







Quoted From Wiki.
Vapnik-Chervonenkis Dimension
In computational learning theory, the VC dimension (for Vapnik-Chervonenkis dimension) is a measure of the capacity of a statistical classification algorithm, defined as the cardinality of the largest set of points that the algorithm can shatter. It is a core concept in Vapnik-Chervonenkis theory, and was originally defined by Vladimir Vapnik and Alexey Chervonenkis.
Informally, the capacity of a classification model is related to how complicated it can be. For example, consider the thresholding of a high-degree polynomial: if the polynomial evaluates above zero, that point is classified as positive, otherwise as negative. A high-degree polynomial can be wiggly, so it can fit a given set of training points well. But one can expect that the classifier will make errors on other points, because it is too wiggly. Such a polynomial has a high capacity. A much simpler alternative is to threshold a linear function. This polynomial may not fit the training set well, because it has a low capacity. We make this notion of capacity more rigorous below.
Shattering
A classification model f with some parameter vector θ is said to shatter a set of data points (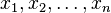 ) if, for all assignments of labels to those points, there exists a θ such that the model f makes no errors when evaluating that set of data points.
) if, for all assignments of labels to those points, there exists a θ such that the model f makes no errors when evaluating that set of data points.
VC dimension of a model f is the maximum h such that some data point set of cardinality h can be shattered by f.
For example, consider a straight line as the classification model: the model used by a perceptron. The line should separate positive data points from negative data points. When there are 3 points that are not collinear, the line can shatter them. However, the line cannot shatter four points. Thus, the VC dimension of this particular classifier is 3. It is important to remember that one can choose the arrangement of points, but then cannot change it as the labels on the points are permuted. Note, only 3 of the 8 possible permutations are shown for the 3 points.
 |  |  |  |
| 3 points shattered | 4 points impossible | ||
Uses
The VC dimension has utility in statistical learning theory, because it can predict a probabilistic upper bound on the test error of a classification model.
The bound on the test error of a classification model (on data that is drawn i.i.d. from the same distribution as the training set) is given by
-
Training error +

with probability 1 − η, where h is the VC dimension of the classification model, and N is the size of the training set (restriction: this formula is valid when the VC dimension is small h < N).
Hill Climbing
Hill climbing is an optimization technique which belongs to the family of local search. It is a relatively simple technique to implement, making it a popular first choice. Although more advanced algorithms may give better results, there are situations where hill climbing works well.
Hill climbing can be used to solve problems that have many solutions but where some solutions are better than others. The algorithm is started with a random (potentially bad) solution to the problem. It sequentially makes small changes to the solution, each time improving it a little bit. At some point the algorithm arrives at a point where it cannot see any improvement anymore, at which point the algorithm terminates. Ideally, at that point a solution is found that is close to optimal, but it is not guaranteed that hill climbing will ever come close to the optimal solution.
An example of a problem that can be solved with hill climbing is the traveling salesman problem. It is easy to find a solution that will visit all the cities, but this solution will probably be very bad compared to the optimal solution. The algorithm starts with such a solution and makes small improvements to it, such as switching the order in which two cities are visited. Eventually, a much better route is obtained.
Hill climbing is used widely in artificial intelligence fields, for reaching a goal state from a starting node. Choice of next node and starting node can be varied to give a list of related algorithms.
Mathematical description
Hill climbing attempts to maximize (or minimize) a function f(x), where x are discrete states. These states are typically represented by vertices in a graph, where edges in the graph encode nearness or similarity of a graph. Hill climbing will follow the graph from vertex to vertex, always locally increasing (or decreasing) the value of f, until a local maximum (or local minimum) xm is reached. Hill climbing can also operate on a continuous space: in that case, the algorithm is called gradient ascent (or gradient descent if the function is minimized).

Variants
In simple hill climbing, the first closer node is chosen, whereas in steepest ascent hill climbing all successors are compared and the closest to the solution is chosen. Both forms fail if there is no closer node, which may happen if there are local maxima in the search space which are not solutions. Steepest ascent hill climbing is similar to best-first search, which tries all possible extensions of the current path in order instead of only one.
Random-restart hill climbing is a meta-algorithm built on top of the hill climbing algorithm. It is also known as Shotgun hill climbing. Random-restart hill climbing simply runs an outer loop over hill-climbing, where each step of the outer loop chooses a random initial condition x0 to start hill climbing. The best xm is kept: if a new run of hill climbing produces a better xm than the stored state, it replaces the stored state.
Random-restart hill climbing is a surprisingly effective algorithm in many cases. It turns out that it is often better to spend CPU time exploring the space, rather than carefully optimizing from an initial condition
Problems
Local maxima
A problem with hill climbing is that it will find only local maxima. Unless the heuristic is convex, it will not necessarily reach a global maximum. Other local search algorithms try to overcome this problem such as stochastic hill climbing, random walks and simulated annealing.This problem of hill climbing can be solved by using random hill climbing search technique

Ridges
A ridge is a curve in the search place that leads to a maximum, but the orientation of the ridge compared to the available moves that are used to climb is such that each moves will lead to a smaller point. In other words, each point on a ridge looks to the algorithm like a local maximum, even though the point is part of a curve leading to a better optimum.
Plateau
Another problem with hill climbing is that of a plateau, which occurs when we get to a "flat" part of the search space, i.e. we have a path where the heuristics are all very close together. This kind of flatness can cause the algorithm to cease progress and wander aimlessly.
Pseudocode
Hill Climbing Algorithm
currentNode = startNode;
loop do
L = NEIGHBORS(currentNode);
nextEval = -INF;
nextNode = NULL;
for all x in L
if (EVAL(x) > nextEval)
nextNode = x;
nextEval = EVAL(x);
if nextEval <= EVAL(currentNode)
//Return current node since no better neighbors exist
return currentNode;
currentNode = nextNode;















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









