







@【自我学习】胶囊网络CapsNet
引言
CNN进行学习时,对图片特征信息较为敏感,而最大池化又会抛弃一些有价值的信息,如位置信息。
就导致了如下图所示,只要CNN学习到了眼睛鼻子嘴的特征信息,就可以抛弃掉其位置关系,将图片认定为人脸图像。
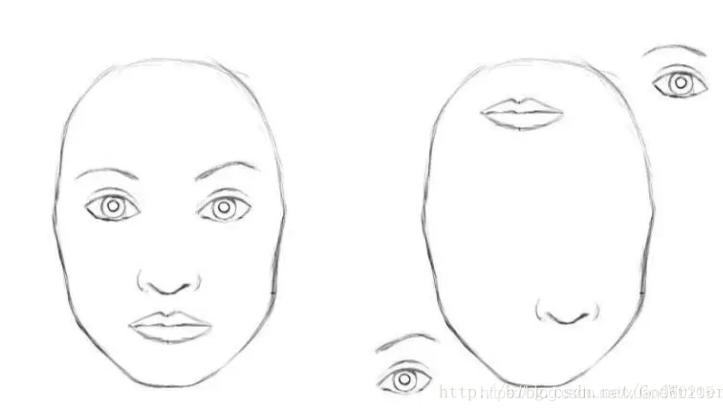
如果CNN的每个神经元输出并不仅仅用一个标量值来表示某一特征,而是用向量的方式表示某个特征的方向、大小等空间信息,则可以很大程度上增强模型的学习能力
胶囊网络
原文: 《Dynamic Routing Between Capsules》
网络结构:输入层+卷积层+主胶囊层+数字胶囊层
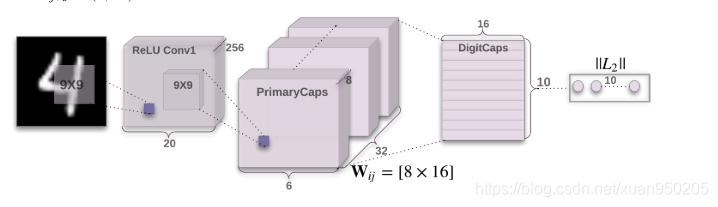
卷积层
第一层卷积为普通卷积层,由256个9X9的卷积核组成,步长为1,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6997
6997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









