







自定义损失函数
PyTorch在torch.nn模块为我们提供了许多常用的损失函数,比如:MSELoss,L1Loss,BCELoss......
但有些损失函数实现则需要我们通过自定义损失函数来实现。另外,在科学研究中,我们往往会提出全新的损失函数来提升模型的表现,这时我们既无法使用PyTorch自带的损失函数,也没有相关的博客供参考,此时自己实现损失函数就显得更为重要了。
以函数方式定义
以通过直接以函数定义的方式定义一个自己的函数,如下所示:
def my_loss(output, target):
loss = torch.mean((output - target)**2)
return loss以类方式定义

在下面的例子中我们以DiceLoss为例向大家讲述。
Dice Loss是一种在分割领域常见的损失函数,损失函数——Dice Loss - 知乎
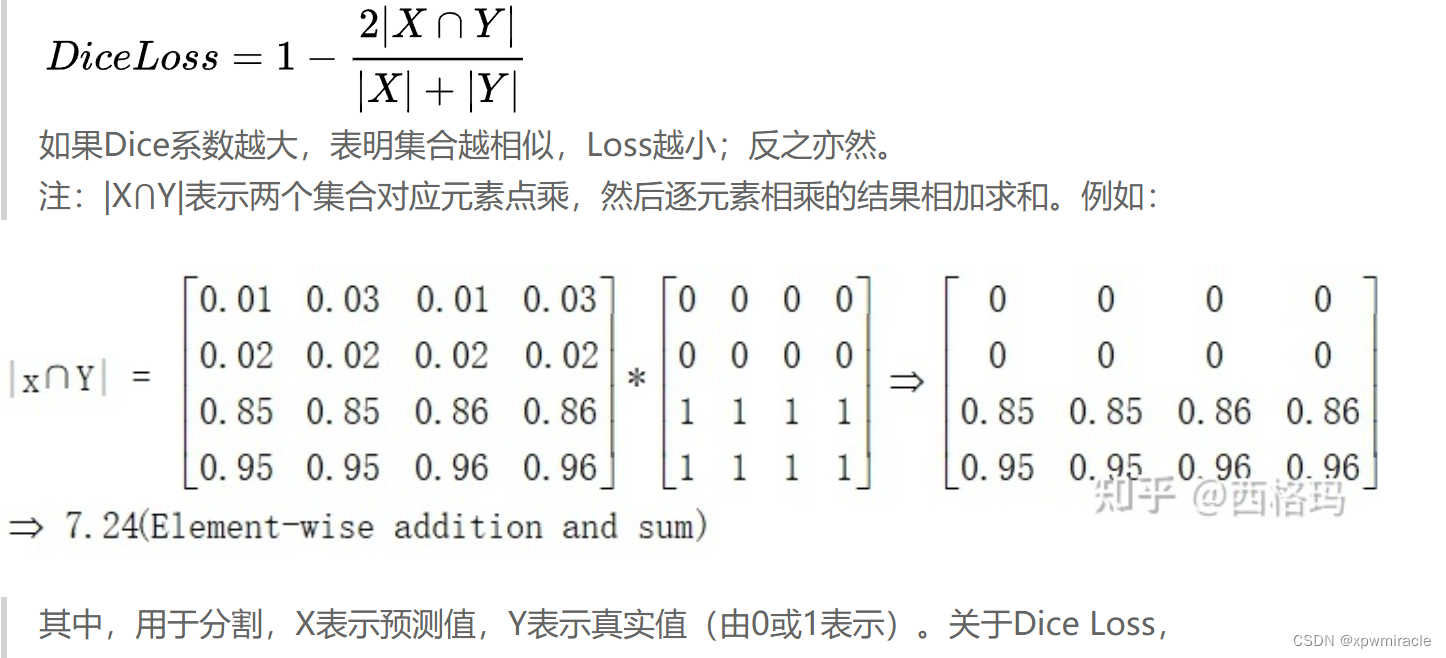
如果Dice系数越大,表明集合越相似,Loss越小;反之亦然。
注:|X⋂Y|表示两个集合对应元素点乘,然后逐元素相乘的结果相加求和。例如:实现代码如下:
class DiceLoss(nn.Module):
def __init__(self,weight=None,size_average=True):
super(DiceLoss,self).__init__()
def forward(self,inputs,targets,smooth=1):# 加上smooth是为了防止分母为0,改善过拟合
inputs = F.sigmoid(inputs)
# 将输入和输出转化为一维:
inputs = inputs.view(-1) # |X|
targets = targets.view(-1) # |Y|
intersection = (inputs * targets).sum() # |X⋂Y|
dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
return 1 - dice
# 使用方法
criterion = DiceLoss()
loss = criterion(input,targets) 


class DiceBCELoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceBCELoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice_loss = 1 - (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth)
BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')
Dice_BCE = BCE + dice_loss
return Dice_BCE
--------------------------------------------------------------------
class IoULoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(IoULoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
inputs = F.sigmoid(inputs)
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
total = (inputs + targets).sum()
union = total - intersection
IoU = (intersection + smooth)/(union + smooth)
return 1 - IoU
--------------------------------------------------------------------
ALPHA = 0.8
GAMMA = 2
class FocalLoss(nn.Module):
#https://zhuanlan.zhihu.com/p/75542467
def __init__(self, weight=None, size_average=True):
super(FocalLoss, self).__init__()
def forward(self, inputs, targets, alpha=ALPHA, gamma=GAMMA, smooth=1):
# alpha 进行设置(该参数用于调整正负样本数量不均衡带来的问题)
#comment out if your model contains a sigmoid or equivalent activation layer
inputs = F.sigmoid(inputs)
#flatten label and prediction tensors
inputs = inputs.view(-1)
targets = targets.view(-1)
#first compute binary cross-entropy
BCE = F.binary_cross_entropy(inputs, targets, reduction='mean')
BCE_EXP = torch.exp(-BCE)
focal_loss = alpha * (1-BCE_EXP)**gamma * BCE
return focal_loss在自定义损失函数时,涉及到数学运算时,我们最好全程使用PyTorch提供的张量计算接口,这样就不需要我们实现自动求导功能并且我们可以直接调用cuda,使用numpy或者scipy的数学运算时,操作会有些麻烦。
参考:
【1】https://www.kaggle.com/bigironsphere/loss-function-library-keras-pytorch/notebook
【2】https://www.zhihu.com/question/66988664/answer/247952270
【3】https://blog.csdn.net/dss_dssssd/article/details/84103834
【4】https://zj-image-processing.readthedocs.io/zh_CN/latest/pytorch/%E8%87%AA%E5%AE%9A%E4%B9%89%E6%8D%9F%E5%A4%B1%E5%87%BD%E6%95%B0/
【5】https://blog.csdn.net/qq_27825451/article/details/95165265
【6】https://discuss.pytorch.org/t/should-i-define-my-custom-loss-function-as-a-class/89468
动态调整学习率

在训练神经网络的过程中,学习率是最重
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









