="/uniframework/widget/tags"%>
<%@ taglib prefix="unwidget" uri="/uniframework/widget/tags" %>
因为managerStaff.jsp使用了ajaxSelectDepartment自定义标签,所以需在页面头部引入:
<%@ include file="/jsp/meta.jsp"%>
-
标签使用
在引入标签库描述文件中的jsp页面中使用自定义标签,managerStaff.jsp页面中使用ajaxSelectDepartment标签的代码如下所示:
<th>所属部门:</th>
<td>
<un:ajaxSelectDepartment id="model.staff.DEPARTMENT_ID" name="departmentname" domainId="${model.curDomainId}" />
</td>
以上标签代码最终会被浏览解析成如下代码:
<script type="text/javascript">
.....//省略JS处理逻辑.....
</script>
<input type="text" οnfοcus="initCombo_5209();" οndblclick="javascript:$('#departmentname').autocomplete('search',$(this).val());"
id="departmentname" name="departmentname" class="ajaxInputWith ajaxInput" title="输入关字进行查询,双击显示前10条记录">
<input type="hidden" id="model.staff.DEPARTMENT_ID" name="model.staff.DEPARTMENT_ID" object=null value="0" >
-
框架工具类(Utils)
-
概述
-
ITSM基础框架中提供了许多类型不同的工具类,系统中的工具类可以分为两类(第三方的工具类、框架自定义封装的工具类),下面是系统中引入的第三方工具类的jar包,大部分的框架自定义工具类都是从以下apache提供的工具包进行继承并扩展。
工具包名称 | 说明 |
commons-beanutils-1.8.3.jar | 提供了对于JavaBean进行各种操作, 比如对象,属性复制等等。 |
commons-codec-1.4.jar | 提供了一些公共的编解码实现,比如Base64, Hex, MD5,Phonetic and URLs等等。 |
commons-collections-3.2.1.jar | 对java.util的扩展封装,各种集合类和集合工具类的封装 |
commons-compress-1.4.jar | 是一个压缩、解压缩文件的类库。可以操作ar, cpio, Unix dump, tar, zip, gzip, XZ, Pack200 and bzip2格式的文件,功能比较强大 |
commons-configuration-1.8.jar | 用来帮助处理配置文件的,支持很多种存储方式 |
commons-dbcp-1.4.jar | 是一个依赖Jakarta commons-pool对象池机制的数据库连接池,Tomcat的数据源使用的就是DBCP。 |
commons-dbutils-1.3.jar | Apache组织提供的一个资源JDBC工具类库,它是对JDBC的简单封装,对传统操作数据库的类进行二次封装,可以把结果集转化成List。,同时也不影响程序的性能。 |
commons-digester-2.1.jar | 简言之,Digester由"事件"驱动,通过调用预定义的规则操作对象栈,将XML文件转换为Java对象。 |
commons-email-1.2.jar | 提供的一个开源的API,是对javamail的封装。 |
commons-exec-1.1.jar | Apache Commons Exec 是 Apache 上的一个 Java 项目,提供一些常用的方法用来执行外部进程。 |
commons-fileupload-1.2.2.jar | java web文件上传功能。 |
commons-httpclient-3.1.jar | 基于HttpCore实 现的一个HTTP/1.1兼容的HTTP客户端,它提供了一系列可重用的客户端身份验证、HTTP状态保持、HTTP连接管理module。 |
commons-io-2.3.jar | 对java.io的扩展 操作文件非常方便。 |
commons-lang-2.5.jar | 主要是一些公共的工具集合,比如对字符、数组的操作等等。 |
commons-logging-1.1.1.jar | 提供的是一个Java 的日志接口,同时兼顾轻量级和不依赖于具体的日志实现工具。 |
commons-math-2.1.jar | Apache 上一个轻量级自容器的数学和统计计算方法包,包含大多数常用的数值算法。 |
commons-net-3.1.jar | 封装了各种网络协议的客户端 |
commons-pool-1.5.4.jar | Apache的commons pool组件是我们实现对象池化技术的良好助手。 |
-
常用工具类
ITSM基础框架把一些通用的功能按功能、类型分类封装成不同的自定义工具类,工具类中提供了大量的方法供开发人员调用,比如ArrayUtil.java,提供大量与数组处理有关的方法,StringUtil.java,提供大量处理字符串相关功能的方法。以下是系统中比较常用的工具类(存放路径org/wbase/framework/core/utils/)
工具类名称 | 描述 |
ArrayUtil.java | 数组处理类,存放与数组相关的方法,现有两个方法 getSubArray:截取数组 getListByArrays:将数组转换成列表 |
BeanUtil.java | Bean对象处理类,主要方法如下 copyProperties:两个对象之间复制属性值 findProperty:获取Bean对象的属性值 |
ByteCodeUtil.java | 字节码工具类,主要方法如下 newInstance:创建实体类对象 getBeanValue:获取实体类中属性的值 setBeanValue:设置对象中属性的值 |
ClassUtil.java | 类的查询工具类,类按注解或接口实现进行查找,支持类名pattern以提高搜索速度。 |
DaoUtil.java | 处理与dao层实体相关的工具类,提供了pojo实体相关联的功能的方法 |
DateUtil.java | 日期处理类,提供了大量日期相关的方法,比如获取当前日期、日期相加、将字符串解析返回日期对象等方法 |
EncodeUtil.java | 代码格式工具类,提供几个主要方法: convertEncodeString:将字符串按照指定格式返回 encodeString:将字符串转换为UTF-8格式 |
Encrypter.java | 字符串安全工具类,提供字符串加密解密等方法 |
FileUtil.java | 文件工具类,提供与文件相关的方法,主要包括,文件的创建、删除、判断文件是否存在、创建目录、删除目录、等方法 |
HtmlUtil.java | HTML工具类,提供与HTML相关的方法,主要包括字符串转换为html语句、判断一个字符串是否是html语句等方法。 |
ServletUtil.java | 会话管理工具,主要包括取得web应用名称、检查会话是否已授权、取得浏览器User-Agent等方法 |
StringUtil.java | 字符串工具类,提供了大量与字符串相关的方法,主要包括判断字符串是否为空、删除字符串多余的空格、比较两个字符串大小等方法。 |
Struts2Util.java | Struts2工具类,主要包括以下几个方法 outputJson:输出json格式的字符串 outputText:输出Text格式的字符串 getRequestParam:获取对象中的值 |
XmlUtil.java | Xml工具类,主要包括读文档、写文档、将文档对象转换为字符串等方法 |
-
框架附加工具(Tools)
-
代码生成器(CodeGenerator)
-
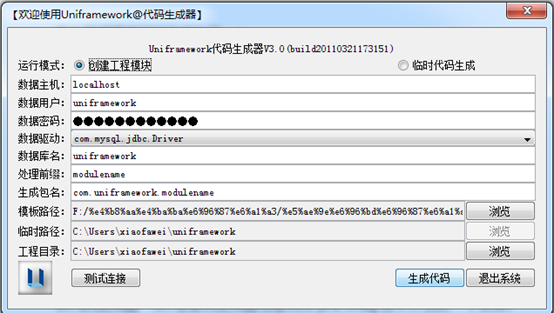
框架附件工具都是采用java swing技术开发的工具,这里,关于java swing的知识原来不在赘述,当我们要新开发一个模块时,例如"资产管理",我们在数据库建好一系列表之后,利用代码生成器可以为我们生成好一些最基本的文件,java文件,配置文件,jsp以及js文件,从而大大减少我们的工作量。
-
基本原理
基本原理简单归纳起来如下:1、填写好所有值之后,点击【生成代码】,程序将根据填写的值生成对应的所有文件目录结构,包括dao、service、web、model等文件夹。2、程序根据填写的数据库信息值查询模块所有的表名,并保存到List集合中。3、遍历查询到的表名,为每张表都生成对应的文件,首先生成对应的pojo类,然后生成hibernate的配置文件,再生成对应的js文件,最后生成jsp文件。4、为整个模块生成dao文件,service文件,以及web文件。5、最后生成spring配置文件以及struts2文件。
-
过程概述
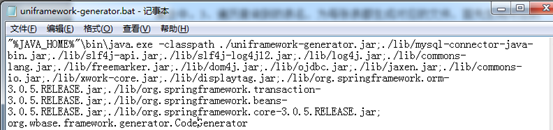
1、首先我们文本打开uniframework-generator.dat,当我们双击这个bat文件时,org.wbase.framework.generator.CodeGenerator的main方法将会运行,而前面的jar包则是运行所依赖的jar包,具体的bat语法这里不再赘述,如下图。
-
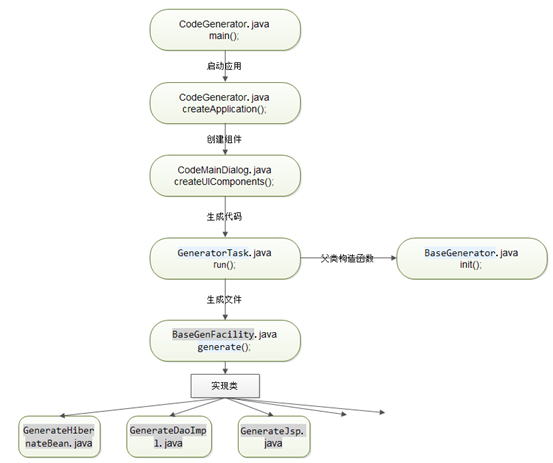
CodeGenerator.java的main方法启动,调用CodeMainDialog.java的构造方法创建对话框并为按钮及文本框注册事件。
-
点击【生成代码】,对应的监听事件将获取填写的所有值,并封装到自定义类Params中,然后new GeneratorTask(Params),然后调用这个类的run()方法。
-
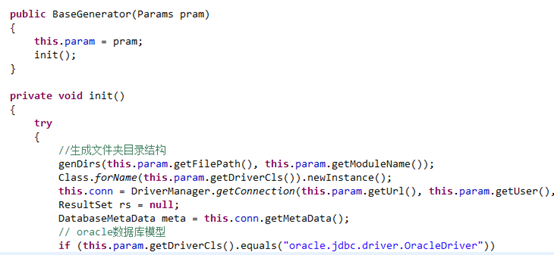
而在new GeneratorTask(Params)时,调用它的父类BaseGenerator()的构造函数,父类的构造函数主要负责三项工作,首先保存传递过来的参数类Params,然后根据参数新建好所有的文件夹目录结构(不生成文件,只生成文件夹),最后根据参数查询数据库模块的所有表保存至List中。
-
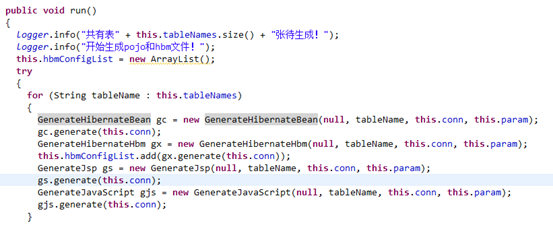
GeneratorTask()的run()方法将遍历所有查询到的表,为每个表生成对应的pojo,js,jsp,hbm文件。其中需要特别注意的是,生成jsp和js文件使用的是模块方式,利用FreeMaker的Template类,所有的ftl模板放置在template/generator下。
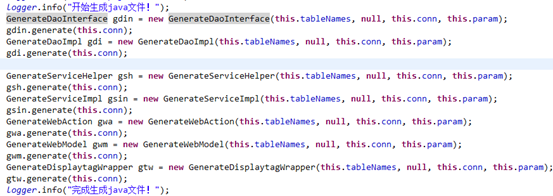
-
run()方法为模块生成dao类、helper类、model类、action类等
-
run()方法为模块生成spring、struts配置文件等
-
所有的生成文件的类都继承至 BaseGenFacility.java,子类通过重写generate()方法来生成文件, 通过重写buildCurTableStructureInfo()来查询数据库。
-
总体示意图
-
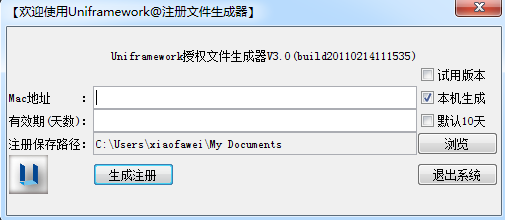
注册码生成器(RegGenerator)
和代码生成器一样,注册码生成器也是利用java swing技术开发的一个工具,用于生成ITSM系统的注册码。
-
基本原理
基本原理简单归纳起来如下:
-
-
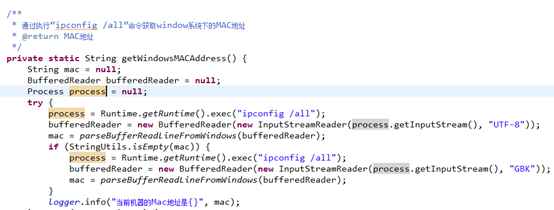
假设是本机生成注册码,点击【本机生成】则系统会先判断本机系统为windows还是linux,然后根据不同的系统运行不同命令查看MAC地址(例如,windows下的命令为ipconfig /all),最后把MAC地址解析出来返回到生成器。
-
然后输入有效天数,
-
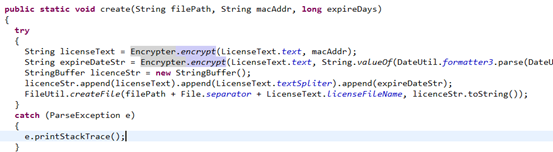
点击【生成注册】按钮,获取到Mac地址和天数,根据一个算法,生成一个字符串,最终将字符串写入到License.dat文件中,而License.dat文件的生成路径就是生成器上的注册保存路径。
-
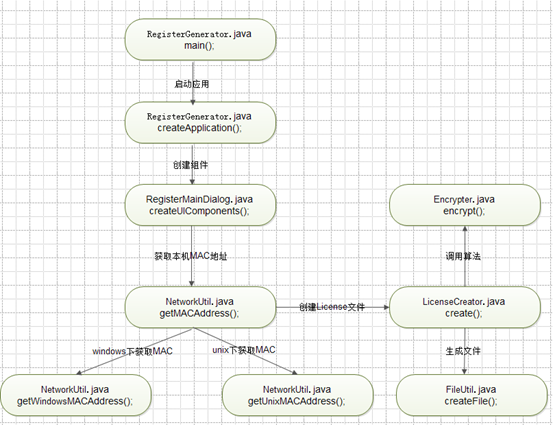
过程概述
1、首先我们文本打开uniframework-register.dat,当我们双击这个bat文件时,org.wbase.framework.generator.RegisterGenerator的main方法将会运行,而前面的jar包则是运行所依赖的jar包,具体的bat语法这里不再赘述,如下图。
2、RegisterGenerator.java的main方法启动,调用RegisterMainDialog.java的构造方法创建对话框并为按钮及文本框注册事件。
3、勾选【本机生成】时,对应的事件监听将调用NetworkUtil.getMACAddress()方法获取判断本机系统类型,再根据本机的系统类型分别调用getWindowsMACAddress()或getUnixMACAddress()执行命令来获取MAC地址,例如getWindowsMACAddress()方法将执行"ipconfig /all"命令来查询本机的mac地址。
4、点击【生成注册】按钮,对应的监听事件将执行,获取输入的MAC地址,天数,生成路径三个参数,调用LicenseCreator.create()方法,生成注册码
5、程序将MAC地址和天数都经过同一个算法,得出两个数字串,再将两个数字串用"%"拼接,最后调用FileUtil.createFile();生成License.dat并将数字串写入到文件中。
-
总体示意图
-
数据迁移工具(DataMigrator)
数据迁移工具和注册码生成器采用的技术一致,为java swing,这里不做详细讲解。该工具主要完成oracle和mysql数据库切换时的数据迁移工作。
-
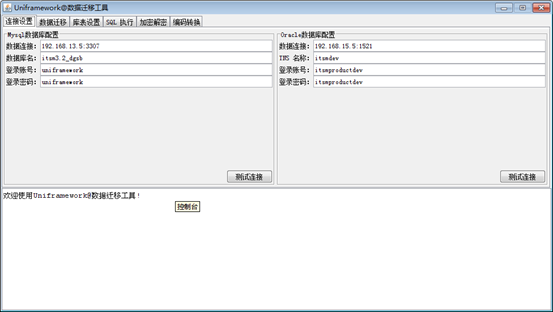
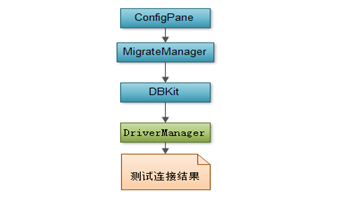
连接设置(ConfigPane)
连接设置主要用于配置数据库的链接地址以及用户密码。
-




-
过程图
-
具体实现
-
为两个"测试连接"按钮注册action监听;
mysBtn.addActionListener(new ActionListener()
{
@Override
public void actionPerformed(ActionEvent e)
{
if (StringUtils.isNotEmpty(M_hostport_i.getText()) && StringUtils.isNotEmpty(M_database_i.getText()) && StringUtils.isNotEmpty(M_account_i.getText()) && StringUtils.isNotEmpty(M_password_i.getText()))
{
MigrateManager.startWork(new Runnable()
{
@Override
public void run()
{
DBKit.testOpenMysql(getM_hostport_i(), getM_database_i(), getM_account_i(), getM_password_i());
}
}, new NotifyEvent(getNotifier(), mysBtn));
mysBtn.setEnabled(false);
}
else
log.info("请填写完整的Mysql连接配置信息!");
}
});
-
通过调用DBKit类的测试mysql连接的方法测试mysql配置是否正确;
String url = "jdbc:mysql://" + formatIpAndPort(host, Constants.DB_TYPE_MYSQL) + "/" + dbname + "?useUnicode=true&characterEncoding=utf-8&autoReconnect=true";
try
{
connMysql = DriverManager.getConnection(url, user, password);
}
catch (SQLException e)
{
log.info("DB Host: " + formatIpAndPort(host, Constants.DB_TYPE_MYSQL));
log.error(e.getMessage());
e.printStackTrace();
return false;
}
try
{
stmtMysql = connMysql.createStatement();
}
catch (SQLException e)
{
log.info("DB Host: " + formatIpAndPort(host, Constants.DB_TYPE_MYSQL));
log.error(e.getMessage());
e.printStackTrace();
return false;
}
3、调用DBKit类的测试oracle连接的方法测试oracle配置是否正确;
String url = "jdbc:oracle:thin:@" + formatIpAndPort(host, Constants.DB_TYPE_ORACLE) + ":" + dbname;
try
{
connOracle = DriverManager.getConnection(url, user, password);
DatabaseMetaData MD = connOracle.getMetaData();
}
catch (SQLException e)
{
log.info("DB Host: " + formatIpAndPort(host, Constants.DB_TYPE_ORACLE));
log.error(e.getMessage());
e.printStackTrace();
return false;
}
try
{
stmtOracle = connOracle.createStatement();
}
catch (SQLException e)
{
log.info("DB Host: " + formatIpAndPort(host, Constants.DB_TYPE_ORACLE));
log.error(e.getMessage());
e.printStackTrace();
return false;
}
-
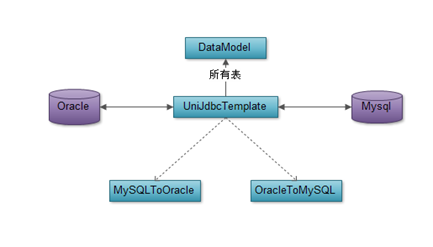
数据迁移(MigrationPane)
数据迁移主要完成将数据从Oracle迁移到MySql或者从MySql迁移到Oracle的功能。其中迁移是通过所选择的表进行迁移,未选中的表不做迁移。
-
过程图
-
-
具体实现
-
为Oracle -> Mysql单选按钮注册监听事件,获取连接设置中所配置的Oracle数据库的所有表;
oTm.addItemListener(new JRadioButtonListener());
// 单选按钮监听事件
public class JRadioButtonListener implements ItemListener {
@Override
public void itemStateChanged(ItemEvent e) {
// 判断是否选中
if (e.getStateChange() == e.SELECTED) {
if (e.getSource() == oTm) {
showAllModel = new DataModel(1, "oracle");
showAllList.setModel(showAllModel);
checkedModel = new DataModel(2, "oracle");
checkedList.setModel(checkedModel);
}
if (e.getSource() == mTo) {
showAllModel = new DataModel(1, "mysql");
showAllList.setModel(showAllModel);
checkedModel = new DataModel(2, "mysql");
checkedList.setModel(checkedModel);
}
} else {
}
}
}
在DataModel中执行以下SQL语句查询所有的表
"SELECT TABLE_NAME FROM USER_TABLES ORDER BY TABLE_NAME";
-
为Mysql-> Oracle单选按钮注册监听事件,获取连接设置中所配置的Oracle数据库的所有表;
mTo.addItemListener(new JRadioButtonListener());
-
为移动按钮注册选中表或者移除表的监听事件;
// 为右移按钮添加点击事件(把在showAllList中选择的项移动到checkedList中)
ltorBtn.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent event) {
// int[] indicesArray =
// showAllList.getSelectedIndices();//返回所选的全部索引的数组 (按升序排列)
Object[] values = showAllList.getSelectedValues();// 返回所选单 元的一组值。返回值以递增的索引顺序存储。
for (int i = 0; i < values.length; i++) {
// int index=indicesArray[i];
String tableName = (String) values[i];
// String
// tableName=(String)showAllModel.getElementAt(index);
checkedModel.addElement(tableName);
checkedList.setModel(checkedModel);
showAllModel.removeElement(tableName);
showAllList.setModel(showAllModel);
}
}
});
// 为左移按钮添加点击事件(把在checkedList中选择的项移动到showAllList中)
rtolBtn.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent event) {
Object[] values = checkedList.getSelectedValues();// 返回所选单元 的一组值。返回值以递增的索引顺序存储。
for (int i = 0; i < values.length; i++) {
String tableName = (String) values[i];
showAllModel.addElement(tableName);
showAllList.setModel(showAllModel);
checkedModel.removeElement(tableName);
checkedList.setModel(checkedModel);
}
}
});
-
为执行按钮注册监听事件。
//执行将Oracle转换为Mysql
MigrateManager.startWork(new OracleToMySQL(oracleTableList), new NotifyEvent(getNotifier(), exeBtn));
//OracleToMySQL的入口方法
@Override
public void run(){
convertAllData();
}
//执行将Mysql转换为Oracle
MigrateManager.startWork(new MySQLToOracle(mysqlTableList), new NotifyEvent(getNotifier(), exeBtn));
//MySQLToOracle的入口方法
@Override
public void run()
{
convertAllData();
}
-
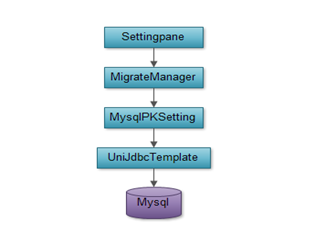
库表设置(SettingPane)
为数据库做一些特定的设置,目前只是提供了为MySql添加和取消主键自增功能。
-
过程图
-
具体实现
-
-
为"开始执行"按钮添加监听事件,根据所选的单选项执行不同的操作;
exeBtn.addActionListener(new ActionListener()
{
public void actionPerformed(ActionEvent event)
{
//添加主键自增
if (radioGroup.getSelection() == autoBtn.getModel())
{
MigrateManager.startWork(new MysqlPKSetting(true), new NotifyEvent(getNotifier(), exeBtn));
}
//取消主键自增
else if (radioGroup.getSelection() == manualBtn.getModel())
{
MigrateManager.startWork(new MysqlPKSetting(false), new NotifyEvent(getNotifier(), exeBtn));
}
else
{
JOptionPane.showMessageDialog(null, "请选择库表操作!", " 操作提示", JOptionPane.WARNING_MESSAGE);
autoBtn.requestFocus();
return;
}
manualBtn.setEnabled(false);
autoBtn.setEnabled(false);
exeBtn.setEnabled(false);
}
});
-
在MysqlPKSetting中执行对数据的操作。
if (Boolean.TRUE.equals(isAuto))
{
sql = configHelper.genPKGeneralTypeSQL(tableName, primaryKey, dataType, Constants.AUTO_INCREMENT);
ret = uniJdbcTemplate.executeMysql(sql);
log.info(msg.append("设置表:").append(tableName).append(" 的主键 " + primaryKey + " 自增方式为: ").append("AUTO_INCREMENT ").append(ret ? "失败" : "成功").toString());
}
else
{
sql = configHelper.genPKGeneralTypeSQL(tableName, primaryKey, dataType, Constants.NO_AUTO_INCREMENT);
ret = uniJdbcTemplate.executeMysql(sql);
log.info(msg.append("取消表:").append(tableName).append(" 的主键 " + primaryKey + " 自增方式!").append(ret ? "失败 " : "成功").toString());
}
-
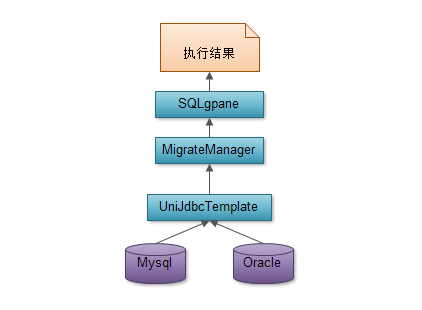
SQL执行(SQLPane)
该窗口重要用于执行SQL语句,可以选择数据库类型为:oracle、mysql
-
-
过程图
-
具体实现:
-
为"开始执行"按钮注册监听事件,根据选择的数据库类型以及输入的sql语句执行不同的操作。
//执行mysql的sql语句
else if (radioGroup.getSelection().equals(mys.getModel()))
{
MigrateManager.startWork(new Runnable()
{
@Override
public void run()
{
try
{
executeState = UniJdbcTemplate.getTemplateInstance().executeMysql(sql);
}
catch (SQLException e1)
{
log.error(e1.getMessage());
e1.printStackTrace();
}
finally
{
if (executeState)
log.info("语句执行完毕!");
}
}
}, new NotifyEvent(getNotifier(), exeBtn));
setButtonStatus(false);
}
//执行oracle的sql语句
else if (radioGroup.getSelection().equals(ora.getModel()))
{
MigrateManager.startWork(new Runnable()
{
@Override
public void run()
{
try
{
executeState = UniJdbcTemplate.getTemplateInstance().executeOracle(sql);
}
catch (SQLException e1)
{
log.error(e1.getMessage());
e1.printStackTrace();
}
finally
{
if (executeState)
log.info("语句执行完毕!");
}
}
}, new NotifyEvent(getNotifier(), exeBtn));
setButtonStatus(false);
}
-
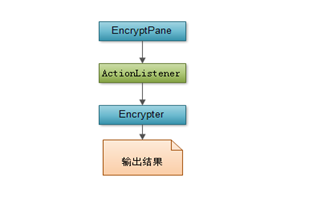
加密解密(EncryptPane)
实现将输入的字符串进行加密解密的功能。
-
-
过程图
-
具体实现
-
为"加密"按钮添加监听事件;
encBtn.setToolTipText("可对任何字符进行加密");
encBtn.addActionListener(getEncActionListener());
-
为"解密"按钮添加监听事件;
decBtn.setToolTipText("只对数字字串进行解密");
decBtn.addActionListener(getDecActionListener());
-
编写加密解密方法。
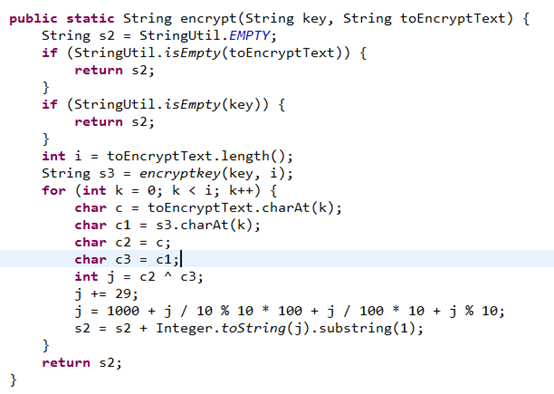
//加密方法
public static String encrypt(String key, String toEncryptText) {
String s2 = StringUtil.EMPTY;
if (StringUtil.isEmpty(toEncryptText)) {
return s2;
}
if (StringUtil.isEmpty(key)) {
return s2;
}
int i = toEncryptText.length();
String s3 = encryptkey(key, i);
for (int k = 0; k < i; k++) {
char c = toEncryptText.charAt(k);
char c1 = s3.charAt(k);
char c2 = c;
char c3 = c1;
int j = c2 ^ c3;
j += 29;
j = 1000 + j / 10 % 10 * 100 + j / 100 * 10 + j % 10;
s2 = s2 + Integer.toString(j).substring(1);
}
return s2;
}
//解密方法
public static String decode(String key, String toDecodeText) {
try {
String s2 = StringUtil.EMPTY;
if (StringUtil.isEmpty(toDecodeText)) {
return s2;
}
if (StringUtil.isEmpty(key)) {
return s2;
}
int i = toDecodeText.length() / 3;
String s3 = encryptkey(key, i);
for (int l = 0; l < i; l++) {
String s4 = toDecodeText.substring(l * 3, (l + 1) * 3);
char c1 = s3.charAt(l);
int k = Integer.parseInt(s4);
k = k / 10 % 10 * 100 + k / 100 * 10 + k % 10;
char c2 = c1;
int j = k - 29 ^ c2;
char c = (char) j;
s2 = s2 + c;
}
return s2;
} catch (Exception nfe) {
logger.error(nfe.getLocalizedMessage());
}
return "N/A";
}
-
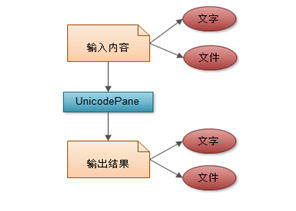
编码转换(UnicodePane)
该模块主要完成中文和unicode编码之间的转换功能,支持从文件导入输入内容和将输出结果导出到文件中的功能。
-
-
过程图
-
具体实现
-
为"中文转UNICODE"按钮添加监听事件;
// unicode转中文按钮,具体代码详见:getU2AActionListener())
u2aBtn.addActionListener(getU2AActionListener());
-
为"UNICODE转中文"按钮添加监听事件;
// 中文转unicode按钮,具体代码详见:getA2UActionListener())
a2uBtn.addActionListener(getA2UActionListener());
-
为"从文件打开"按钮添加监听事件;
// 打开源文件,具体代码详见:getInputFileActionListener()
inputFileBtn.addActionListener(getInputFileActionListener());
-
为"结果另存为"按钮添加监听事件;
// 保存目标文件,具体代码详见:getOutputFileActionListener()
outputFileBtn.addActionListener(getOutputFileActionListener());
-
框架主体功能(System)
-
系统管理
-
系统配置
-
附件管理
-
工作日管理
-
文件管理
-
简表定义
-
日程管理
-
附件检索
-
流程管理
-
消息管理
-
-
单元测试---先不做
-
概述
-
-
版本管理(Maven)
-
依赖管理(POM)
-
Nexus资源库
-
-
此部分内容参考《关于中心Maven资源库的使用》附件。
-
发布资源
目前ITSM基础框架所有依赖第三方库均已纳入Maven资源库进行管理。注意,其中一些在Maven中央库或其它互联网资源库中也无法找到的组件包通过手工上传到中心Nexus资源库中进行管理。因此,在无法连接到中心Maven资源库的情况下,需要更新并手工备份本地用户目录下的Maven资源缓存文件夹(如C:\Users\cairongfu\.m2\repository)方可脱机使用。
以下列表为手工上传到中心资源库管理的组件包:
组件包
备注
Displaytag-itsm
在ITSMv3.2产品中定制后构建的Displaytag简表标签组件
quiee
润乾报表系列组件
chardet
mozilla出品的字符集检测工具包
cpdetector
自动检测文本编码格式工具包
dataLoader
ITM监控数据采集(已上传Nexus)
portal-client
门户接口(已上传Nexus)
jbpm-jpdl
jbpm流程引擎(已定制,已传Nexus)
jofc2
OFC报表的java数据接口
-
打包构建(Assembly)
-
打Jar包
-
ITSM基础框架工程由于代码数量庞大,在进行项目构建时一般按核心包、基础服务包、配置文件包以及功能模块包进行分包构建。以下是通过配置Maven-assembly-plugin插件实现分包构建的代码装配定义配置。
<!-- 子模块分别打包(组装)插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.3</version>
<configuration>
<skipAssembly>false</skipAssembly>
<!-- 自定义输出目录 -->
<outputDirectory>
${project.build.directory}/jars/
</outputDirectory>
<!-- 描述符文件 -->
<finalName>org.wbase.framework</finalName>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>http://192.168.1.36:8888/nexus/content/groups/public/
</classpathPrefix>
<classpathLayoutType>repository</classpathLayoutType>
</manifest>
<manifestEntries>
<Product_Name>uniframework-allinone</Product_Name>
<Uniframework-Version>Uniframework V3.2.1</Uniframework-Version>
<Author_Name>cairongfu</Author_Name>
<Implementation-Version>build20121025</Implementation-Version>
<Implementation-Vendor>Sinobest_uniframework
</Implementation-Vendor>
<SVN-Revision>${SVN.revision}</SVN-Revision>
<Build_Time>${timestamp}</Build_Time>
</manifestEntries>
</archive>
<descriptors>
<descriptor>src/main/assembly/attach.xml</descriptor>
<descriptor>src/main/assembly/calendar.xml</descriptor>
<descriptor>src/main/assembly/core.xml</descriptor>
<descriptor>src/main/assembly/daysettings.xml</descriptor>
<descriptor>src/main/assembly/demo.xml</descriptor>
<descriptor>src/main/assembly/designer.xml</descriptor>
<descriptor>src/main/assembly/extjsportal.xml</descriptor>
<descriptor>src/main/assembly/extra.xml</descriptor>
<descriptor>src/main/assembly/file.xml</descriptor>
<descriptor>src/main/assembly/flex.xml</descriptor>
<descriptor>src/main/assembly/form.xml</descriptor>
<descriptor>src/main/assembly/generator.xml</descriptor>
<descriptor>src/main/assembly/importer.xml</descriptor>
<descriptor>src/main/assembly/mail.xml</descriptor>
<descriptor>src/main/assembly/migrator.xml</descriptor>
<descriptor>src/main/assembly/monitor.xml</descriptor>
<descriptor>src/main/assembly/printer.xml</descriptor>
<descriptor>src/main/assembly/properties.xml</descriptor>
<descriptor>src/main/assembly/query.xml</descriptor>
<descriptor>src/main/assembly/report.xml</descriptor>
<descriptor>src/main/assembly/schedule.xml</descriptor>
<descriptor>src/main/assembly/search.xml</descriptor>
<descriptor>src/main/assembly/server.xml</descriptor>
<descriptor>src/main/assembly/settings.xml</descriptor>
<descriptor>src/main/assembly/sysadmin.xml</descriptor>
<descriptor>src/main/assembly/taglib.xml</descriptor>
<descriptor>src/main/assembly/uploader.xml</descriptor>
<descriptor>src/main/assembly/viewlet.xml</descriptor>
<descriptor>src/main/assembly/webservice.xml</descriptor>
<descriptor>src/main/assembly/windowsad.xml</descriptor>
<descriptor>src/main/assembly/workflow.xml</descriptor>
</descriptors>
</configuration>
<executions>
<execution>
<id>make-jar</id>
<!-- 绑定到package生命周期阶段上 -->
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
完成maven-assembly-plugin插件的定义后,可以右键点击"POM.XML"文件,选择"Run As..."---"Run Configuration..."进行MVN命令配置并执行jar包构建任务:
-
打War包
ITSM基础框架构建War包,使用Maven-war-plugin插件进行。插件配置如下,通过右键点击"POM.XML"文件,选择"Run As..."---"Maven Package"即可执行所定义的打包任务:
<!-- 构建war插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<id>make-war</id>
<phase>package</phase>
<goals>
<goal>war</goal>
</goals>
<configuration>
<!-- 自动触发default-jar目标 -->
<!-- 自动将项目的类文件打成jar放到lib目录中。 打成jar的好处是:只修改class时,可以只更新jar。 -->
<archiveClasses>true</archiveClasses>
<archive>
<manifest>
<addDefaultImplementationEntries>true
</addDefaultImplementationEntries>
<addDefaultSpecificationEntries>true
</addDefaultSpecificationEntries>
</manifest>
<manifestEntries>
<SVN-Revision>${SVN.revision}</SVN-Revision>
<Built-On>${timestamp}</Built-On>
</manifestEntries>
</archive>
<warSourceExcludes>logs/**/*</warSourceExcludes>
</configuration>
</execution>
</executions>
</plugin>
-
发布管理(Deploy)
-
资源部署(snapshot)
-
<!-- 部署到远程资源库 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.7</version>
<configuration>
<!-- 选择远程仓库 -->
<altDeploymentRepository>
<id>snapshots</id>
<name>snapshots</name>
<url>http://192.168.1.36:8888/nexus/content/repositories/snapshots
</url>
</altDeploymentRepository>
<!-- 选择是否更新元数据,作为release版本发布 -->
<updateReleaseInfo>true</updateReleaseInfo>
</configuration>
</plugin>
-
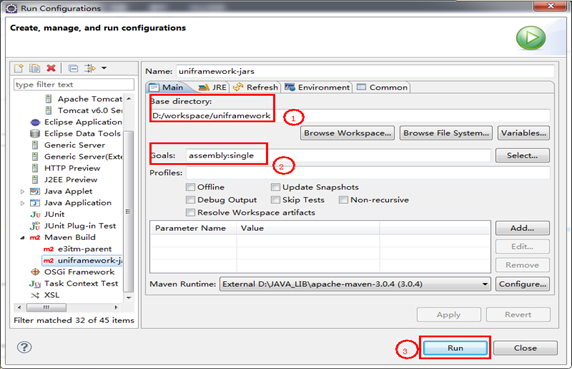

















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









