







文 | 小戏
记得在刚入门 ML 时,希望找到一个关于特定领域下的数据集,涉世未深的我在中文互联网不断搜索,可每每点进链接出来的都是某 SDN 下载的高价勒索。用惯了直接从老师同学那里讨来的数据集的我第一次感受到了“寻找数据集”这样一个简单任务的艰难。
当然,虽然我们都不断说机器学习深度学习最重要的是数据集,而数据集难获得这事真正的难点倒不在,或者倒不应该在搜索引擎的检索上,其实更多是在于高质量的数据集难获得,行业内的数据集涉及商业、隐私多方考虑,难以直接使用。
但是对于无论是初学还是研究而言,现在业已经有开源的数据集提供者为我们提供了广泛的数据集资源,那么如果能有一个搜索引擎规避掉这些开源数据集提供者之间行业上,网站间的壁垒,降低我们的检索成本,并可以一键直达,直接获取这些数据集资源,那是不是一项挺不错的“便民工程”呢?

于是乎,谷歌大大扛起了这项工作,“无所谓,我会出手”,构建了一个可以称得上是资源“海量”的数据集搜索引擎“Dataset Search”,这篇推文便想向大家简介一下 Dataset Search 的功能,有关构建它的动机与实现方法,大家可以在下面这篇文章中看到:
论文题目:
Google Dataset Search: Building a search engine for datasets in an open Web ecosystem
论文链接:
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/77547c8d2a7fba472e76c774028cf2b3c0afdb8a.pdf
早在 2017 年,Google 就已经开始了“数据集检索”任务的实践,并且在 2019 年提出了一个“数据集搜索引擎”的初步构想与技术框架,而在 2020 年 1 月,“Dataset Search” 正式结束测试,上线了谷歌。
Dataset Search 的页面十分简洁,只有搜索框与和一个简单的登录按钮,使用谷歌账户登录后可以保存、跟踪需要检索的数据集。随便检索一个文本分类的任务,可以看到:
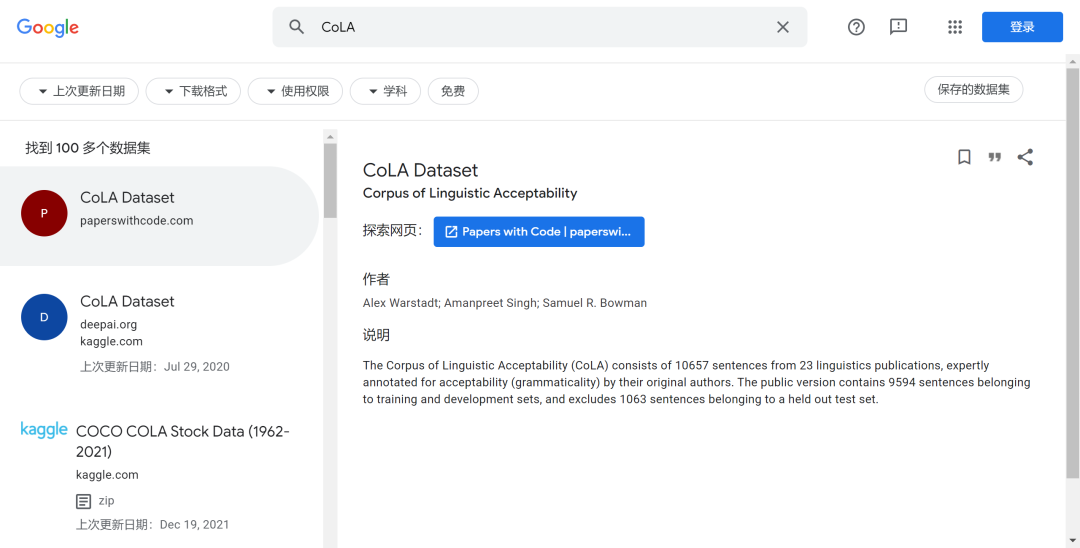
左边是检索结果的排列,根据相关性呈现检索到的结果,右边是检索结果的简介,显示了数据集的来源、获取入口、作者与关于这个数据集的简短说明。链接进去之后,可以直接得到数据的介绍与下载链接。

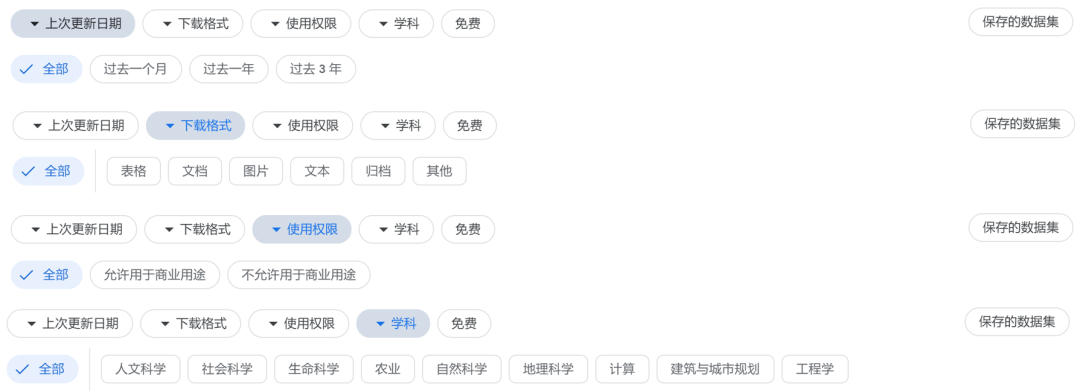
除了基本的检索功能外,Dataset Search 也提供了颇为丰富的筛选功能,可以从时间、下载格式、使用权限、学科与是否付费进行筛选:
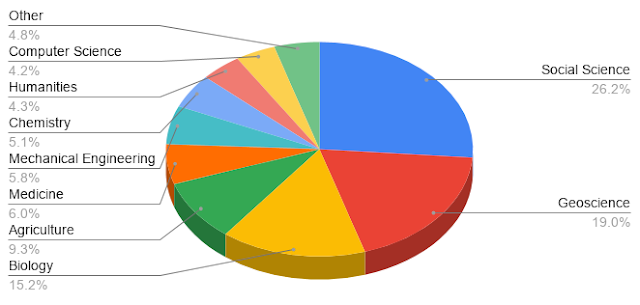
可以看到,这个项目建立之初便不是把目光仅仅聚集于 AI 这一块小天地,而是更加开放的鼓励跨学科的数据集共享,学科已经有人文社科、社会科学、生命科学、农业等等,在 2020 年 8 月谷歌关于这个项目的一个博客中展现了目前这个项目的涉及领域:
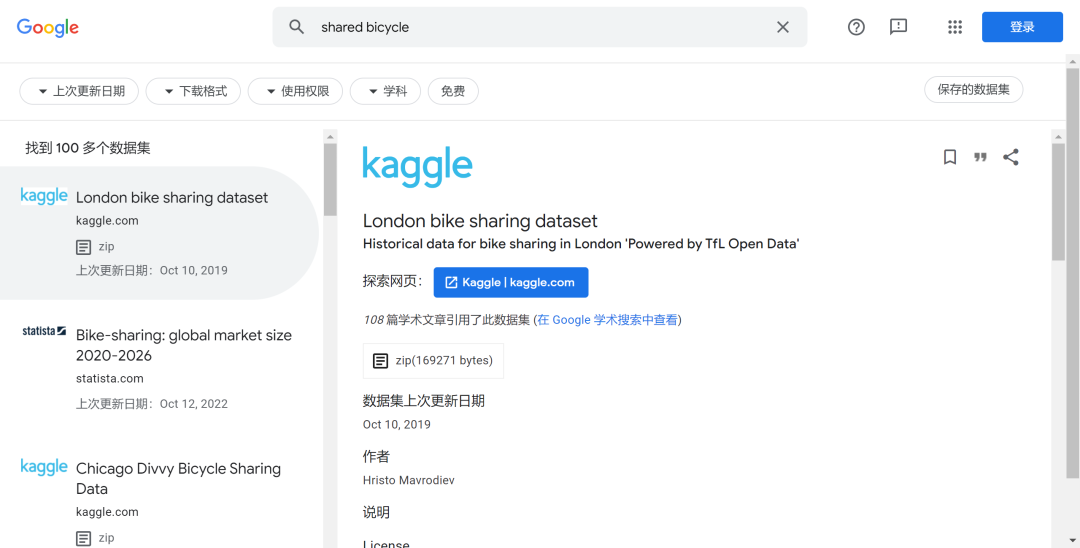
这也使得,Dataset Search 不仅可以针对固定的开源数据集进行搜索,还能对许多特定行业特定领域的数据进行搜索,比如检索“共享单车”,也可以找到大量共享单车的订单、轨迹等数据集:
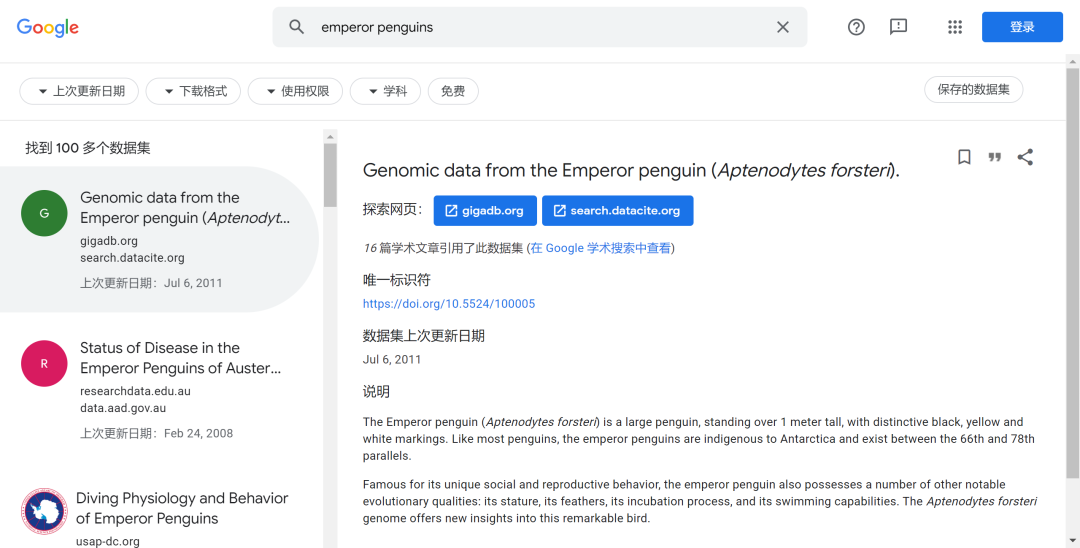
而再偏门一点甚至可以找到帝企鹅的饮食数据集:
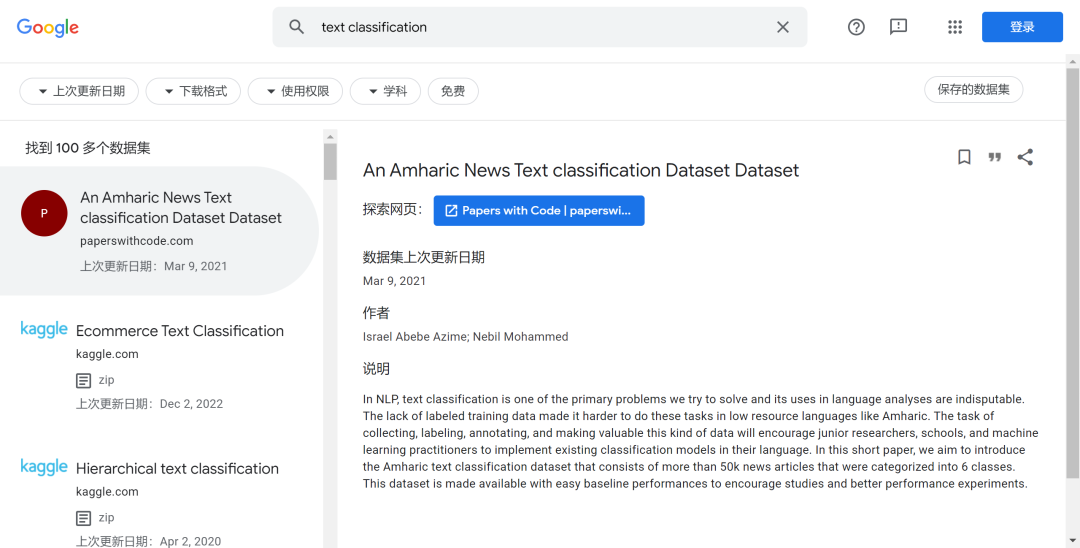
除了依据领域,也可以直接检索任务,比如搜索文本分类,但是在结果不会特别显示出文本分类的常用数据集,但是几乎无一例外,搜索情感分析、主题分析内的常用数据集几乎都可以在 Dataset Search 中找到:
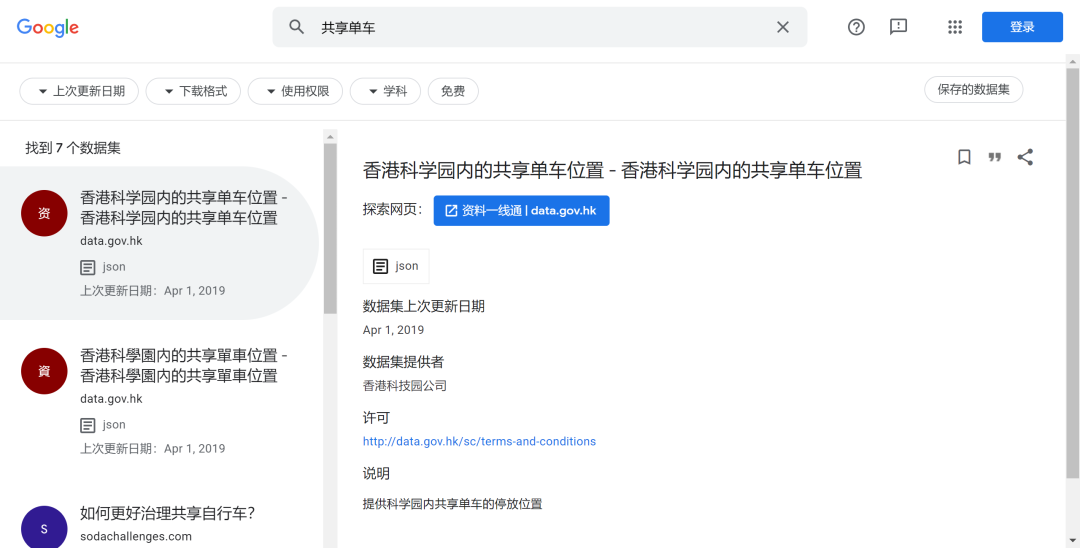
当然,美中不足的是,尽管 Dataset Search 支持中文搜索,但是中文数据集的数量显然不太尽如人意,数据集仍然集中于台湾、香港的大学、比赛发布的数据集:
而在提供强大的检索功能以为,谷歌更想做的,可能是一个数据集共享的生态,以数据集搜索引擎为线索,谷歌沿用了 2011 年提出的 schema.org 计划,schema.org 是一种与搜索引擎进行交互的代码形式,以类似 SEO 优化的形式,告诉搜索引擎在抓取信息时应该关注的重点。
通过 schema.org ,可以在数据集的“供应商”与 Dataset Search 的互动中形成良性循环,更好的为用户展示数据集中的内容,便于用户更加方便快捷的使用。
任何一个学科的发展必然需要良好的社区生态,而在一个良好的生态以外,还需要有配套的“基础设施”建设,通过这些基础设施来降低行业的入行成本,减少一些不必要的内耗。伴随着数据集的重要性愈加凸显以及数据集共享生态的逐渐形成,这个数据据检索引擎也会愈加显示它的重要性吧!
网站链接:
https://datasetsearch.research.google.com
卖萌屋作者:小戏
边学语言学边学NLP~
作品推荐
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群


















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









