






现在的大模型论文简直像是在比长度,动不动就上百页!记得前阵子小编瞅见那份90页的Gemini技术报告,顿时脑袋嗡嗡作响。那会儿就幻想着:要是有个AI大脑来啃下这些"学术巨无霸",那岂不是爽歪歪?
没想到过了几个月,这个幻想竟然实现了!如今大语言模型正在挑战这一难题,试图成为我们阅读长文本的得力助手。但问题是,这些AI助手自己对付长文本的能力如何呢?
近日,上海AI实验室推出了一个名为NeedleBench的评测框架,对36个主流大模型展开了一场别开生面的"长文本大比拼"。这项研究不仅测试了模型们在不同长度文本上的表现,还设计了一系列渐进式的挑战任务,就像是给LLMs出了一道道难度递增的阅读理解题。
有趣的是,在这场比拼中被誉为"LLM界的高考状元"的GPT-4竟然只拿到了第二名!反倒是Claude-3-Opus后来者居上,一举夺魁。这个结果让不少人大跌眼镜,也引发了业界对大模型长文本能力的新思考。
研究还发现,虽然这些AI模型在找出单一关键信息方面表现不错,就像能准确回答"课文第三段第二句说了什么",但在需要综合分析、逻辑推理的复杂问题上,它们却显得有些力不从心。这就好比,LLMs能轻松找出文中的重点句,却在写读后感时犯了难。
系好安全带!咱们马上就要深入剖析这项研究的"秘笈",看看AI大脑是如何对付这些"学术巨无霸"的。顺便也畅想一下,未来的AI说不定能一口气吞下整本百科全书呢!

论文标题:
NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
论文链接:
https://arxiv.org/pdf/2407.11963
LLM的长文本挑战
大语言模型(LLM)在处理短文本方面已经表现出色,但长文本处理仍是一个重要挑战。想象一下,如果LLM能轻松理解冗长的法律文件或学术论文,这将为我们的工作和学习带来巨大便利。
近期,各大AI公司在这一领域纷纷展示了自己的实力。OpenAI的GPT-4 Turbo可处理128K个词元,Anthropic的Claude 3系列声称能处理超过100万词元,Google的Gemini 1.5更是宣称支持数百万词元的处理能力。开源模型如GLM4-9B-Chat和InternLM2.5-7B-Chat也加入了这场竞争。

然而,仅仅能处理长文本是不够的,关键在于是否真正理解内容。为此,上海AI实验室推出了NeedleBench评测框架。这个框架不仅测试模型的长文本处理能力,还考察它们的信息检索和逻辑推理能力。
NeedleBench的核心是在长文本中植入关键信息,然后测试AI是否能准确找出这些信息并进行复杂推理。特别值得一提的是"祖先追踪挑战"(ATC)任务,它模拟了现实世界中复杂的逻辑推理问题。
研究结果显示,当文本长度增加到约1120个词元时,大多数开源模型在处理复杂逻辑问题时的准确率显著下降。这表明,即使是最先进的AI模型,在长文本的深度理解上仍面临挑战。
下图呈现了三个顶级模型(GPT4-Turbo、Claude-3-Opus和GLM-4)在ATC测试中的表现。从图中可以看出,随着上下文长度和复杂度的增加,即使是这些顶级模型的表现也呈现出明显的下降趋势。特别是当上下文长度达到1988个词元,包含77个需要追踪的信息点时,所有模型的得分都大幅下降。这一结果凸显了长文本处理,尤其是涉及复杂逻辑推理时,对AI模型的巨大挑战。
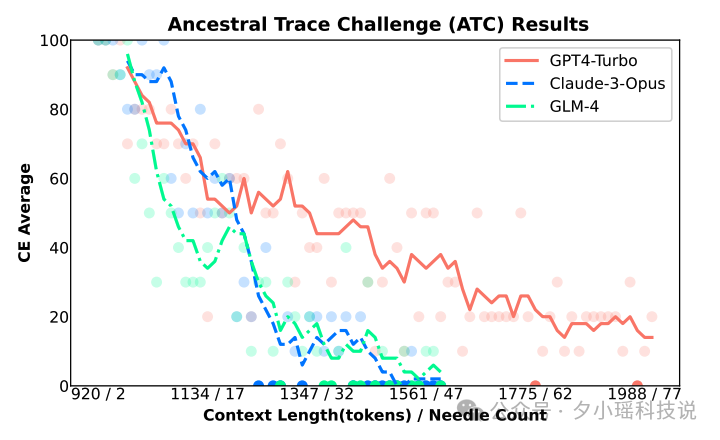
通过NeedleBench,我们看到AI在单一信息检索方面表现出色,但在需要深度理解和复杂推理的任务中仍有提升空间。在我们使用LLM时需要合理评估LLM的能力边界。
如何测试AI的"阅读理解"能力
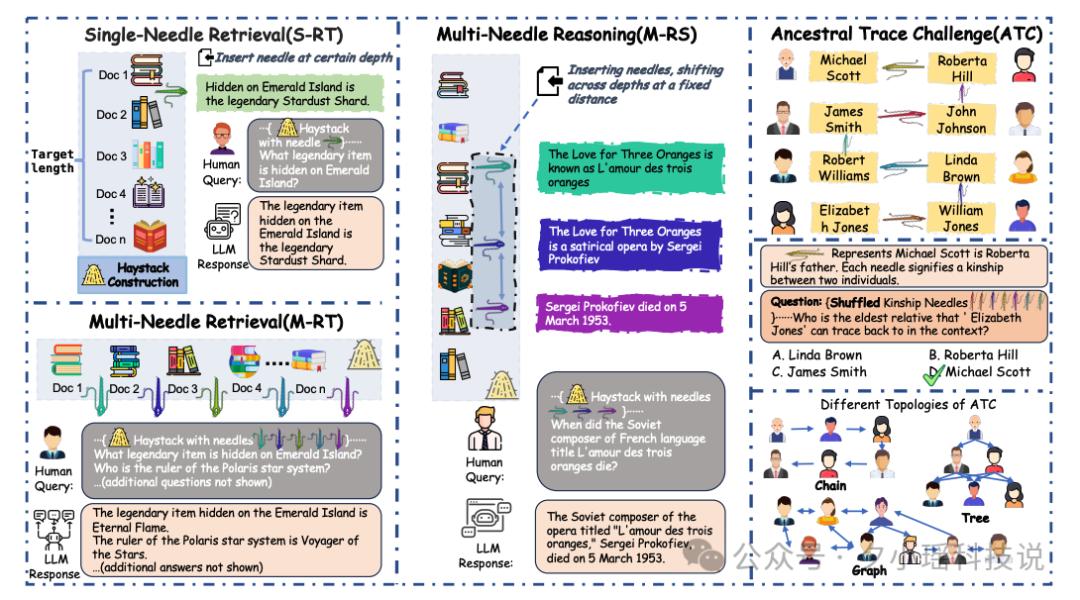
NeedleBench评测框架设计了一系列任务,全面考验AI的信息检索和逻辑推理能力。这个框架包括三个主要任务:单针检索任务(S-RT)、多针检索任务(M-RT)和多针推理任务(M-RS)。
下图展示了NeedleBench的框架结构。左侧展示了单针和多针检索任务,中间部分展示了多针推理任务,右侧则呈现了祖先追踪挑战(ATC)的不同拓扑结构。这张图直观地展示了从简单的信息检索到复杂的逻辑推理,NeedleBench如何逐步增加任务难度。
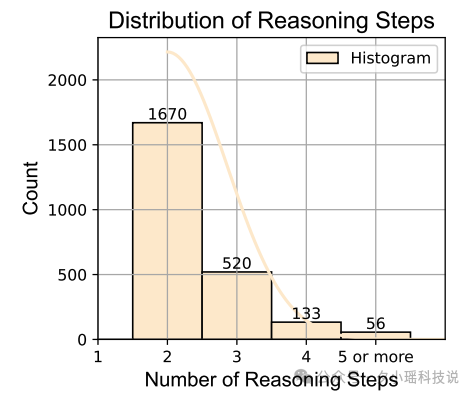
在多针推理任务中,研究团队利用了 数据集。下图展示了这个数据集中推理步骤的分布情况。从图中我们可以看出,大多数推理问题涉及两到三个步骤,少数问题需要四步或更多步骤来解决。
祖先追踪挑战(ATC)是NeedleBench的终极挑战。这个任务要求AI在长文本中追溯复杂的家族关系。研究团队设计了不同拓扑结构的家族关系,包括链状、树状和图状。
研究人员展示了关键信息("针")放置在文本开头、中间和结尾的情况,直观地说明了任务的设计方式。下图展示了在文本开头的例子。

下图则展示了多针检索任务的样例,其中包含了五个需要AI模型同时检索的信息点。

除此之外,文中还展示了多针推理任务的样例,要求模型不仅要找到相关信息,还需要基于这些信息进行推理。

祖先追踪挑战(ATC)任务的设计通过一系列示例和最终挑战问题来测试AI模型的复杂逻辑推理能力。这个任务包括四个引导示例和一个终极挑战问题,旨在全面评估模型的深度理解能力。特别值得注意的是,带有推理路径的示例清晰地展示了如何评估模型的逻辑推理过程,不仅关注最终答案,还重视模型如何一步步得出结论。这种设计方法有效地测试了AI是否真正理解了复杂的家族关系,以及是否能够基于给定信息进行多步推理。

评分系统采用Levenshtein距离来衡量AI回答与标准答案的相似度,同时考虑关键词的出现情况。这种评分方法不仅看重整体表达,还关注核心要点的把握。
通过这一系列精心设计的任务和评估方法,NeedleBench全方位地考察了AI的长文本处理能力,从简单的信息检索到复杂的逻辑推理。
LLMs的'阅读成绩单'
NeedleBench评测框架为36个主流大模型提供了一份全面的"阅读成绩单",涵盖了从4K到1000K token的多个文本长度区间。这些模型包括了Claude-3-Opus、GPT4-Turbo等顶级商业API模型,以及众多开源模型如InternLM、Qwen和Baichuan系列等。

在NeedleBench评测框架中,研究团队采用了一种复杂而全面的评分机制来衡量AI模型的表现。这个评分系统的核心是一个基于Levenshtein距离的公式,用于计算模型预测与参考答案之间的相似度。
具体来说,评分公式如下:
其中, 和 分别代表模型的预测和参考答案; 是与每个 相关的核心关键词集合; 是 和 之间的Levenshtein距离; 和 分别是 和 的长度; 是一个惩罚因子,设定为0.2。
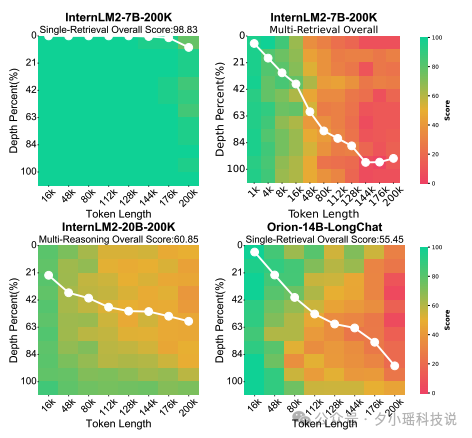
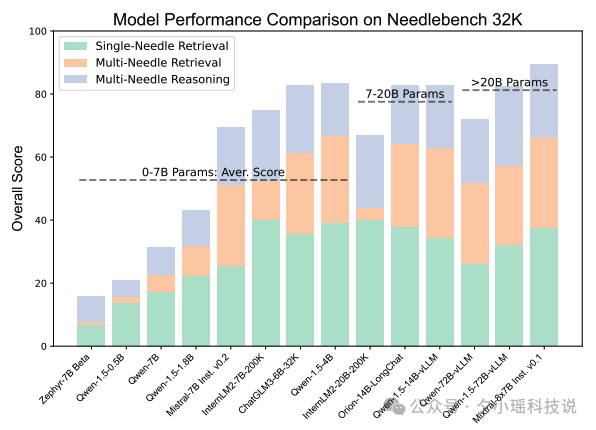
评测结果呈现了一幅复杂的AI能力图谱。在32K token的测试中,Mixtral-8x7B Instruct v0.1模型以89.38的总分位居榜首,展现了优秀的综合能力。紧随其后的是Qwen-1.5-72B-vLLM和ChatGLM3-6B-32K,分别以82.36和82.86的总分展示了强劲实力。这些结果表明,即使是参数量较小的模型,通过精细调优也能在特定任务上与大模型比肩。
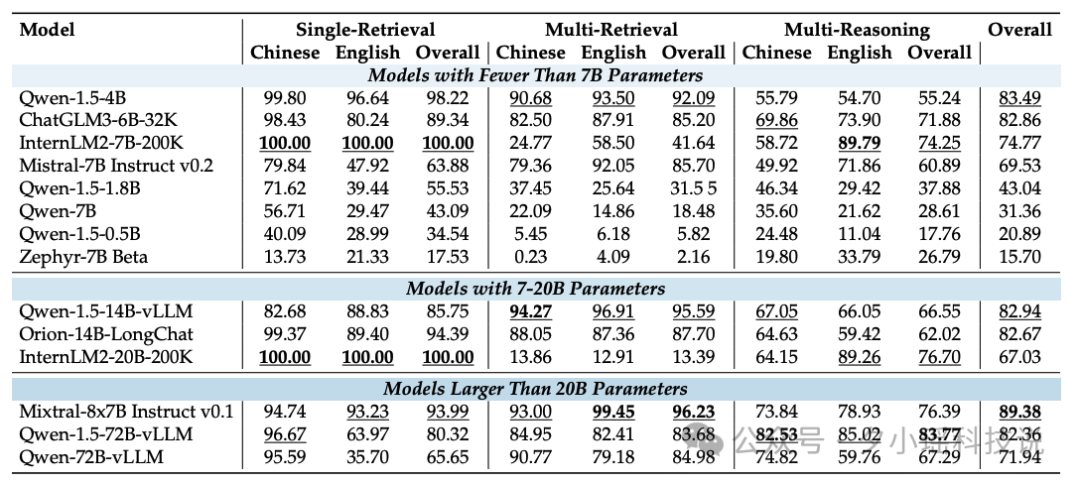
当文本长度延伸至200K token时,能够支持如此长文本的开源模型数量显著减少。在这一挑战中,InternLM2-7B-200K模型表现出色,尤其是在单针检索任务中几乎达到了完美表现。然而,同一模型在多针检索任务中表现不佳,暴露出在指令遵循方面的不足。
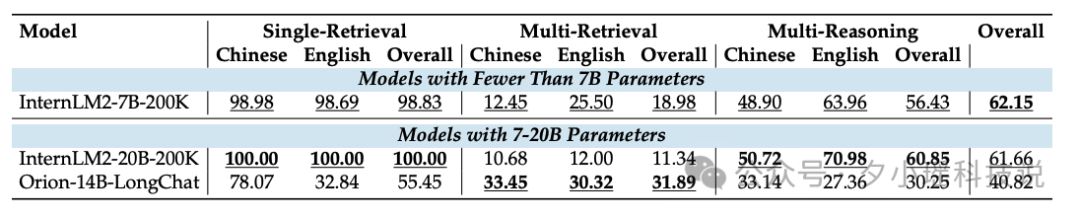
文章中还对不同模型在200K token内的结果进行可视化,随着文本长度的增加,模型效果普遍下降。
更具挑战性的是1000K token测试。在这一极限测试中,仅有InternLM2.5-7B-Chat-1M和GLM4-9B-Chat-1M两个模型参与。结果显示,InternLM2.5-7B-Chat-1M在大多数任务中表现优于GLM4-9B-Chat-1M。特别值得注意的是,通过调整提示策略,GLM4-9B-Chat-1M的性能得到显著提升,这凸显了提示工程在发挥模型潜力中的重要作用。

祖先追踪挑战(ATC)任务的结果尤为引人注目。API模型在这项任务中展现出明显优势,Claude-3-Opus以57.61的总分领先,其次是GPT4-Turbo(48.29分)和GLM-4(42.99分)。在开源模型中,DeepSeek-67B表现最为出色,总分达到44.03,接近顶级API模型的水平。这一结果显示了开源模型在缩小与商业API模型差距方面的潜力。
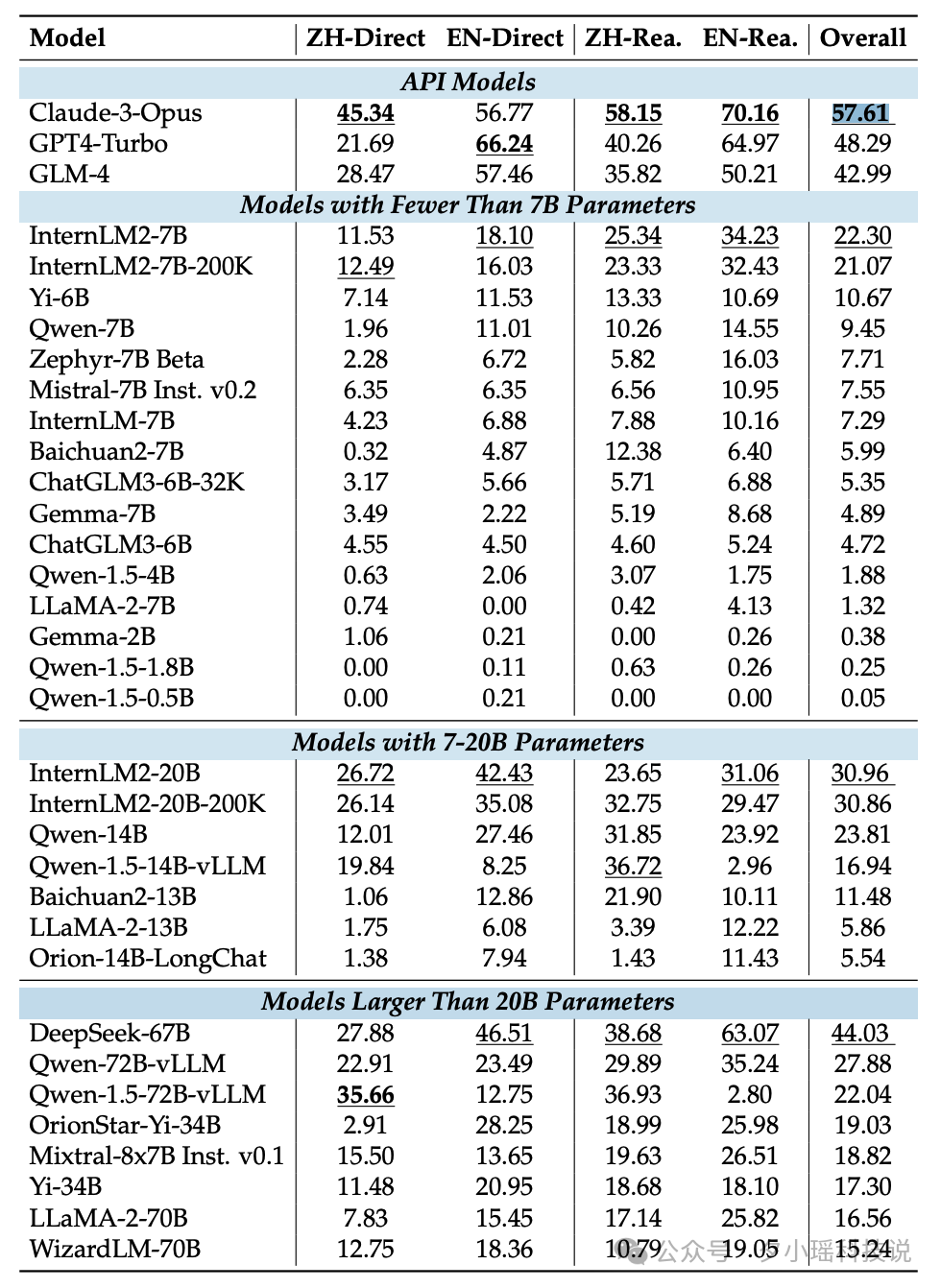
ATC测试还揭示了一个普遍趋势:随着上下文长度和复杂度的增加,几乎所有模型的表现都呈现下降趋势。特别是当推理步骤达到16步左右时,大多数开源模型的准确率降至10%以下,即使是在仅有约1120个词元的情况下。这一发现凸显了AI在处理复杂逻辑关系时面临的巨大挑战。
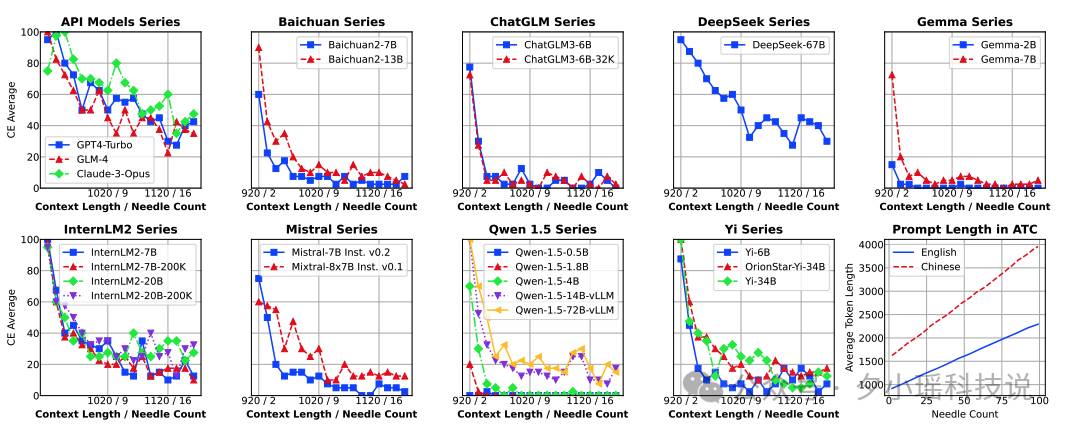
研究还发现,模型规模与性能之间并非简单的线性关系。例如,在Qwen系列中,72B参数版本在某些任务上的表现不如参数较少的版本。这一发现强调了模型优化策略的重要性,而不仅仅是增加参数量。
此外,实验结果还揭示了模型在指令遵循方面的有趣现象。一些模型在被要求回忆更多信息点时,反而提高了对第一个信息点的回忆准确率。这种看似矛盾的现象为未来的模型优化提供了新的思路。
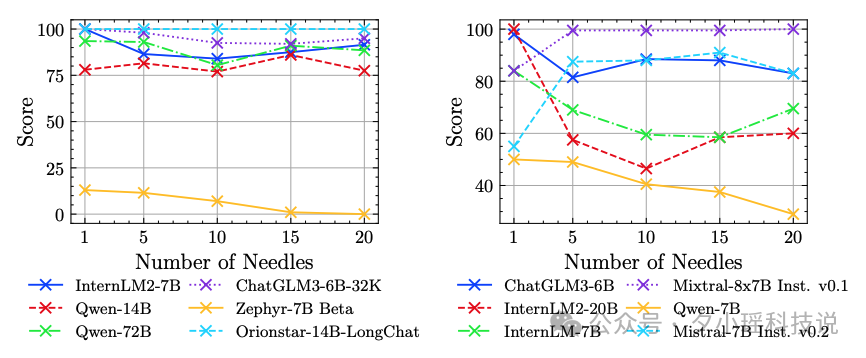
总的来说,NeedleBench的评测结果不仅展示了当前AI模型在长文本处理方面的进展,也揭示了它们在复杂推理任务中面临的挑战。同时,实验也展示了一些意外发现,如某些模型在多信息点检索时表现出的非线性改善,以及模型规模与性能之间的复杂关系。
总结与展望
上海AI实验室推出的NeedleBench评测框架为我们呈现了一场精彩的长文本处理能力大赛。在这场由36个大模型参与的角逐中,我们看到了令人意外的结果:被誉为AI界顶尖选手的GPT-4仅排第二,而Claude-3-Opus摘得桂冠。这一结果不仅展示了AI技术的飞速进步,也反映了长文本处理领域的激烈竞争。
NeedleBench的评测结果揭示了当前AI模型在长文本处理方面的优势与挑战。虽然在单一信息检索任务中表现出色,但在涉及复杂逻辑推理的长文本任务中,即使是最先进的模型也面临显著困难。特别是在祖先追踪挑战(ATC)中,随着推理步骤的增加,几乎所有模型的性能都出现了明显下降。
这些发现为AI技术的未来发展指明了方向。首先,提升模型的长文本理解和复杂逻辑推理能力仍是一个重要课题。其次,模型规模与性能之间的非线性关系提醒我们,未来的研究不应仅仅关注增加参数量,还要着重优化模型结构和训练策略。最后,某些模型在多信息点检索时表现出的非预期改善,为我们提供了新的研究思路。
未来,我们期待看到更多针对长文本处理和复杂推理能力的创新。这不仅将推动LLM在学术研究、法律分析、商业智能等领域的应用,还可能带来AI理解和处理信息方式的根本性变革。


















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









