






#programmer & copyright: xlxlqqq
#data: 2023-12-15
简介
“Winner Takes All” (WTA) 深度学习策略是一种用于神经网络和模型训练的方法,其主要目标是选择网络中具有最大活跃度或激活的单元,使其成为"赢家",并抑制其他单元。这个策略在不同的领域和应用中都有其独特的用途。
提出和发展历史
WTA策略的概念起源于生物学对于神经元工作方式的观察。在神经系统中,激活最强的神经元通常会抑制其他神经元,以实现信息的选择性传递。在深度学习中,WTA策略被引入以模拟这种生物学现象。
随着神经网络的发展,WTA策略逐渐成为一种增强模型鲁棒性和提高分类性能的手段。该策略的使用不仅限于监督学习,还包括无监督学习和强化学习等不同领域。
常见应用
特征选择和学习:WTA策略可以用于选择网络中最重要的特征或表示,从而提高模型的效率和泛化性能。
竞争型学习:WTA策略常用于竞争型学习场景,其中神经元之间相互竞争,以学习并表示输入数据中的模式。
稀疏编码:WTA策略有助于生成稀疏的表示,这在处理高维数据时非常有用,可以减少存储和计算成本。
图像分割:在计算机视觉领域,WTA策略可用于图像分割,其中网络学会将图像中的不同区域分配给不同的神经元。
自组织映射:WTA策略常用于自组织映射(Self-Organizing Maps, SOMs)等无监督学习方法中,以实现对输入数据的聚类和映射。
强化学习:在强化学习中,WTA策略可以用于选择动作或决策,以应对不同环境的变化。
总体而言,WTA策略通过在神经网络中引入竞争性的元素,可以使模型更加灵活,适应不同的输入模式,并在某些任务中表现出更强的鲁棒性。
工作原理
假设我们现在面临这样一个问题,将N个输入,分别记录为 P i P_i Pi,按照一定规则划分为K类。这不是一个典型的分类问题(Classification Problem),而是一个区域聚类问题。在深度学习领域,聚类问题类似于非监督学习问题,即在未知分类规则和分类结果的情况下,对输入进行分类。
为了解决这个k聚类问题,我们作以下分析。在前向传播的过程中,有N个输入(输入可以是任意维度),每个输入经过神经元 w j w_j wj运算后,会得到不同的输出值,该输出是由神经元超参数 w j w_j wj所单一决定的。采用WTA策略,就是要在不断循环迭代的过程中,不断更新 w j w_j wj,最终 W = [ w 1 , w 2 , . . . , w k ] W = [w_1, w_2, ... , w_k] W=[w1,w2,...,wk]就代表了训练的结果。最后训练得到的权重参数 W W W可以作为分类的最终依据。
对于WTA策略在区域聚类问题中的应用,主流解释均使用圆形的单位圆进行解释,在此笔者为了让读者更为便捷地理解WTA策略,将该策略在单位圆内的工作流程制作为一个动图:
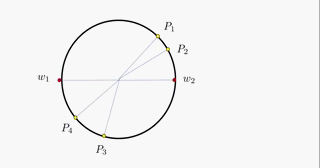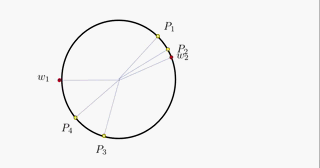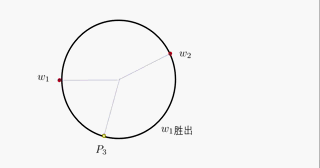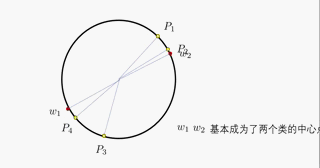
可以看到,第 i i i个点均对 k k k类参考点进行距离运算,取距离较近地那个参考点,同时将这个参考点向第 i i i个点稍微靠近一点,这个点将会作为第 i i i个点的(临时)聚类中心而存在。在一个批次的循环中,对每一个这样的输入点均进行同样的操作,这样,迭代的结果就是: k k k个参考点作为 k k k个聚类的聚类中心,即实现了对 N N N个输入进行 k k k聚类的操作。
当然,在神经网络领域,使用以上的单位圆进行原理解释是不优雅的,在深度学习中,WTA策略通常单独作为一个竞争策略层出现,因此,我们将WTA抽象为神经元模型,进行再一次地解释:同样假设面临一个二分类问题,同样是分类规则未知,WTA的网络模型如下:
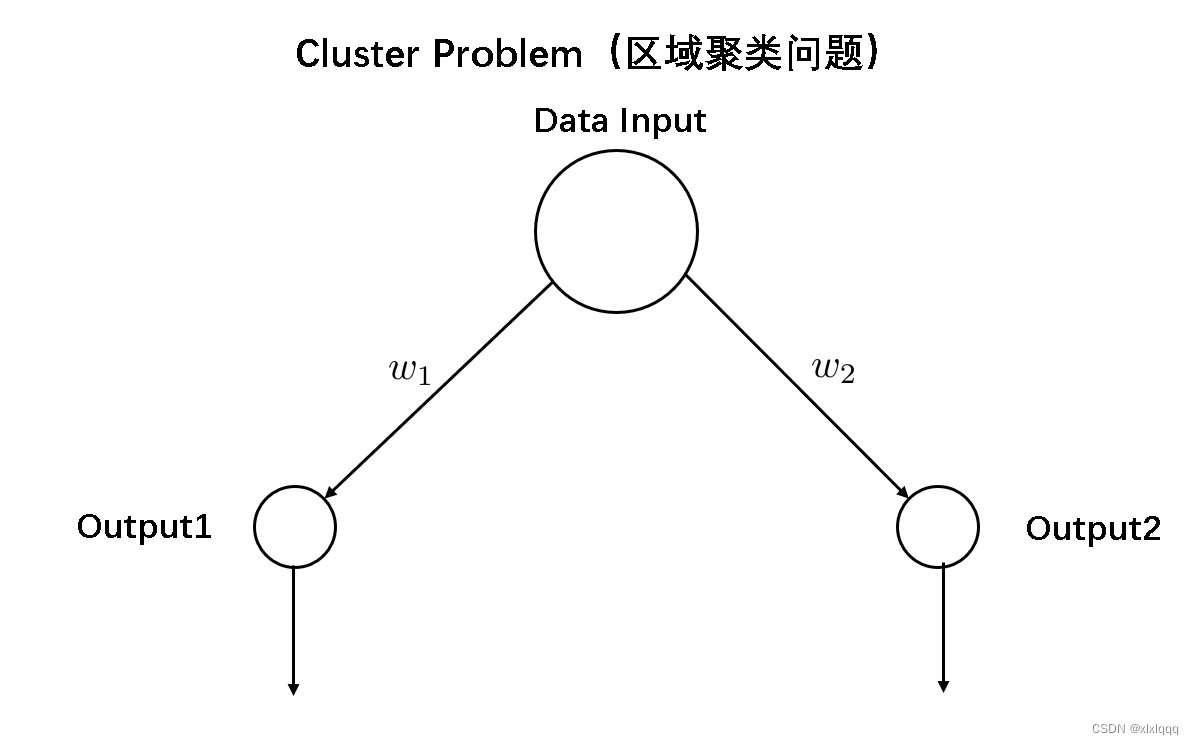
在每一次迭代的过程中,每一个输入均会经过所有神经元的运算,每个神经元会得到一个输出值。输入-输出的运算关系也许会很简单,也许会很难,在简单的区域聚类问题中,这个运算通常就是计算输入点和参考点的欧氏距离(二范数)。当第i个输入经过第 j j j个神经元得到的距离比较相近的时候,对第 j j j个神经元进行参数迭代(由于这个神经元只有 w w w参数,因此只对 w w w进行更新)
代码
使用WTA必然是要有一定应用场景的,笔者在此使用matlab对30个二维点进行2聚类,代码如下:
% programmer: xlxlqqq
% date: 2023-12-15
% function: distinct data with WTA principle
% github.com/xlxlqqq/
clear;
clc;
close all;
%%
x = [4.1, 1.8, 0.5, 2.9, 4.0, 0.6, ...
3.8,4.3,3.2,1.0,3.0,3.6, ...
3.8,3.7,3.7,8.6,9.1,7.5, ...
8.1,9.0,6.9,8.6,8.5,9.6, ...
10.0,9.3,6.9,6.4,6.7,8.7];
y = [8.1,5.8,8.0,5.2,7.1,7.3, ...
8.1,6.0,7.2,8.3,7.4,7.8, ...
7.0,6.4,8.0,3.5,2.9,3.8, ...
3.9,2.6,4.0,2.9,3.2,4.9, ...
3.5,3.3,5.5,5.0,4.4,4.3];
%%
normalizedInput = zeros(2, 30);
normalizedAngle = zeros(1, 30);
normalizedRadian = zeros(1, 30);
firstClass = zeros(1, 30);
secondClass = zeros(1, 30);
weight1 = 0;
weight2 = 90;
%%
for i = 1: 30
lengthofLine = sqrt(x(i) * x(i) + y(i) * y(i));
normalizedInput(1, i) = x(i) / lengthofLine;
normalizedInput(2, i) = y(i) / lengthofLine;
normalizedRadian(i) = atan(y(i) / x(i));
normalizedAngle(i) = normalizedRadian(i) * 180 / pi;
end
%%
for i = 1: 20
for j = 1: 30
point = [normalizedInput(1, j), normalizedInput(2, j)];
distanceFirst = normalizedAngle(j) - weight1;
distanceSecond = normalizedAngle(j) - weight2;
err = 0.1 * pi * min(abs(distanceFirst), abs(distanceSecond));
if min(abs(distanceFirst), abs(distanceSecond)) == abs(distanceFirst)
weight1 = weight1 + distanceFirst;
firstClass(j) = j;
else
weight2 = weight2 + distanceSecond;
secondClass(j) = j;
end
end
end
%% def functions
function output = getEulerDis(pointOne, pointTwo)
if length(pointOne) ~= 2 || length(pointTwo) ~= 2
error('Error input!!!');
end
x = pointOne(1) - pointTwo(1);
y = pointOne(2) - pointTwo(2);
output = sqrt(x * x + y * y);
end
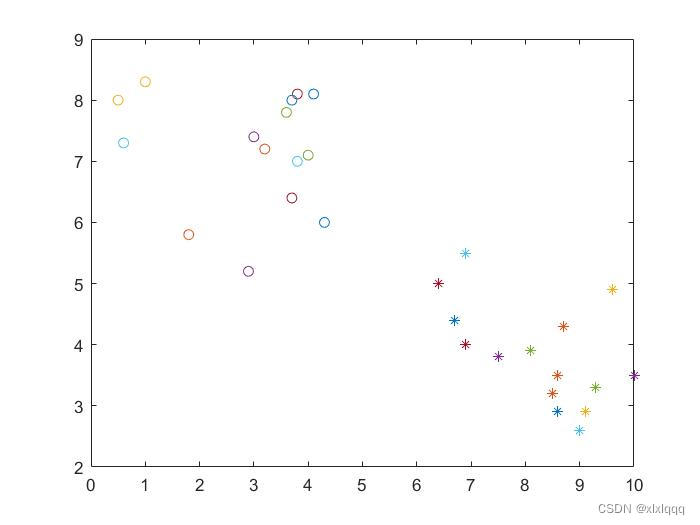
以上代码即可对30个二维点进行二分类(聚类求解),求解的结果即存放在firstClass和secondClass中,可以进一步进行查看,最终,标号为1-15的点属于第一类,标号为16-30的点属于第二类。使用matlab进行绘制可得到如下结果:
如果你有更好的想法,可以尝试联系xlxlqqq@163.com

















 2434
2434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









