









北京大学慕课:Tensorflow笔记 9.1真实复杂场景手写英文体识别(复现笔记)
慕课地址:
https://www.icourse163.org/learn/PKU-1002536002?tid=1206591210#/learn/announce
实验代码:
https://github.com/zlsdu/ocr-handwriting-recognition
前言
本人最近需要做ocr相关任务,看到这个项目,想尝试运行试试,下面简单记录一下。
一、配置
- 系统:Win10
- 显卡:1660Ti
- python3.7
- tensorboard==1.15.0
- tensorflow==1.15.0
- tensorflow-estimator==1.15.1
- tensorflow-gpu==1.15.0
- CUDA10.0
- cudnn7
(只列出了主要配置,一些需要的库缺少的话,直接pip install)
二、准备工作
运行process1.py和process2.py来准备数据集:
python process1.py
python process1.py
三、训练模型
python train_model.py
刚开始:
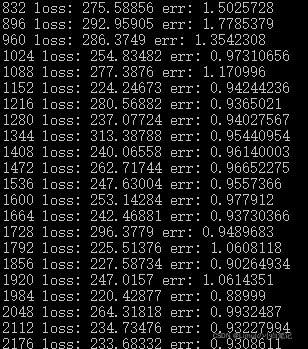
后来:
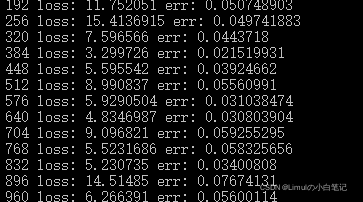
四、测试模型
python test_model.py
图片:

识别结果:

补充:
1. 过程中遇到的问题1:某地址不存在
原因分析
文件夹不存在,所以无法在该文件夹里创建文件。
解决方案
根据提示,创建文件夹。
PS:要是我没记错,创建的文件夹有:
train_img
train_txt
test_img
test_txt
2. 过程中遇到的问题2:在执行line=line[0]时下标超出范围
原因分析
访问列表下标为0的元素还能超出范围,就只能是这个列表为空。所以根据代码逻辑,这个line为空是训练集中某个标注(.txt文件)为空。
解决方案
debug后能发现出错的文件。将这个.txt文件与对应的.png文件删除。
PS:我删除了的文件有:
train_img\3_80301602_1.png
train_txt\3_80301602_1.txt
train_img\3_80301604_1.png
train_txt\3_80301604_1.txt
3. 过程中遇到的问题3:已经解压装有模型的压缩包后,restore模型时仍找不到这个模型的文件
原因分析
解压时,我选择了解压到…(E),然后这个导致了解压出来的文件夹有双层,所以模型的地址不正确导致无法restore模型。
解决方案
有两种办法:
- 打开装有模型的那两层文件夹,将模型文件放到上一层目录
or - 修改代码中模型的地址,多加一层文件夹名称
我选择的是第一种方法。
4. 数据集问题
在测试过程中,发现数据的标签存在一些错误,例如:

↑这里可以看出原图片中写着about my good friend,但标签里写的是about my send friend。














 2567
2567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









