






 探讨大语言模型是否具备类人智能,分析其在抽象概念理解、逻辑推理等方面的能力,并对比人类智能形成过程。
探讨大语言模型是否具备类人智能,分析其在抽象概念理解、逻辑推理等方面的能力,并对比人类智能形成过程。

文 | severus
近日,曾开发出举世瞩目的 AlphaGo 的 DeepMind,在 ArXiv 上发表了一篇文章,名为:
Meaning without reference in large language models
文中提到,大参数规模的语言模型是已经具备了部分类人智能的,但由于它们仅仅接受了纯文本数据的训练,所以其能力也没有得到充分的发挥。
文中举出了大量的例子,试图证明 LLMs,或其他以 transformers 为主要结构的大模型,已经具备了和人类表现类似的智能能力。
DeepMind 一直是通用人工智能(AGI)探索路上的先行者,今年上半年,他们也曾提出了 Gato,在604个不同的任务上都取得了不错的表现,大有 AGI 模型之势。
在笔者看来,其至少证明了,当模型的容量足够大的时候,其的确能够容纳合格地完成不同的窄领域任务所需的知识,更像是给我们展现了通用agent的可行性,但真的说是智能的话,似乎同笔者的认知有所偏差。

论文标题:
Meaning without reference in large language models
论文地址:
https://arxiv.org/abs/2208.02957
人的智能表现
文章提到,人的某些智能表现一定不是从大数据中得到的。例如:
抽象概念的能力:在人的知识体系中,存在大量的抽象概念,而这些抽象概念几乎不可能从与世界的交互中得来。如:正义、法律、才智等,并且人可以轻易扩展这类概念。
对事物本身的理解可以脱离载体:当写有协议的纸张被损坏的时候,协议本身依旧是存在的;当记录法律的书本被遗失的时候,法律本身依旧是生效的。
想象能力:人能够想象不在眼前的事物,也能够想象世界上不存在的东西,甚至可以去想象一个架空的世界。
逻辑推断能力:人可以通过已知概念的组合,即可推断出新的概念。如数学证明,理论物理学的发展等。
文章认为,这些能力几乎不可能仅从大数据中得到,人也不可能仅仅通过大数据归纳学习,就具备了这些能力,而(文章认为)大量的例子表明,大模型已经初步具备了上述的能力,所以,当前大模型的结构已经符合了智能。
神农尝百草
首先,文章中所提到的人的学习能力,以及大量的智能表现,几乎都是已经成长了若干年的人的表现,即,人已经经历了超大规模数据的训练,同时,所提到的示例,也几乎是已发展成熟的领域,人们已经摸索出了最高效的指导方式,比如原文中关于水分子那一段(而它没提到的是,哪怕有这么成熟的指导体系,人想要掌握那些知识,也是要不断地试错。
想想,为了学会四则运算,你做了多少道算术题?为了考试写对化学反应式,你做了多少次训练?)。而没去考虑,想要去对比模型和人的状态,应当从完全空白开始。

实际上,新生儿和模型一样,在刚刚来到这个世界的时候,学习知识的途径,也仅仅有与这个世界的交互,即超大数据量的归纳学习。认知心理学实验表明,新生儿在刚刚出生的时候,会对所有的声音信号有注意力反应,而几个月之后,会对自己父母的声音有更强的注意力反应。对语言的反应也一样,出生几个月之后,新生儿会对自己的母语有更高的注意力。
同时,认知神经科学的实验也表明,新生儿在出生的头两年,脑内的神经链接是不断地变多的,而在接下来的十几年,则会不断减少,直到达到一个稳定的水平。
也就是说,新生儿和大模型一样,原本也是具有任意泛化的能力(如海伦·凯勒自传中,她曾描述小时候无法学习到什么是水),人类归纳学习得不够,也很容易发生“过拟合”(一朝被蛇咬,处处闻……啊不是,十年怕井绳,你看。笔者也过拟合了吧[doge]),而大量的交互,或大数据量的训练,实际上是一种剪枝行为。那么,所谓概念的学习,早期语言的学习,也是大量的交互而形成的。
比如,婴幼儿在见到家里的宠物狗时,他的父母叫了宠物狗的名字,他就很容易将那个名字和狗这个形象绑定起来,而不是直接得到了“狗”这一概念,他们也需要见到足够多的狗,知道了足够多不同的名字,才会将具体的名字和狗分离开。
抽象的概念,如正义、法律等,也是要经过大量的修正之后,才形成大家都基本差不多的认知。不然,也不必去从小在行为上规范、修正,去让一个孩子去遵守公序良俗。
哪怕是成年人,面对人类知识体系上完全空白的领域时,也是通过大量与世界的交互,大数据量的总结,才形成了一套完整的知识体系。从亚里士多德到伽利略,两千年的归纳试错,才形成了牛顿第一定律。我们不能够否认,人类从零开始形成新的知识体系时,哪怕是刚刚接触一个新的电子游戏,也往往是从归纳开始的。
只不过,有一点文章说的是有道理的,纯文本的数据的确是不够的。纯文本本身是已经抽象过的东西,相比之下,人类能够得到的感知信号种类就太多了。若仅仅通过文本数据,人类所能习得的概念或许也很有限。
我们不能去否认,归纳学习在智能产生的过程中,起到的巨大作用,但显然,在对某一领域的认知达到了一定的水平之后,人就不仅仅依靠归纳学习去获取新的知识了。我们能够不断地利用已掌握的概念,去推演新的概念,也逐渐从观测现象,总结知识转换到设计实验,验证理论这样的学习模式。这种能力,即为人的演绎能力。
大模型具备了类人智能?
这篇文章认为,大模型一定程度上已经具备了类人的推断能力了。如 DeepMind 发表的另一篇实验报告[1],试图证明,大模型已经具备了逻辑推理能力,例如在三段论问题上,以及华生选择任务上,大模型在零样本上,都取得了一些分数。
华生选择任务是一个典型的逻辑问题,例如:桌面上有四张卡,每张卡的两面各表示了同一个人的动作。现在可见的一面是“借车”、“没借车”、“为车子加油”、“没为车子加油”。你至少要翻开哪些牌,才能验证这句论述“如果借了车,就要为车子加油”?
这篇工作笔者也花时间读了一下,但是,其给出的数据,以及模型的表现,并不足以证明模型的推理能力,原因在于,模型正向的表现,很像是数据中带有统计显著性的部分,即数据的同质部分。当然,报告中给出的另外一个实验,即把答案给抹掉,或者打乱,模型的效果骤降,似乎也佐证了笔者的观点。
另一篇工作[2]想要证明大模型掌握了“颜色”这一概念,其列出的证据为,大模型对颜色相关词语的表示,和直接在视觉信号上学到的颜色表示,在几何空间上有高度的相似性。
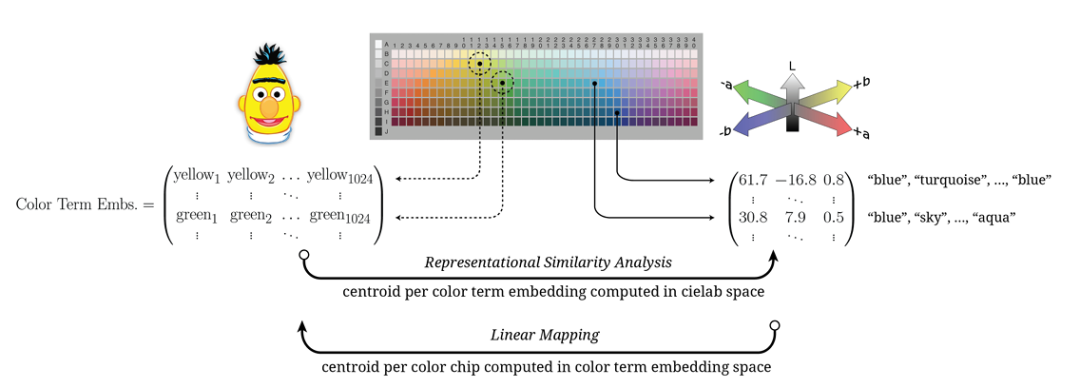
恕我直言,这不正是分布式表示的立足点吗?我们有大量的自然文本去应用不同的颜色词语,其在几何空间上的归纳偏置正应该有这样的表现啊?
同时,文章也认为,AlphaFold 能够生成完全没有见过的蛋白质结构,也符合了前文对人类想象能力的描述。
那我就要说了,蛋白质结构形成,虽复杂,但是以笔者浅薄的生物学知识,仍旧认为其问题空间仍旧是极其有限的,例如本身分子形成时,各类化学键及其表现出的化学性质,几乎已经是很明确的规则,无论是通过已有大数据归纳,还是通过大量交互去强化学习,我认为模型是非常能够具备这种能力的,这就如同 AlphaGo 可以下出所有棋手都没见过的棋路,也可以在围棋规则内下赢高手们一样。
在已有明确规则下不断计算、试错,最终有类人,甚至超越人类的表现,这正是计算机的强项,但我们也不能将这种机械的运算归为人类的智能。
另有一些文章,认为在一些问题上,fRMI 扫描到人类神经激活的现象,和神经网络有相似性,则更像是一种预先假定结论而去有目的性的倒推现象,且实验中的问题本身也是大量归纳即可学到的,笔者认为更不存在什么证明价值。
如果,大模型真的具备了文章所主张的那种智能,那么它应该知道什么是“不合理”,以及什么是“不知道”。
例如我们如果问一个大模型,一个完全不合理的问题(比如,我的脚有几只眼睛),它应该能够分辨出这个问题无法回答,但如果小伙伴们感兴趣,可以去尝试一下现在已有的大模型,看它们会给你什么样的答案。

我们当然也可以去训练大模型,去回答这种问题,但是,我们总归是能够从各种刁钻的角度找出来不同的问题,去让大模型失败的。
原因就在于,我们知道什么是“不合理”,什么时候是“不知道”。对于广阔的不合理、不知道,我们是有明确的认知的,但是统计模型是没有这种推断能力的。
多说一句,如果统计模型真的具备这种能力,科学计算也不会使用半逻辑半统计的方式了
而我们能够“凭空”拓展我们的理论,能够通过一次的修正信号去修改整个行为,也正是得益于这种演绎能力。
很遗憾的是,在初始状态下,人类的学习条件似乎还比不上模型,但人类获得了这种能力,而统计模型没能得到这种能力。
或许当我们告诉模型,它的行为是错误的时候,不够“斩钉截铁”(梯度下降只能“逐步”地修正模型的行为),但哪怕我们能够去精准更新参数,统计模型的推断方式,也不允许它去推断“没有”(即统计模型仍旧不知道分布外的问题是存在于分布外的,毕竟仍旧是连接的)。
何况,统计模型的结构与其训练算法,本就是一体的。人类或许有什么机制能够精准更新自己的大脑,但现有统计模型框架之下,我们并没有办法完成这一点。
哪怕我们真的去描述“知识”(实际上,这也是个几乎不可能的任务),也难以将之传授给统计模型,毕竟,不合理的泛化,几乎没有办法去规避掉,最终的表现,也一定和大数据训练一样,数据丰富的地方,相对合理一些,数据稀疏的地方,它就开始胡乱泛化了。
人学会进行这么大规模的归纳,实际上是低能耗的,但是大模型则不然,想要训练一个百亿级别参数的模型,其耗费的资源是相当巨额的,恐怕会超过一个人从出生到成长为领域专家所耗费的所有资源。
但是笔者认为,这篇文章提到的一些例子,倒是还有一些其他的价值,比如:
已被模型抽象过的表示,其上层映射起来的确更加简单,如颜色的那个例子,或许这方面工作的拓展,可以对多模态模型提供指导经验,例如 Google 今年的 imagen,用大规模语言模型训练,抽象了语义之后再去指导图片生成,就是一篇不错的尝试
现有的统计模型,及其对应的归纳学习机制,的确部分实现了对大部分基本概念的学习,尤其是增加了多模感知信号之后,那么跳出现有框架,探索新的机制或许更加可行
总结:DeepMind 想干什么
笔者认为,DeepMind 的科学家们一定比笔者厉害得多,它们不可能不知道,这篇文章预设的结论有多么不合理,找到的证据又有多么无力,但是它们为什么要发表呢?
答案是,这篇文章应该不是写给内行看的,而是写给外行看的。
哪怕行内人对当前人工智能的现状是什么样的认知,但是几个简简单单的例子,足够震慑到外行人了,而相比于从业者,其他人显然是更多的,那么只要将这些东西放出来,就足以吸引很多人的眼球,那么这个行业的热度就维持住了。
说这么多,也只是希望,从业者,以及想要从业的同学们,别也被这篇文章唬住了,或者被各路大模型的 PR 唬住了,脚踏实地一些,或做出真东西,或探索新套路。
最后,类人也不应该是 AI 的目标,如果 AI 真的类人了,人类又将如何自处?人类想要的也无非是更廉价、更专业、工作时间更长,且不需要为之安全有多负责的助手,而非另一个竞争者。
毕竟,1(数)2(百)年前,人类在潘(新)多(大)拉(陆)星球上,面对从未见过的人类时,都已痛下杀手,又怎会允许现在的人们,造出一个或许能超越自己的智能呢?[doge]

以上。
萌屋作者:Severus
Severus,在某厂工作的老程序员,主要从事自然语言理解方向,资深死宅,日常愤青,对个人觉得难以理解的同行工作都采取直接吐槽的态度。笔名取自哈利波特系列的斯内普教授,觉得自己也像他那么自闭、刻薄、阴阳怪气,也向往他为爱而伟大。
作品推荐
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群

[1]. Dasgupta I, Lampinen A K, Chan S C Y, et al. Language models show human-like content effects on reasoning[J]. arXiv preprint arXiv:2207.07051, 2022.
[2]. Abdou M, Kulmizev A, Hershcovich D, et al. Can language models encode perceptual structure without grounding? a case study in color[J]. arXiv preprint arXiv:2109.06129, 2021.


















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









