







强烈推荐一本书 《游戏编程中的人工智能技术》(AI.Techniques.for.Game.Programming).(美)Mat.Buckland
一、缘起
在之前的c印记系列当中有有一个迷宫小游戏,算是一个关于数组应用的例子。 其中有通过接收按键(人工操作)的方式来走出迷宫,也有使用递归算法或非递归算法的方式来实现自动(AI操作)走出迷宫。
后来我对近两三年比较火的人工智能,机器学习,深度学习之类的比较感兴趣了。于是乎,我找了很多书籍或网上的文章来看。但基本上都是两个类别的,其中一类就是一上来就是甩出一堆让人看得眼花缭乱的数学公式,工作好几年了,大学时学的高的数学,线性代数,微积分,概率统计之类的东东基本都忘得差不多了,看起来很是头疼。 还有一类就是照搬各种框架的官方文档,这其中最多应该就算TensorFlow框架了,但他是Python实现的,而本人工作这么多年,绝大多数时间都是使用的c/c++, 虽然Python也了解一些,但还是不太习惯看Python的应用,尤其是很多将Python用的很复杂,在可读性方面总是让人一个头两个大的。
再后来无意当中看到一本书籍《游戏编程中的人工智能技术》,虽然我不是做游戏开发的,但我始终认为技术方面有很多地方都是共通的,他山之石可以攻玉。 于是乎,我就稍微的看了一下,发现真的很适合我这个初学者,浅显易懂。这本书里面关于智能,它写了两方面的东西,一个是遗传算法,一个是神经网络。 就像作者在书中所说的那样,他写这本书就是想让读者看了之后能够有一种 “啊哈”的感觉(我觉得完整一点的表达应该是:“啊哈,原来如此”之类的)。 这篇文章,说的就是那本书中提到的第一部分: 遗传算法
二、遗传算法简介
在百度百科中对遗传算法的解释如下:
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法
至于更详细的遗传算法知识点,有兴趣的可以在网上去搜索,应该会有很多资料。这里就不在铺开来说明了,说太细就变成一本书了。
2.1 基本组成
遗传算法既然是模拟生物进化的过程,那它的组成也和生物进化中的专业名词相似。
-
种群:由n个个体组成的一个物种或群体
-
适应性:个体评价,个体对环境的适应度
-
算子(操作函数):
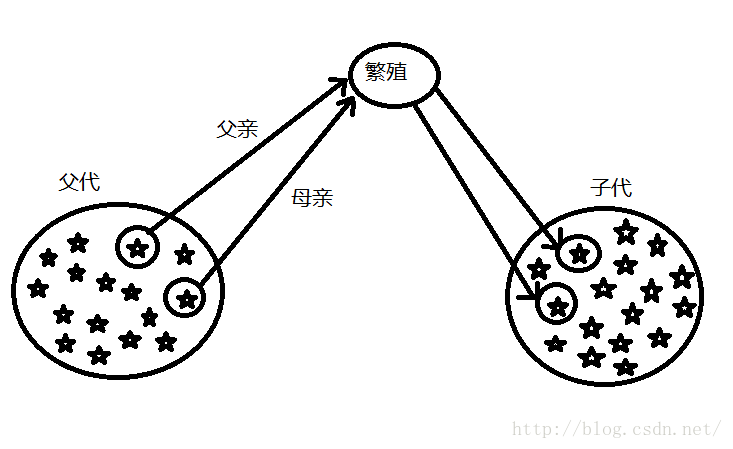
- 选择:就像自然界的物竞天择一样,根据某种规则在种群中选择出父代个体,以进行繁殖,产生出新的子代。并淘汰掉没被选择的个体。
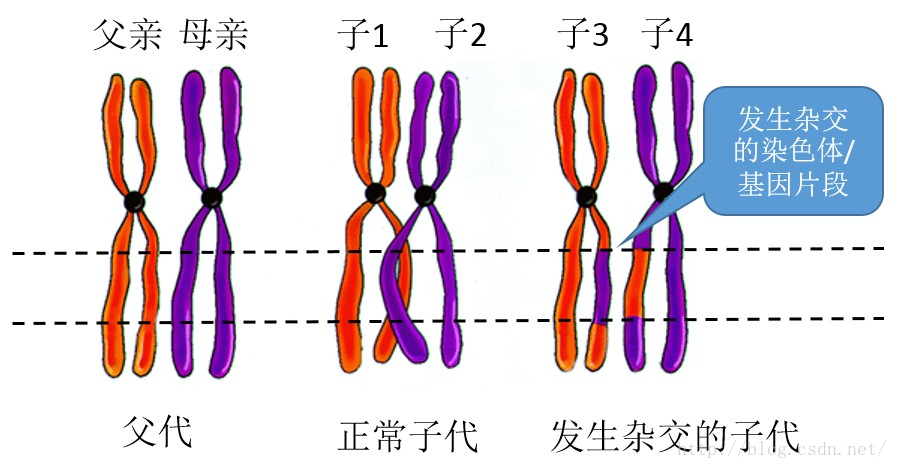
- 杂交:当父代产生子代的过程中,父代中父亲和母亲的基因片段根据特定的规则发生了互换。
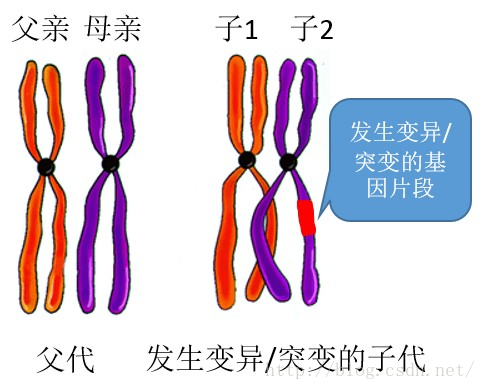
- 变异(或突变):在产生子代的过程中,子代的基因片段根据特定的规则发生了变异。
- 选择:就像自然界的物竞天择一样,根据某种规则在种群中选择出父代个体,以进行繁殖,产生出新的子代。并淘汰掉没被选择的个体。
-
碱基:在遗传算法中不一定存在,它是组成基因的基本单元。
-
基因:在遗传算法中,基因就是最基本的信息编码单元。
-
染色体:由n个基因组成,是需要求解的问题的一个潜在的可行解。
-
染色体组:由n个染色体组成(每一个染色体代表一个不同的候选解)。

2.3 基本原理/流程
遗传算法的基本流程如下:
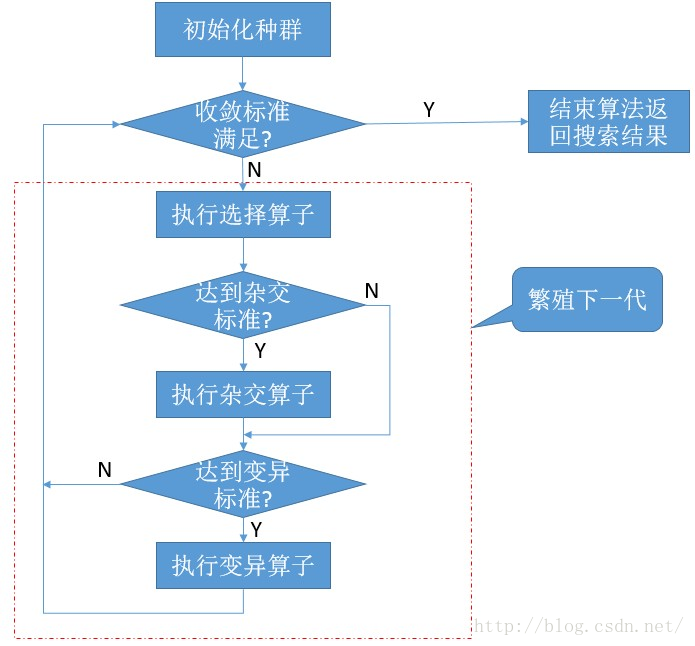
上图中红色虚线包裹起来的部分就是繁殖新子代所要进行的基本过程。另外,在判断收敛标准的同时,也需要判断遗传进行了多少代了,可以预设一个遗传代的最大数量,以防止死循环(当找不到能达到标准的解时)。
2.4 特点与案例
“遗传算法不保证一定能得到解,如果有解也不保证找到的是最优解,但只要采用的方法正确,你通常都能为遗传算法编出一个能够很好运行的程序。遗传算法的最大优点就是,你不需要知道怎么去解决一个问题;你需要知道的仅仅是,用怎么的方式对可行解进行编码,使得它能能被遗传算法机制所利用”————摘自《游戏编程中的人工智能技术》第三章第三节
以上基本上就概括了遗传算法的特点,还有一个比较经典的“袋鼠跳”问题。在说这个问题之前,需要先了解几个基本的概念:极大值、最大值、局部最优解、全局最优解。
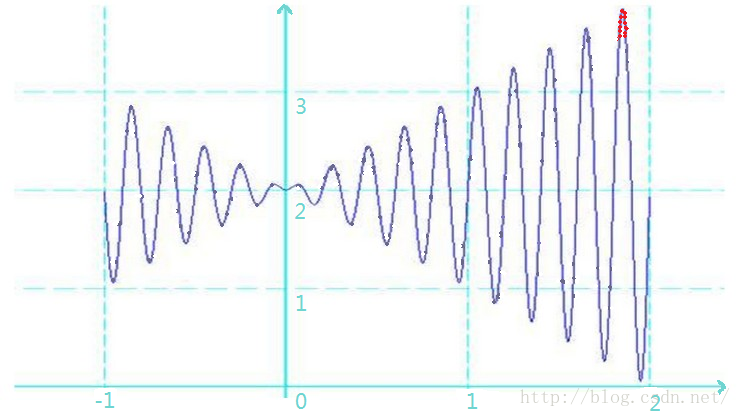
已知一元函数:
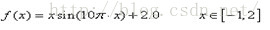
其波形如下图所示:
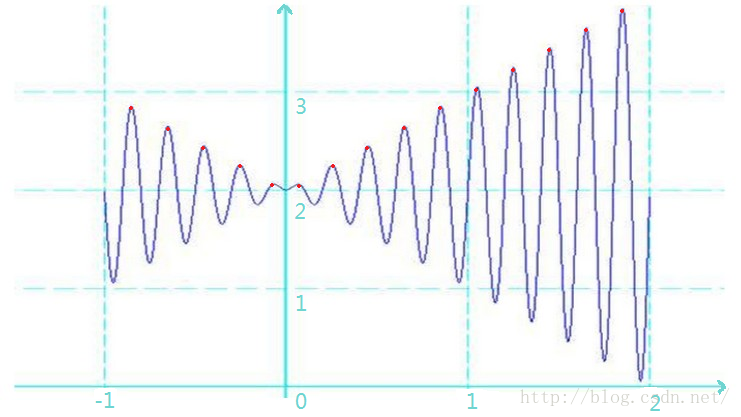
- 极大值:在一个小邻域里面左边的函数值递增,右边的函数值递减,那么这个点就是一个极大值。也就是说上图中每一个红点的“波峰”都是一个极大值。
- 最大值:就是在所有极大值当中,最大的那一个。
- 局部最优解:与极大值对应,也就是说每一个“波峰”就是一个局部最优解。
- 全局最优解:与最大值相对应。
袋鼠跳案例:
假设,上面一元函数的波形图就是广袤的群山,“波峰”就代表山顶,“波谷”就代表山谷。在这些群山之中生活着很多的袋鼠,初始情况如下图所示(红色的点代表袋鼠):
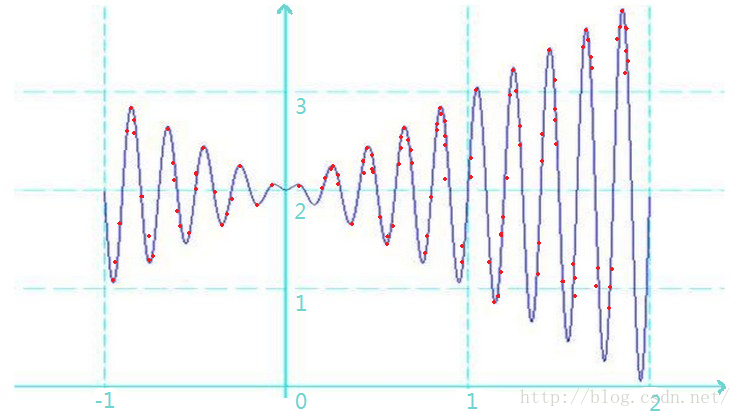
现在,由于全球气候变暖,海平面上升,海拔低的地方逐渐的被海水淹没。也就是说,生活在海拔越高的地方,活的就久。 在低海拔的生活的袋鼠就会逐步走向灭亡(原本这里的选择条件是说低海拔的袋鼠会被射杀,我这里换了一种说法,但原理是一样的)。
因此,就开启了一场自然选择与物种进化的旅程。
经过几代进化之后,低海拔的袋鼠都被海水淹没而灭绝了,高海拔的仍然在继续繁衍。
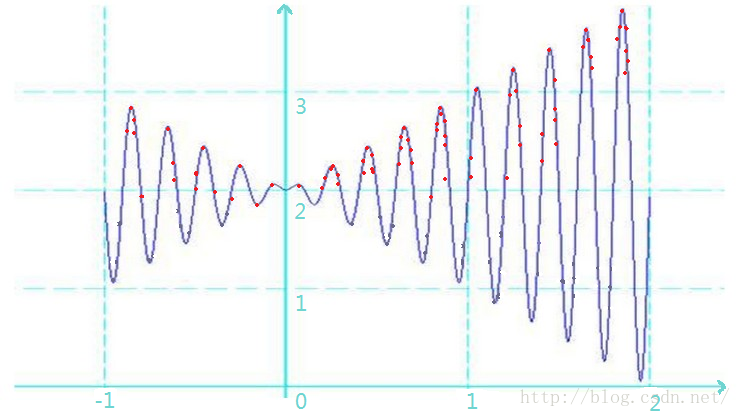
当然,这里并不是简单的直接将低海拔的袋鼠抹掉,因为在进化的过程中,低海拔的有些袋鼠会因为某些原因向高海拔迁徙(就当这部分是聪明有远见的袋鼠吧),同样的生活在高海拔的地方袋鼠也有可能反而向低海拔的地方迁徙。
最理想的情况是(或者说最优解),到最后大多数袋鼠都迁徙到最高峰生存繁衍了。如下图所示:
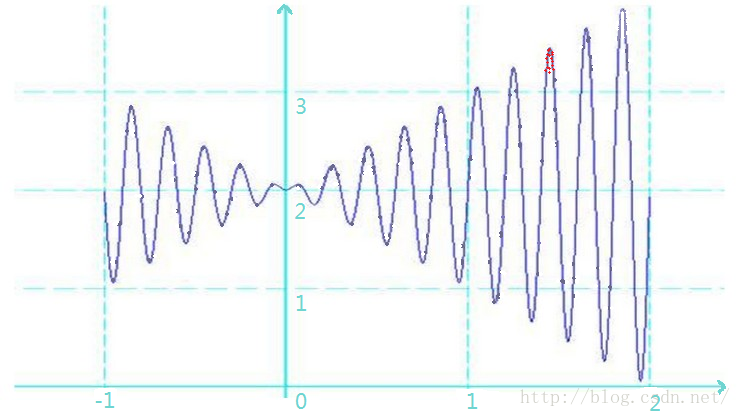
前面已经说到了,遗传算法并不保证一定能够得到解,如果有解也不保证是最优解。在袋鼠跳的案例中,袋鼠们也不总是能够幸运的跳到最高的山峰上,有时候,他们以为的他们跳到了最高峰,但其实并不是,有可能只是如下图所示的一个局部高峰而已:
三、遗传算法走迷宫
看过c印记系列中的就知道,这个由数组作为地图的迷宫是一个二维的平面,角色的移动方式有四种:前,后,左,右(或者东南西北,上下左右都可以),每次只能移动一步,遇到障碍物或墙壁,只能改变方向,不能穿透障碍物。这就是基本的几个规则。
接下来,就是根据第二章中说到的遗传算法的组成,依次将迷宫小游戏的元素套入到遗传算法中去。
3.1 碱基,基因,染色体,染色体组
上面说到迷宫小游戏的移动方式有四种,如果我们使用二进制数值来表示迷宫小游戏的基因的话,就需要两位二进制数来表示。
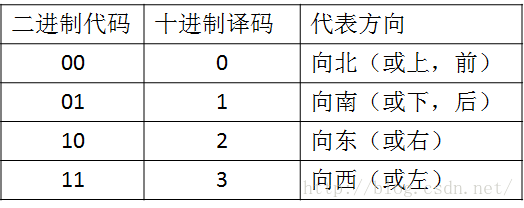
这部分也是《游戏编程中的人工智能技术》中第三章第四节中的例子:帮助Bob回家当中说到的东西。在这个迷宫小游戏当中,虽然在进行遗传算法的时候也有使用碱基层的部分,但在这里为了简单直接使用十进制来表示一个基因,并为其定义了一个数据类型
typedef char gene_t; /** the type of gene */
碱基,基因,染色体,染色体组的包含关系如下所示:

从这张图可以知道,染色体组由n条染色体组成,染色体由n个基因组成,基因由n个碱基组成。也就是说在定义数据结构体时需要知道各自的数量。 但是因为这些变量的值都是相同的(比如染色体组中,每一条染色体内包含的基因数量都是相同),所以就可以将这些表示数量的变量提取到公共部分(比如,染色体中表示当前染色体中包含的基因数量的变量就可以提取出来)。这样可以节省不必要的内存浪费。具体的数据结构定义如下:
typedef struct genome_s
{
// int gene_length; /** how many bits per gene */
// int chromosome_length; /** how many count of gene per chromosome */
gene_t genes[CHROMOSOME_LENGTH]; /** chromosome (consist of a number of genes) */
double fitness; /** the score of fitness */
}genome_t;
从上面这个数据结构可以看出,这里其实并没有仔细区分染色体和染色体组(或者说,这里每个染色体组里面就只有一条染色体)。另外一点是,这里使用数组来存放基因,只是为了简单(因为使用c语言写的,没有方便的vector之类的容器),如果要编写灵活性和通用性较好的遗传算法程序,可能就不太恰当了。
然后在上面的结构体中海油一个变量“double fitness;”,因为这里一个染色体组就表示一个个体,每个个体都需要一个变量来表示这个个体对环境的适应度。
接下来就是整个种群的数据结构的定义了
typedef struct population_s
{
int pop_size; /** the size of population(how many genomes per population) */
genome_t genomes[POPULATION_SIZE]; /** the population of genomes */
double crossover_rate; /** the rate of genome crossover */
double mutation_rate; /** the rate of genome mutation */
/** because all genome have the same of gen_length and chromosome length,
* so we move them to here from structure of genome_t to save memory */
int gene_length; /** how many bits per gene */
int chromosome_length; /** how many count of gene per chromosome */
//
int fittest_genome; /**the genome which have best score of fitness */
double best_fitness_score; /** the best of score of fitness */
double total_fitness_score; /** the total of all score of fitness */
int generation; /** mark the count of genetic generation */
unsigned int is_running; /** 1: running, 0: not. to avoid endless loop */
}population_t;
上面的数据结构的定义中,都有相应的注释,这里就不多说了。
最后是地图部分的数据结构定义了,其原理和结构和c印记中是差不多了,也不再多做解释。只是二维数组的行和列的大小不太一样(是截取的《游戏编程中的人工智能技术》中第三章第四节中的例子的数组结构)。
static const int g_maze_map[MAZE_ROW][MAZE_COLUMN] =
{
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1,
8, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1,
1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1,
1, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1,
1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1,
1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1,
1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 5,
1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1
};
3.2 迷宫小游戏的遗传算法算子
在这一节就根据第二章中的遗传算法的基本流程来依次说明各个算子函数。
3.2.1 判断验收标准
初始化部分就不必细说了,首先来看 “收敛标准是否满足?”步骤。
这一步在代码中的 updateFitnessScore 函数中进行,具体代码如下:
static void updateFitnessScore(population_t* population)
{
int i;
int pop_size = population->pop_size;
int move_steps[CHROMOSOME_LENGTH];
genome_t* genome = NULL;
int chromosome_length = population->chromosome_length;
int fittest_genome = 0;
double best_fitness_score = 0;
double total_fitness_score = 0;
//更新适应性分数,并检测到目前为止适应度最好的个体
for (i = 0; i < pop_size; ++i)
{
genome = &(population->genomes[i]);
//将个体的基因译码为具体的移动步骤
genomeDecode(genome, move_steps, chromosome_length);
//通过试走一遍来确定当前个体最终的适应性分数
genome->fitness = mazeTestPlay(move_steps, chromosome_length);
//更新总适应性分数
total_fitness_score += genome->fitness;
//如果当前个体的适应性分数是最好的,那就当前个体在种群中的索引值保存起来
if (genome->fitness > best_fitness_score)
{
best_fitness_score = genome->fitness;
fittest_genome = i;
//检测是否已经到达迷宫出口
if (genome->fitness == 1)
{
//如果已到达迷宫出口,就停止遗传算法的运行
population->is_running = 0;
}
}
}//next genome
population->fittest_genome = fittest_genome;
population->best_fitness_score = best_fitness_score;
population->total_fitness_score = total_fitness_score;
}
经过上面的函数之后,如果population->is_running 仍然等于 1,表示还未达到收敛标准,需要继续繁衍下一代。
3.2.2 执行选择算子
这时候就需要执行选择算子了。在遗传算法中有很多种选择算子,这里只是使用了一种比较简单的选择算子,叫做 轮盘赌 选择。如果有对此感兴趣的可以自行在网上去搜索相关信息。
** 轮盘赌选择**
又称比例选择方法.其基本思想是:各个个体被选中的概率与其适应度大小成正比。但这不保证适应性分数最高的成员一定能选入下一代,仅仅说明它有最大的概率被选中。就像下图的饼图一样,每一个块,代表一个个体的适应度,当最终的选择点落入哪一个块,就表示哪一个个体被选中。
具体操作如下:
(1)计算出群体中每个个体的适应度f(i=1,2,…,M),M为群体大小;
(2)获取选择点;
(3) 然后依次将个体的适应度累加,直到累加个体n之后,总的适应性分数 > 选择点 时就表明个体n被选中;
依次累加这个起始点也可以使用随机函数来确定,在本例中为了简单,每次都是从第0个个体开始累加的。
具体的函数实现如下:
genome_t* rouletteWheelSelection(population_t* population)
{
/** 使用一个随机数(0.0 ~ 0.9999999...) 来乘以 总适应性分数得到选择点 */
double fSlice = randFloat() * population->total_fitness_score;
double total = 0.0;
genome_t* genomes = population->genomes;
int pop_size = population->pop_size;
int selected_genome = 0;
for (int i = 0; i < pop_size; ++i)
{
total += genomes[i].fitness; /** 累加适应性分数 */
if (total > fSlice)
{/** 如果累加的适应性分数大于选择点时,表示得到了被选择的个体,记录下索引值并推出循环 */
selected_genome = i;
break;
}
}
return &genomes[selected_genome]; /** 根据索引得到被选中个体,并将其返回 */
}
3.2.3 执行杂交算子
本例子中使用的也都是简单的杂交算子,其基本思路就是:
-
确定一个杂交率,即,父代基因发生交换的概率。《游戏编程中的人工智能技术》一书中说“实验表明这一数值通常取为0.7左右是理想的,尽管某些问题领域可能需要更高一些或较低一些的值。” 所以本例也是选择的0.7
-
产生一个随机数,并与杂交率比较,如果随机数小于等于(<=)杂交率,也就表明在需要进行交杂的范畴之类。
-
产生一个随机数来作为基因交换的起始点(本例中使用的是单点杂交)将起始点到染色体末尾的所有基因进行交换。
具体函数如下所示:
void geneticCrossover(gene_t mum[], gene_t dad[], gene_t baby1[], gene_t baby2[],double crossover_rate, int chromosome_length)
{
if ((randFloat() > crossover_rate) || (geneCompare(dad, mum, chromosome_length)))
{/** 如果产生的随机数大于杂交率,或者父代中的 父亲和母亲是相同的,就不需要进行杂交,直接返回 */
baby1 = mum;
baby2 = dad;
return;
}
/** 随机产生一个基因交换的起始点 */
int cp = randInt(0, chromosome_length - 1);
/** 按正常顺序将父代基因拷贝到子代基因中去 */
for (int i = 0; i < cp; ++i)
{
baby1[i] = mum[i];
baby2[i] = dad[i];
}
/** 从交换起始点开始,将父亲和母亲的基因交换拷贝到子代基因中去 */
for (int i = cp; i < chromosome_length; ++i)
{
baby1[i] = dad[i] ;
baby2[i] = mum[i];
}
}
3.2.4 执行突变算子
本例单子的变异算子也比较加单,就是在将符合变异的碱基(本例当中碱基是一个二进制位),进行翻转,即0变1,1变0。
具体函数如下:
void geneMutate(gene_t gene, int gene_length, double mutation_rate)
{
int i;
for (i = 0; i < gene_length; i++)
{
if (randFloat() < mutation_rate)
{/** 如果产生的随机数小于突变率,也就表明在执行突变的范围之内 */
/** 将当前基因的第 i 个碱基(二进制位) 进行翻转 */
gene ^= ((1 << (i - 1)));
}
}
}
void geneticMutate(gene_t genes[], int chromosome_length, double mutation_rate)
{
int i;
for (i = 0; i < chromosome_length; i++)
{
/** 依次对每一个基因尝试进行突变操作 */
geneMutate(genes[i], GENE_LENGTH, mutation_rate);
}//next bit
}
3.2.5 Epoch函数
Epoch函数就是组织整个遗传算法的函数,本例的实现如下:
unsigned int populationEpoch(population_t* population)
{
updateFitnessScore(population); /** 更新适应性分数,并检查是否达到收敛标准 */
if (population->is_running == 1)
{/** 如果没有达到收敛标准,就产生新的子代 */
//Now to create a new population
int baby_count = 0;
int pop_size = population->pop_size;
int chromosome_length = population->chromosome_length;
genome_t* org_genomes = population->genomes;
//create some storage for the baby genomes
genome_t baby_genomes[POPULATION_SIZE]; /** 子代种群 */
while (baby_count < pop_size)
{
/** 使用轮盘赌的方式在父代中选出父亲和母亲 */
genome_t* mum = rouletteWheelSelection(population);
genome_t* dad = rouletteWheelSelection(population);
/** 执行杂交算子 */
genome_t baby1, baby2;
geneticCrossover(mum->genes, dad->genes, baby1.genes, baby2.genes, population->crossover_rate, chromosome_length);
/** 分别对两个子代执行突变算子 */
geneticMutate(baby1.genes, chromosome_length, population->mutation_rate);
geneticMutate(baby2.genes, chromosome_length, population->mutation_rate);
/** 将新产生的子代存储到子代种群当中 */
baby_genomes[baby_count++] = baby1;
baby_genomes[baby_count++] = baby2;
}
//copy babies back into starter population
memcpy(org_genomes, baby_genomes, sizeof(genome_t) * POPULATION_SIZE);
//increment the generation counter
population->generation++;
}
return (population->is_running == 1) ? 0 : 1;
}
3.2.6 算子总结
不管是杂交率,还是突变率,都需要根据具体的问题进行设定,然后反复调整,选择不当,可能会出现过早收敛,就像第二章中的袋鼠跳例子一样,过早收敛,就可能搜索到的是局部最优解,也有可能收敛太慢或者无法收敛。当然也可以使用不固定的杂交率或突变率,比如在繁衍的前期可以设置稍微大雨点的值,随着繁衍,再按照某种规律逐步的减小这些值,就好像显微镜的粗调和细调一样。本例子中所有东西都是选的比较简单的实现,所以就使用的是固定值。
3.3 具体代码
由于代码较多,这里就没有全部贴出来。有兴趣的话,可以在开源中国上去抓取,网址如下:
https://gitee.com/xuanwolanxue/genetic_maze
四、后续更新
- 2017/05/18 更新,增加c++版本的遗传算法以及迷宫游戏的实现。

















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









