









背景
最近接到一个任务,是写一些接口提供给供应商,主要包括Topsale,销售业绩,PK接口的任务。说简单点,就是根据提供的活动ID,去活动配置对应的表中查询对应的条件参数,然后根据条件参数查出对应的CRM,IPOS,等库(表)中,查出对应的统计数据,比如店员之间的业务pk。简单的流程图如下所示:

现在以查询店铺入会率PK为例,sql如下所示:
select t.shopNumber,t.orderQtyForVip,t.orderQtyForNormal,ifnull(t.orderQtyForVip/(t.orderQtyForVip+t.orderQtyForNormal),0) as membershipRate from (
SELECT a.shop_number as shopNumber,sum(case when b.uc_id is not null then 1 else 0 end ) as orderQtyForVip,
sum(case when b.uc_id is null and a.user_id<=0 then 1 else 0 end ) as orderQtyForNormal
from ec_loyalty.loyalty_order_info as a
left join user_clerk as b on a.user_id=b.user_id and b.shop_number=a.shop_number and b.store_id=23
and b.create_time>='2017-03-08 00:00:00' and b.create_time<='2017-03-12 23:59:59'
where a.order_create_time>='2017-03-08 00:00:00' and a.order_create_time<='2017-03-12 23:59:59'
and a.shop_number in ("3602","3604","3607","3608","3609","3610","3611","3613","3612","3614","3615","3616","3617","5610","5611","5612","5614","5603","5613","5615","4609","4608","4610","3U04","3U05","5U02","4U01","8601","8602","8606","8607","8U03","8U04","8619","8616","8617","8618","1601","1602","1604","1605","1U02","2U02","2601","2604","2605","2607","2608","2609","2610","2612","6602","6603","6604","7601","7603","7602","7620","7605","7614","7616","7623","7U01","7612","7613","7607","7608","7609","7611","7615","7618","7619","7621","7U03")
and a.order_from=2 and a.order_status='PAYED'
group by a.shop_number) as t order by 4 desc,2 desc limit 3
执行sql 所耗时间将近3秒左右,耗时算有点长的。为什么会出现这种情况呢?
原因分析
结合自己的经验分析几个原因
单表数据过大,就简单根据主键ID统计总数一条这么简单的sql查询竟然需要耗费7m
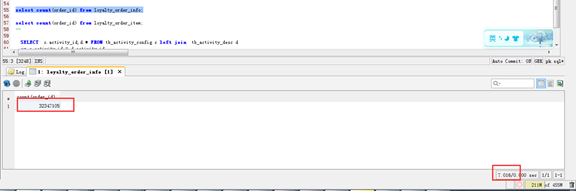
其次统计sql中有关联查询,业务计算。本身单表数据量过大的情况下,再加上这些操作,势必导致查询速度偏慢。
优化思路
可以采用分库分表的形式,减少单表的数据量,同时又能提供快查询。一般情况下认为MySQL是个简单的数据库,在数据量大到一定程度之后处理查询的效率降低,如果需要继续保持高性能运转的话,必须分库或者分表了。关于数据量达到多少大是个极限这个事儿,本文先不讨论,研究源码的同学已经证实MySQL或者Innodb内部的锁粒度太大的问题大大限制了MySQL提供QPS的能力或者处理大规模数据的能力。在这点上,一般的使用者只好坐等官方不断推出的优化版本了。在一般运维的角度来看,我们什么情况下需要考虑分库分表?
首先说明,这里所说的分库分表是指把数据库数据的物理拆分到多个实例或者多台机器上去,而不是类似分区表的原地切分。原则零:能不分就不分。是的,MySQL 是关系数据库,数据库表之间的关系从一定的角度上映射了业务逻辑。任何分库分表的行为都会在某种程度上提升业务逻辑的复杂度,数据库除了承载数据的存储和访问外,协助业务更好的实现需求和逻辑也是其重要工作之一。分库分表会带来数据的合并,查询或者更新条件的分离,事务的分离等等多种后果,业务实现的复杂程度往往会翻倍或者指数级上升。所以,在分库分表之前,不要为分而分,去做其他力所能及的事情吧,例如升级硬件,升级,升级网络,升级数据库版本,读写分离,负载均衡等等。所有分库分表的前提是,这些你已经尽力了。
原则一:数据量太大,正常的运维影响正常业务访问。
这里说的运维,例如:
(1)对数据库的备份。如果单表或者单个实例太大,在做备份的时候需要大量的磁盘IO或者网络IO资源。例如1T的数据,网络传输占用50MB的时候,需要20000秒才能传输完毕,在此整个过程中的维护风险都是高于平时的。我们在Qunar的做法是给所有的数据库机器添加第二块网卡,用来做备份,或者SST,Group Communication等等各种内部的数据传输。1T的数据的备份,也会占用大量的磁盘IO,如果是SSD还好,当然这里忽略某些厂商的产品在集中IO的时候会出一些BUG的问题。如果是普通的物理磁盘,则在不限流的情况下去执行xtrabackup,该实例基本不可用。
(2)对数据表的修改。如果某个表过大,对此表做DDL的时候,MySQL会锁住全表,这个时间可能很长,在这段时间业务不能访问此表,影响甚大。解决的办法有类似腾讯游戏DBA自己改造的可以在线秒改表,不过他们目前也只是能添加字段而已,对别的DDL还是无效;或者使用pt-online-schema-change,当然在使用过程中,它需要建立触发器和影子表,同时也需要很长很长的时间,在此操作过程中的所有时间,都可以看做是风险时间。把数据表切分,总量减小,有助于改善这种风险。
(3)整个表热点,数据访问和更新频繁,经常有锁等待,你又没有能力去修改源码,降低锁的粒度,那么只会把其中的数据物理拆开,用空间换时间,变相降低访问压力。
原则二:表设计不合理,需要对某些字段垂直拆分
这里举一个例子,如果你有一个用户表,在最初设计的时候可能是这样:
table :usersid bigint
用户的IDname varchar
户的名字last_login_time datetime
最近登录时间
personal_info text
私人信息xxxxx
其他信息字段。
一般的users表会有很多字段,我就不列举了。如上所示,在一个简单的应用中,这种设计是很常见的。
但是:设想情况一:你的业务中彩了,用户数从100w飙升到10个亿。你为了统计活跃用户,在每个人登录的时候都会记录一下他的最近登录时间。并且的用户活跃得很,不断的去更新这个login_time,搞的你的这个表不断的被update,压力非常大。那么,在这个时候,只要考虑对它进行拆分,站在业务的角度,最好的办法是先把last_login_time拆分出去,我们叫它 user_time。这样做,业务的代码只有在用到这个字段的时候修改一下就行了。如果你不这么做,直接把users表水平切分了,那么,所有访问users表的地方,都要修改。或许你会说,我有proxy,能够动态merge数据。到目前为止我还从没看到谁家的proxy不影响性能的。设想情况二:personal_info这个字段本来没啥用,你就是让用户注册的时候填一些个人爱好而已,基本不查询。一开始的时候有它没它无所谓。但是到后来发现两个问题,一,这个字段占用了大量的空间,因为是text嘛,有很多人喜欢长篇大论地介绍自己。更糟糕的是二,不知道哪天哪个产品经理心血来潮,说允许个人信息公开吧,以方便让大家更好的相互了解。那么在所有人猎奇窥私心理的影响下,对此字段的访问大幅度增加。数据库压力瞬间抗不住了,这个时候,只好考虑对这个表的垂直拆分了。
原则三:某些数据表出现了无穷增长
例子很好举,各种的评论,消息,日志记录。这个增长不是跟人口成比例的,而是不可控的,例如微博的feed的广播,我发一条消息,会扩散给很多很多人。虽然主体可能只存一份,但不排除一些索引或者路由有这种存储需求。这个时候,增加存储,提升机器配置已经苍白无力了,水平切分是最佳实践。拆分的标准很多,按用户的,按时间的,按用途的,不在一一举例。
原则四:安全性和可用性的考虑
这个很容易理解,鸡蛋不要放在一个篮子里,我不希望我的数据库出问题,但我希望在出问题的时候不要影响到100%的用户,这个影响的比例越少越好,那么,水平切分可以解决这个问题,把用户,库存,订单等等本来同统一的资源切分掉,每个小的数据库实例承担一小部分业务,这样整体的可用性就会提升。这对Qunar这样的业务还是比较合适的,人与人之间,某些库存与库存之间,关联不太大,可以做一些这样的切分。
原则五:业务耦合性考虑
这个跟上面有点类似,主要是站在业务的层面上,我们的火车票业务和烤羊腿业务是完全无关的业务,虽然每个业务的数据量可能不太大,放在一个MySQL实例中完全没问题,但是很可能烤羊腿业务的DBA 或者开发人员水平很差,动不动给你出一些幺蛾子,直接把数据库搞挂。这个时候,火车票业务的人员虽然技术很优秀,工作也很努力,照样被老板打屁股。解决的办法很简单:惹不起,躲得起。《三国演义》第一回:"话说天下大势,分久必合,合久必分。"其实在实践中,有时候可能你原本要分,后来又发现分了还得合,分分合合,完全是现实的需求,随需而变才是王道,而DBA的价值也能在此体现。或分或合的情况太多,不能穷举,欢迎继续交流这个话题,
总结
如何分表的方案,其实这个不能一概而论,与业务逻辑有关系,与数据性质有关系,比如订单类型的,那就非常容易了,通过时间这个特性,可以通过一个路由表,把数据分散到多个实例上面,或者多个表上面,扩展性非常强,但是如果是用户关系等类似的表,他的唯一可以做HASH的值就是用户ID,做HASH时,涉及到不均匀、可扩展能力,迁移麻烦等问题,所以还是不太容易的,所以只能是具体问题具体分析了。上面说的是分表的优化方案,当然还有其它方案,那就是要尽可能的写好SQL语句,不要留坑,MySQL就是适合那种快进快出的语句,尽可能的别把业务逻辑放到MySQL中去处理,要保持MySQL的高效运行才是最正确的选择。















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









