






 本文介绍了基于机器视觉的数字1-10手势识别系统,利用OpenCV进行图像处理,包括平滑处理、二值化、直方图均衡、开闭运算和轮廓提取。系统通过手势建模、特征提取(如Hu矩)和SVM训练进行识别,具有在人机交互、虚拟现实和智能家居领域的应用潜力。核心代码涉及图像处理和模型训练,为实现手势识别提供了详细的步骤和实现方法。
本文介绍了基于机器视觉的数字1-10手势识别系统,利用OpenCV进行图像处理,包括平滑处理、二值化、直方图均衡、开闭运算和轮廓提取。系统通过手势建模、特征提取(如Hu矩)和SVM训练进行识别,具有在人机交互、虚拟现实和智能家居领域的应用潜力。核心代码涉及图像处理和模型训练,为实现手势识别提供了详细的步骤和实现方法。
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着科技的不断发展,机器视觉技术在各个领域中得到了广泛的应用。其中,基于机器视觉的手势识别系统在人机交互、虚拟现实、智能家居等领域中具有重要的意义。手势识别系统可以通过识别人类的手势动作,实现与计算机的自然交互,为人们提供更加便捷、直观的操作方式。
数字1-10手势识别系统是手势识别技术中的一个重要研究方向。数字1-10是人们日常生活中常用的数字,其手势动作的识别对于人机交互和智能设备的控制具有重要意义。传统的手势识别系统通常需要使用特定的设备或传感器,如手套、摄像头等,这限制了其在实际应用中的普及。而基于机器视觉的手势识别系统则可以通过普通的摄像头来实现,无需额外的设备,大大提高了其实用性和可扩展性。
数字1-10手势识别系统的研究对于人机交互领域具有重要的意义。传统的人机交互方式主要依赖于键盘、鼠标等输入设备,操作繁琐且不直观。而通过手势识别系统,用户可以通过简单的手势动作来控制计算机或其他智能设备,实现更加自然、直观的交互方式。这不仅可以提高用户的使用体验,还可以降低学习成本,让更多的人能够轻松地使用计算机和智能设备。
此外,数字1-10手势识别系统在虚拟现实领域也具有重要的应用价值。虚拟现实技术已经在游戏、教育、医疗等领域中得到了广泛的应用。而手势识别系统可以为虚拟现实设备提供更加自然、直观的交互方式,使用户能够通过手势来控制虚拟环境中的对象和操作。这不仅可以提高虚拟现实的沉浸感和真实感,还可以扩展虚拟现实的应用场景,如虚拟手术模拟、虚拟实验室等。
此外,数字1-10手势识别系统还可以应用于智能家居领域。随着智能家居技术的快速发展,人们对于智能家居控制方式的要求也越来越高。传统的智能家居控制方式主要依赖于手机、遥控器等设备,操作繁琐且不直观。而通过手势识别系统,用户可以通过简单的手势动作来控制智能家居设备,如调节灯光、控制电视等。这不仅可以提高智能家居的便捷性和智能化程度,还可以为老年人和残障人士提供更加友好的家居控制方式。
综上所述,基于机器视觉的数字1-10手势识别系统在人机交互、虚拟现实、智能家居等领域中具有重要的意义。其研究和应用将为人们提供更加便捷、直观的操作方式,提高用户的使用体验,推动科技的进步和社会的发展。因此,对于数字1-10手势识别系统的研究具有重要的理论和实践价值。
2.图片演示



3.视频演示
基于机器视觉的数字1-10手势识别系统_哔哩哔哩_bilibili
4.系统流程图
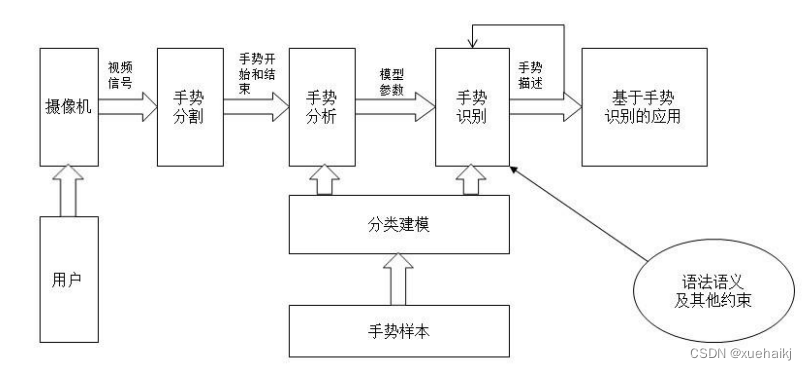
本文中基于视觉的手势识别系统的总体结构如图所示。首先,通过摄像头等图像采集设备进行数据采集,某些系统里可能会有多个采集设备;接着系统对采集到的数据进行检测,分析其中是否有手势图像,如果出现了手势图像,就将其从原始图像中分割出来;然后,对分割后的图像进行参数估计和特征检测,得到的数据供后续的工作使用;最后是手势识别,根据上面计算得到的特征参数对输入的手势图像进行分类识别;最终根据用户的需求将输出结果用于具体的应用程序。
本章从手势建模和预处理、手势分割特征检测以及手势识别等三个方面介绍手势识别系统的总体技术,同时对各个功能模块所对应的算法进行简单的介绍以及比较分析,阐述本文所采用的系统流程及原理。
5.核心代码讲解
5.1 getmaxminframes.py
class VideoConverter:
def __init__(self):
self.hc = []
def convert(self, dataset):
fcount = []
count = 0
rootPath = os.getcwd()
majorData = os.path.join(os.getcwd(), "majorData")
if (not exists(majorData)):
os.makedirs(majorData)
dataset = os.path.join(os.getcwd(), dataset)
os.chdir(dataset)
x = os.listdir(os.getcwd())
for gesture in x:
adhyan = gesture
gesture = os.path.join(dataset, gesture)
os.chdir(gesture)
frames = os.path.join(majorData, adhyan)
if(not os.path.exists(frames)):
os.makedirs(frames)
videos = os.listdir(os.getcwd())
videos = [video for video in videos if(os.path.isfile(video))]
for video in videos:
count = count+1
name = os.path.abspath(video)
print name
cap = cv2.VideoCapture(name) # capturing input video
frameCount = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print frameCount
fcount.append((frameCount, video))
# fname.append(video)
os.chdir(gesture)
cap.release()
cv2.destroyAllWindows()
os.chdir(rootPath)
fcount.sort(key=lambda x: x[0], reverse=True)
f = open("out.txt", "wb")
for (a, b) in fcount:
x = str(a)+" : "+b
print x
f.write(x+"\n")
f.close()
这个程序文件名为getmaxminframes.py,主要功能是将指定文件夹中的视频文件转换成帧,并计算每个视频文件的帧数。具体的代码如下:
- 导入所需的库:cv2用于处理视频文件,os用于操作文件和文件夹路径,exists用于判断文件夹是否存在。
- 定义一个空列表hc用于存储视频文件的帧数。
- 定义一个函数convert,参数为dataset,用于处理指定文件夹中的视频文件。
- 初始化变量fcount和count,分别用于存储帧数和计数。
- 获取当前工作目录的路径,并创建一个名为majorData的文件夹。
- 将dataset的路径设置为当前工作目录,并获取该文件夹下的所有文件和文件夹的名称。
- 遍历每个手势文件夹。
- 将手势文件夹的路径设置为当前工作目录,并创建一个名为frames的文件夹。
- 获取当前文件夹下的所有视频文件,并将其存储在videos列表中。
- 遍历每个视频文件。
- 计数器count加1。
- 获取视频文件的绝对路径,并打开该视频文件。
- 获取视频文件的帧数,并将其存储在frameCount变量中。
- 将帧数和视频文件名添加到fcount列表中。
- 释放视频文件的资源,并关闭所有窗口。
- 返回到手势文件夹的上一级目录。
- 返回到根目录。
- 根据帧数对fcount列表进行降序排序。
- 打开一个名为out.txt的文件,以二进制写入模式。
- 遍历fcount列表中的每个元素,将帧数和视频文件名以字符串的形式写入文件中。
- 关闭文件。
最后,调用convert函数,参数为"test/",即处理名为"test"的文件夹中的视频文件。
5.2 handsegment.py
class HandSegmentation:
def __init__(self):
self.boundaries = [
([0, 120, 0], [140, 255, 100]),
([25, 0, 75], [180, 38, 255])
]
def segment(self, frame):
lower, upper = self.boundaries[0]
lower = np.array(lower, dtype="uint8")
upper = np.array(upper, dtype="uint8")
mask1 = cv2.inRange(frame, lower, upper)
lower, upper = self.boundaries[1]
lower = np.array(lower, dtype="uint8")
upper = np.array(upper, dtype="uint8")
mask2 = cv2.inRange(frame, lower, upper)
mask = cv2.bitwise_or(mask1, mask2)
output = cv2.bitwise_and(frame, frame, mask=mask)
return output
if __name__ == '__main__':
hand_segmentation = HandSegmentation()
frame = cv2.imread("test.jpeg")
hand_segmentation.segment(frame)
这个程序文件名为handsegment.py,主要功能是对输入的图像进行手部分割。程序使用了OpenCV库和NumPy库。
程序首先定义了一个boundaries列表,其中包含了两个颜色范围。这些颜色范围用于识别手部的颜色。
然后定义了一个handsegment函数,该函数接受一个图像帧作为输入。函数首先使用第一个颜色范围来创建一个掩膜mask1,然后使用第二个颜色范围创建一个掩膜mask2。接下来,使用位运算符将两个掩膜合并为一个掩膜mask。最后,使用位与运算符将原始图像帧和掩膜mask进行合并,得到输出图像output。
在程序的主函数中,读取了一个名为test.jpeg的图像,并将其作为参数传递给handsegment函数。
程序的注释部分是一种替代的实现方式,使用了循环来处理boundaries列表中的每个颜色范围,但是该部分被注释掉了。
整体来说,这个程序文件实现了手部分割的功能,可以根据颜色范围来识别图像中的手部,并将手部区域提取出来。
5.3 hog.py
class HOGFeatureExtractor:
def __init__(self, orientations=10, pixels_per_cell=[12, 12], cells_per_block=[4, 4]):
self.orientations = orientations
self.pixels_per_cell = pixels_per_cell
self.cells_per_block = cells_per_block
def get_hog_skimage(self, img, visualize=False):
features = ft.hog(img, orientations=self.orientations, pixels_per_cell=self.pixels_per_cell,
cells_per_block=self.cells_per_block, visualize=visualize, transform_sqrt=True)
return features
def build_hog_data(self, folder_path):
train_data = []
test_data = []
for filename in tqdm(os.listdir(folder_path)):
img = cv2.imread(folder_path + "\\" + filename, 0)
img_hog = self.get_hog_skimage(img)
if filename.find('train') != -1:
train_data.append(img_hog)
else:
test_data.append(img_hog)
train_data = np.array(train_data)
test_data = np.array(test_data)
return train_data, test_data
这个程序文件名为hog.py,它包含了一些函数用于提取图像的HOG特征。具体功能如下:
-
get_hog_skimage函数:使用skimage库中的hog函数提取图像的HOG特征。它接受一个灰度图像作为输入,并可以设置一些参数,如bin的个数、每个cell的大小、每个block中含有多少cell等。如果设置了visualize参数为True,则可以输出HOG图像;否则,返回一维向量表示的HOG特征。 -
build_hog_data函数:该函数用于获取指定文件夹下所有图片的HOG特征。它接受一个文件夹路径作为输入,并遍历该文件夹下的所有图片文件。对于每个图片文件,首先使用cv2.imread函数读取为灰度图像,然后调用get_hog_skimage函数提取HOG特征。根据文件名中是否包含"train"来判断是训练数据还是测试数据,并将HOG特征添加到相应的列表中。最后,将训练数据和测试数据转换为NumPy数组并返回。
总体来说,这个程序文件提供了一种使用skimage库提取图像HOG特征的方法,并提供了一个函数用于获取指定文件夹下所有图片的HOG特征。
5.4 loadpicklefileanddisplay.py
class DataPrinter:
def __init__(self, file_path):
self.file_path = file_path
def print_data(self):
x = pickle.load(open(self.file_path, 'rb'))
print("Length", len(x))
print(x[0])
print("Press y to print all data and n to exit")
t = input()
if t == 'y':
for each in x:
print(each)
这个程序文件名为loadpicklefileanddisplay.py,它的功能是加载一个pickle文件并显示其中的数据。
程序首先导入了sys和pickle模块。然后,它使用pickle.load函数加载了一个pickle文件,该文件的路径由命令行参数sys.argv[1]指定。加载的数据被赋值给变量x。
接下来,程序打印出变量x的长度,即数据的数量。然后,它打印出x中的第一个元素。
程序接着提示用户输入一个字符,如果输入的字符是’y’,则程序会遍历x中的每个元素,并将其打印出来。
总结起来,这个程序的功能是加载pickle文件并显示其中的数据。用户可以选择是否打印出所有的数据。
5.5 predict_spatial.py
class FramePredictor:
def __init__(self, model_file, frames_folder, input_layer='Placeholder', output_layer='final_result', batch_size=10):
self.model_file = model_file
self.frames_folder = frames_folder
self.input_layer = input_layer
self.output_layer = output_layer
self.batch_size = batch_size
def load_graph(self):
graph = tf.Graph()
graph_def = tf.GraphDef()
with open(self.model_file, "rb") as f:
graph_def.ParseFromString(f.read())
with graph.as_default():
tf.import_graph_def(graph_def)
return graph
def read_tensor_from_image_file(self, frames, input_height=299, input_width=299, input_mean=0, input_std=255):
input_name = "file_reader"
frames = [(tf.read_file(frame, input_name), frame) for frame in frames]
decoded_frames = []
for frame in frames:
file_name = frame[1]
file_reader = frame[0]
if file_name.endswith(".png"):
image_reader = tf.image.decode_png(file_reader, channels=3, name="png_reader")
elif file_name.endswith(".gif"):
image_reader = tf.squeeze(tf.image.decode_gif(file_reader, name="gif_reader"))
elif file_name.endswith(".bmp"):
image_reader = tf.image.decode_bmp(file_reader, name="bmp_reader")
else:
image_reader = tf.image.decode_jpeg(file_reader, channels=3, name="jpeg_reader")
decoded_frames.append(image_reader)
float_caster = [tf.cast(image_reader, tf.float32) for image_reader in decoded_frames]
float_caster = tf.stack(float_caster)
resized = tf.image.resize_bilinear(float_caster, [input_height, input_width])
normalized = tf.divide(tf.subtract(resized, [input_mean]), [input_std])
sess = tf.Session()
result = sess.run(normalized)
return result
def load_labels(self, label_file):
label = []
proto_as_ascii_lines = tf.gfile.GFile(label_file).readlines()
for l in proto_as_ascii_lines:
label.append(l.rstrip())
return label
def predict(self, graph, image_tensor):
input_name = "import/" + self.input_layer
output_name = "import/" + self.output_layer
input_operation = graph.get_operation_by_name(input_name)
output_operation = graph.get_operation_by_name(output_name)
with tf.Session(graph=graph) as sess:
results = sess.run(
output_operation.outputs[0],
{input_operation.outputs[0]: image_tensor}
)
results = np.squeeze(results)
return results
def predict_on_frames(self):
input_height = 299
input_width = 299
input_mean = 0
input_std = 255
batch_size = self.batch_size
graph = self.load_graph()
labels_in_dir = os.listdir(self.frames_folder)
frames = [each for each in os.walk(self.frames_folder) if os.path.basename(each[0]) in labels_in_dir]
predictions = []
for each in frames:
label = each[0]
print("Predicting on frame of %s\n" % (label))
for i in tqdm(range(0, len(each[2]), batch_size), ascii=True):
batch = each[2][i:i + batch_size]
try:
batch = [os.path.join(label, frame) for frame in batch]
frames_tensors = self.read_tensor_from_image_file(batch, input_height=input_height, input_width=input_width, input_mean=input_mean, input_std=input_std)
pred = self.predict(graph, frames_tensors)
pred = [[each.tolist(), os.path.basename(label)] for each in pred]
predictions.extend(pred)
except KeyboardInterrupt:
print("You quit with ctrl+c")
sys.exit()
except Exception as e:
print("Error making prediction: %s" % (e))
x = input("\nDo You Want to continue on other samples: y/n")
if x.lower() == 'y':
continue
else:
sys.exit()
return predictions
def run(self):
# reduce tf verbosity
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
predictions = self.predict_on_frames()
out_file = 'predicted-frames-%s-%s.pkl' % (self.output_layer.split("/")[-1], train_or_test)
print("Dumping predictions to: %s" % (out_file))
with open(out_file, 'wb') as fout:
pickle.dump(predictions, fout)
print("Done.")
这个程序文件是一个用于预测空间数据的Python脚本。它使用TensorFlow库来加载预训练的模型,并对给定的图像帧进行预测。以下是脚本的主要功能:
- 导入所需的库和模块。
- 定义了一些辅助函数,如加载图像帧、加载标签、预测等。
- 定义了一个函数
predict_on_frames,用于在给定的图像帧文件夹中进行预测。 - 解析命令行参数,包括模型文件、图像帧文件夹、输入层名称、输出层名称和批处理大小。
- 调用
predict_on_frames函数进行预测,并将预测结果保存到pickle文件中。
总体而言,这个程序文件是一个用于预测空间数据的脚本,它可以根据给定的图像帧和预训练模型进行预测,并将结果保存到文件中。
5.6 trainSVM.py
class SVM:
def __init__(self):
self.X = []
self.Y = []
self.classifier = None
def load_data(self):
for i in range(0, 2):
for f in os.listdir("C:/Users/15690/Desktop/800SVM/code/datasets/images/%s" % i):
Images = cv2.imread("C:/Users/15690/Desktop/800SVM/code/datasets/images/%s/%s" % (i, f))
image = cv2.resize(Images, (256, 256), interpolation=cv2.INTER_CUBIC)
hist = cv2.calcHist([image], [0, 1], None, [256, 256], [0.0, 255.0, 0.0, 255.0])
self.X.append(((hist / 255).flatten()))
self.Y.append(i)
print(str(((hist / 255).flatten())) + ' ' + str(i))
self.X = np.array(self.X)
self.Y = np.array(self.Y)
def train(self):
cv = StratifiedKFold(n_splits=10)
self.classifier = svm.SVC(kernel='rbf', gamma=0.0001, C=1000, probability=True, random_state=0)
mean_tpr = 0.0
mean_fpr = np.linspace(0, 1, 100)
cnt = 0
for i, (train, test) in enumerate(cv.split(self.X, self.Y)):
cnt += 1
probas_ = self.classifier.fit(self.X[train], self.Y[train]).predict_proba(self.X[test])
fpr, tpr, thresholds = roc_curve(self.Y[test], probas_[:, 1])
mean_tpr += np.interp(mean_fpr, fpr, tpr)
mean_tpr[0] = 0.0
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, lw=1, label='ROC fold {0:.2f} (area = {1:.2f})'.format(i, roc_auc))
plt.plot([0, 1], [0, 1], '--', color=(0.6, 0.6, 0.6), label='Luck')
mean_tpr /= cnt
mean_tpr[-1] = 1.0
mean_auc = auc(mean_fpr, mean_tpr)
plt.plot(mean_fpr, mean_tpr, 'k--', label='Mean ROC (area = {0:.2f})'.format(mean_auc), lw=2)
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
def save_model(self):
os.chdir("./save_model")
joblib.dump(self.classifier, "train_model.m")
这个程序文件是用来训练支持向量机(SVM)模型的。程序首先导入了必要的库和模块,然后读取了一组图片数据,并对图片进行了预处理和特征提取。接下来,程序使用交叉验证和ROC曲线评估了SVM模型的性能,并绘制了平均ROC曲线。最后,程序保存了训练好的模型。
6.系统整体结构
整体功能和构架概括:
这个项目是一个基于机器视觉的数字1-10手势识别系统。它包含了多个程序文件,每个文件都有不同的功能,共同构建了整个系统。以下是每个文件的功能的整理:
| 文件名 | 功能概述 |
|---|---|
| getmaxminframes.py | 将指定文件夹中的视频文件转换成帧,并计算每个视频文件的帧数 |
| handsegment.py | 对输入的图像进行手部分割 |
| hog.py | 提取图像的HOG特征 |
| loadpicklefileanddisplay.py | 加载pickle文件并显示其中的数据 |
| predict_spatial.py | 预测空间数据,使用预训练的模型对给定的图像帧进行预测 |
| trainSVM.py | 训练支持向量机(SVM)模型 |
| ui.py | 用户界面,用于交互和展示手势识别系统 |
以上是每个文件的功能概述,它们共同构成了基于机器视觉的数字1-10手势识别系统。
7.手势建模
手势模型对于手势识别来说十分重要,因为模型的好坏关系到识别范围的确定。一般来说,模型会根据用户具体的需求来进行选取,如果手部动作较为简单,不涉及到复杂的手指变化,一般采用简单的模型就能满足需求,如果手部动作复杂,有各种细节的描述,则需要进行精确的建模。目前基本有两类手势建模的方法:基于表观的手势建模和基于3D模型的手势建模R:基于表观的手势建模是建立在人手图像的表观之上的,通过分析具体手势的表观特征来进行建模;基于3D模型的手势建模则考虑到了具体手势产生的中间媒体,例如手和手臂。图对描述了手势模型的具体分类。
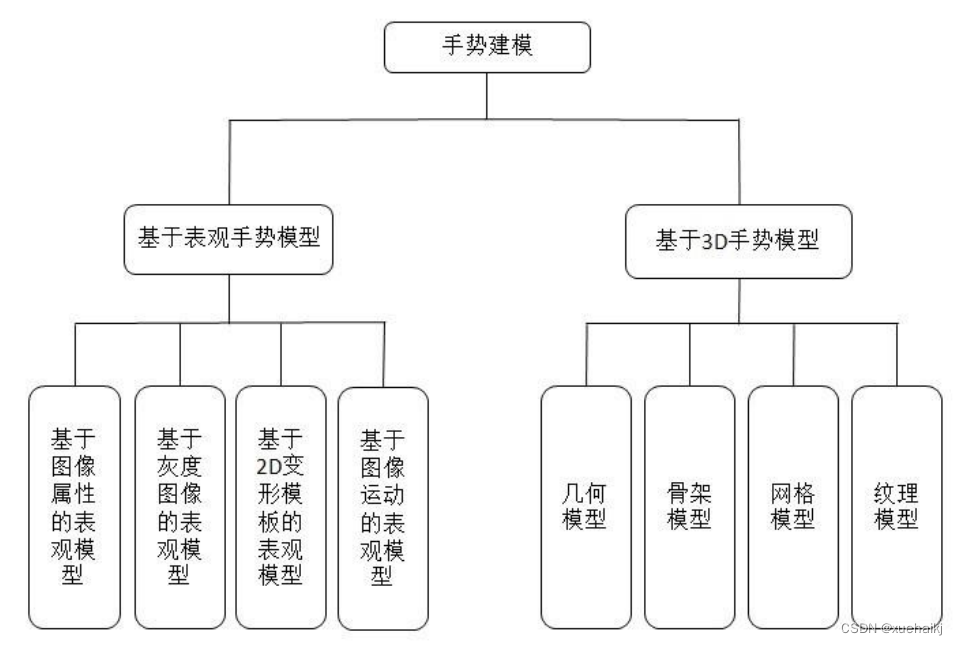
基于3D的手势模型可以分为四类:几何模型,骨架模型,网格模型和纹理模型[10]。各个模型对应不同的应用场合,例如,骨骼模型主要用于跟踪和识别身体的姿势,几何模型适合于对实时性要求较高的系统等。使用3D模型时通常会碰到两个问题:首先,模型参数空间的维数比较高,计算上会比较复杂;其次,通过视觉技术来检测模型的参数难度将会比较大,并且过程复杂。
基于表观的手势模型同样也可以分为四类:基于灰度图像本身手势模型,基于图像属性的表观模型,基于2D变形模板的表观模型以及基于图像运动的表观模型。基于表观的手势模型相对而言更加简单,使用较少的信息表达出用户需要的描述的信息。同样,各个模型也适用于不同的情况,如基于图像运动的表观模型一般用于识别动态手势图像,本文中选择的是基于灰度图像的表观模型。
8.手势图像的输入及预处理
图像的平滑处理
图像的平滑处理也称作模糊处理,是一项简单且使用频率很高的图像处理方法。使用平滑处理有多种用途,最常见的是用来减少图像上的噪声和失真。降低图像分辨率时,平滑处理尤其重要。平滑处理有多种方法:第一种,局部平均法,这种方法原理是直接在空域上进行平滑处理,使用这种方法时,我们把图像看作是由若干个灰度不变的小块组成,互相之间空间相关性很高,但是噪声的统计则是独立的。因此,我们利用每一个像素相邻的8个像素的灰度的均值来代替这个像素原来的灰度值,这样逐个像素处理以后,整幅图像就有了平滑的效果。比较常用的局部平均法有:非加权邻域平均,这种方法对每个邻域中的像素所给的权值都一样,全部对等看待,因此该算法计算速度快,算法较简单,但是也会在降噪的同时使得图像在边界和细小处变得模糊,对其改进后的方法有超限像素平滑法、梯度倒数加权法、灰度最相近的N个相邻点平均法以及自适应滤波法等等。第二种,中值滤波法,中值滤波其实也是局部平均法的一种,它的特点主要是是针对脉冲干扰和椒盐进行抑制减噪,其效果比较好,同时在抑制随机噪声过程中,能使边沿减少模糊。中值滤波法是一种非线性的图像平滑方法,它使用一个滑动窗口,对窗口中的各个像素根据其灰度值进行排序,取这些灰度的平均值,再平均值代替窗口中心像素原
来的灰度值。中值滤波与局部平均法进行比较,其有以卜优点:R得底能使图佟边明显;如果图像中像素灰度值变化较小,其平滑处理的效果可以很好f;能使图像边沿的模糊程度得到降低。第三种,频域平滑技术,上面介绍的平滑处理是在空域中
进行的,在频域中同样也可以进行平滑处理。在频域中进行平滑处理,即将一维信号低通滤波器推广在二维图像中。我们采用二维傅里叶变换对输入图像处理大多数噪声频谱都分布在空间频域的较高区域,而图像有用区域的频谱分量空间频域较低的区域内,因此可以采用低通滤波器,这样高频的分量就会被阻拦,我们需要的图像本身低频分量就会保留,这样就实现了图像的平滑处理。
二值化处理
完成了许多针对图像的处理后,我们通常需要对图像中的像素做出最后的决策,直接剔除一些高于或者低于某个定值的像素,这个过程即将灰度图转化为二值图像。
设图像f(x,y)的灰度值范围在[a,b],二值化阀值设为H(a<H<b),则二值化处理的一般方式为:
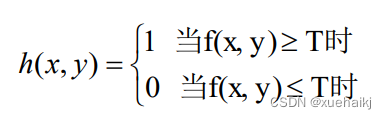
h(x,y)是二值图像,我们在这里用1来表示对象物体,用0来表示背景区域。对于阀值T的选择有多种方法,它的值决定了处理以后的图像的质量对图像二值化方法进行简单的分类则一般可以分为两种:整体阀值二值化和局部阀值二值化。
图像的整体阀值二值化方法,即对整幅图像只设置一个固定的阀值,将所有像素与其比较,若像素灰度小于阀值,则标记为物体,大于阀值就为背景。这种方法的优点是计算速度比较快,对对比度高质量高的图像,尤其是对于背景较为简单的图像而言,其处理效果很好,但是对于背景复杂的图像,特别是前景像素和背景像素灰度值区别不明显,互相之间都有相互交叉的,固定阀值就不太适合了。若外界亮度发生变化时,固定阀值也会变得与图像最佳处理效果不符。
直方图均衡
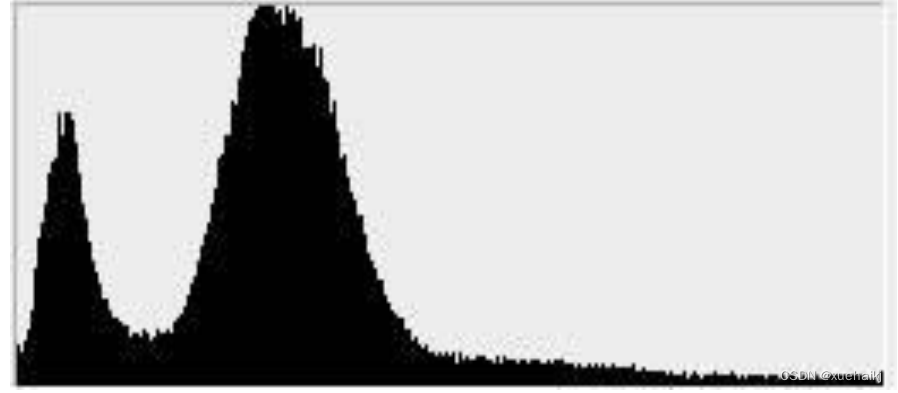
由于人工设定阀值总会偏离最佳的处理效果,因此我们可以根据图像的灰度直方图来进行阀值的选择,这是一种自动确定阀值的方法。灰度直方图是对图像的所有像素的灰度分布按灰度值的大小显示其出现频率的统计图。通常,横轴表示灰度值,纵轴表示频率,频率即某一灰度值的像素在图像中出现的次数。对于手势图像来说,手部的像素和背景的像素集中了很多像素,因此在直方图上会有两个山峰形的分布。一个峰值对应于手,另一个对应于背景。山峰之间的谷底就是通常选择作为阀值的值,谷底越深二值化的效果越好。一个灰度直方图的示例图如下图所示:
开运算和闭运算
在研究开运算和闭运算之前,我们先介绍图像的膨胀和腐蚀。参考文献[8]中详细介绍了腐蚀与膨胀的原理,简单来说,腐蚀得到的是原图像的子集,即腐蚀具有收缩图像的作用,膨胀则是腐蚀的对偶运算,膨胀式利用结构元素对输入图像进行扩充,膨胀可以填充图像中小于结构元素的洞。了解了图像的膨胀和腐蚀以后,我们再来研究开运算和闭运算。
一般研究发现,如果对一副图像先进行腐蚀,再进行膨胀,会有一个特别的效果,得到的图像往往不是原始图像本身,而比原始图像要简单。这个操作就称作开运算。腐蚀操作会去掉物体的边缘点,细小物体所有的点都会被认为是边缘点,因此会整个被删去。再做膨胀时,留下来的大物体会变回原来的大小,而被删除的小物体则永远消失了。开运算会去除小的明亮区域,剩余的明亮区域将被隔离,但是其大小不变。
闭运算则是先对图像进行膨胀,再进行腐蚀。用来填充物体内细小空洞、连接邻近物体、平滑其边界的同时并不明显改变其面积。通常,由于噪声的影响,图像在阈值化后所得到边界往往是很不平滑的,物体区域具有一些噪声孔,背景区域上散布着一些小的噪声物体。连续的开和闭运算可以有效地改善这种情况。
有时需要经过多次腐蚀之后再加上相同次数的膨胀,才可以产生比较好的效果。
针对本文中的二值化手势图像,存在一定的粗糙边缘以及内部的空洞,可以适当的选择适当的开运算、闭运算进行消除。处理以后的效果会得到优化,对后续的特征检测更有帮助。我们调用的是cvErode()和 cvDilate()函数实现上述变化的。cvErode()是对图像进行腐蚀操作,函数形式:
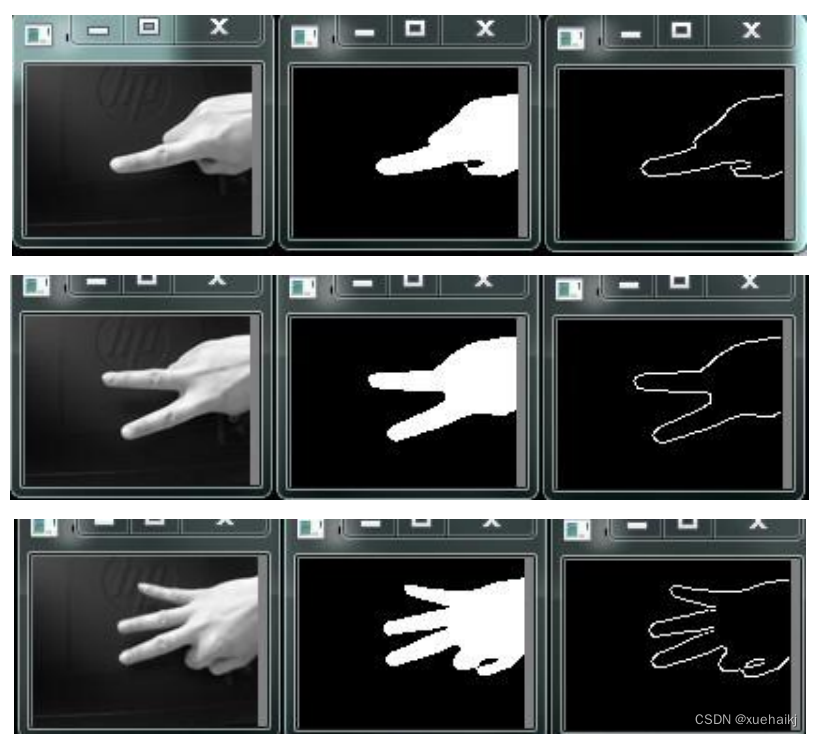
轮廓提取
通过Canny之类的边缘检测算法可以根据像素之间的差异检测出轮廓边界的像素,但是它并没有将轮廓作为一个整体,在上图中可以明显看出。下一步是要把这些边缘像素组合成轮廓,这就是轮廓提取的目标。
由于边缘检测是并行处理得到的,所以其结果一般不连续,针对轮廓提取我们则会选择一种串行的检测技术得到一个连续的输出结果。下面介绍一种常见的方法,采用Freeman 链码的八邻域搜索法。在 Freeman 链码中,多边形被表示为一系列的位移,每一个位移有八个方向可以选择,用0-7表示:
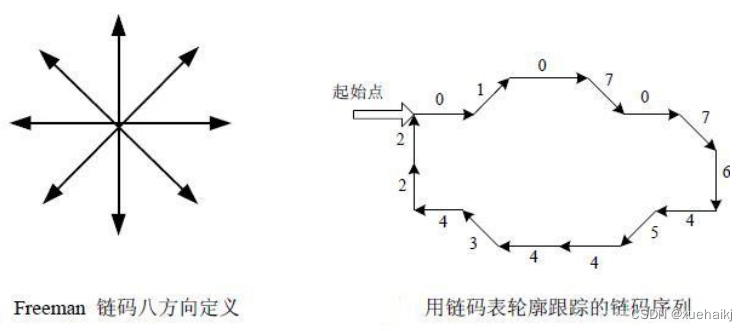
图像中的每一个像素都会有8个相邻像素,即所谓八邻域点,如果当前像素点p(x,y)为边界像素点,则对其相邻八个像素点按次序扫描,下一个边界点一定在其中。具体算法步骤即,首先,边缘检测已经分理处了背景与物体,定义背景像素为0,物体像素为1,同时设置d为八邻域像素点的位置编码,对图像进行自上而下,自左向右的扫描,将第一个值为1的像素点作为算法的开始点,取d=5进行下一个边界点的搜索;从d开始按逆时针方向依次检车当前点的八邻域像素点,第一次出现值为1的点,该点就是新的边界点,记录下其位置编码的 d1,存入序列结构中;由于八邻域算法是一个串行的算法,得到的是一个连续封闭的轮廓,即最后一定会回到起始点,故将上述步骤重复,若d1回到了初始点,则搜索结束,输出结果。
本文中根据实际情况选择的 Canny边缘检测对二值化图像进行处理,采用八邻域轮廓提取的方法提取手势的轮廓矩阵。
Hu 矩的提取
Hu矩有着明确的物理和数学意义,低阶矩一般描述的是图像的整体特征,例如面积、方向、主轴等等;高阶矩则一般描述的是图像的细节部分的特征,例如扭曲度、峰态等等。
零阶矩描述的是图像的面积,一阶矩描述的是图像的重心,二阶矩也被称作惯性矩,其有三个分量。这三个矩通常被作为低阶矩。低阶矩所描述的图像特征值一般反映了图像中物体的旋转半径、主轴方向以及图像椭圆这些特征。
三阶以上的矩通常称为高阶矩,一般描述的是图像中物体的细节部分。三阶矩所描述的是目标的扭曲程度;四阶矩描述的是一个分布的峰态,当所描述的峰态值为负数时,其分布的函数图象看起来就比较平缓,反之,则表示峰值比较高并且分布变化比较大。这七个Hu矩向量值中,Hul到Hu6具有镜像不变性,而I,在镜像变换中变为-I,。Hu矩向量由于其特殊的数学特性,在描述物体的形态特征中有着明显的优点,因此被广泛使用在在边缘提取、图像匹配及目标识别等过程中[3]。
本文中,在程序中计算Hu矩向量,主要运用了cvGetHuMoments()函数,计算Hu矩变量的部分伪代码如下:


9.结果分析
针对上述10种手势,分别进行多次采样,这里我们分别采集30张图像,然后经过处理后取其特征向量的平均值作为样本,将待识别的图像特征向量与其进行计算,就可得到最接近的手势了。我们采用的是Hu矩向量作为特征值,程序中检测了每一个矩向量的值,最后的样本均值如下:
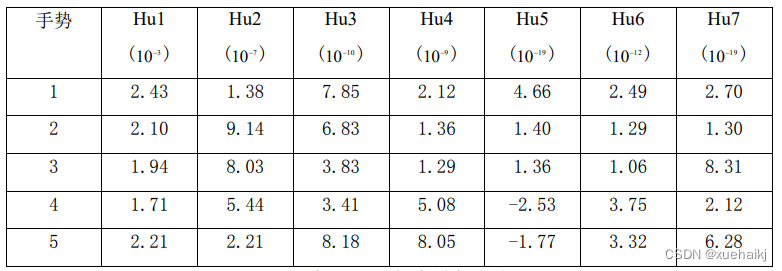
表4-1中,Hu4、Hu5、Hu6以及Hu7的值均有不同程度的误差,我们通过分析后得出结论:高阶矩是基于三阶或者以上的构造得到的,对于物体的旋转、平移和缩放具有不变性,但是因为高阶矩对于待识别图像的误差和一些细小的噪声或者小的变形来说,其敏感程度比较高,容易出现各种数值上的误差,因此,构造出来的Hu4、Hu5、Hu6以及 Hu7的值对于物体的识别准确率会有一些偏差,而Hu1、Hu2、Hu3等低阶矩则会有较好的稳定性,误差相对较小,在向量数值上更加的准确。我们从另外一个方面来分析,我们发现表中 Hul、Hu2、Hu3、Hu4、Hu5、Hu6以及Hu7的值,其数量级分别为十的-3、-7、-10、-9、-19、-12和-19,因此,我们可以明显得出后三个变量的值其数量级要比前面几个低出很多,对于结果的影响很小,如果从计算效率上来考虑的话,其结果可以忽略不计。
由于各个变量的值都比较小,为了体现出变量变化对结果的影响,我们可以对其进行归一化处理,得出的结果更加便于分析。归一化即在О到1的范围内选取合适的值反映原值在取值空间中的比例。
从整体上观察各个特征变量的值,这七个特征参数之间的差别还是比较明显的,相互之间有一定的区分度,因此,它们作为特征参数都是有一定的有效性的,我们选取这些值作为特征参数对于识别系统而言是可行的。
我们针对这五个手势分别进行了30次识别,分别选择的是手背向上和手心向上的输入图像,如图4.3所示,识别以后的结果以手势5为例,手背向上的图像30个输入图像识别出28个,手心向上的图像30个输入图像识别出22个,根据实验结果我们可以发现手心向上的图像明显识别率比较低,分析结果,我们得出的结论,第一,背景图像对于识别的影响很大,手心向上图像的背景相对而言对比度比较低,有光线的照射,背景呈现出多种亮度,这样,背景中会有一些区域接近肤色的亮度,会对预处理阶段以及图像分割阶段的轮廓提取造成影响;第二,摄像头自带的亮度调节功能对亮度的变化比较敏感,通过摄像头获取的图像质量与摄像头直接相关,如果选用高质量的摄像头能够对目标物体亮度进行有选择性的突出,降低背景的颜色亮度,则能够提高识别的效果。
除了同一手势的不同背景识别效果不同之外,不同手势的识别率也会有不同,较简单的手势如手势5,手势4识别率较高,这是因为某些简单手势特征比较明显,能够很直观的与其他手势或者噪声进行区分,因此识别率比较稳定。
总体来说,在不同背景下不同的手势都有较为可观的识别效果,在实时性方面,系统的处理速度会因不同的输入图像而异,但总体来说实时性效果均不错。
10.系统整合

11.参考文献
[1]潘建生.浅谈手势识别在人机交互中的应用[J].电脑知识与技术.2011,(35).DOI:10.3969/j.issn.1009-3044.2011.35.084 .
[2]刘丽,匡纲要.图像纹理特征提取方法综述[J].中国图象图形学报A.2009,(4).
[3]肖志勇,秦华标.基于视线跟踪和手势识别的人机交互[J].计算机工程.2009,(15).DOI:10.3969/j.issn.1000-3428.2009.15.069 .
[4]印勇,张毅,刘丹平.基于改进Hu矩的异常行为识别[J].计算机技术与发展.2009,(9).DOI:10.3969/j.issn.1673-629X.2009.09.025 .
[5]杜友田,陈峰,徐文立,等.基于视觉的人的运动识别综述[J].电子学报.2007,(1).DOI:10.3321/j.issn:0372-2112.2007.01.017 .
[6]路凯,李小坚,周金祥.基于肤色和边缘轮廓检测的手势识别[J].北方工业大学学报.2006,(3).DOI:10.3969/j.issn.1001-5477.2006.03.003 .
[7]崔政,李壮.两种改进的模板匹配识别算法[J].计算机工程与设计.2006,(6).DOI:10.3969/j.issn.1000-7024.2006.06.056 .
[8]夏婷,周卫平,李松毅,等.一种新的Pseudo-Zernike矩的快速算法[J].电子学报.2005,(7).DOI:10.3321/j.issn:0372-2112.2005.07.033 .
[9]孙正兴,冯桂焕,周若鸿.基于草图的人机交互技术研究进展[J].计算机辅助设计与图形学学报.2005,(9).DOI:10.3321/j.issn:1003-9775.2005.09.001 .
[10]胡友树.手势识别技术综述[J].中国科技信息.2005,(2).DOI:10.3969/j.issn.1001-8972.2005.02.034

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









