






 文章介绍了如何在Python中使用正则表达式验证手机号和车牌号,处理文本和二进制文件,包括写入、读取、计算标准方差以及文件内容操作,展示了pickle模块在序列化和反序列化数据方面的应用。
文章介绍了如何在Python中使用正则表达式验证手机号和车牌号,处理文本和二进制文件,包括写入、读取、计算标准方差以及文件内容操作,展示了pickle模块在序列化和反序列化数据方面的应用。
一、主要目的:
1.了解正则表达式的基本概念和处理过程。
2.掌握使用正则表达式模块 Re 进行字符串处理的方法。
3.了解文件的基本概念和类型。
4.掌握在 Python 中访问文本文件的方法和步骤。
5.熟悉在 Python 中访问二进制文件的方法和步骤。
二、主要内容和结果展示:
1.编写一个程序,使用正则表达式校验输入的手机号是否正确。
import re
str = input("请输入手机号:")
reg = r"\b1[3-9]\d{9}\b"
res = re.match(reg, str, re.M)
if res:
print("校验输入的手机号正确。")
else:
print("校验输入的手机号不正确。")

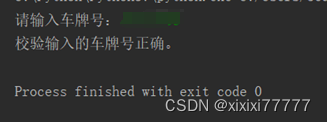
2.编写一个程序,使用正则表达式校验输入的车牌号是否正确。
import re
str = input("请输入车牌号:")
reg1 = r"\b[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领][A-HJ-NP-Z][A-HJ-NP-Z0-9]{5}\b"
flag1 = re.findall(r"[A-HJ-NP-Z]",str)
if len(flag1) > 3:
print("校验输入的车牌号不正确。")
exit(0)
reg2 = r"\b[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领]\d{6}\b"
reg3 = r"\b[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领][A-HJ-NP-Z]\d{5}\b"
reg4 = r"\b[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领]\d{5}[A-HJ-NP-Z]\b"
reg5 = r"\b[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领][A-HJ-NP-Z]{2}\d{4}\b"
res1 = re.match(reg1, str, re.M)
res2 = re.match(reg2, str, re.M)
res3 = re.match(reg3, str, re.M)
res4 = re.match(reg4, str, re.M)
res5 = re.match(reg5, str, re.M)
if res1 or res2 or res3 or res4 or res5:
print("校验输入的车牌号正确。")
else:
print("校验输入的车牌号不正确。")
3.编写一个程序,通过键盘将曹操的《观沧海》写入文本文件gch.txt 中。
str = input("请输入观沧海:")
with open("gch.txt","w") as file:
num = file.write(str)
if num != 0:
print("写入字符串成功!")


4.编写一个程序实现如下功能:
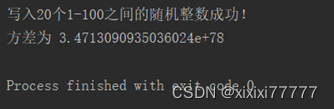
(1)随机产生 20个1~100之间的随机整数,写入文本文件sjs.txt 中。
(2)从文本文件 sjs.txt 中读出数据,计算并输出标准方差。
import random
list1 = []
sum = 0
d = 0
for x in range(20):
list1.append(str(random.randint(1,100)))
with open("sjs.txt","w") as file:
file.writelines(list1)
print("写入20个1-100之间的随机整数成功!")
with open("sjs.txt","r") as f:
str = f.readlines()
for i in str:
sum += int(i)
aver = sum / 20
for j in str:
d += (int(j) - aver) ** 2
d /= 20
print("方差为",d)

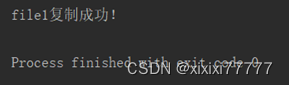
5.编写一个程序,将文本文件 file1.txt 中的内容复制到文本文件file2.txt(空文件)中。
with open("file1.txt","w") as file1:
num1 = file1.write("此为文件file1!")
with open("file2.txt","w") as file1:
num1 = file1.write("此为文件file2!")
with open("file2.txt","w") as file2:
with open("file1.txt","r") as file1:
str = file1.read()
num2 = file2.write(str)
print("file1复制成功!")
6.编写一个程序,将文本文件 filel.txt 中的内容连接到文本文件 file2.txt 的内容后面。
with open("file1.txt","w") as file1:
num1 = file1.write("此为文件file1!")
with open("file2.txt","w") as file1:
num1 = file1.write("此为文件file2!")
with open("file2.txt","a") as file2:
with open("file1.txt","r") as file1:
str = file1.read()
num2 = file2.write(str)
print("file1复制成功!")


7.有两个文本文件(a.txt 和b.txt),各存放一行英文字母,要求把这两个文件中的信息合并(按字母顺序排列),写到一个新文件c.txt 中。
with open("a.txt","w") as file1:
num1 = file1.write("hello")
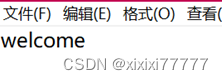
with open("b.txt","w") as file2:
num2 = file2.write("welcome")
with open("c.txt","w") as file5:
with open("a.txt","r") as file3:
str1 = file3.read()
with open("b.txt","r") as file4:
str2 = file4.read()
str3 = sorted(list(str1+str2))
num3 = file5.write(" ".join(str3))
print("两个文件中的信息合并成功!")


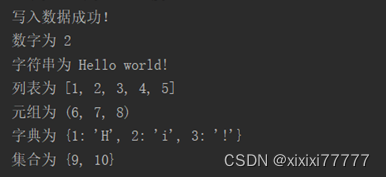
8.编写一个程序,分别将一个数字、字符串、列表、元组、字典和集合写入一个二进制文件bFile.dat 中,然后从二进制文件 bFile.dat 中读出并显示。
import pickle
num1 = 2
str2 = "Hello world!"
list3 = [1,2,3,4,5]
tuple4 = (6,7,8)
dict5 = {1:"H",2:"i",3:"!"}
set6 = {9,10}
data = [num1, str2, list3, tuple4, dict5, set6]
with open("bFile.dat","wb") as pickle_file:
for i in data:
pickle.dump(i, pickle_file)
print("写入数据成功!")
with open("bFile.dat","rb") as pickle_file:
data1 = pickle.load(pickle_file)
print("数字为",data1)
data2 = pickle.load(pickle_file)
print("字符串为", data2)
data3 = pickle.load(pickle_file)
print("列表为", data3)
data4 = pickle.load(pickle_file)
print("元组为", data4)
data5 = pickle.load(pickle_file)
print("字典为", data5)
data6 = pickle.load(pickle_file)
print("集合为", data6)
三、心得体会
在实验中,学习了如何使用正则表达式来验证中国的手机号和车牌号格式的正确性。这些任务演示了正则表达式强大的模式匹配能力,它能够识别符合特定规则的字符串。在这个过程中,意识到编写和理解正则表达式可能需要一些时间,但一旦掌握,它可以极大地简化字符串处理任务。同时,还操作了文本和二进制文件,实现了不同的功能,如数据写入、读取、计算标准方差、文件内容复制和合并等。你还使用了pickle模块来进行Python数据结构的序列化和反序列化,这是在二进制文件中存储复杂数据的有效方法。
1. 正则表达式的强大:正则表达式在进行复杂字符串匹配和搜索时的强大功能。通过适当的模式,几乎可以识别和验证任何形式的字符串数据。
2. 文件操作的灵活性:Python的文件操作非常灵活,可以很容易地处理文本和二进制数据。文本文件适用于人类可读的数据,而二进制文件则适用于存储和传输序列化数据。
3. 数据持久化的重要性:通过实验,了解到了数据持久化的重要性。将数据写入文件,可以在程序关闭后保留数据,并且在以后可以重新加载和处理这些数据。
在实验中可能遇到了一些问题,通过查阅文档、编写和调试代码来解决这些问题,解决能力和逻辑思维能力也得到了提升。对Python语法和使用Python标准库中的模块(如`re`和`pickle`)也有了更深的理解和实践。
















 3506
3506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











