






 文章讲述了中科大开发的Woodpecker方法,一种用于解决多模态大模型生成文本与图像不一致的幻觉难题的策略,通过关键概念提取、问题制定和视觉知识验证等步骤,显著提升了模型的准确性。
文章讲述了中科大开发的Woodpecker方法,一种用于解决多模态大模型生成文本与图像不一致的幻觉难题的策略,通过关键概念提取、问题制定和视觉知识验证等步骤,显著提升了模型的准确性。
夕小瑶科技说 原创
作者 | 付奶茶、王二狗
最近多模态大模型的研究取得了巨大的进展。然而,这些模型在生成时存在着文本与图像不一致的问题,这个问题就是一直困扰研究者们的“幻觉难题”。

▲给定一幅图像,MLLM会输出的回应,包括了物体层面和属性层面的幻觉。
为了缓解这个问题,中科大开发了一种名为Woodpecker(啄木鸟)的新方法。这个方法可以从生成的文本中挑选出幻觉并进行纠正。具体来说,直接从模型给出的错误文本下手,“倒推”出可能出现“幻觉”之处,然后与图片确定事实,最终直接完成修正。
一句话总结就是:哪里出现问题就啄哪里~

▲给定MLLM的一个回应,Woodpecker会校正被幻觉的部分并整合基础信息以便于验证。
Woodpecker 包括五个阶段:
-
关键概念提取;
-
问题制定;
-
视觉知识验证;
-
视觉声明生成;
-
幻觉校正。

啄木鸟框架具备轻松适用于各种多模态大型模型的能力,并且通过访问五个不同阶段的中间输出来提供解释。通过实验,可以清晰地观察到,在多个不同的模型(LLaV,mPLUG-Owl,MiniGPT-4,Otter)的评估中,准确率都表现出了不同程度的增长。
特别一提的是,MiniGPT-4 和 mPLUG-Owl 模型分别实现了惊人的30.66%和24.33%的提升!
接下来,让我们一同深入探讨它们取得这一成绩的秘诀~
论文标题:
《Woodpecker: Hallucination Correction for Multimodal Large Language Models》
论文链接:
https://arxiv.org/abs/2310.16045
代码地址:
https://github.com/BradyFU/Woodpecker
算法框架
1.关键概念提取
首先从生成的句子中提取关键概念对象,这些对象最有可能导致视觉幻觉。例如,对于句子“这个男人戴着一顶黑色帽子。”,提取“男人”和“帽子”这两个对象,并将它们作为后续诊断的中心。作者提出可以用具有强大的概括能力和丰富的世界知识的LLMs来完成这个任务。
2.问题形式化
接下来,围绕这些关键概念提出一系列问题,以进行幻觉诊断。这些问题涵盖了对象级别以及属性级别的幻觉。例如,我们可能会探询图像中是否存在特定对象,如果存在,有多少个这种对象,这些对象正在进行什么活动,以及这些对象之间是否存在什么关系等。
3.视觉知识验证
在这个阶段,作者使用开放式对象检测器和预训练的视觉问答(VQA)模型来解决上述问题。对象级别的问题可以通过感知图片来直接验证,而属性级别的问题则更加多样化并且依赖于上下文。
4.视觉声明生成
基于前两步中获得的问题以及对应的视觉信息,合成结构化的“视觉断言”。然后将其组织成一个可供后续步骤参考的可视化知识库。这个知识库包括目标级别的声明和属性级别的声明,前者主要用于减轻目标级别的幻觉,而后者包含特定属性信息,用于减轻属性级别的幻觉。
5.幻觉纠正阶段
作者将LLM用作一个校正工具,用于修改生成的回答中的幻觉。将知识库与原始回答合并,然后指示LLM对回答进行校正并输出最终的答案。
实验
在论文中,作者主要评估了多模态大模型的幻觉方面的应用。作者使用了POPE、MME和LLaVA-QA90三种不同的数据集,并选择了mPLUG-Owl、LLaVA、MiniGPT-4和Otter四种主流的MLLMs作为基线模型。
POPE
该数据集专门用于评估多模态大模型的幻觉。它包含了随机、热门和对抗性采样的设置,这些设置主要在负样本构造的方式上有所不同。作者采样了50张图像,并为每张图像构建了6个问题,将物体注释转化为一系列的“是或否”问题,并侧重于评估物体级别的幻觉。
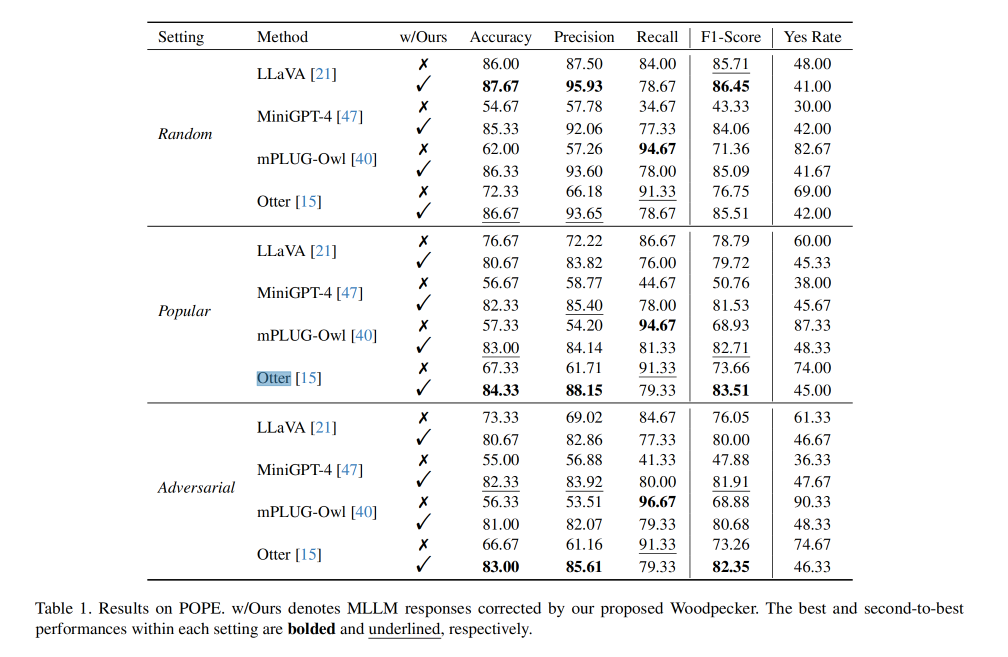
▲表格中w/Ours表示由“啄木鸟”校正的MLLM响应,x为未采用,对勾为采用
我们可以观察到,Woodpecker方法能够显著提升这几个模型的性能,在准确性方面为MiniGPT-4和mPLUG-Owl分别带来了30.66%和24.33%的相对提升。在更具挑战性的常见和敌对设置下,MLLMs的性能都出现不同程度的下降,尤其是在相对强的基线模型(如LLaVA)中,性能下降更为明显。与随机设置相比,LLaVA在常见和敌对设置中的准确性分别下降了9.33%和12.67%。这一趋势表明MLLMs可能会错误地适应训练语料库中的某些数据特征,例如在常见设置中的下降可能源自于长尾数据分布。与此相反,Woodpecker方法因为配备了强大的专家视觉模型,表现出极高的稳定性,显著改善了各种基线模型的各项指标,所有模型的准确性都超过了80%。特别值得一提的是,Woodpecker方法将mPLUG-Owl在敌对设置中的准确性从56.33%大幅提升至81%。
MME
MME是一个综合性基准,旨在评估MLLMs在各个方面的性能。它包括十个感知能力子任务和四个认知能力子任务。作者重新利用了数据集,选择存在性和计数子集来衡量对象级幻觉,位置和颜色子集用于衡量属性级幻觉。
MME的实验更加全面,因为它不仅涵盖了物体级别的幻觉评估,还包括属性级别的幻觉评估。我们可以看到,在物体级别的评估中,LLaVA和Otter在存在方面表现出色,但是在更难的计数查询方面相对落后。在这种情况下,啄木鸟校正方法显得更加有效,为LLaVA带来了+65的分数增益,为MiniGPT-4带来了+101.66的分数增益。
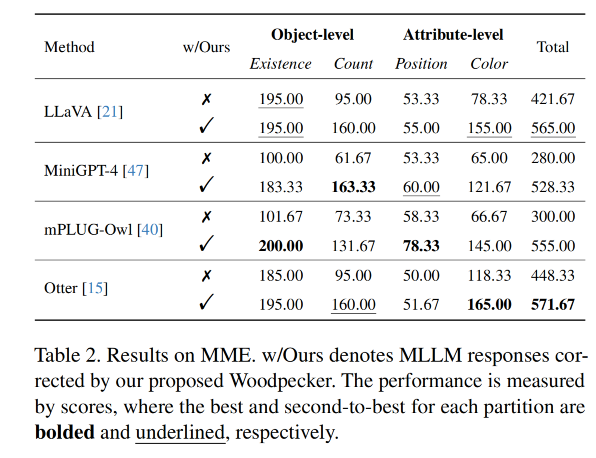
相比之下,位置方面的改进相对较小,作者推断这可能是由两个因素引起的:(1)VQA模型BLIP-2在位置推理方面的相对较弱能力;
(2)LLM可能无法充分理解给定的边界框以自行推导出位置关系。
LLaVA-QA90
这个数据集也被用于评估MLLMs,作者抽样了10个以不同形式改写的描述性查询,来指导MLLM描述一张图片。
实验过程由三个预训练模型组成,需要进行修正的MLLM,以及LLM、GPT-3.5-turbo来完成关键概念提取、问题形成和幻觉修正的子任务。对于开放式目标检测,使用Grounding DINO来提取默认检测阈值下的目标计数信息。此外,作者利用BLIP-2-FlanT5XXL作为VQA模型,以回答与输入图像相关的属性问题。
不同于上述的两个实验,它只涉及“是或否”类型的问题,LLaVA-QA90的实验更为开放。描述型查询要求MLLMs完全将输入图像翻译成语言,而不仅仅是关于对象的存在或属性。采用了一个纯文本的GPT-4,图像内容以简短的说明和一些对象的边界框的形式馈送给语言模型。
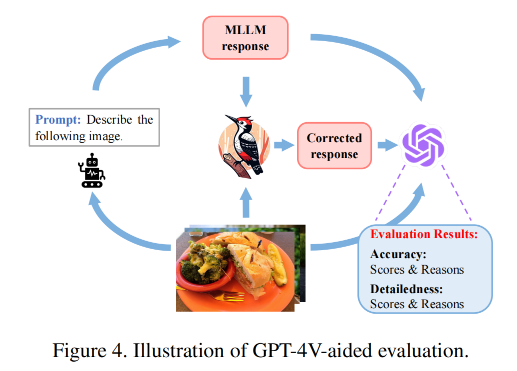
如图4所示,GPT-4V可以直接接收原始回应、校正后的回应,最重要的是输入图像。在这种情况下,可以要求GPT-4V提供评估结果和判断理由。
作者设计了以下两个指标:
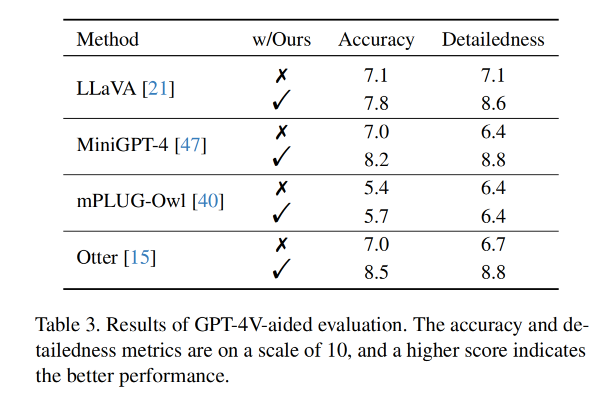
• 准确性:回应是否与图像内容相符。• 详细程度:回应是否丰富多细节。
这两个指标的得分显示在表3中,啄木鸟也取得了一致的提升。一方面,准确性的提高表明能够有效校正MLLM回应中的幻觉。另一方面,引入的边界框信息为回应增加了细节,从而提高了详细程度。
在这里,小编插播一句,最近我们也进行了一个有趣的类似评估,大家也可以参考一下~
GPT-4和DALL·E 3彻底懵逼,这到底是「牛」还是「鲨」
各种结果都表明,在经过“啄木鸟”修正后,图片描述的准确性有了显著的提升。这表明啄木鸟框架能够有效地纠正描述中的幻视现象,从而使描述更准确和可信。此外,修正方法还引入了更多的位置信息,进一步丰富了文本描述,提供了更多物体位置的信息量。

▲GPT-4V辅助的评测样例
小结
啄木鸟引入了基于纠正机制的框架,能给减轻多模态语言模型中存在的幻觉问题。这一方法无需额外训练,而是结合了多个现有模型,可轻松整合到各类多模态语言模型中,作者通过一系列实验验证了所提出方法的有效性。
尽管Woodpecker等方法取得了显著的效果,有望为解决幻觉问题开辟新的思路。但是,多模态大模型的幻觉问题依然存在,因此仍需要进一步的研究和创新来全面解决。



















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









