






1. Nosql
1.特点
方便扩展、大数据量高性能、数据类型是对样的
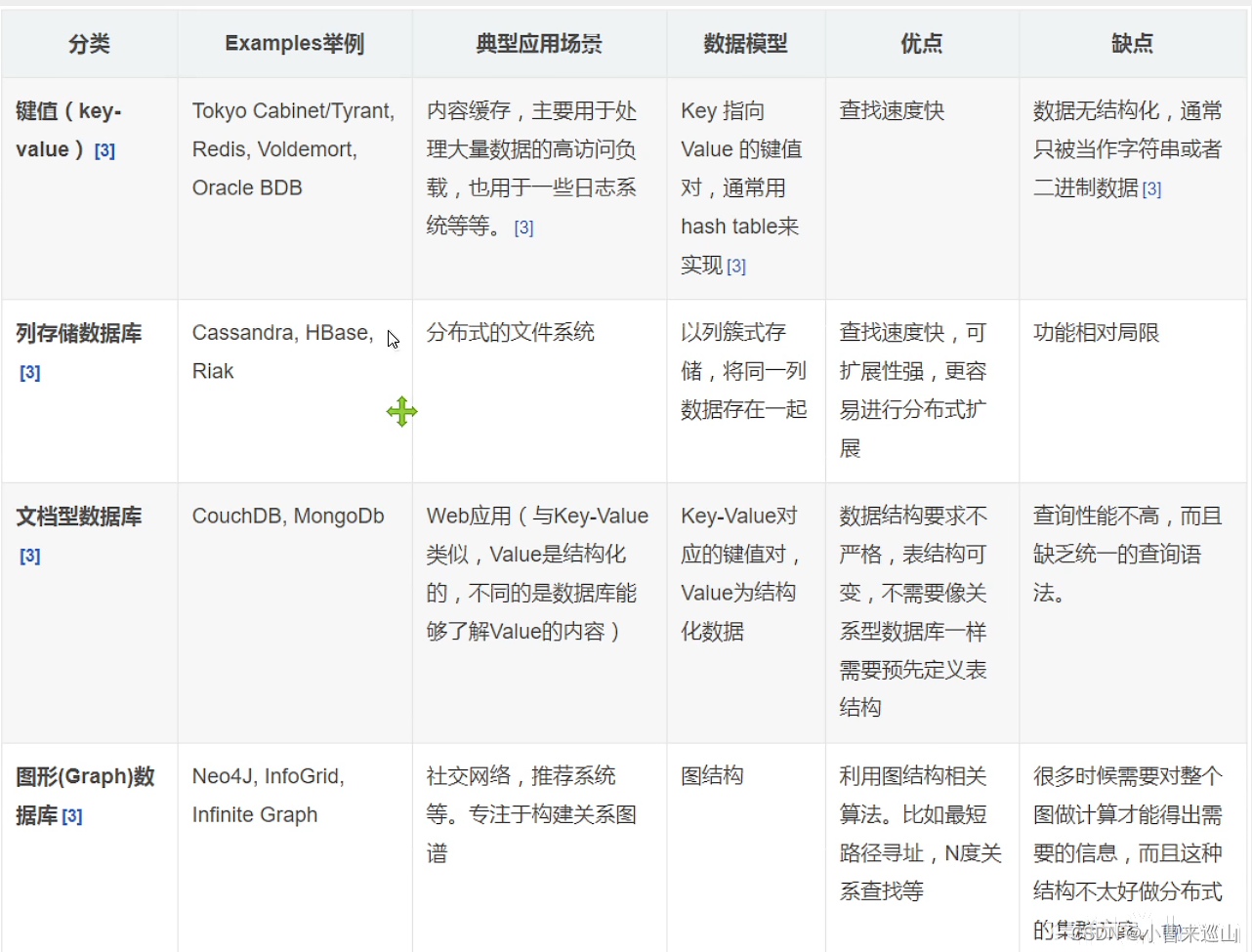
2、四大分类
1、KV键值对

2、文档型数据库

3 、列存储数据库
4、图关系数据库
优缺点对比
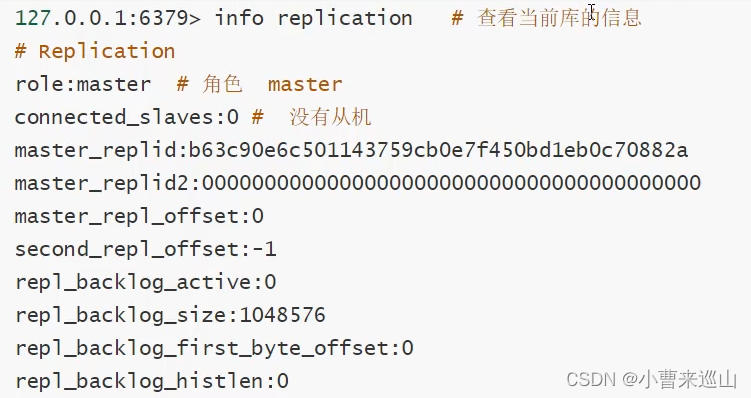
2.Redis
内存中的数据结构存储系统,可以用作数据库,缓存和消息中间件
远程字典服务,Key_Value数据库
redis功能:内存存储、持久化(rdb,aof)
2.1、redis安装及运行(linux)
9、Linux下安装Redis详解_哔哩哔哩_bilibili
cd usr/local/bin、 redis-server Kconfig/redis.conf 、 redis-cli -p 6379
退出:shutdown 、 quit
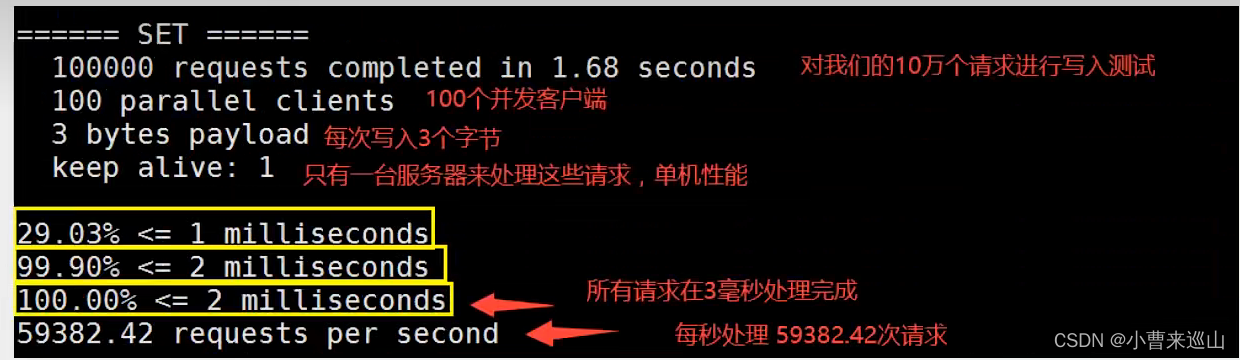
2.2性能测试
redis-benchmark -h localhost -p 6379 -c 100 -n 100000(测试100个并发连接,并且每个并发连接100000个请求)
查看分析如下:
2.3基础知识
默认使用的是第0个数据库,可以用select来进行切换
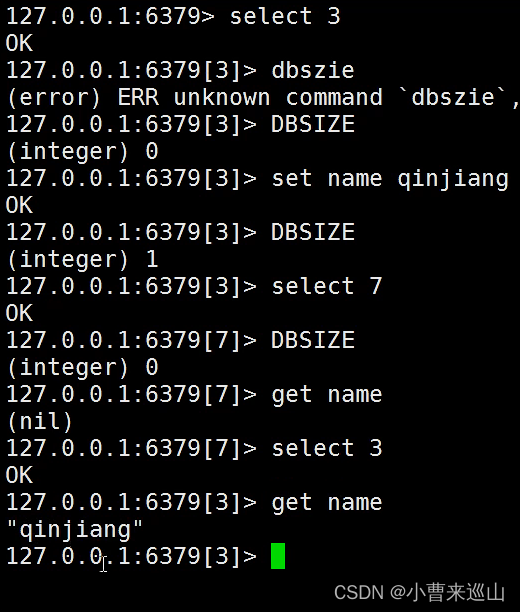
keys * 查看当前数据库所有的key ;flushdb 清除当前数据库 ;move [name] 移除当前的key ;
EXPIRE [name] 10 name10秒后过期 ; ttl [name] 查看name还有多长时间过期;
type [name] 查看name是什么类型的
命令可以再redis官网中的命令进行查询学习:
redis是单线程的(基于内存)
redis的瓶颈是与机器的内存和网络带宽相关,与cpu无关。
redis为什么单线程还这么快
核心:redis是将数据存放到内存中的,所以使用单线程操作效率最高,多线程中cpu上下文会切换:耗时的操作
2.4 五大数据类型
2.4.1 String(value可以是字符串或者数字)
APPEND [name] "avdfg" 拼接字符串;GETRANGE [name] 0 3 截取0-3的字符串
DECRBY [name] 10 以步长为10执行降低;SETRANGE [name] 1 xx 替换指定位置开始的字符串

setnx(分布锁中会经常用到)
值相当于json字符串来保存一个对象,很巧妙的设计
getset [name] "asfa” 先get在set
应用场景:计数器、统计多单位的数量、粉丝数、对象缓存存储
2.4.2 List
在Redis中,list可以变成栈、队列、阻塞队列
list命令以l开头的
LPUSH(RPUSH ) list [one] (添加)、
LRANGE list 0 2 (查看)、
lindex list 2(查看) 、
lpop(rpop) list (移除) 、
rpoplpush list otherlist(移动元素)、
Linsert list before(after) "we" "ewr3e" (在某位置插入元素ewr3e)
lrem list 2 three:移除两个three
注(上面的list是创建的list名称,用户可以自由修改)
小结:
list相当于一个链表

使用场景:消息排队! 消息队列(lpush,rpop),栈(lpush,lpop)
2.4.3 set集合(没有重复元素)
命令以s开头( sadd myset "xx" (添加); SMEMBERS myset (查看) ;SISMEMBER myset "xx" (判断是否存在) ; srem myset "xx" (移除元素) ;SRANDMEMBER myset 2 (随机挑选2个元素) ;spop myset (随机删除元素);setmove myset myset2 “xx” (移动元素))
交并补:sdiff set1 set2 (不同元素) ;sinter set1 set2 (交集);sunion set1 set2 (并集)
应用场景:共同好友,用户关注博主等
2.4.4 hash(哈希)
Map集合,key-value 这个值是一个map集合
命令以h开头(hset 、hget 、hmset(批量添加)、hmget 、hsetall(获取所有值)、hdel (删除指定的key字段)hlen (获取长度))
注意: hash变更的数据user name age ,尤其是用户信息之类的,经常变动的信息,hash更适合对象的存储,string更适合字符串的存储
2.4.5 zset(有序集合)
命令以z开头 (zset set1 2 xx (2是设置的排序)、zrem (移除制定元素)、zcard (获取元素个数)、zcount (获取在指定区间内的成员数量))

案例思路:set 排序 存储班级成绩表,工资表排序,排行榜应用实现
2.5 三种特殊类型
2.5.1 geospatial 地理位置
geoadd list1 经度 纬度 名称 :写入定位
geopos list1 名称 :获得当前定位
geodist list1 名称1 名称2 :两地直线距离
georadius list1 经度 纬度 半径 单位 :附近的元素
GEO底层的实现原理是Zset
2.5.2 Hyperloglog
基数统计的算法
优点:占用的内存是固定,从内存角度比较hyperloglog首选(传统的采用set统计判断用户数据)
命令( pfadd list1 xx xx ;pfcount list1 ; pfmerge list3 list1 list2 (合并到list3中))
如果允许容错,一定采用hyperloglog
如果不允许容错,使用set或者自己的数据类型即可
2.5.3 Bitmaps(位图)
操作二进制来存储,只有0,1两种状态
位存储
统计用户信息,(不)活跃,(未)登录 两个状态的,都可以使用bitmaps
命令:( setbit (记录); getbit(查看); bitcount(统计))
2.6基本事务操作
2.6.1 基础知识
redis事务本质:一组命令的集合,执行过程中,会按照顺序进行(一次性、顺序性、排他性)
原子性:要么同时成功,要么同时失败
(redis中单条命令保存原子性,但是事务不保证原子性)
事务流程:开启事务(multi)、命令入队、执行事务(exec) (放弃事务(discard))
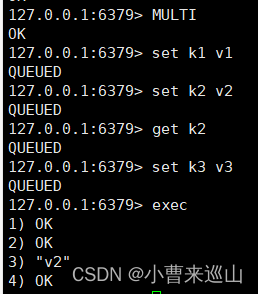
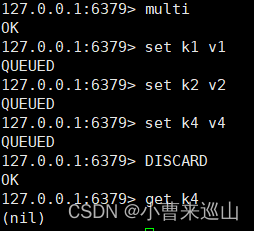
2.6.2 乐观锁
redis测监视测试(watch)
测试多线程修改值,使用watch可以当做redis的乐观锁操作 面试常问


2.7 JRedis
REDIS官方推荐的Java连接并发工具,使用java操作Redis中间件
2.7.1测试
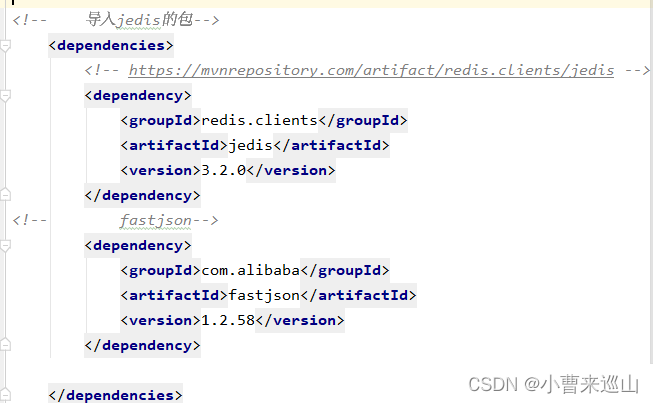
1、导入依赖
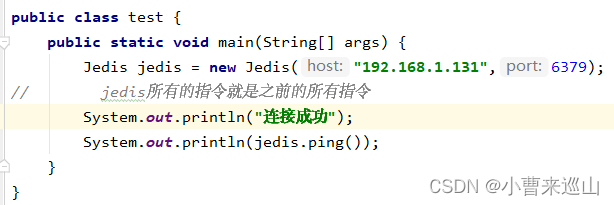
2.编码测试
连接数据库
操作命令
断开连接
2.7.2 事务(再次理解)
public static void main(String[] args) {
//创建客户端连接服务端,redis服务端需要被开启
Jedis jedis = new Jedis("192.168.1.131", 6379);
jedis.flushDB();
JSONObject jsonObject = new JSONObject();
jsonObject.put("hello", "world");
jsonObject.put("name", "java");
//开启事务
Transaction multi = jedis.multi();
String result = jsonObject.toJSONString();
try{
//向redis存入一条数据
multi.set("json", result);
//再存入一条数据
multi.set("json2", result);
//这里引发了异常,用0作为被除数
int i = 100/0;
//如果没有引发异常,执行进入队列的命令
multi.exec();
}catch(Exception e){
e.printStackTrace();
//如果出现异常,回滚
multi.discard();
}finally{
System.out.println(jedis.get("json"));
System.out.println(jedis.get("json2"));
//最终关闭客户端
jedis.close();
}
}2.8 springboot整合redis(redis-springboot)
1、导入依赖
<!--操作redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2、配置连接
#Springboot所有的配置类,都有一个自动装配类 **AutoConfiguration
#自动装配类会绑定一个 properties 配置文件 **Properties
spring.redis.host=127.0.0.1
spring.redis.port=63793、测试
@Autowired
// 这是注入在RedisAutoConfiguration中配置的类
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
//redisTemplate opsForValue操作字符串 opsForList操作List opsForGeo等
//除了基本的操作,我们常用的方法都可以通过redisTemplate操作,比如事务和基本的增删改查等
//获取连接
// RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
// connection.flushDb();
// connection.flushAll();
redisTemplate.opsForValue().set("mykey","wuhu");
System.out.println(redisTemplate.opsForValue().get("mykey"));
}![]()
4。自定义RedisTemplate
@Configuration
public class RedisConfig {
//这是固定模板,在企业中,可以直接使用
/*编写自己的配置类redisTemplate*/
@Bean
@SuppressWarnings("all")
public RedisTemplate<String , Object> redisTemplate(RedisConnectionFactory factory) {
//为了开发方便,一般直接使用<String, Object>
RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();
template.setConnectionFactory(factory);
//Json序列化配置
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
//string的序列化
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
//配置具体的序列化方式
// key采用String的序列化方式
template.setKeySerializer(stringRedisSerializer);
// hash的key也采用String的序列化方式
template.setHashKeySerializer(stringRedisSerializer);
// value序列化方式采用jackson
template.setValueSerializer(jackson2JsonRedisSerializer);
// hash的value序列化方式采用jackson
template.setHashValueSerializer(jackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
![]()
5、创建工具类,方便使用 utils包下
在真实开发中,自己封装RedisUtil ,将一些常用的方法封装,然后可以在使用的时候注入
2.9、Redis.conf详解
(仅仅是了解配置文件,不做修改)redis配置文件
在虚拟机中的usr/local/usr/Kuangshen/redis.conf中

快照(持久化,在规定的时间内,执行了可多少次操作,则可持久化到.rdb .aof)


客户端限制(clients)

2.10 Redis持久化
面试和工作的重点
redis是内存数据库,如果不将内存中的数据库状态保存到磁盘,那么一旦服务器进程退出,服务器中的数据库状态也会消失。所以redis提供了持久化功能
2.10.1 RDB
是指用数据集快照的方式半持久化模式)记录 redis 数据库的所有键值对,在某个时间点将数据写入 一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
优点: 只有一个文件 dump.rdb ,方便持久化; 容灾性好,一个文件可以保存到安全的磁盘; 性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 Redis 的高性能) ;适合大规模的数据恢复;对数据的完整性要求不高。
缺点: 数据安全性低。 RDB 是间隔一段时间进行持久化,如果持久化之间 Redis 发生故障,会发生数据丢失。所以这种方式更适合数据要求不严谨的时候;fork进程的时候,会占用一定的空间
触发机制

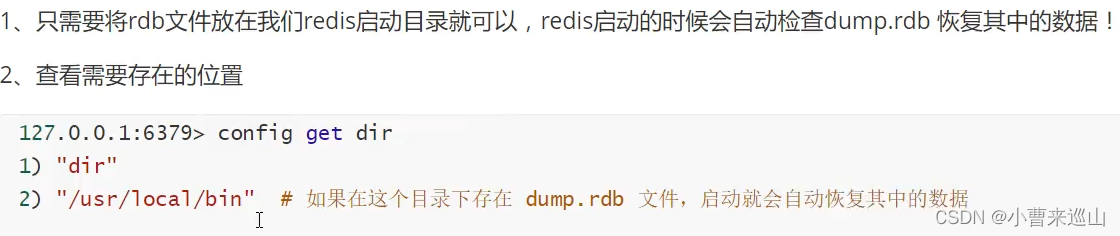
恢复rdb文件
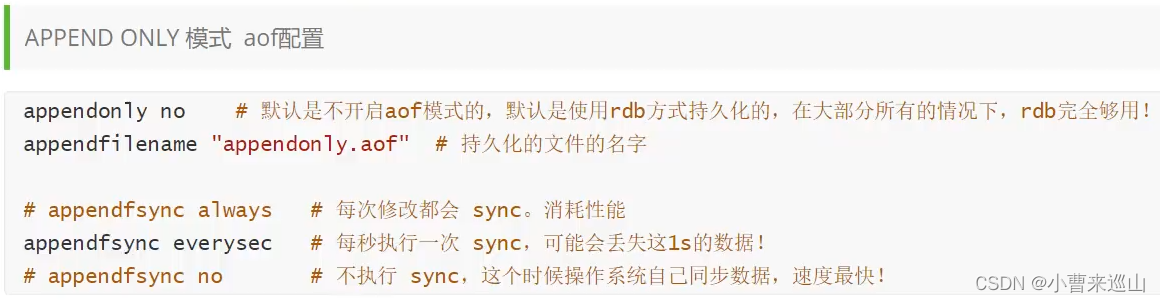
2.10.2 ROF
将所有命令记录下来,恢复的时候把文件执行一遍
aof文件出错:如果这个aof文件有错误,这时候Redis启动不了,我们需要修复这个aof文件。用redis-check-aof --fix修复 (redis-check-aof --fix appengonly.aof)
优点:
数据安全, AOF 持久化可以配置 appendfsync 属性,有 always,每进行一次命令操作就记录到 AOF 文件中一次;
缺点:
AOF 文件比 RDB 文件大,且恢复速度慢;数据集大的时候,比 RDB 启动效率低。
重写规则
如果文件大于64m,fork一个新的进程
2.11 Redis发布订阅
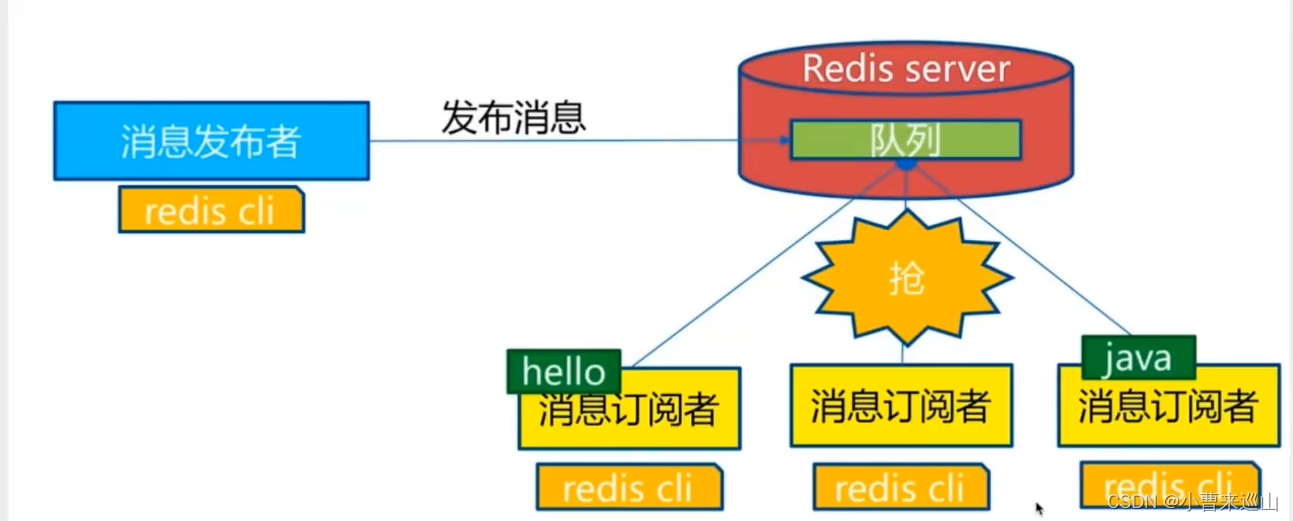
测试(publish、subscribe、psubscribe)
发送端

订阅端
使用场景
实时消息系统、实时聊天(频道当聊天室)、订阅关注系统
稍微复杂的场景会使用消息中间件MQ
2.12 Redis主从复制
一个主服务器的数据复制到其他多个从服务器;数据的复制是单向的;读写分离,80%在进行读操作
2.12.1主从复制的作用
数据冗余、故障恢复、负载均衡、高可用基石

2.12.2 环境配置(伪集群,在一台电脑上)
只配置从库,不用配置主库
1.复制3个配置文件,然后修改对应的信息(端口,pid名字,日志名称,dmp名称)
2.认主机 SLAVEOF 127.0.0.1(主机地址) 6379(主机端口)
2.12.3 细节
1、主机可以写,从机不能写只能读! 主机的信息自动被从机保存
2、主机断开连接,当主机再次连接时,从机依旧可以获取主机写的信息
3、如果命令行来配置的主从,如果重启,会变为主机!只要变为从机,一次全量复制将被自动执行
如果主机宕机了,对从机手动配置设置为主机(SLAVEOF no one)
2.12.4 哨兵模式(自动选举主机)
哨兵是独立的进程,哨兵对redis服务器发命令,让服务器返回运行状态 ;当检测主机宕机,会自动将主机切换为从机,然后通过发布订阅模式通知其他的从服务器,修改配置文件,切换主机
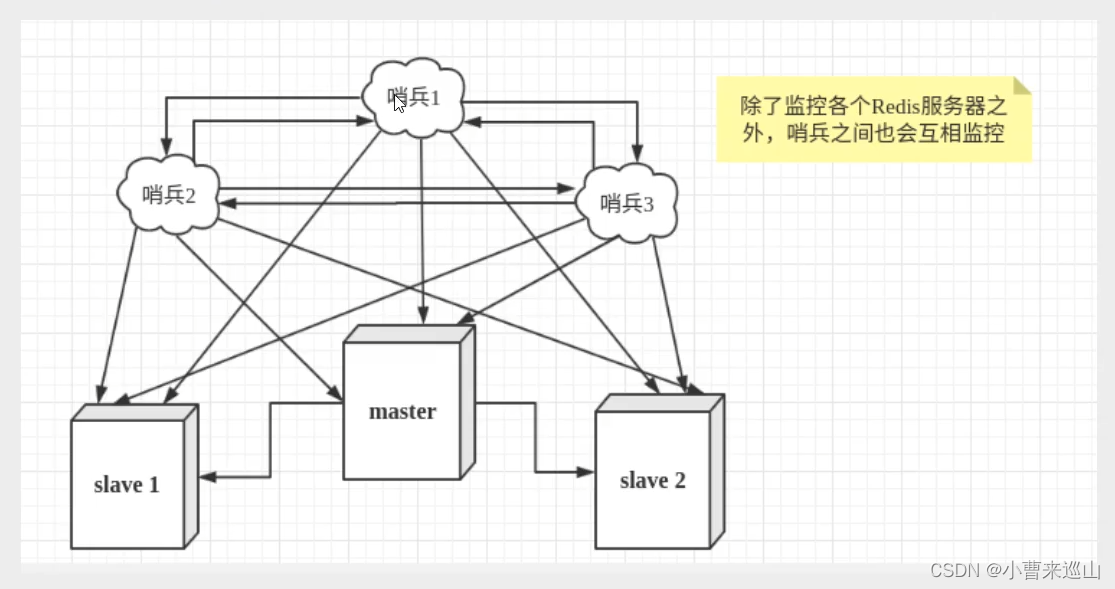
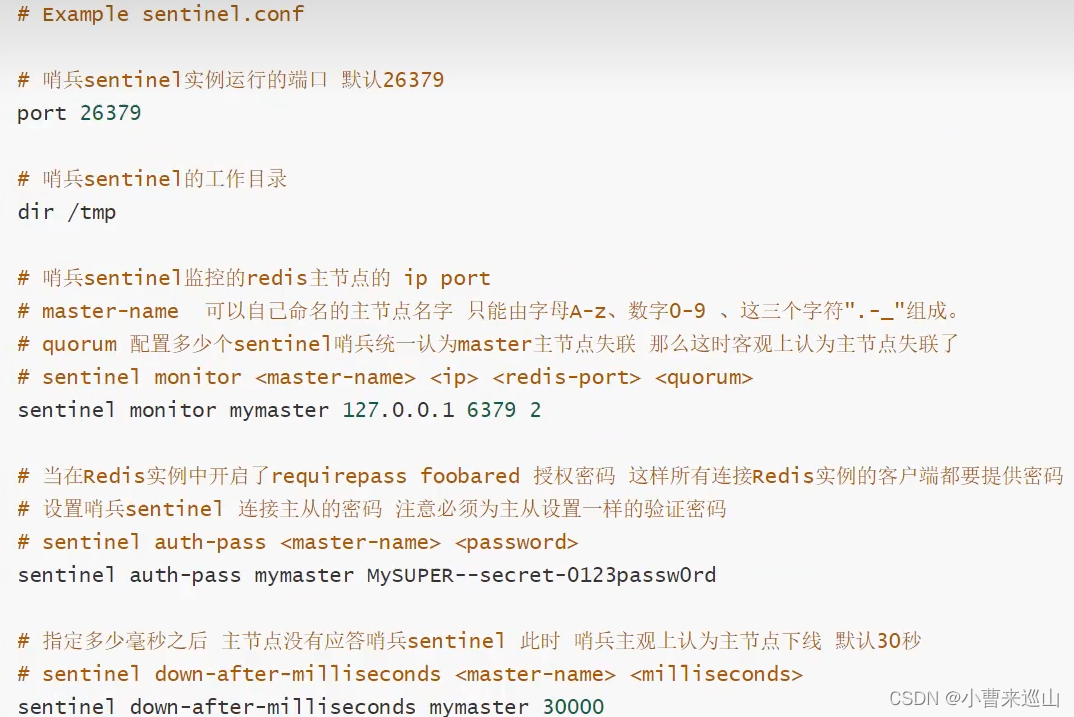
测试
1. 在Kconfig文件夹下新建sentinel.conf文件,并写入sentinel monitor myredis(被监控的名称) 127.0.0.1(host) 6379(port) 1(投票)
2.在bin目录下运行redis-sentinel Kconfig/sentinel.conf命令,打开哨兵模式
3.如果master断开,则会在从集中随机选择一个服务器(投票算法)
4.如果此时主机重新回来了,只能归并到新的主机下,当做从机
优点:

缺点:

全部配置


2.13 Redis缓存穿透和雪崩(面试高频)
2.13.1 缓存穿透(查不到导致的)

解决方案
1.布隆过滤器
2、缓存空对象
2.13.2 缓存击穿(量太大,缓存过期导致的)

解决方案
1.设置热点数据永不过期
2、加互斥锁

2.13.3 缓存雪崩


解决方案
redis高可用、限流降级、数据预热

补充:
linux:狂神说Linux02:常用的基本命令(必掌握)、狂神说Linux03:Vim使用及账号用户管理、狂神说Linux04:三种软件安装方式及服务器基本环境搭建
将springboot项目打包并在linux上运行:15、rpm安装jdk上线项目_哔哩哔哩_bilibili
打开端口、重启防火墙、查看所有开启的端口、访问















 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









