







写Python2的人,很多人都见过下面这行Error
Traceback (most recent call last):
File "/Users/Jack/Documents/ApricotForestDoc/2_product_rnd/redspiderlily/mailfetcher.py", line 35, in <module>
if is_reply_mail(subject):
File "/Users/Jack/Documents/ApricotForestDoc/2_product_rnd/redspiderlily/module/mailutil.py", line 46, in is_reply_mail
return ("回复" in subject_.lower()) or ("re:" in subject_.lower())
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)上一次聊到Python3升级的一个重头就是unicode编码。所以这次想重点就聊两句字符编码。说实话就是在此之前自己也有些算不清楚。所以还是深入的跑到wiki上研究了一番,分享供参考。
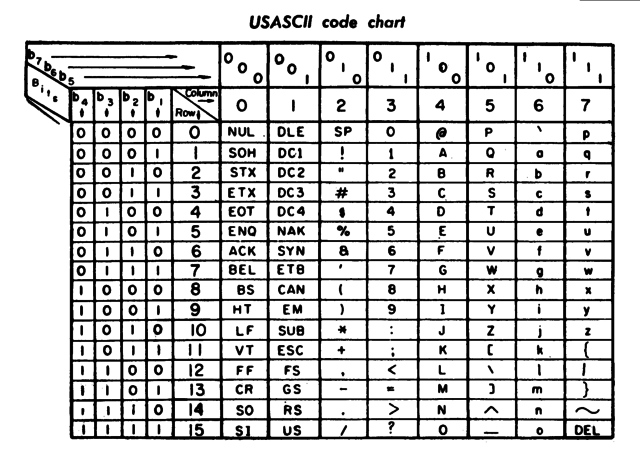
ASCII,全称American Standard Code for Information Interchange,是一个字符编码标准。使用0-127(2^7)的数字代表不同的英文字符,这里包括大小写字母,空格,特殊字符等。这是一个大家都比较熟悉的字符集标准,可以看看下面图中的内容。这里不做赘述。
但是,ASCII因为标准内含有的有限,带有音标的字符‘é’就无法很好的表述,更别提汉字了。到了1980年代,计算机技术发展,那时候大家已经开始使用字节(byte)来作为计算机基本计数单位。1byte=8bit(2^8=256),所以可以表述的字符变多了。那个时候开始出现了实用128-255这些数字表示发音单词。所以直到今天,你去看word里面的字符表,Latin依然可以看到这个顺序关系,大体就是这个原因。
再之后,当世界各地的语言发展出了各自不同的字符集体系,比如中国简体(GBK,GB18030),中文繁体(Big5,以前有个特别扯的名字叫做大五码),法语(Latin1),日语等等。本来各种语言字符集各自写互不干扰,倒也相安无事。但是,世界大融合嘛,于是问题来了。有人需要在中文里写上一段日语,就像这样 ++“日本語にほんご”++ 。于是问题就来了,怎么才能在同一个文件里现实不同的字符集的字符内容呢?1980年,人来开始尝试解决这个问题,并制定了一个新的计算机工业标准用以规范的处理、表示和编码全世界主要文字。这个标准叫做Unicode(全称是The Unicode Standard)。目前,Unicode标准是8.0,已经包含了全世界已经有超过12万个字符,覆盖129种现代和历史上的语言种类。在这里面需要说明一个额外的概念叫做Universal Coded Character Set (UCS,也叫做ISO 10646)。按照Wiki对于Unicode和UCS的说法,目前两套字符集应该是完全相同的。同一个数字在两个字符集里所代表的字符应该是相同的。但是Unicode的外延要多一些。USC仅仅是一个字符集,而对应的Unicode同时还规范了校对、标准化、表示顺序的算法等。就如同本文提及对Unicode的定义一样,Unicode出来包括了字符集,还有表现和处理方法的部分。因此Unicode应该说是一个更加广泛含义上的标准。
理论上说,Unicode字符集或者UCS有110万字符点数可以被分配,目前时机分配成16个Plane,其中Plane0,被叫做BMP(Basic Multilingual Plane),一共65536个,其中绝大部分是中文(Chinese),日文(Japanese)和韩文(Korean),三者合称CJK。
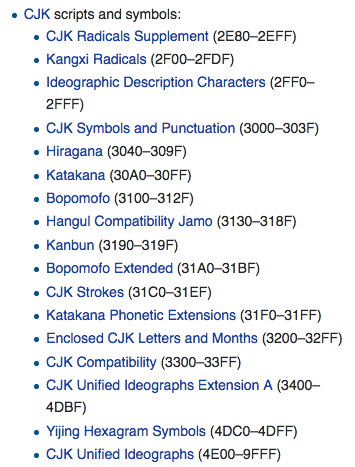
这里需要特别提一下Chinese Simplified(GBK,GB18030),自从2000年以后,中国政府规定,所有在中国售卖的软件产品必须支持Chinese Simplified(GB18030)字符集。因此在我国,就出现了一个神奇的事情,就是Unicode和Chinese Simplified双字符集并行的问题。
有趣的是,笔者大概调研了几大中文网站的编码如下:
| URI | 字符编码 |
|---|---|
| https://www.taobao.com/ | Unicode(UTF-8) |
| http://www.jd.com/ | Chinese Simplified (GBK) |
| http://bj.meituan.com/ | Unicode(UTF-8) |
| https://www.baidu.com/ | Unicode(UTF-8) |
| http://cn.bing.com/ | Unicode(UTF-8) |
| http://www.sohu.com/ | Chinese Simplified (GBK) |
| http://qq.com/ | Chinese Simplified (GBK) |
| http://www.sina.com.cn/ | Unicode(UTF-8) |
感觉上各个大厂也是自说自话,不是不是很一致要遵守政府规定或者不遵守规定。这么说来,国家对这块儿在申请xxx备案的管理也不是很严格。
话有点扯远了,咱们再回来。目前Unicode字符集共设定16个Plane(数字从0x000000-0x10FFFF)对应(2^16+2^20)对应(1,114,112)。刚刚说的Plane0,基础语言集定义是从0x000000-0x00FFFF(2^16)。其他的大家可以查,Plane1和2用了一些,其他基本上用的很少。因此总共来说目前分配的字符大约是12万。
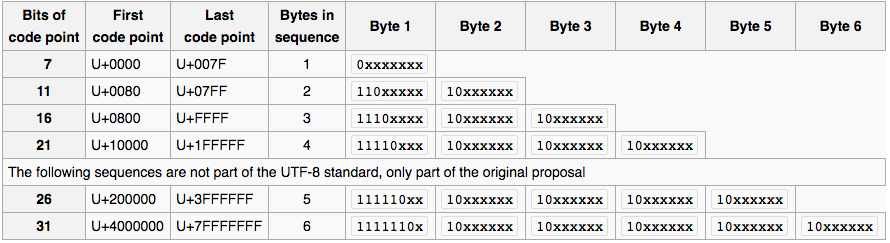
但是这样庞大的数字和计算机的比特(byte)之间并不统一,把一个Unicode字符串转换成Byte的过程,这里引入了一个叫做Encoding,编码的概念。1992年,为了兼容不同处理器和C语言,人们引入了一个编码标准,这就是大家广泛知道的UTF-8。截至2016年5月份,在WWW上的统计,UTF-8的使用率已经达到86.9%,对比GB2312(0.8%)。同时W3C也把UTF-8作为XML和HTML的推荐编码。
下面我们来阐述一下UTF-8的实现原理(同时可以结合下图来看):
如果是7位以内表述的字符表数字,就只占用一个自己,表现为(0xxxxxxx),这样刚好和ASCII码的描述相一致,这样就不会造成原有ASCII的识别错乱,特别是针对C语言的strlen()和strcopy()。从第8位,也就是十位数的256开始,采用两字节表述模式(110xxxxx 10xxxxxx),最多可以表示11个bit位,也就是2^8(256)到2^12-1(4095)。以此类推。是不是一种很有趣的编码模式 :)
下面看一个栗子。以杏树林的“杏”字为题
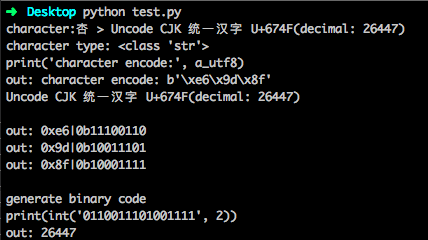
所以总结一下,Unicode和ASCII是一个字符集的概念,他们是随着电信发展而产生的编码本。只不过Unicode有多包涵了表示和处理部分,范围会更广泛。为了让计算机能读懂编码,适应计算机的计算,我们有了诸如UTF-8类的编码方法。
值得参考的一系列词条出处
https://docs.python.org/3/howto/unicode.html
https://en.wikipedia.org/wiki/Character_encoding
https://en.wikipedia.org/wiki/Unicode
https://en.wikipedia.org/wiki/Universal_Coded_Character_Set
https://en.wikipedia.org/wiki/Plane_(Unicode)#Basic_Multilingual_Plane
https://en.wikipedia.org/wiki/UTF-8
杏树林研发 王哲















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









