







本文主要通过一个爬虫实例来对scrapy的整个框架的开发流程,scrapy框架的整体运行机制有个比较清晰的认识,以便于下面进一步学习。
我将通过一个论坛的版面抓取帖子的作者的昵称和头像信息,并通过mysql存储,如下图所示。
1.开发环境介绍:
- win32(操作系统环境)
- python 3.4.2
- pycharm(pythonIDE,python的代码提示功能相对不强)
- scrapy 1.1(目前下载的是最新版本的scrapy)
- mysql 5.5.6(本实例使用mysql作为存储)
2.爬虫环境搭建(针对win32+py3.4,其他版本适当参考):
(1)安装py 3.4.2,配置环境变量(过程略),当在命令行下执行python,出现python版本的时候,说明安装配置成功。
(2)scrapy,最新版本的py3.4里面自带了pip以及easy_install等下载python模块的工具包,所以下载scrapy.只需要执行pip install scrapy,即可等待其完成安装,在python环境中通过import scrapy命令测试scrapy是否安装成功。
(3)在命令行下通过执行scrapy startproject projectname来创建一个scrapy project.
(4)常见问题:
py3.4+win32+scrapy 1.1安装完成后,测试第一个demo时出现了类似import error _win32stdio的错误。这个错误可以通过从github上下载_win32stdio.py以及_pollingfile.py这2个文件并将其移动到twisted/internet目录下即可。
3.开发流程
开发流程按照官方文档的介绍来说一般分为五部分。
—-创建scrapy项目,搭建IDE环境(为了加快变成效率)
—-抓取目标定位(fetch item)
—-定制爬虫(customize spider)
—-数据存储(pipeline data process)
—-爬虫配置Ian
(1)创建scrapy项目:
首先进入一个s存放crapy代码的目录,在该目录下执行scrapy startproject fetchForum 命令会创建一个scrapy项目,目录结构如下图:
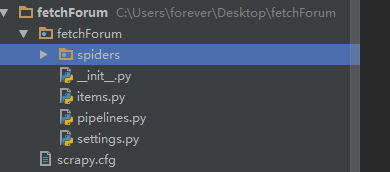
fetchForum:项目名
pipeline:定义数据管道,对scrapy数据进行加工处理。
items:用来定义需要抓取的数据结构
spiders:用来编写爬虫代码的目录
settings:爬虫配置文件
(2)定义item数据结构:
class FetchforumItem(scrapy.Item):
"""#define the fields for your item here like:
"""user_img = scrapy.Field()
"""user_name = scrapy.Field()(3)定制scrapy爬虫
定制爬虫主要是通过重写spider或者crawlspider,我们阅读官方文档,我们选择使用spider.Spider来实现。
#encoding=utf8
import scrapy
from scrapy.http.request import Request
from fetchForum.items import FetchforumItem
class ForumSpider(scrapy.Spider):
name = "forum"
allowed_domains = ["forum.home.news.cn"]
start_urls = [
"http://forum.home.news.cn/list/50-133-0-31.html",
]
def parse(self, response):
topiclist=response.xpath('//dt[@class="clear"]')
tieziurl=""
#if the article is deleted then ignore it
if len(topiclist)!=0:
for topic in topiclist:
try :
tieziurl="http://forum.home.news.cn"+str(topic.xpath('./a[@class="bt"]/@href')[0].extract())
yield Request(tieziurl, callback=self.parse_topic)
except Exception as e:
print("analyse the topic error")
print(e)
# xpath look for the elements at the begining of one not the zero
next_url="http://forum.home.news.cn"+response.xpath('//div[@class="lt-page clear"]/ul[@class="fl"][1]/li[3]/span[1]/a[1]/@href')[0].extract()
print("----------next_url--->>%s" %next_url)
yield Request(next_url,callback=self.parse)
def parse_topic(self,response):
#如果该帖子没有被删除,则进行解析帖子
if response.xpath("//title/text()")[0].extract().find("出错")==-1:
userinfo = FetchforumItem()
print("collecting the user data")
user_img="".join(response.xpath('//ul[@class="de-xx clear"]/li/a/img/@src').extract()).strip()
user_name="".join(response.xpath('//ul[@class="de-xx clear"]/li')[1].xpath("./a/text()").extract()).strip()
# print("---------")
# print(type(user_img))
# print(user_name)
# print("---------------")
userinfo['user_img']=user_img
userinfo['user_name']=user_name
return userinfo
#print("name:%s img %s" %(user_name,user_img) )关于spider的一些疑问可以通过官方文档来解决(比如name、start_urls是干嘛用的,是不是必须要写等问题,)这涉及到爬虫设计的规范问题,这些是强制的。
(4)实现pipeline
pipeline主要是对item进行加工操作,常见操作如存储,数据分析等。
#encoding=utf8
import pymysql
from scrapy.exceptions import DropItem
class FetchforumPipeline(object):
def __init__(self,host,user,passwd,db):
self.host=host
self.user=user
self.db=db
self.passwd=passwd
self.imgset=[]
self.img_count=0
@classmethod
def from_crawler(cls,crawler):
return cls(host=crawler.settings.get('MYSQL_HOST'),
user=crawler.settings.get('MYSQL_USER'),
passwd=crawler.settings.get("MYSQL_PASSWD"),
db=crawler.settings.get("MYSQL_DBNAME")
)
def open_spider(self,spider):
try:
self.con=pymysql.connect(host=self.host,user=self.user,passwd=self.passwd,db=self.db,charset='utf8')
print("数据库连接成功建立")
except Exception as e:
print("数据库连接失败")
print(e)
def close_spider(self,spider):
self.con.close()
def process_item(self,item,spider):
#不重复存储图片,用户头像地址就是通过用户名来唯一标识地址
#形如http://tpic.home.news.cn/userIcon/s/cocoo0921
validate_img=item['user_img'].split('/')[-1]
if validate_img in self.imgset:
raise DropItem("Duplicate item found: %s" % item)
else:
self.imgset.append(validate_img)
mycuror =self.con.cursor()
try:
mycuror.execute("""
INSERT INTO forum(f_name,f_head)
VALUES
('%s','%s')
""" %(item['user_name'],item['user_img']))
self.img_count+=1
#每隔200个数据提交一次,提高效率
if self.img_count>=200:
self.con.commit()
except Exception as e:
print("insert error")
print(e)
pass
finally:
mycuror.close()
return item这里出现中文导入mysql库中出现中文乱码问题,要想解决这类问题,需要将数据库的字符集设置统一,我就是因为在创建数据库时,没有使用utf8,而且db server、db client、db connnection等没有设置统一,如果出现这类问题,我推荐http://www.jb51.net/article/38122.htm、
http://www.sootoo.com/content/329439.shtml这2篇博客就可以解决问题。还有一个问题,是py3.x系列不支持mysqldb,所以我用pip下载的是pymysql工具来连接数据库。
(5)环境配置:
# -*- coding: utf-8 -*-
# Scrapy settings for fetchForum project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'fetchForum'
SPIDER_MODULES = ['fetchForum.spiders']
NEWSPIDER_MODULE = 'fetchForum.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'fetchForum (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
**DOWNLOAD_DELAY = 3**
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
#start MYSQL database configure setting
MYSQL_HOST='localhost'
MYSQL_USER='root'
MYSQL_PASSWD='xxxxxxx'
MYSQL_PORT='3306'
MYSQL_DBNAME='mytest'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0. 8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.99 Safari/537.36 LBBROWSER',
}
TEM_PIPELINES = {
'fetchForum.pipelines.FetchforumPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'三.测试
我们将发表文章的作者的昵称以及头像地址存储到mysql中,我们通过查看mysql中forum表来测试是否爬虫抓取成功,并且我们在pipeline中已经做了去重处理.
1.查看抓取的作者数:
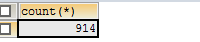
哎,不对啊,明明有那么多页,为什么只有这么少作者,原因有二,一是有作者发表了不止一篇文章,而是那个版块实际只有40多页。所以才会只抓取这么少数据。
2.查看抓取作者和头像地址
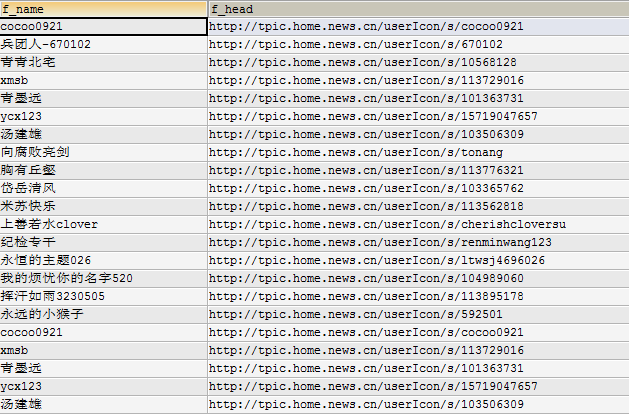
大功告成!
四.总结和感悟
学习scrapy框架只要结合一个小案例和官方文档基本能满足部分需求,另外一些比如抓取动态页面,如何应对爬虫等复杂场景,我们需要在平时慢慢积累,再看看大牛的文章,基本也能做出来一些了。















 1502
1502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









