






一、简介
TF-IDF的全称是Term Frequency-inverse Document Frequency ,是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比。这种计算方式能有效避免常用词对关键词的影响,提高了关键词与文章之间的相关性。
二、详细介绍
(1)主要思想
如果某个词或短语在 一篇文章中 出现的 频率TF高 ,并且在 其他文章中 很 少 出现,则认为此词或者短语具有 很好的类别区分能力 ,适合用于分类。
(2)求解公式

解释:
TF 是词频(Term Frequency),某个词在文章中出现的总次数。常用的求解公式:
拓展:不用词的出现次数的原因是为了避免文章的长度对词的出现次数的影响,导致结果偏向过长的文档。
IDF 是逆向文档频率(Inverse Document Frequency),度量某个词的普遍性。常用的求解公式:
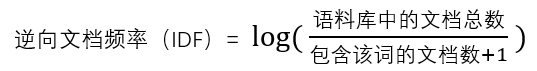
拓展:
1、需要一个语料库,用来模拟语言的使用环境。
2、分母加1是为了避免分母为0(即所有文档都不包含该词的时候)。
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
(3)优缺点:
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)















 1355
1355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









