







一、线性链式条件随机场
我们常用的是线性链式条件随机场,结构如下图所示:

链式条件随机场主要包含两种关于标记变量的团:
- 单个标记变量与 X 构成的团: { y i , X y_i,X yi,X}, i = 1 , 2 , . . . , n i =1,2,...,n i=1,2,...,n 。
- 相邻标记变量与X 构成的团: { y i − 1 , y i , X y_{i-1},y_i,X yi−1,yi,X}, i = 1 , 2 , . . . , n i =1,2,...,n i=1,2,...,n。
条件随机场使用势函数和团来定义条件概率
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X) :
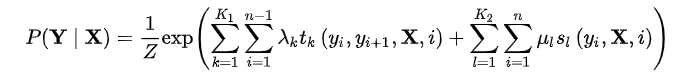
t k ( y i , y i − 1 , X , i ) t_k(y_i,y_{i-1},X,i) tk(yi,yi−1,X,i) :是定义在观测序列的两个相邻标记位置上的转移特征函数(transition feature function),用于刻画相邻标记变量之间的相关关系以及观测序列对它们的影响.
s l ( y i , X , i ) s_l(y_i,X,i) sl(yi,X,i) :是定义在观测序列的标记位置 i i i 上的状态特征函数(status feature function),用于刻画观测序列对标记变量的影响.
λ k , u l λ_k, u_l λk,ul 为参数, Z Z Z 为规范化因子(它用于确保上式满足概率的定义)。
K 1 K_1 K1 为转移特征函数的个数, K 2 K_2 K2 为状态特征函数的个数。
二、数据的预处理
1、语料分词和词性标注
如果原始语料没有分词和词性标注的话,第一步任务进行分词和词性标注。
2、命名实体的标注

根据词性进行命名实体的标注,最终生成的数据格式如下,句子与句子之间用空行隔开:

三、提取特征
在CRF中,使用的特征函数是已知的,由预料训练得到,红色框框部分;模型训练的参数只是各特征的权重,绿色框框部分。
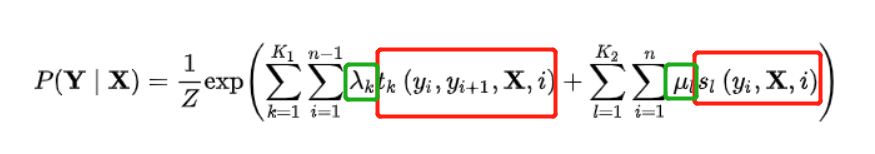
1、CRF++ 使用特征模板
模板是使用CRF++的关键,它能帮助我们自动生成一系列的特征函数,而不用我们自己生成特征函数,而特征函数正是CRF算法的核心。
Unigram模板
特征模板格式:%x[row,col] 。
x
x
x 可取
U
U
U 或
B
B
B,对应两种类型。
方括号里的编号用于标定特征来源,row 表示相对当前位置的行,0 即是当前行;col 对应训练文件中的列。这里只使用第1列(编号0),即文字。
Unigram template:第一个字符是U,这是用于描述unigram feature的模板,每一行 %x[#,#] 生成一个 CRF 中的特征函数。
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-2,0]/%x[-1,0]/%x[0,0]
U06:%x[-1,0]/%x[0,0]/%x[1,0]
U07:%x[0,0]/%x[1,0]/%x[2,0]
U08:%x[-1,0]/%x[0,0]
U09:%x[0,0]/%x[1,0]
以 小明今天穿了一件红色上衣 为例:

先看第一个模板 U00:%x[-2,0] , 第一个模板产生的特征如下:
如果当前词是 ‘今’ ,那-2位置对应的字就是 ‘小’ 。
根据第一个模板 U00:%x[-2,0] 能得到的转移特征函数如下:
func1=if(output=B and feature='U00:小') return 1 else return 0
func2=if(output=I and feature='U00:小') return 1 else return 0
func3=if(output=S and feature='U00:小') return 1 else return 0
其中 output=B 指的是当前词(字)的预测标记,也就是 ’今‘ 的预测标记,每个模板会把所有可能的标记输出都列一遍,然后通过训练确定每种标记的权重,合理的标记在训练样本中出现的次数多,对应的权重就高,不合理的标记在训练样本中出现的少,对应的权重就少。
得到三个特征函数之后当前这个字 ’今‘ 的特征函数利用第一个模板就全了。然后扫描下一个字 ‘天‘,以 ’天‘ 字作为当前字预测这个字的标记 tag ,同样会得到三个特征函数:
func1=if(output=B and feature='U00:明') return 1 else return 0
func2=if(output=I and feature='U00:明') return 1 else return 0
func3=if(output=S and feature='U00:明') return 1 else return 0
后面U01~U09都会按此方式继续扫描生成特征函数,每个特征对应的字如下:
U00:%x[-2,0] --------> 小
U01:%x[-1,0] --------> 明
U02:%x[0,0] --------> 今
U03:%x[1,0] --------> 天
U04:%x[2,0] --------> 穿
U05:%x[-2,0]/%x[-1,0]/%x[0,0] --------> 小/明/今
U06:%x[-1,0]/%x[0,0]/%x[1,0] --------> 明/今/天
U07:%x[0,0]/%x[1,0]/%x[2,0] --------> 今/天/穿
U08:%x[-1,0]/%x[0,0] --------> 明/今
U09:%x[0,0]/%x[1,0] --------> 今/天
当前位置输出标签为 B,并且当前位置为今,前一个位置是 明,前两个位置是 小,则输出 1。
func = if(output = B,and feature = "U05:小/明/今") return 1 else return 0
最终会生成NTM个特征函数,N代表分词中词的个数,T代表分词标注的tag标签(B,I,S等),M代表模板个数。
2、sklearn_crfsuite 提取特征函数

部分代码如下:
from sklearn_crfsuite import CRF
def word2features(sent, i):
"""抽取单个字的特征"""
word = sent[i]
prev_word = "<s>" if i == 0 else sent[i-1]
next_word = "</s>" if i == (len(sent)-1) else sent[i+1]
# 使用的特征:
# 前一个词,当前词,后一个词,
# 前一个词+当前词, 当前词+后一个词
features = {
'w': word,
'w-1': prev_word,
'w+1': next_word,
'w-1:w': prev_word+word,
'w:w+1': word+next_word,
'bias': 1
}
return features
def sent2features(sent):
"""抽取序列特征"""
return [word2features(sent, i) for i in range(len(sent))]
class CRFModel(object):
def __init__(self,
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=False
):
self.model = CRF(algorithm=algorithm,
c1=c1,
c2=c2,
max_iterations=max_iterations,
all_possible_transitions=all_possible_transitions)
def train(self, sentences, tag_lists):
features = [sent2features(s) for s in sentences]
print(features[0])
self.model.fit(features, tag_lists)
def test(self, sentences):
features = [sent2features(s) for s in sentences]
pred_tag_lists = self.model.predict(features)
return pred_tag_lists
















 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











