







论文介绍
谷歌DeepMind团队在2017年文章《Population Based Training of Neural Networks》中提出的PBT算法,看似比较简单和朴素,但是在实际应用中结果表现良好。
论文链接:https://arxiv.org/pdf/1711.09846v2.pdf
论文源码:(没有官方的)https://paperswithcode.com/paper/population-based-training-of-neural-networks
自己体会
介绍这篇论文的文章蛮多了,我争取说一些别人没有提到的点。
其它同学的参考链接:
https://blog.csdn.net/jinzhuojun/article/details/100047416
https://zhuanlan.zhihu.com/p/313792467
https://www.cnblogs.com/initial-h/p/10519150.html
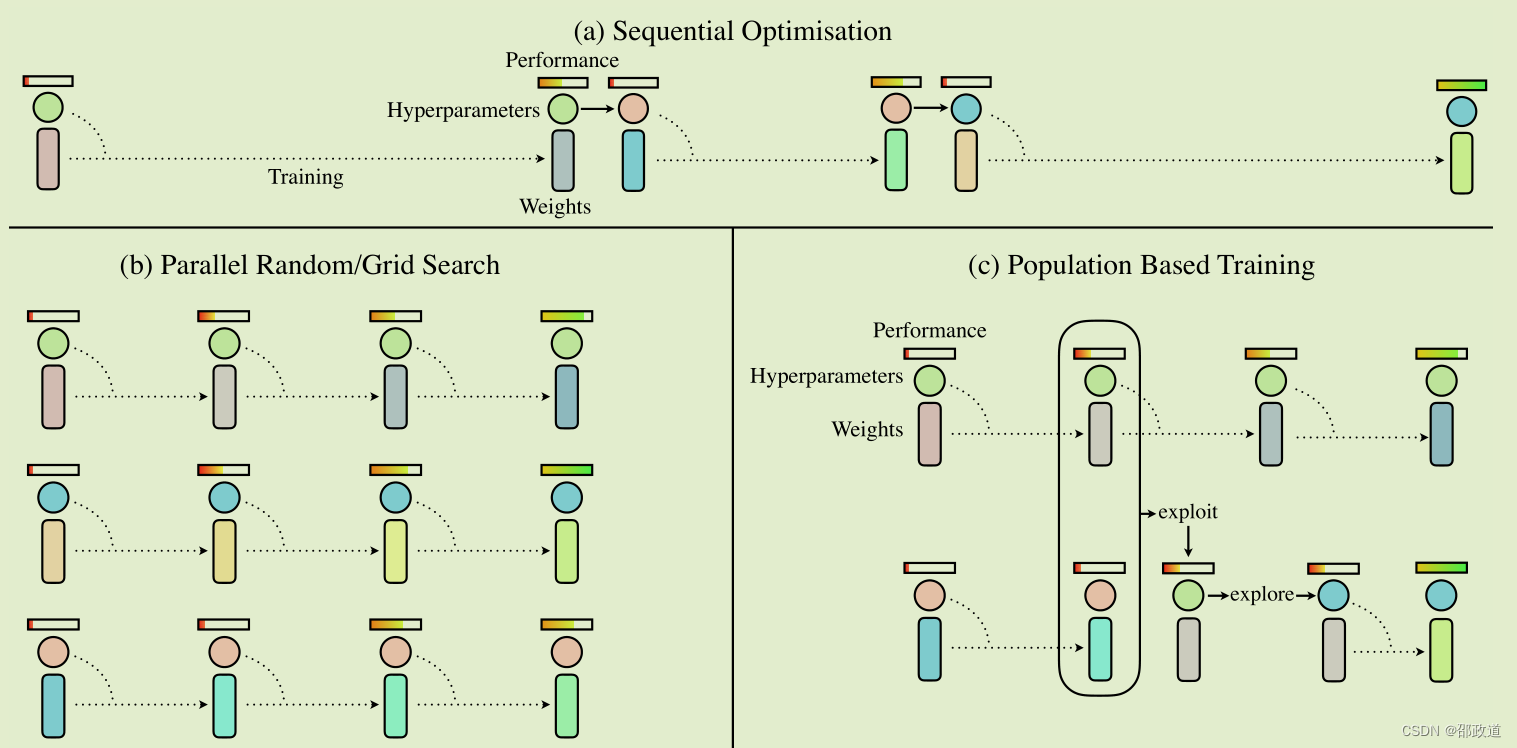
算法核心框图:
在博弈中,常常会因为“策略的旋度(non-transitive)”导致学到的策略循环往复,最后什么都没有学到的情况。比如石头剪刀布游戏中,如果只用简单的self-play 方式训练best response,就会在 一直出石头->一直出布->一直出剪刀->一直出石头的循环中浪费算力。
在《Real World Games Look Like Spinning Tops》一文中提到过,策略有Transitive和non-transitive两部分,从某个角度看,整个策略集合就像一个陀螺,而一个博弈中,绝大部分的策略都属于中间有着极大策略旋度的地方。对处于策略旋度较大的策略生成best-response时,主要梯度方向会是水平方向的(沿着non-transitive方向),这是我们训练策略时不愿意看到的。
这就导致最终选择出来的策略,在Transitive方向可能并没有提升,甚至可能会是负提升。而且,在引入了神经网络之后,self-play并不能保证策略向着纳什均衡解的方向前进。
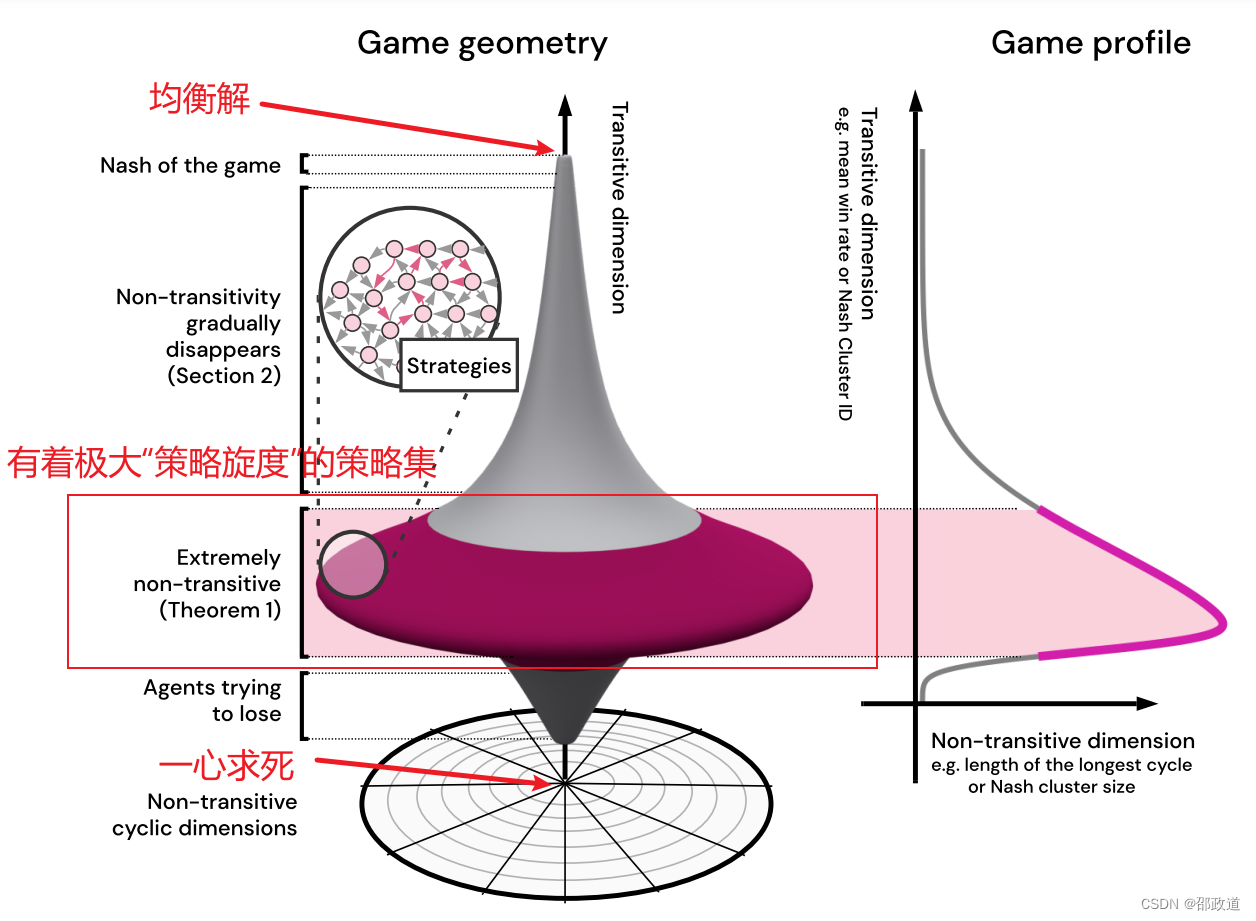
如论文中这张图所示,很多训练方式如self-play,都必须在原本的智能体具有一定水平时,才能够保证生效。
Go 是self-play声名鹊起的重要原因之一。它能够有很好效果的原因,可能在于围棋本身是一个non-transitive分量很小的游戏,很少有长期打不过低级别选手却能打赢高级别选手的案例。面对更加复杂的游戏,可能就会有更多的“transitive”分量了。

而PBT这篇文章,提出的模型训练方式其实有一点“帕累托改进”的意味,或者有点像Double DQN里面“胜者诅咒”导致的过估计。如果种群足够大,从种群中选择出“最能打”的Agent,确实是可以做到,大概率会在transitive方向有分量的,这个概率远远大于传统基于self-play在transitive上有提升的概率。
另外,不难证明,如果游戏的策略旋度越大,则方差越大,用PBT求解时,种群基数就要越大。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











