







 这篇博客回顾了文生图模型从CLIP的诞生到SDXL1.0的发展历程,重点介绍了关键模型如Disco Diffusion、Glide、Latent Diffusion、DALL·E 2、Stable Diffusion等的进展。作者通过比较不同模型在艺术肖像画的生成效果,展示了AI在艺术创作中的进步,同时提到了LoRA和ControlNet如何增强模型的可控性和表现力。
这篇博客回顾了文生图模型从CLIP的诞生到SDXL1.0的发展历程,重点介绍了关键模型如Disco Diffusion、Glide、Latent Diffusion、DALL·E 2、Stable Diffusion等的进展。作者通过比较不同模型在艺术肖像画的生成效果,展示了AI在艺术创作中的进步,同时提到了LoRA和ControlNet如何增强模型的可控性和表现力。
很久没有更新文章,最近真的太忙啦 ,在T2I领域,学习速度真的赶不上进化速度!每天都有无数新模型、新插件、新玩法涌现。玩得太上瘾啦。
,在T2I领域,学习速度真的赶不上进化速度!每天都有无数新模型、新插件、新玩法涌现。玩得太上瘾啦。
上月初我去参加我硕士专业的夏季烧烤大趴,跟我的论文导师重逢(好多年没见啦)。他今年也赶风头开课讲授 Generative AI 与商业创新的结合。不过他的课主要讲的是LLM,听说我在玩T2I,就邀请我回母校的商学院做了个分享。我为那次分享做了个简单时间线,罗列了我认为文生图领域至关重要的里程碑(基于扩散模型)。
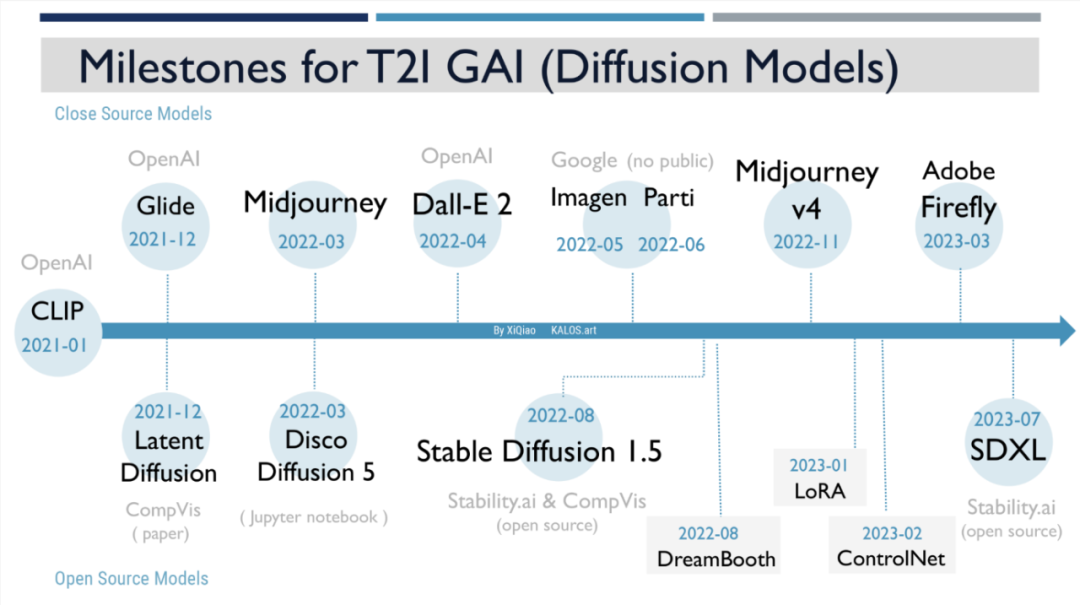
时间轴的上排是闭源相关,下排是开源相关
这个领域的一切都始于 CLIP 开源,CLIP 是一个通过自然语言监督有效地学习视觉概念的神经网络。通过使用 CLIP 可将文本和图像连接在一起。
CLIP 的全称是 Contrastive Language–Image Pre-training,也就是文本和图像对照的预训练模型,数据集使用的是 LAION-400M,包含 4 亿组从互联网上收集的 文本-图像对。文本编码器提取文本特征,图像编码器提取图像特征,两个放到一起对比相似度,从而让 AI “掌握” 文本-图像 的匹配关系。
21 年 1 月 CLIP 发布后(与 CLIP 一起发布的还有 DALL·E 第一代文生图模型,生成能力有限),基于它的各种文生图模型相继出现,Disco Diffusion 也是在这个时候诞生,此时它们的生成效果都并不理想,但社区对未来充满了憧憬。
21 年 12 月,OpenAI 发布了 Glide,即 Guided Language-to-Image Diffusion,它是 DALLE 2 的基础。同一个月,慕尼黑大学 Compvis 实验室发布了 Latent Diffusion 的论文 High-Resolution Image Synthesis with Latent Diffusion Models,它是生成能力实现重大突破基础。
基于 Glide 的论文和各种探索,T2I 开源社区开启了 Disco Diffusion 项目,22 年 3 月 Disco Diffusion v5 发布,这是图像生成模型第一次出圈引爆,吹响了打开 AI 艺术大门的号角,魔法由此开始释放。
同一个月,Midjourney 通过包装使用 Disco Diffusion,进行了商业应用。
22 年 4 月,OpenAI 发布了 DALL·E 2。它的生成能力有了较大提升,但光芒很快就会被掩盖。
为了与 OpenAI 竞争,Google在22 年 5 月和 6 月发布了 Imagen 和 Parti 的论文,但一直没有公开发布过产品,极少有人真正体验过这两个 SOTA 模型,Google 保持着其在ML研究领域高调发paper但绝不ship任何产品的姿态,在T2I领域同样也起大早赶晚集,最后甚至压根就没现身。
真正的转折点来了,22 年 8 月发布的 Stable Diffusion 1.5,由 Stability AI 与慕尼黑大学 Compvis 实验室合作训练完成。它的光芒很快盖过了其他模型,加之后来的 LoRA 和 ControlNet 如虎添翼,构建了庞大的 SD 生态。
同月,谷歌发布了 Dreambooth 的论文 DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation。对自家的T2I 预训模型(也就是前文提到的Imagen,当然这个技术也可以应用于其它扩散模型)进行微调,使其学会将某 identifier与该特定主题绑定。只要输入少量该主题的图片用于训练(通常3-5张),就可让模型能用该 identifier 生成该主题的在不同背景下演绎的个性化图像。比如把"xiqiao_meowmeow"与一些我的脸图绑定后训练,就能用xiqiao_meowmeow 生成出我在画漫画的结果,即使训练素材里只包含了我的脸。
22 年 11 月 Midjourney v4 发布,它的生成能力和艺术感惊人,使其一举奠定了MJ 作为商业闭源模型无法撼动的王者地位。
23 年1 月,LoRA 诞生,"它并不改变原模型的权重,而是在线性层旁边新增一个下采样-上采样的支路,通过训练这个支路来完成微调。因此,同一个基底 SD 模型可以搭载不同的 LoRA 使用,具有很高的灵活性。由于 LoRA 支路网络的参数量小,相比微调整个模型,对算力的需求更加友好,并且也能达到不错的效果,因此很快受到大家的热烈欢迎,成为了目前最流行的微调 SD 的方法之一。"
https://zhuanlan.zhihu.com/p/640144661
2 月,这个领域的天才人物张吕敏发布 ControlNet。它的出现代表着 T2I 生成开始真正变得可控,能够成为真正的生产力工具。ControlNet 比之前 img2img 提供了更丰富更准确的控制方式,可以直接提取 input 画面的边缘、深度、语义分隔、深度信息,以及人物的姿势等。精确控制AI 生成完美的手势和正确的手指再也不是问题。
3 月 Adobe 发布了 Firefly,将生成式 AI 集成到自己的产品 Photoshop Beta 以及面向普通人的 Express 中,正式加入这张大战。Adobe 在自家拳头产品里的深度集成(碾压了所有第三方插件)以及我烧得起钱你随便用的战略,使其在AI图像的生成量极快的上升,远超 DALLE2。虽然上场晚,但稳坐第三把交椅。
7 月,Stability 开源了 SDXL1.0,Stability.AI 最新一代旗舰模型。当之无愧的最强开源文生图模型。高参数,高分辨率,极强的 prompt 理解力,极强的写真照片类图像生成能力,当然推理和训练成本也大大提高,将会重塑 T2I开源社区的格局。
回顾文生图扩散模型的发展史,才两年多时间就走到了今天,成为一项一种每天被数百万人使用的技术,在许多领域塑造着未来。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









