






摘要:基于检测的自适应跟踪已经被广泛研究了且前景很好。这些追踪器的关键理念是如何训练一个在线有识别力的分类器,这个分类器可以把一个对象从局部背景中分离出来。利用从检测目标位置附近的当前帧中提取的正样本和负样本不断更新分类器。然而,如果检测不准确,样本可能提取的不太准确,从而导致视觉漂移。最近,基于跟踪的多实例学习(MIL)已经在某些程度上提出了一些解决这些问题的办法。它将样本放入正负包中,然后通过最大化似然函数用在线提升的办法选择一些特征。最后,被选择的特征相结合用于分类。然而,在MIL追踪里,通过似然函数选择特征,这样从复杂的背景提取的目标具有较少的信息量。受主动学习的方法的启发,在本文中,我们提出一个主动特征选择的方法,通过利用费舍尔信息准则测量分类器模型的不确定性,我们能够选择比MIL跟踪器携带更多信息量的特征。更具体地说,通过优化费舍尔准则,我们提出了一个在线提升特征选择方法。可以产生更加鲁棒和高效实时跟踪性能。与先进的跟踪器相比,基于挑战性序列的实验评估展示了本文提出的跟踪器的效率,准确性,和鲁棒性。
关键字:主动学习;信息准则;多实例学习;视觉跟踪
1引言
在计算机视觉领域里面,视觉跟踪是一个非常活跃的研究主题,有着很重要的地位,特别是在车辆导航、交通监测以及人机交互等应用方面[1]。虽然在近几十年来目标跟踪领域已经提出了很多算法,但它一直以来都存在着一个重大的难题,即目标物体的外观会因为某些因素而产生重大的变化,例如光照变化、姿势变化、遮挡问题、突然的运动。这些因素都会导致跟踪的结果产生视觉漂移等问题。因此,设计一个高性能的跟踪系统的关键在于如何设计一个鲁棒的外观模型,从而能够很好地处理以上所提到的问题。
有些外观模型仅仅表示物体,而有些外观模型既考虑物体,又考虑局部背景。后者的方法比前者好,因为它把跟踪问题当做一个二进制的分类问题,通过一个有区分能力的分类器把目标从背景中分离出来。考虑到这些方法与目标检测任务比较相关,它们经常被称为基于检测的跟踪。当训练分类器的时候,正负样本的选择会影响跟踪的性能。大多数跟踪系统会选择当前的帧作为正样本。如果跟踪的位置不精确,分类器就会以一个错误的正样本进行更新,从而随着时间的推移会导致视觉漂移。为了减轻漂移问题,跟踪的目标位置附近的多样本可以用来训练分类器。用传统的监督学习的方法去训练分类器,会产生模糊歧义的问题。[2]。
最近,为了解决跟踪的模糊歧义问题,有人提出了多实例学习(MIL)。样本被放入包中且只提供包的标签。如果包中有一个正样本,那么就为正包;如果包中所有的样本都是负样本,那么就是负包。选择跟踪位置附近的样本放入正包中,选择远离跟踪位置的样本放入负包中。通过优化包的似然函数来设计分类器,为了处理外观的不断变化,通过最大化包的似然函数提出一个在线的MIL提升算法来顺序从特征池中选择有区分能力的特征。最后把所选择的弱分类器线性组合成一个强分类器,从而在下一帧把物体从背景中分离处理。实验表明它比先进的跟踪器能够更好地处理视觉漂移的问题[2]。
尽管他们取得了成功,但是,MIL跟踪器[2]有以下的缺点。第一、所选择的特征携带较少的信息量。为了使分类器有足够的区分能力,就需要从特征池中选择大量的特征,这就给计算带来了不便。第二、选择的特征越多,这些特征之间的区别就越小,这也会降低分类器的性能,从而导致漂移。
为了解决上述问题,受主动学习方法的启发[3],本文提出了一种主动特征选择的方法来选择携带更多信息量的特征——主动特征选择(AFS)。通过优化包的费舍尔信息函数(而不是包的似然函数)提出了一种在线的特征选择方法。因此,所选择的特征比MIL跟踪器中通过包的似然函数所选择的特征携带更多的信息量。因此就可以用更少的特征去设计分类器了,这笔MIL跟踪器的分类器更加有效和鲁棒。基于挑战视频序列的实验结果表明了AFS的方法在有效性、精确度和鲁棒性等方面都有一定的优势。
本文的其余部分组织如下。一些相关的工作是在第二部分回顾了。在第三部分中,我们详细介绍了我们的跟踪算法。第四部分把我们的追踪器与先进的追踪器进行了比较。最后,第五部分是结论。
2相关工作
视觉跟踪已经被广泛的研究,一个好的回顾可以在[1]中看到。根据如何处理目标对象和背景的外观变化,最近的算法主要分为两类:生成方法[4]—[12]和有识别力的方法[2],[13]-[21]。生成方法通过最小化搜索区域和涉及的目标模型之间的差异学习目标对象的外观模型。Black等人[4]通过离线学习子空间模型表述物体。为了处理目标外观的不断变化,提出了一些在线的外观更新模型。Jepson等人[5提出了]高斯混合模型,由一个在线期望最大化(EM)算法更新。Ho等人[6]和罗斯等人[7]使用增量子空间更新方法去适应外观变化。Adam等人[8]提出了基于分块的外观模型去处理姿势变化和部分遮挡。最近,提出的稀疏表达的方法处理视觉跟踪里的部分遮挡问题[9]。Kwon[10]把观察模型分解为多个基本观测模型,涵盖了不同类型的特征和运动来处理姿势变化,光照和尺度变化。Sun等人[11]提出一个物体外观模型,它结合了局部的尺度不变特征和整体增量主成分分析(PCA)。
通过训练一个有判别能力的分类器,从而把物体从背景中分离出来,判别方法把跟踪看为二进制分类问题。Avidan[13]训练一个离线支持向量机(SVM)并组合成一个基于光流的追踪器。为了适应对象和背景的外观变化,Avidan[14]提出在线提升方法来训练分类器:有些弱分类器以在线的方式更新,然后组合成一个强分类器。Collins等人[15]提出了一个在线特征选择方案,可以评价多个特征,并把这个方法与mean-shift跟踪系统[12]结合起来,并选择最有识别能力的特征。在[16],利用对象和结构化环境之间的关系利用提高跟踪的性能。Grabner等人[17]开发了一个在线提升特征选择技术,展示了良好的性能去自适应处理外观变化。为了更好地处理视觉漂移,Grabner等人[18]提出了一种在线半监督跟踪器,它只在第一帧标签样本,而不标签后继帧的样本。Babenko等人[2]提出使用一个在线MIL方法处理跟踪位置的模糊歧义问题,以减少视觉漂移。Kalal等人[19]提出了半监督学习方法,通过一个拥有结构约束的在线分类器选择正负样本。最近,一个基于压缩传感理论[22]的有效跟踪算法[21]被提出了,这表明,从高维多尺度图像特征空间随机提取的低维特征可以保留识别能力,从而促进目标跟踪。
3基于自适应特征选择的跟踪
A 系统综述
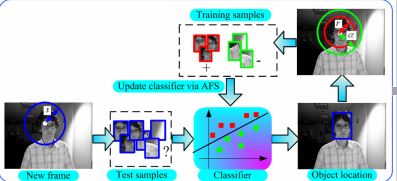
图1说明了我们跟踪系统的基本流程。在我们跟踪系统里有两个重要的部分。一个是如何检测物体在下一帧的位置,另一个是如何更新分类器。我们描述第t帧目标的位置为。旧目标位置附近的一系列图像块记作,s是搜索半径,x代表图像块。然后,对于所有的我们计算分类器响应,分类器是一些弱分类器的线性组合。最后,我们用贪婪策略更新目标位置
(1)
当所有的目标位置更新以后,一系列样本被采样,并放入一个正包中,r是一个标量半径。对于负样本,我们随机选取一些样本,,是一个标量半径,因为包含大量的样本。如果两个连续帧之间没有变化很多,负样本块(不是来自目标周围的边界区域)也许对分类有利,因为他们是相关的。然而,如果背景严重改变,这样的负块也许对分类有边缘效应,因为它们不太相关。为了协调,我们仅考虑目标周围的负样本。我们把所有的负样本放入一个负包中,通过用在线的方法最大化包的费舍尔信息损失函数来跟新分类器。
B MIL跟踪器
我们首先简短地回顾MIL跟踪器[2],这和我们的工作很相关。MIL方法是Dietterich等人介绍的,为了处理药物活性预测。假设我们有一系列的N包,每一个包有ni个实例。是包的标签,是实例的标签。MIL定义,如果包是正的,则至少有一个实例标签是正的。如果包标签为0,则所有对应的实例标签都为0。MIL跟踪器寻找判别分类器,可以返回条件概率。由于判别分类器是一个实例分类器,且和实例的条件概率相关,Noisy-OR模型用来利用实例的条件概率去估计包概率
(2)
实例概率 (3)
是sigmoid函数,通过最小化包的对数似然损失函数学习分类器
(4)
为了处理外观变化,提出在线MIL提升算法去更新分类器。首先,维持弱分类器,然后通过最大化包的对数似然,选择少量的弱分类器
其中,是前k-1个弱分类器组成的强分类器,是拥有M个候选弱分类器的弱分类器池。类似于脸部检测[24]中的提升特征选择方法,弱分类器可以被看作特征选择,因为每一个弱分类器对应一个特征。特征选择对于减少视觉漂移是非常有用的[15]。此外分类器可以有效运行,因为选择特征的数量比特征池中的少的多。
C AFS原理
从(4)中的对数似然函数,我们可以发现(5)中的特征选择方法是选择弱分类器,目的是最大化正包的条件概率和最小化负包的条件概率。我们认为与优化费舍尔信息准则后的特征相比,被选特征携带更少的信息量,下面会介绍的。因此,为了确保足够的判别信息,在MIL中,选择了相对多的特征(K=50,M=250),在AFS中,K=15,M=50。此外,如果太多的特征被选择,目标和背景特征之间的判别会减少。
类似于MIL跟踪器[2],我们定义分类器如下形式
其中,是一个权重向量,是一个弱分类器向量。h中的每一个元素都是一个决策树函数,返回二进制标签(+1或-1)。为了设计分类器,我们需要估计对应的参数α。Cramer–Rao不等式[25]表明,对于α的任意无偏估计,它们是独立同分布的样本,tn的协方差应该满足是一个非非正定矩阵,其中I(α)是费舍尔信息矩阵[25],定义为
费舍尔信息矩阵表示了分类模型的整体不确定性,这在主动特征方法[26]中经常用到。在[26]中,对于主动学习每一个询问,选择可以减少费舍尔信息的未标签样本。为了测量AFS分类模型的不确定性,我们使用基于包概率样本的费舍尔信息矩阵
其中,是包标签,δIm(δ>0是一个标量参数,Im是一个单位矩阵)被增加使得I(α)非奇异。因此,如何选择δIm不影响特征选择步骤。在(8)中,和通过(2),(3),(6)表达如下:
请注意,我们的信息矩阵(8)是不同于最近研制的多实例主动学习(MIAL)方法[27]和[28] 的目标函数,因为当标签是已知的,我们的目标是衡量分类模型的不确定性,虽然MIAL的目的是测量未标签样本的分类模型的不确定性。
逆费舍尔信息矩阵I(α)-1是估计α的协方差矩阵的较低边界[25]。作为特殊例子,det(I(α)-1)是α中元素的协方差乘积的较低边界。因此,Liao等人[29]提出选择样本最大化det(I(α)-1),减少α的不确定性。然而,由于很难计算det(I(α)-1),我们减少 矩阵I(α)的迹,因为det(I(α)-1)的上界是。很容易证实det(I(α)-1)≤。因为I(α)是一个正定对称矩阵[25],所有的特征值都是正数[30]。因此,有如下不等式[30]
在(11)中,设置,因为每个元素是一个决策树函数。请看附录A。
虽然(11)看起来很复杂,它的物理意义很简单。对于正包,[31],矩阵I(α)迹中的正包可以简化为。为了最小化函数,我们需要最大化和。类似于包似然函数(4),第一步是最大化正包的条件概率。第二步是达到最大值,可以测量实例的分类不确定性。矩阵I(α)迹中的负包包括两个部分:和。分析和正包是一样的。因此,最小化矩阵的迹可以看作是包概率和分类不确定性之间的权衡。下面,我们提出AFS,通过最小化矩阵的迹去选择有信息量的特征。
D 在线AFS提升
当顺序选择弱分类器来优化特定的目标函数时,我们用统计的观点看待提升[32](每个弱分类器对应一个特征):
其中,是前k-1个弱分类器组成的强分类器。Φ是所有可能的弱分类器的集合,对于在线学习,我们保持M个候选弱分类器的特征池。当更新强分类器的时候,我们首先用最新的样本更新弱分类器,然后通过最小化费舍尔信息矩阵顺序选择K(K















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









