







spark-RDD函数:算子reduce,fold,aggregate的区别,运算
算子:reduce
实现累加效果
def reduce(self,f):
"""
pass
"""
算子:fold
比reduce算子,多一个参数,可以设置聚合时中间临时变量的初始值]
def fold(self,zeroValue,op):
"""
pass
"""
算子:aggregate
比如fold多一个参数,分别设置RDD数据集合时局部聚合函数和全局聚合函数
def fold(self,zeroValue,seqOp,combOp):
"""
pass
"""
废话不多说上练习源码
分别使用reduce、fold和aggregate函数对RDD数据求和。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
# 第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
#导包
import os
from pyspark import SparkConf, SparkContext, TaskContext
if __name__ == '__main__':
# 设置系统环境变量
os.environ['JAVA_HOME'] = '/export/server/jdk'
os.environ['HADOOP_HOME'] = '/export/server/hadoop'
os.environ['PYSPARK_PYTHON'] = '/export/server/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/export/server/anaconda3/bin/python3'
# 1. 获取上下文对象-context
spark_conf = SparkConf().setAppName("PySpark Example").setMaster("local[2]")
sc = SparkContext(conf=spark_conf)
# 2. 加载数据源-source
input_rdd = sc.parallelize(list(range(1, 11)))
# 3. 数据转换处理-transformation
# TODO:reduce函数
def reduce_func(tmp, item):
sum = tmp + item
#为了看不同算子具体运行过程,这步print可以省略,下文同理
print("p-", TaskContext().partitionId(), ": tmp=", tmp, ",item=", item, sep="")
return sum
reduce_value = input_rdd.reduce(reduce_func)
print("Reduce value:", reduce_value)
# TODO: fold,自定义临时变量
def fold_func(tmp, item):
sum = tmp + item
print("p-", TaskContext().partitionId(), ": tmp=", tmp, ",item=", item, sep="")
return sum
fold_value = input_rdd.fold(10, fold_func)
print("Fold Sum:", fold_value)
# aggregate 功能更强大,可以自定义临时变量和 两个函数,建议使用此函数函数
# TODO: aggregate1 累乘 局部聚合函数
def aggregate_func1(tmp, item):
mult = tmp * item
print("p-", TaskContext().partitionId(), ": tmp=", tmp, ",item=", item, sep="")
return mult
# TODO: aggregate2 累加,全局聚合函数
def aggregate_func2(tmp, item):
sum = tmp + item
print("p-", TaskContext().partitionId(), ": tmp=", tmp, ",item=", item, sep="")
return sum
aggregate_value = input_rdd.aggregate(
10,
aggregate_func1,
aggregate_func2
)
print("Aggregate Sum:", aggregate_value)
# 4. 处理结果输出-sink
# 5. 关闭上下文对象-close
sc.stop()
运行结果如下
reduce
两个分区,无默认起始值,只有累加效果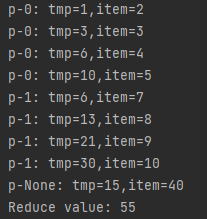
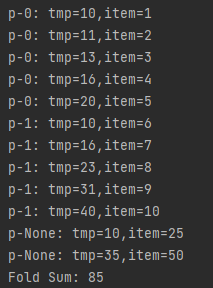
fold
起始值为10,两个分区,两个阶段,局部聚合和全局聚合共用一个函数
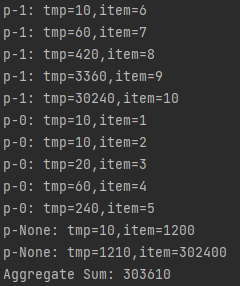
aggregate
起始值为10,p-0,p-1,先分别局部进行累乘,再进行全局累加,为了体现效果,设置两个不同的函数















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









