







论文阅读: ECCV2016 Chained Predictions Using Convolutional Neural Networks
作者:Georgia Gkioxari, Alexander Toshev Navdeep Jaitly
单位:1. University of California at Berkeley 2. Google Inc.
尝试了下Markdown把原来用latex写的记录转换成markdown,感觉用起来还行,就是图片不好用。。还是要上传。。。还是挺麻烦。。。
本文所解决的问题
本文的核心思路就是:
尝试改造CNN,使得CNN变成Recurrent的网络,以解决单个图像中人姿态以及视频中人姿态的估计问题。
本文工作以及创新点
本文的主要创新点是将Recurrent CNN用于人的姿态估计,有两种类型的输入,一种是针对单幅图像的,一种是视频的。
那么针对这两种分别采取两种不同的输入方式,单幅图像的输入序列是关节的heatmap作为输入序列,第一次输入的是一幅图像,而后阶段的输入将前一阶段所输出的heatmap作为输入返回去输入给自身,每次都进行解码,依次预测出各个关节的heatmap。
而视频的输入则是若干个视频帧所组成的序列,每个视频帧作为输入序列的元素。通过将前一帧的信息进行编码得到隐含的表示。结合当前帧利用CNN所提取的特征解码出该视频帧所对应的姿态。
网络架构一览
首先来看网络架构,如图
???
所示为系统的整体架构示意图。
![网络架构图][arch](https://img-blog.csdn.net/20160913211841321)
如上图右边是传统的CNN获得关节位置的示意图,而右边则是本文所提出的单幅图像使用Recurrent CNN进行预测的示意图。
第一次的时候输入的是一幅图片,然后第二次的时候输入的不仅仅是图片的还有前几次输出的其他关节的heatmap,关节的顺序是比较重要的。
具体的单幅图和视频所对应的Recurrent CNN模型可见下图
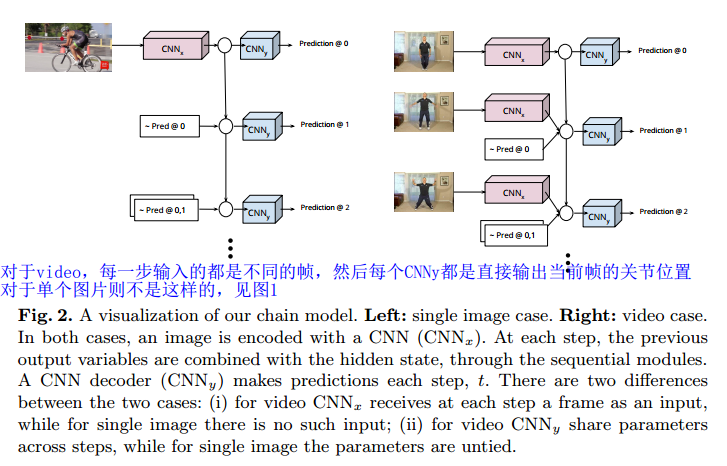
如上图左边是单幅图片使用Recurrent CNN的示意图,右边是在video上使用Recurrent CNN的示意图。
不管是对单幅图像还是video,都有编码网络和解码网络,在图中用
CNNx
和
CNNy
来表示。图中的圆圈代表隐藏单元。
核心思想
单幅图的Chain Model
假设输入图像是
X
对应的heatmap用
那么在第t步的隐藏单元可以表示为
上述公式中 ht−1 是上一阶段的隐藏单元的状态,该隐藏单元包含了从0到t-1期间的信息, e(yi) 表示第i次所预测出来的heatmap。整个公式的第一部分 wht∗ht−1 表示前几个关节所融合的隐藏特征,第二部分 ∑t−1i=0wyi,t∗e(yi)
表示前几个关节的heatmap融合的特征,这样再通过一个激活函数 σ ,激活函数可以是ReLU函数,得到当前阶段的隐藏单元的状态,然后再将该隐藏单元的状态通过一个解码网络 mt 进行解码,最后通过一个Softmax函数获得最终的heatmap。
Softmax的定义如下:
第k个关节的heatmap定义为
上述公式中的 hk(x,y) 是第k个隐藏单元在 (x,y) 位置上的状态。
对应的ground truth的定义为
在半径 r 内的Ground Truth heatmap为
超出半径的位置都为0。
那么最终的损失误差为
Video中的Chain Model
第t步的隐藏单元可以表示为
ht−1
是上一帧的隐藏单元的状态,
wht∗ht−1
表示将上一帧的隐藏单元的状态转换到当前特征空间去
e(yi)
是第i帧所预测的heatmap,而
∑t−1i=0wyi,t∗e(yi)
表示将前t帧的输出的所预测的heatmap转换到当前的特征空间去。
参数 wht,wyi,t 以及 mt 的参数若干个video之间是共享的。
本文还使用了scheduled sampling来避免Recurrent model这种sequence-to-sequence model在训练的时候所遇到的困难。
值得借鉴的地方
- 将关节按照顺序输入到Recurrent CNN中是一种解决左右关节不分这个问题的一种解决方案。
- Recurrent CNN在video上的做姿态估计的效果还是很好的。
缺点
- 这种模型,对于在单幅图像上的人的姿态估计效果一般,这从实验中也可以看出来,但是在video上的效果惊人。
- 这种模型同样不能解决遮挡问题,这个老大难的问题。
预处理
实验
数据集
MPII Human Pose dataset, which consists of about 40K instances (28K for train and 12K for validation) of people performing various actions. All frames (apart for the test set) come with a maximum of 16 annotated joints (Top Head, Neck, Right Ankle, Left Knee, etc.)
For the task of pose estimation in video we use the Penn Action dataset, which consists of 2326 video sequences (split in half for train and test) of people performing various sports. All frames come with a maximum of 13 annotated joints.
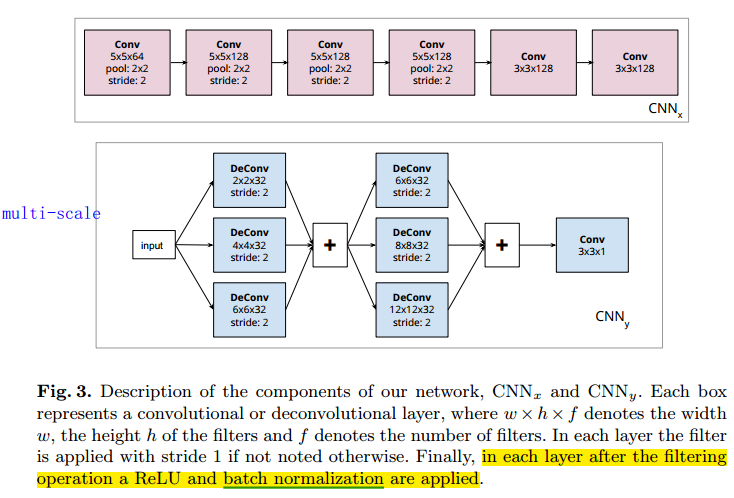
两个不同编码网络 CNNx
First, a shallow convolutional neural network which consists of 6 layers each followed by a rectified linear unit and Batch Normalization. The first 4 layers include max pooling with stride 2, thus leading to an effective stride of 16. 具体如图中的 CNNx 所示。
Second, we experiment with a deeper network of identical architecture to inception-v3. We throw away the last convolutional layer of inception-v3 and connect the output to CNNy .具体如图中的 CNNy 所示。
多尺度解码网络 CNNy
The CNNy network decodes the hidden state to a heatmap over possible locations of a single body part. This heatmap is converted to a probability distribution over locations using a softmax. The network consists of 2 towers of deconvolutional layers each of which increases the width and height of the feature maps by a factor of 2. Note the that the deconvolutional towers are multi-scale -in one layer, different filter sizes are used and combined together. This is similar to the inception model, with the difference that here it is applied with the deconvolution operation, and, thus, we call it deception. 具体如下图中的 CNNy 所示。
评价指标
If a joint prediction lies within a predefined distance from the ground truth location it is counted as a correct detection. The predefined distance is proportional to the size of the person in question, which is estimated through the person’s head size or total height. This metric is called
PCK.
实验结果比对
网络结构有效性对比
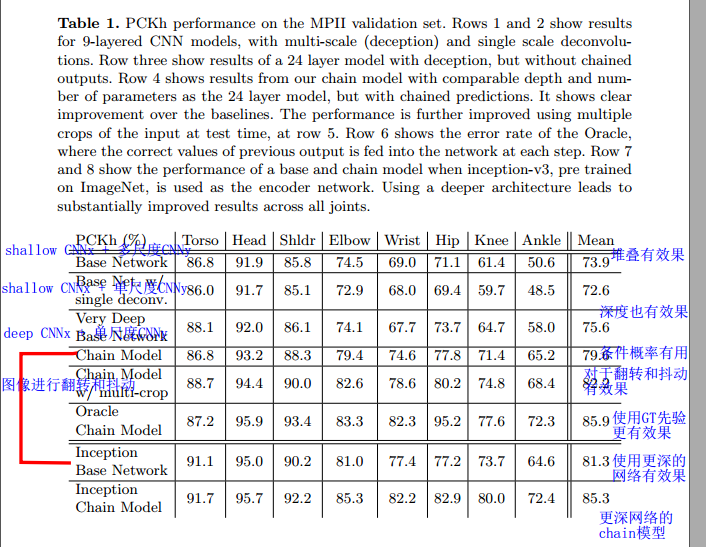
如图所示为网络结构有效性的对比。
错误模式分析
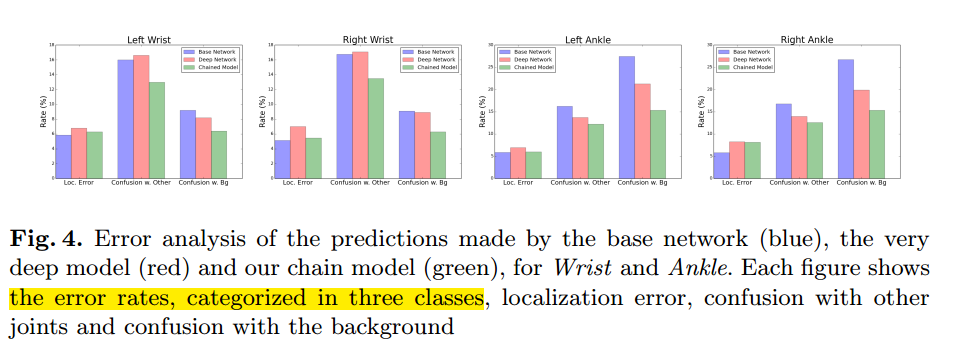
The chain model reduces the misses due to confusion with other joints and the background
For Wrists, the confusion with other joints seems to be the dominating error mode, and further analysis shows that the main source of confusion comes mainly from the opposite wrist and then the nearby joints.
For Ankles, the biggest error mode comes from confusion with the background. This is because, ankles are usually heavily occluded and lack strong appearance cues.
单幅图姿态估计对比
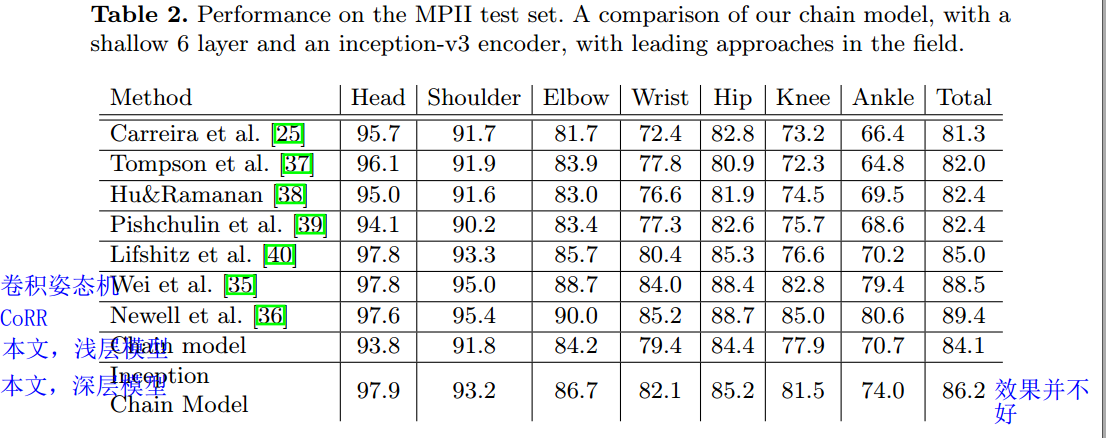
We show the performance of both versions of our chain model, with a shallow 6 layer encoder as well as the inception-v3 architecture. For the shallow chain model, we ensembled two chain models trained at different input scales. For the inception chain model, no ensembling was performed.
视频姿态估计对比
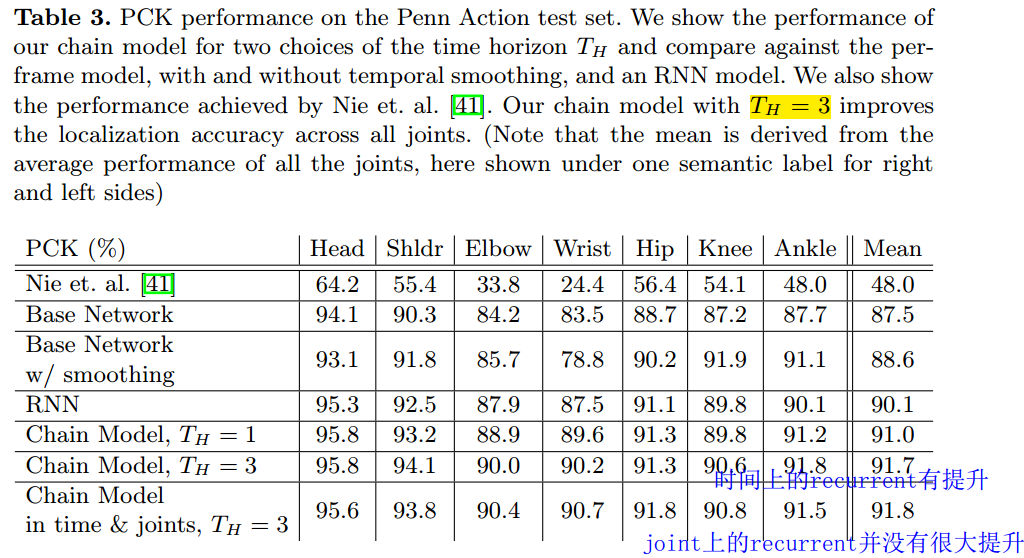
We observe a gain in performance compared to the baseline per frame CNN as well as the RNN across all joints. Interestingly, chain models improve arm prediction more than they improve on legs. This is due to the fact that people in the videos play sports which involve big arm movements, while the legs are mostly un-occluded and less kinematic. In addition, we see that TH = 3 leads to better performance, which is not surprising since the model makes a decision about the location of the joints at the current time step based on observation from 3 past frames. We did not observe gains from using a larger time horizon. Lastly, chaining in time and in joints does not seem to improve performance even further. This might be due to the already high accuracy achieved by the time chain model.
模型可以区分左右关节

点评
本文实际上提供了一种解决左右手部分的思路,此外还给出了在video上做姿态估计的一种有效的方法,即使用Recurrent CNN的效果还是挺不错的。
实际实现
通过看代码发现,其实作者并没有实现recurrent。只是单独地进行训练的。。。
没啥意思。。。。大失所望。















 2806
2806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









