







模型搭建和评估--建模
完成泰坦尼克号存活预测这个任务
模型搭建
- 处理完前面的数据我们就得到建模数据,下一步是选择合适模型
- 在进行模型选择之前我们需要先知道数据集最终是进行监督学习还是无监督学习
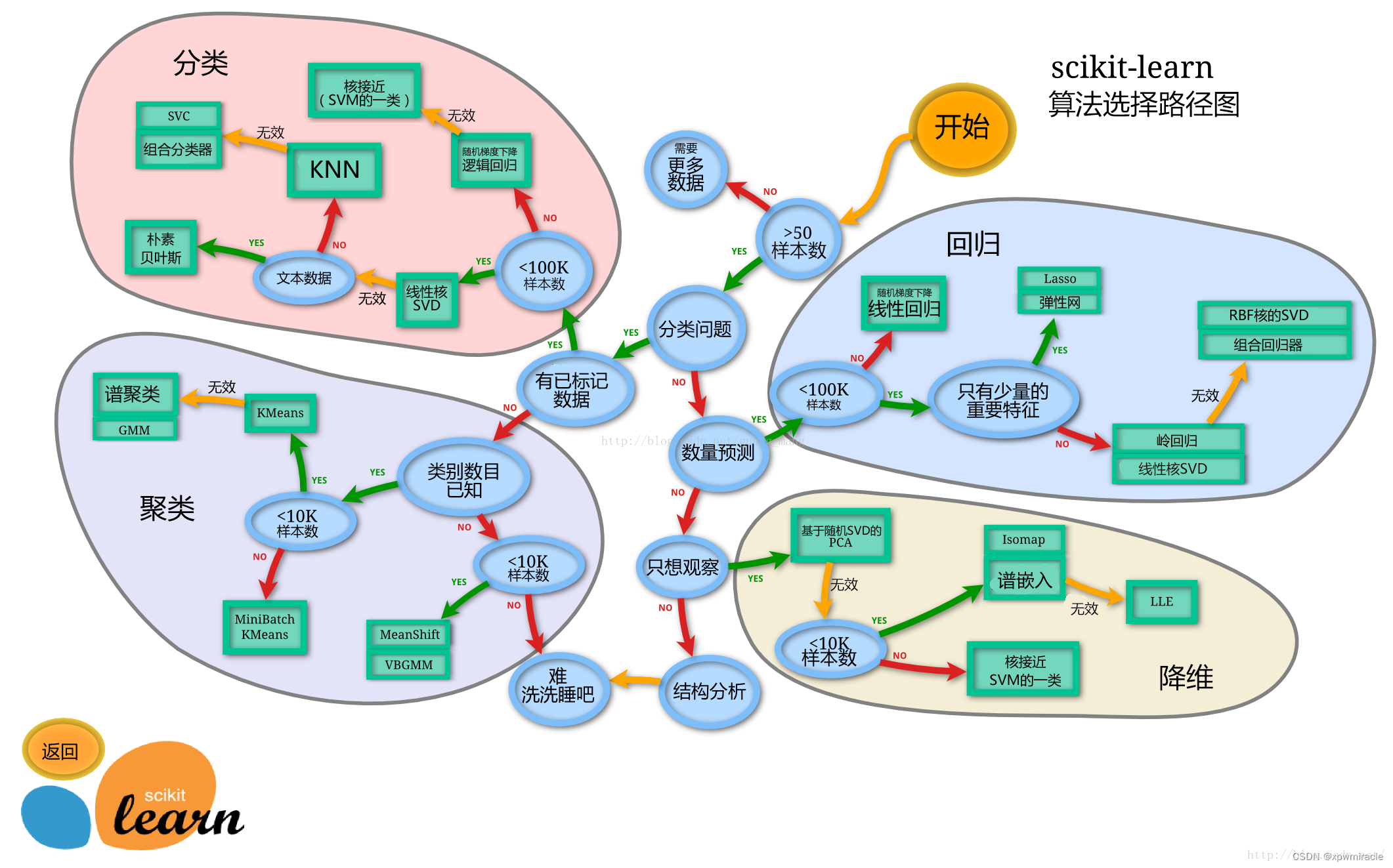
- 模型的选择一方面是通过我们的任务来决定的。
- 除了根据我们任务来选择模型外,还可以根据数据样本量以及特征的稀疏性来决定
- 刚开始先尝试使用一个基本的模型来作为其baseline,进而再训练其他模型做对比,最终选择泛化能力或性能比较好的模型
sklearn库完成模型的搭建
任务一:切割训练集和测试集
对于数据集的划分有三种方法:留出法、交叉验证法和自助法。
留出法
留出法直接将数据集D划分为两个互斥的部分,其中一部分作为训练集S,另一部分用作测试集T。
通常训练集和测试集的比例为70%:30%。同时,训练集测试集的划分有两个注意事项:
1. 尽可能保持数据分布的一致性。避免因数据划分过程引入的额外偏差而对最终结果产生影响。在分类任务中,保留类别比例的采样方法称为“分层采样”(stratified sampling)。
2. 采用若干次随机划分避免单次使用留出法的不稳定性。
k 折交叉验证
通常将数据集 D 分为 k 份,其中的 k-1 份作为训练集,剩余的那一份作为测试集,这样就可以获得 k 组训练/测试集,可以进行 k 次训练与测试,最终返回的是 k 个测试结果的均值。
这里数据集的划分依然是依据 分层采样 的方式来进行。
对于交叉验证法,其 k 值的选取往往决定了评估结果的稳定性和保真性,通常 k 值选取 10。
与留出法类似,通常我们会进行多次划分得到多个 k 折交叉验证,最终的评估结果是这多次交叉验证的平均值。
当 k=1的时候,我们称之为留一法。
自助法
留出法与交叉验证法都是使用 分层采样 的方式进行数据采样与划分,而自助法则是使用有放回重复采样的方式进行数据采样。
每次从数据集D中取一个样本作为训练集中的元素,然后把该样本放回,重复该行为 m 次,这样我们就可以得到大小为m的训练集,在这里面有的样本重复出现,有的样本则没有出现过,我们把那些没有出现过的样本作为测试集。
进行这样采样的原因是因为在D中约有 36.8% 的数据没有在训练集中出现过(取极限后求得)。
这种方法对于那些数据集小、难以有效划分训练/测试集时很有用,但是由于该方法改变了数据的初始分布导致会引入估计偏差。
分层采样:保留类别比例的采样方式
先将总体的单位按某种特征分为若干次级总体(层),然后再从每一层内进行单纯随机抽样,组成一个样本。分层可以提高总体指标估计值的精确度,它可以将一个内部变异很大的总体分成一些内部变异较小的层(次总体)。
分层抽样比单纯随机抽样所得到的结果准确性更高,组织管理更方便,而且它能保证总体中每一层都有个体被抽到。这样除了能估计总体的参数值,还可以分别估计各个层内的情况,因此分层抽样技术常被采用。
一、导入库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from IPyt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









