






 本文介绍了一个基于卷积神经网络(CNN)的肺炎影像分类分割智能诊断系统,旨在提高肺炎诊断的准确性和效率。系统利用CNN自动学习和特征提取,实现肺炎的自动诊断,包括图像分类和分割。核心代码包括Classifier.py、export.py、predict.py、train.py、ui.py,以及模型common.py。数据预处理采用了限制对比对自适应直方图均衡等方法,确保数据质量。系统整合了多种深度学习模型,如GoogLeNet、ResNet50、DenseNet和Transformer-based的ViT,以及U-Net结构进行图像分割。通过这些技术,系统能为医生提供辅助决策,促进医学研究和教育的发展。
本文介绍了一个基于卷积神经网络(CNN)的肺炎影像分类分割智能诊断系统,旨在提高肺炎诊断的准确性和效率。系统利用CNN自动学习和特征提取,实现肺炎的自动诊断,包括图像分类和分割。核心代码包括Classifier.py、export.py、predict.py、train.py、ui.py,以及模型common.py。数据预处理采用了限制对比对自适应直方图均衡等方法,确保数据质量。系统整合了多种深度学习模型,如GoogLeNet、ResNet50、DenseNet和Transformer-based的ViT,以及U-Net结构进行图像分割。通过这些技术,系统能为医生提供辅助决策,促进医学研究和教育的发展。
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
肺炎是一种常见的呼吸系统感染疾病,其主要病因包括细菌、病毒和真菌等。肺炎的早期诊断对于患者的治疗和预后至关重要。传统的肺炎诊断方法主要依赖于医生的经验和肺部影像学的观察,这种方法存在主观性强、诊断效率低等问题。随着计算机科学和人工智能的快速发展,基于卷积神经网络的肺炎影像分类分割智能诊断系统逐渐成为研究的热点。
卷积神经网络(Convolutional Neural Network,CNN)是一种模仿人类视觉系统的深度学习算法,具有自动学习和特征提取的能力。通过对大量的肺部影像数据进行训练,CNN可以自动识别和提取肺部影像中的特征,从而实现对肺炎的自动诊断。
基于卷积神经网络的肺炎影像分类分割智能诊断系统具有以下几个方面的意义:
-
提高诊断准确性:传统的肺炎诊断方法主要依赖于医生的经验和肺部影像学的观察,存在主观性强、诊断效率低等问题。而基于卷积神经网络的肺炎影像分类分割智能诊断系统可以通过自动学习和特征提取,提高诊断的准确性和可靠性。
-
提高诊断效率:传统的肺炎诊断方法需要医生对大量的肺部影像进行观察和分析,耗费时间和精力。而基于卷积神经网络的肺炎影像分类分割智能诊断系统可以实现对大量肺部影像的自动分析和诊断,大大提高诊断的效率。
-
辅助医生决策:基于卷积神经网络的肺炎影像分类分割智能诊断系统可以为医生提供辅助决策的依据。通过对肺部影像进行自动分析和诊断,系统可以提供患者的病情评估、治疗建议等信息,帮助医生做出更准确的诊断和治疗方案。
-
促进医学研究和教育:基于卷积神经网络的肺炎影像分类分割智能诊断系统可以对大量的肺部影像数据进行分析和挖掘,从而为医学研究提供宝贵的数据资源。同时,系统还可以作为教学工具,帮助医学生和医生进行肺炎诊断的学习和培训。
综上所述,基于卷积神经网络的肺炎影像分类分割智能诊断系统具有重要的研究意义和应用价值。通过提高肺炎诊断的准确性和效率,该系统可以为医生提供辅助决策的依据,促进医学研究和教育的发展,最终提高肺炎患者的治疗效果和生存质量。
2.图片演示



3.视频演示
基于卷积神经网络的肺炎影像分类分割智能诊断系统_哔哩哔哩_bilibili
4.系统流程图
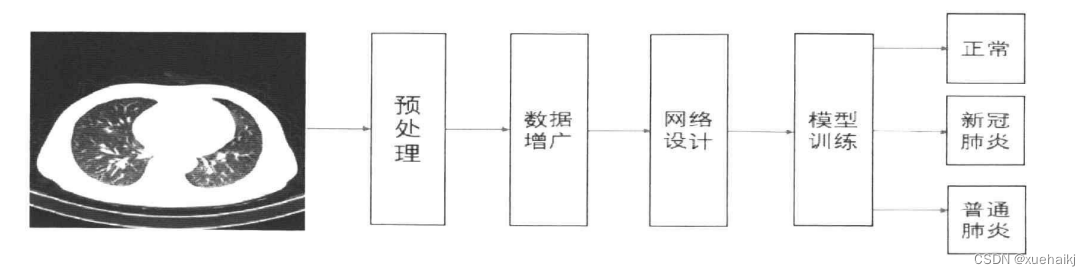
通过第一节理论的介绍,本文已经对深度学习和CT图像原理有了基本的了解。而接下来本文要做的是对于已经得到CT图像进行分析研究,本章将对于原始CT图像进行分类。肺炎图像分类指新冠肺炎、非新冠肺炎的二分类和新冠肺炎、普通肺炎、健康的三分类,根据不同的需要进行任务选择。而对于专业的医生来说,对于给定的一张CT 图像,需要仔细观察病变的区域和区域的大小,根据一定的专业知识和经验,才能进行相应的判断。显然这是相当费时和费力的过程,也存在很大的错误概率。由于患者的人数庞大,很多患者无法得到及时诊治,错过了治疗的最佳时机,使得病情加重。
本文致力于使用深度学习的方法,快速、高效地做出分类预测,为医生提供宝贵的意见。本章将使用深度学习的技术在公开的数据集上进行算法研究,实现肺部CT图像的分类。整个流程是端到端的,只需要输入CT图像即可得到最终的预测类别。肺部CT图像分类的流程图如下图所示,由于公开获取的数据集质量有高有低,所以预处理是必要的。由于深度学习是大数据驱动的算法,数据的增广也是必不可少的。接着就是网络的设计,鉴于目前很多卷积神经网络已经证明在各大数据集上得到了较好的结果,因此本文训练了多个经典的分类网络模型来进行效果比较,并将传统卷积方法和Transformer方法进行对比,对ViT 网络进行改进,从多方面对比各个网络模型的效果。训练后的模型用于对图像的分类预测,即可实现端到端的分类算法。下面首先介绍分类网络的设计。
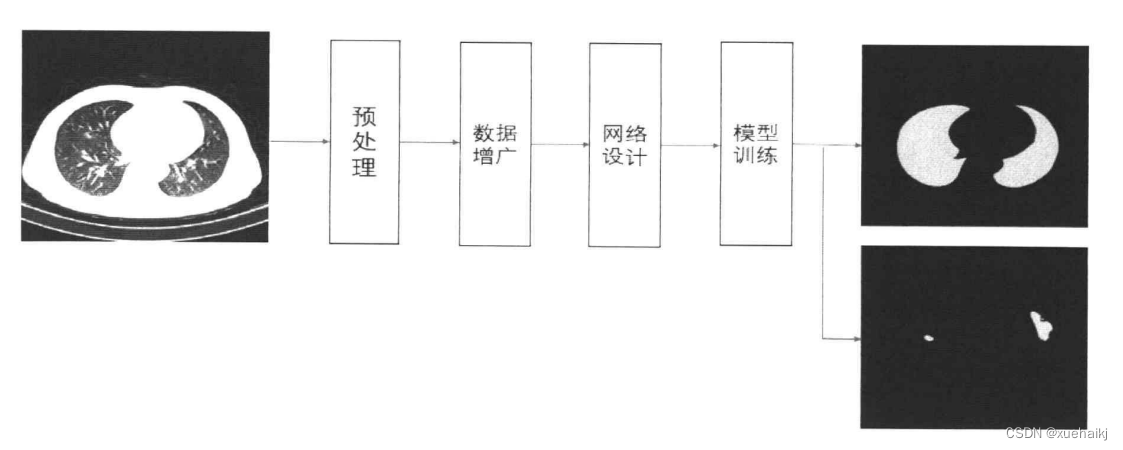
本文提出了一种基于改进的 ViT和YOLO等的肺炎分类方法,实现了对于CT 图像类别的分析,准确率可以达到93%以上,可以实现对病情的定性分析。但是一个类别的信息并不能够全面的辅助医生的诊断,还需要对病变区域定量分析。图像中仍有大量信息需要提取,因此,本文提出对于新冠肺炎的CT图像进行分割,提取出图像中的肺野、病变等区域信息,更加多方面的辅助医生进行判断,准确地对病情进行分析诊断。本章继续使用深度学习的方法,将Transformer和卷积神经网络进行融合,最终实现肺野、病变的分割,并与现有的优秀分割网络进行对比。分割任务类似于分类的任务,仍然需要数据集的获取和预处理,需要数据量的支撑,因此图像的增广也必不可少。网络的设计和改进是本文的主要目标,接着训练模型和计算指标值。最终本章能够实现端到端的分割,对于输入图像可以输出肺野分割结果、病变分割结果或者两者都含有的四类别分割结果。分割的流程图如下图所示:
5.核心代码讲解
5.1 Classifier.py
class ImageClassifier:
def __init__(self, weights_path, data_path, img_size=(224, 224), device=''):
self.device = select_device(device)
self.model = DetectMultiBackend(weights_path, device=self.device, data=data_path)
self.names = self.model.names
self.img_size = img_size
self.model.warmup(imgsz=(1, 3, *img_size))
def classify(self, image):
image_tensor = torch.Tensor(image).to(self.device)
image_tensor = image_tensor.float()
if len(image_tensor.shape) == 3:
image_tensor = image_tensor[None]
results = self.model(image_tensor)
pred = F.softmax(results, dim=1)
max_i = pred.argmax(dim=1).item() # 使用 argmax 找到最大置信度的索引
max_confidence = float(pred[0][max_i]) # 获取最大置信度的值
return self.names[max_i], max_confidence
def load_image(image_path, img_size):
dataset = LoadImages(image_path, img_size=img_size, transforms=classify_transforms(img_size[0]))
return next(iter(dataset))[1]
if __name__ == '__main__':
weights_path = './best.pt'
data_path = './data/coco128.yaml'
image_path = './test/1.jpg'
classifier = ImageClassifier(weights_path, data_path)
image = load_image(image_path, classifier.img_size)
results = classifier.classify(image)
print(results)
将以上代码封装为一个名为ImageClassifier的类,该类具有以下方法和属性:
__init__(self, weights_path, data_path, img_size=(224, 224), device=''): 初始化方法,接收模型权重路径、数据路径、图像尺寸和设备类型作为参数。在初始化过程中,会选择设备、加载模型、获取类别名称和设置图像尺寸。classify(self, image): 对输入的图像进行分类,返回预测的类别名称和置信度。img_size: 图像尺寸属性。
另外,还有一个辅助函数load_image(image_path, img_size),用于加载图像并进行预处理。
在if __name__ == '__main__':部分,创建了一个ImageClassifier对象,加载图像并进行分类,最后打印结果。
这个程序文件名为Classifier.py,它包含了一个名为ImageClassifier的类和一个名为load_image的函数。
ImageClassifier类有以下几个方法:
__init__(self, weights_path, data_path, img_size=(224, 224), device=''):初始化方法,接受权重路径、数据路径、图像大小和设备参数。在初始化过程中,它会调用select_device函数选择设备,创建一个DetectMultiBackend模型实例,并将模型的类别名称保存在self.names中。classify(self, image):分类方法,接受一个图像作为输入。它将图像转换为张量,并将其传递给模型进行推理。最后,它使用softmax函数计算预测结果的概率分布,并返回预测结果的类别名称和最大置信度值。
load_image函数有以下功能:
load_image(image_path, img_size):加载图像的函数,接受图像路径和图像大小作为输入。它使用LoadImages类加载图像数据集,并返回第一个图像的张量表示。
在程序的主函数中,定义了权重路径、数据路径和图像路径,并创建了一个ImageClassifier实例。然后,使用load_image函数加载图像,并调用ImageClassifier的classify方法对图像进行分类。最后,打印分类结果。
5.2 export.py
def export_formats():
# YOLOv5 export formats
x = [
['PyTorch', '-', '.pt', True, True],
['TorchScript', 'torchscript', '.torchscript', True, True],
['ONNX', 'onnx', '.onnx', True, True],
['OpenVINO', 'openvino', '_openvino_model', True, False],
['TensorRT', 'engine', '.engine', False, True],
['CoreML', 'coreml', '.mlmodel', True, False],
['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
['TensorFlow GraphDef', 'pb', '.pb', True, True],
['TensorFlow Lite', 'tflite', '.tflite', True, False],
['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
['TensorFlow.js', 'tfjs', '_web_model', False, False],
['PaddlePaddle', 'paddle', '_paddle_model', True, True],]
return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
def try_export(inner_func):
# YOLOv5 export decorator, i..e @try_export
inner_args = get_default_args(inner_func)
def outer_func(*args, **kwargs):
prefix = inner_args['prefix']
try:
with Profile() as dt:
f, model = inner_func(*args, **kwargs)
LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
return f, model
except Exception as e:
LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
return None, None
return outer_func
@try_export
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
# YOLOv5 TorchScript model export
LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
f = file.with_suffix('.torchscript')
ts = torch.jit.trace(model, im, strict=False)
d = {'shape': im.shape, 'stride': int(max(model.stride)), 'names': model.names}
extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
else:
ts.save(str(f), _extra_files=extra_files)
return f, None
@try_export
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
# YOLOv5 ONNX export
check_requirements('onnx>=1.12.0')
import onnx
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
if dynamic:
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
if isinstance(model, SegmentationModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
elif isinstance(model, DetectionModel):
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)
# Simplify
if simplify:
try:
cuda = torch.cuda.is_available()
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
import onnxsim
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(model_onnx)
ass
export.py是一个用于将YOLOv5 PyTorch模型导出为其他格式的程序文件。它支持导出的格式包括PyTorch、TorchScript、ONNX、OpenVINO、TensorRT、CoreML、TensorFlow SavedModel、TensorFlow GraphDef、TensorFlow Lite、TensorFlow Edge TPU、TensorFlow.js和PaddlePaddle。通过运行export.py文件,可以根据指定的参数将YOLOv5模型导出为所需的格式。同时,该文件还提供了一些辅助函数和装饰器,用于简化导出过程和处理异常情况。
5.3 predict.py
class ImageSegmentation:
def __init__(self, image_path, model_path):
self.image_path = image_path
self.model_path = model_path
def load_dataset(self):
images = glob.glob(self.image_path)
anno = images
dataset = tf.data.Dataset.from_tensor_slices((images, anno))
train_count = len(images)
data_train = dataset.take(train_count)
return data_train
def read_jpg(self, path):
img = tf.io.read_file(path)
img = tf.image.decode_jpeg(img, channels=3)
return img
def read_png(self, path):
img = tf.io.read_file(path)
img = tf.image.decode_png(img, channels=1)
return img
def normal_img(self, input_image, input_anno):
input_image = tf.cast(input_image, tf.float32)
input_image = input_image / 127.5 - 1
input_anno -= 1
return input_image, input_anno
def load_images(self, input_images_path, input_anno_path):
input_image = self.read_jpg(input_images_path)
input_anno = self.read_png(input_anno_path)
input_image = tf.image.resize(input_image, (224, 224))
input_anno = tf.image.resize(input_anno, (224, 224))
return self.normal_img(input_image, input_anno)
def set_config(self, data_train):
data_train = data_train.map(self.load_images, num_parallel_calls=tf.data.experimental.AUTOTUNE)
BATCH_SIZE = 32
data_train = data_train.repeat().shuffle(100).batch(BATCH_SIZE)
return data_train
def predict(self):
data_train = self.load_dataset()
data_train = self.set_config(data_train)
new_model = tf.keras.models.load_model(self.model_path)
for image, mask in data_train.take(1):
pred_mask = new_model.predict(image)
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
print(np.unique(pred_mask[0].numpy()))
plt.figure(figsize=(10, 10))
plt.subplot(1, 3, 1)
plt.imshow(tf.keras.preprocessing.image.array_to_img(image[0]))
plt.subplot(1, 3, 2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(mask[0]))
plt.subplot(1, 3, 3)
plt.imshow(tf.keras.preprocessing.image.array_to_img(pred_mask[0]))
plt.show()
这个程序文件名为predict.py,它是一个用于预测图像分割的程序。它使用了TensorFlow和Matplotlib库来加载和处理图像数据,并使用已经训练好的模型进行预测。
程序的主要功能包括:
- 加载数据集:通过指定图像路径,使用glob库获取所有图像文件,并创建一个TensorFlow的dataset对象。
- 检查版本:检查当前环境中TensorFlow、Matplotlib和NumPy的版本是否符合要求。
- 图像预处理:定义了读取jpg和png图像文件的函数,并对图像进行归一化处理。
- 加载图像和标注:定义了加载图像和标注的函数,并对图像进行尺寸规范化和归一化处理。
- 设置配置:对数据集进行配置,包括设置多线程数、batch size和数据重复次数等。
- 预测图像分割:加载训练好的模型,并对输入图像进行预测,得到预测的分割结果。
- 绘制图像:使用Matplotlib库将原始图像、标注图像和预测图像进行可视化展示。
程序的运行逻辑是先检查环境版本,然后加载图像数据集,设置数据集配置,加载模型,进行预测并绘制图像。
请注意,这个程序是一个示例,可能需要根据具体的应用场景进行修改和调整。
5.4 train.py
class ImageLoader:
def __init__(self, images_path, anno_path, batch_size):
self.images_path = images_path
self.anno_path = anno_path
self.batch_size = batch_size
self.dataset = None
self.train_count = None
self.test_count = None
self.data_train = None
self.data_test = None
def read_jpg(self, path):
img = tf.io.read_file(path)
img = tf.image.decode_jpeg(img, channels=3)
return img
def read_png(self, path):
img = tf.io.read_file(path)
img = tf.image.decode_png(img, channels=1)
return img
def normal_img(self, input_image, input_anno):
input_image = tf.cast(input_image, tf.float32)
input_image = input_image / 127.5 - 1
return input_image, input_anno
def load_images(self, input_images_path, input_anno_path):
input_image = self.read_jpg(input_images_path)
input_anno = self.read_png(input_anno_path)
input_image = tf.image.resize(input_image, (224, 224))
input_anno = tf.image.resize(input_anno, (224, 224))
return self.normal_img(input_image, input_anno)
def prepare_data(self):
images = glob.glob(self.images_path)
anno = glob.glob(self.anno_path)
np.random.seed(2019)
index = np.random.permutation(len(images))
images = np.array(images)[index]
anno = np.array(anno)[index]
dataset = tf.data.Dataset.from_tensor_slices((images, anno))
test_count = int(len(images) * 0.2)
train_count = len(images) - test_count
data_train = dataset.skip(test_count)
data_test = dataset.take(test_count)
data_train = data_train.map(self.load_images, num_parallel_calls=tf.data.experimental.AUTOTUNE)
data_test = data_test.map(self.load_images, num_parallel_calls=tf.data.experimental.AUTOTUNE)
data_train = data_train.repeat().shuffle(100).batch(self.batch_size)
data_test = data_test.batch(self.batch_size)
self.dataset = dataset
self.train_count = train_count
self.test_count = test_count
self.data_train = data_train
self.data_test = data_test
......
这个程序文件名为train.py,主要功能是训练一个语义分割模型。程序的主要步骤如下:
- 导入所需的库:tensorflow、matplotlib、numpy和os。
- 定义了几个函数:read_jpg用于读取jpg图像并进行预处理,read_png用于读取png图像并进行预处理,normal_img用于将图像进行归一化处理,load_images用于加载图像和annotations并进行预处理。
- 在主函数中,首先使用glob模块获取图像和annotations的文件路径,并设置保存训练模型的路径。
- 设置训练的参数,包括Epoch(训练轮数)和BATCH_SIZE(批量大小)。
- 对图像和annotations进行乱序处理,并将它们划分为训练集和测试集。
- 创建tf.data.Dataset对象,并使用map函数对数据进行预处理。
- 对训练集进行重复、乱序和分批处理,对测试集进行分批处理。
- 初始化VGG16预训练网络,并根据需要选择指定层的输出。
- 创建语义分割模型,包括卷积、上采样和跳接操作。
- 设置回调函数,用于保存训练过程中的最优权重文件。
- 编译模型,设置优化器、损失函数和评估指标。
- 使用fit函数进行模型训练,设置训练参数和回调函数。
- 保存训练好的模型到本地。
- 打印训练完成的提示信息。
总体来说,这个程序文件实现了一个语义分割模型的训练过程,包括数据加载、预处理、模型构建、模型训练和模型保存等步骤。
5.5 ui.py
def load_dataset(image_path):
images = glob.glob(image_path)
anno = images
dataset = tf.data.Dataset.from_tensor_slices((images, anno)) # 创建dataset
train_count = len(images)
data_train = dataset.take(train_count)
return data_train
def read_jpg(path): # jpg图像预处理
img = tf.io.read_file(path)
img = tf.image.decode_jpeg(img, channels=3)
return img
def read_png(path): # png图像预处理
img = tf.io.read_file(path)
img = tf.image.decode_png(img, channels=1)
return img
def normal_img(input_image, input_anno): # 归一化处理 0-255 转化为0-1
input_image = tf.cast(input_image, tf.float32) # 改变数据类型为float32
input_image = input_image / 127.5 - 1 # 使jpg图片每个像素的值为 -1~1的范围
input_anno -= 1 # 使png图片每个像素分类的范围在0,1,2之中
return input_image, input_anno
def load_images(input_images_path, input_anno_path): # 定义加载函数
input_image = read_jpg(input_images_path) # 加载图片
input_anno = read_png(input_anno_path) # 加载annotations
input_image = tf.image.resize(input_image, (224, 224)) # 规范图片到同样的尺寸(224,224)
input_anno = tf.image.resize(input_anno, (224, 224)) # 规范图片到同样的尺寸(224,224)
return normal_img(input_image, input_anno) # 归一化处理
def set_config(data_train):
data_train = data_train.map(load_images,
num_parallel_calls=tf.data.experimental.AUTOTUNE) # 设置多线程数为自适应最优配置
BATCH_SIZE = 32 # 设置batch_size
data_train = data_train.repeat().shuffle(100).batch(BATCH_SIZE) # 设置学习率 batch_size
return data_train
def seg(info1):
global area1,area2
area1 = 0
check_version() #检查主要环境版本
image_path = info1 #predict图片集完整路径(注意格式中的*)6
data_train = load_dataset(image_path) #加载dataset
data_train = set_config(data_train) #设置config
new_model = tf.keras.models.load_model('./train/fei.h5') # 加载完整模型
#print(new_model.summary()) #展示模型的架构
#以下均为绘图
skip = 0
for image, mask in data_train.take(1):
pred_mask = new_model.predict(image)
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
print(np.unique(pred_mask[0].numpy()))
plt.figure(figsize=(10, 10))
plt.subplot(1, 3, 1)
plt.imshow(tf.keras.preprocessing.image.array_to_img(image[0]))
plt.subplot(1, 3, 2)
plt.imshow(tf.keras.preprocessing.image.array_to_img(mask[0]))
plt.subplot(1, 3, 3)
plt.imshow(tf.keras.preprocessing.image.array_to_img(pred_mask[0]))
if skip == 0:
plt.imsave('./seg.jpg',
tf.keras.preprocessing.image.array_to_img(pred_mask[0]))
skip = 1
if skip == 1:
break
这个程序文件名为ui.py,主要功能是实现一个新冠肺炎等级分类系统的用户界面。程序中导入了一些必要的库,包括tensorflow、matplotlib、numpy、glob、os、sys、cv2等。程序定义了一些函数,包括加载数据集、检查版本、读取图片、图片预处理、加载图片、设置配置、进行肺炎分割等。程序还定义了一个线程类Thread_1和一个UI类Ui_MainWindow,用于实现多线程和用户界面的交互。用户界面包括一个标签、一个显示图片的标签、一个文本浏览器和三个按钮,分别用于选择文件、进行肺炎分割和进行X光分类。用户可以通过选择文件按钮选择要处理的图片文件,然后点击肺炎分割按钮进行肺炎分割,最后点击X光分类按钮进行X光分类。程序还定义了一些辅助函数,用于实现具体的功能。
5.6 models\common.py
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class DWConv(Conv):
# Depth-wise convolution
def __init__(self, c1, c2, k=1, s=1, d=1, act=True): # ch_in, ch_out, kernel, stride, dilation, activation
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
class DWConvTranspose2d(nn.ConvTranspose2d):
# Depth-wise transpose convolution
def __init__(self, c1, c2, k=1, s=1, p1=0, p2=0): # ch_in, ch_out, kernel, stride, padding, padding_out
super().__init__(c1, c2, k, s, p1, p2, groups=math.gcd(c1, c2))
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act=act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1
这个程序文件是YOLOv5的一个模块,包含了一些常用的函数和类。下面是文件中定义的一些类和函数的概述:
- Conv类:标准的卷积层,包含了卷积、批归一化和激活函数。
- DWConv类:深度卷积层,用于进行深度卷积操作。
- DWConvTranspose2d类:深度转置卷积层,用于进行深度转置卷积操作。
- TransformerLayer类:Transformer层,用于进行Transformer操作。
- TransformerBlock类:Vision Transformer模块,包含了多个TransformerLayer层。
- Bottleneck类:标准的瓶颈块。
- BottleneckCSP类:CSP瓶颈块。
- CrossConv类:交叉卷积下采样层。
- C3类:包含3个卷积层的CSP瓶颈块。
- C3x类:带有交叉卷积的C3模块。
- C3TR类:带有TransformerBlock的C3模块。
- C3SPP类:带有SPP的C3模块。
- C3Ghost类:带有GhostBottleneck的C3模块。
- SPP类:空间金字塔池化层。
- SPPF类:快速空间金字塔池化层。
- Focus类:将宽高信息聚合到通道维度的层。
- GhostConv类:Ghost卷积层。
- GhostBottleneck类:Ghost瓶颈块。
- Contract类:将宽高压缩到通道维度的层。
此外,文件中还包含了一些常用的函数,如autopad函数用于自动填充卷积层的padding参数,make_divisible函数用于将通道数调整为可被某个数整除的值,等等。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于卷积神经网络的肺炎影像分类分割智能诊断系统。它包含了多个程序文件,用于实现不同的功能,包括图像分类、图像分割、模型训练、模型导出、用户界面等。其中,Classifier.py文件实现了图像分类的功能,export.py文件实现了模型导出的功能,predict.py文件实现了图像分割的功能,train.py文件实现了模型训练的功能,ui.py文件实现了用户界面的功能。
下面是每个文件的功能整理:
| 文件路径 | 功能 |
|---|---|
| Classifier.py | 实现图像分类功能 |
| export.py | 实现模型导出功能 |
| predict.py | 实现图像分割功能 |
| train.py | 实现模型训练功能 |
| ui.py | 实现用户界面功能 |
| models\common.py | 包含常用的模型类和函数 |
| models\experimental.py | 包含实验性的模型类和函数 |
| models\tf.py | 包含TensorFlow相关的模型类和函数 |
| models\yolo.py | 包含YOLOv5模型类和函数 |
| models_init_.py | 模型模块的初始化文件 |
| tools\check_img.py | 图像检查工具 |
| tools\check_seg.py | 分割结果检查工具 |
| tools\url_get.py | 从URL获取图像的工具 |
| utils\activations.py | 激活函数相关的工具函数 |
| utils\augmentations.py | 数据增强相关的工具函数 |
| utils\autoanchor.py | 自动锚框生成的工具函数 |
| utils\autobatch.py | 自动批量大小调整的工具函数 |
| utils\callbacks.py | 回调函数相关的工具函数 |
| utils\dataloaders.py | 数据加载器相关的工具函数 |
| utils\downloads.py | 下载相关的工具函数 |
| utils\general.py | 通用的工具函数 |
| utils\loss.py | 损失函数相关的工具函数 |
| utils\metrics.py | 评估指标相关的工具函数 |
| utils\plots.py | 绘图相关的工具函数 |
| utils\torch_utils.py | PyTorch相关的工具函数 |
| utils\triton.py | Triton相关的工具函数 |
| utils_init_.py | 工具模块的初始化文件 |
| utils\aws\resume.py | AWS相关的工具函数 |
| utils\aws_init_.py | AWS模块的初始化文件 |
| utils\flask_rest_api\example_request.py | Flask REST API示例请求的工具函数 |
| utils\flask_rest_api\restapi.py | Flask REST API的工具函数 |
| utils\loggers_init_.py | 日志记录器模块的初始化文件 |
| utils\loggers\clearml\clearml_utils.py | ClearML日志记录器的工具函数 |
| utils\loggers\clearml\hpo.py | ClearML日志记录器的超参数优化工具函数 |
| utils\loggers\clearml_init_.py | ClearML日志记录器模块的初始化文件 |
| utils\loggers\comet\comet_utils.py | Comet日志记录器的工具函数 |
| utils\loggers\comet\hpo.py | Comet日志记录器的超参数优化工具函数 |
| utils\loggers\comet_init_.py | Comet日志记录器模块的初始化文件 |
| utils\loggers\wandb\wandb_utils.py | WandB日志记录器的工具函数 |
| utils\loggers\wandb_init_.py | WandB日志记录器模块的初始化文件 |
| utils\segment\augmentations.py | 分割数据增强相关的工具函数 |
| utils\segment\dataloaders.py | 分割数据加载器相关的工具函数 |
| utils\segment\general.py | 分割通用的工具函数 |
| utils\segment\loss.py | 分割损失函数相关的工具函数 |
| utils\segment\metrics.py | 分割评估指标相关的工具函数 |
| utils\segment\plots.py | 分割绘图相关的工具函数 |
| utils\segment_init_.py | 分割模块的初始化文件 |
以上是根据文件路径整理的每个文件的功能概述。
7.数据集来源及数据预处理
数据集来源
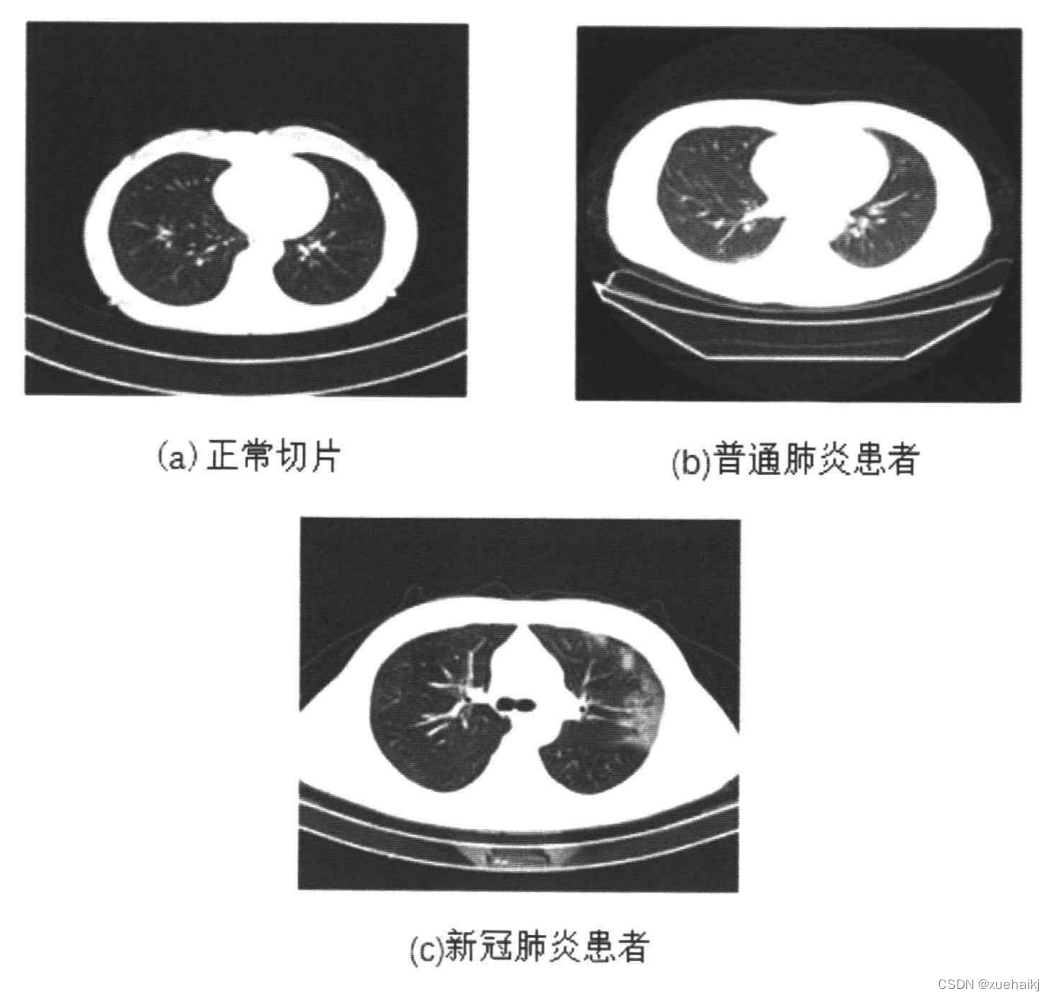
本实验所采用的数据集之一来自于国家生物信息中心,名称为2019新型冠状病毒信息库(2019nCoVR)( http://nov-ai.big.ac.cn/download)。该数据不同于一些公开的新冠肺炎数据集,不存在大小不统一,类别数量不均衡,图像质量不高等问题。经过国家专业人士研究和认证,该数据集包含了新冠肺炎病例、普通肺炎病例和正常人群的肺部CT图像。其中普通肺炎包括病毒性肺炎、细菌性肺炎和支原体肺炎,为最常见的肺炎病因。另一部分数据集来自中国胸部CT 图像调查联盟,新冠肺炎患者1351例、普通肺炎患者500例、正常366例[55]。每一例中包含大量CT切片,但同一位患者的CT切片具有很大的相似性,因此需要进行筛选。图3.8为三种类别的CT图像示例,下面介绍对于原始数据的预处理。
(a)正常切片
(b)普通肺炎患者
©新冠肺炎患者
数据预处理
鉴于深度学习极度依靠数据质量,所以数据的预处理在最终实验结果上起至关重要的作用。数据集中含有噪声等干扰因素,为了获得更好的性能,本文使用的预处理包括限制对比对自适应直方图均衡、图像归一化和图像增广等。
(1)限制对比对自适应直方图均衡
限制对比对自适应直方图均衡(Contrast Limited Adaptive Histogram Equalization,CLAHE)的方法,是直方图均衡的一种变体,对比度的放大受到限制,防止了噪声被放大,也让图像中的细节更加突出明显。在使用后该方法,CT 图像中的病变区域更加明显了,有助于更好地训练模型和得到更好的性能。下图展示了经过处理后的图片示例:

8.肺部CT图像的分类
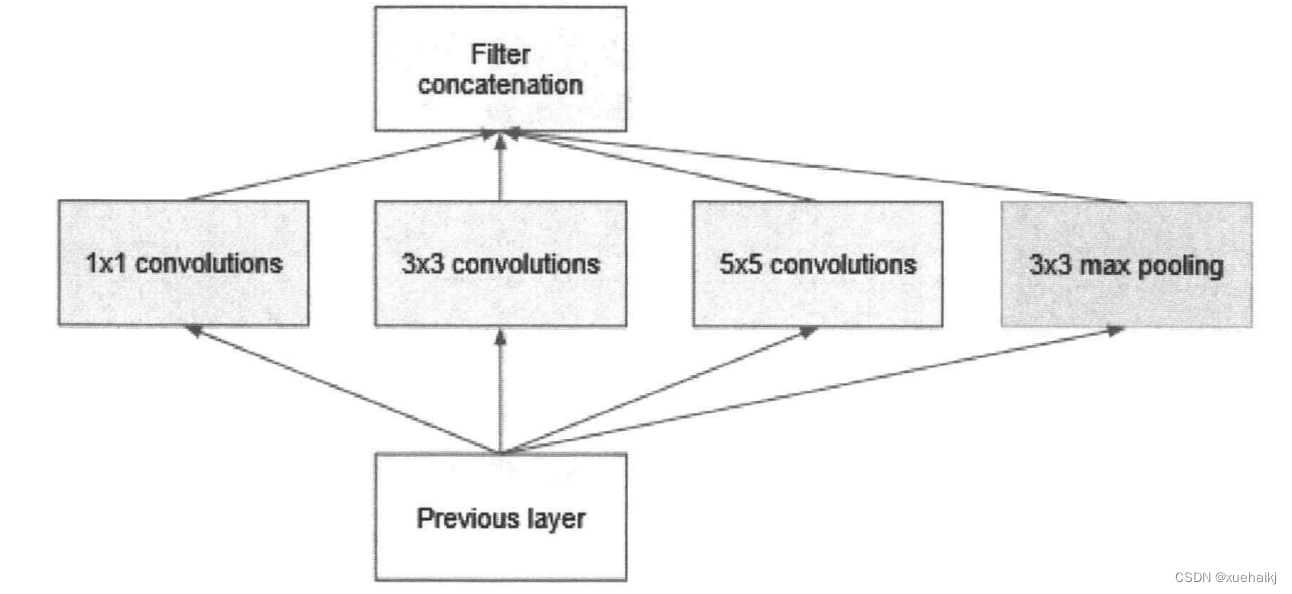
本文首先选择了几个经典的传统卷积神经网络进行实验,有GoogLeNet、ResNet50、DenseNet、MobileNet、vGG16、cOVNET。GoogLeNet是google推出的基于Inception模块的深度神经网络模型,在2014年的ImageNet竞赛中夺得了冠军,在随后的两年中一直在改进,形成了Inception V2、Inception V3、Inception V4等版本。为了增加网络深度的同时减少参数,研究人员提出了Inception方法,把多个卷积或池化的操作组成一个网络模块,整个网络以模块为单位组成。因为不同的尺度的图像中,需要不同大小的卷积核,不同的感受野,所以Inception模块中并列提供多种卷积核,训练过程中调节参数自我选择。网络最后用平均池化代替了分类网络普遍使用的全连接层,论文中实验证明可以提高0.6%的准确率。模块化的结构也更加方便修改。Inception结构如图所示:
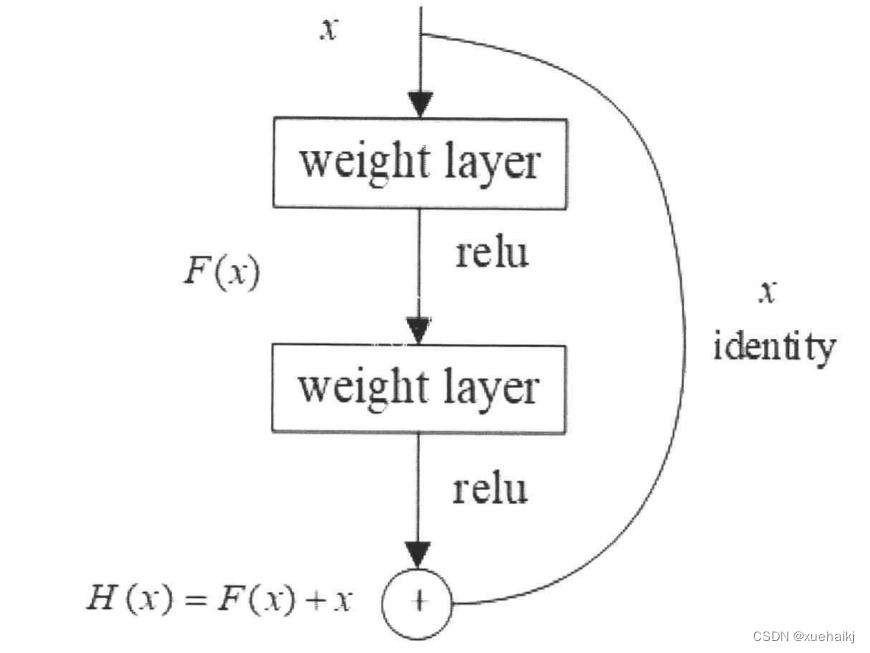
ResNet50网络的特点在于其结构中的残差单元,将卷积后的输出与输入相加,有效防止了梯度消失和梯度爆炸。网络中包括49个卷积层和一个全连接层。首先对输入进行卷积、正则化、激活函数和最大池化,然后经过多个残差块,每个残差快包含三层卷积,最后经过平均池化和全连接层,输出类别概率。残差结构如下图所示。
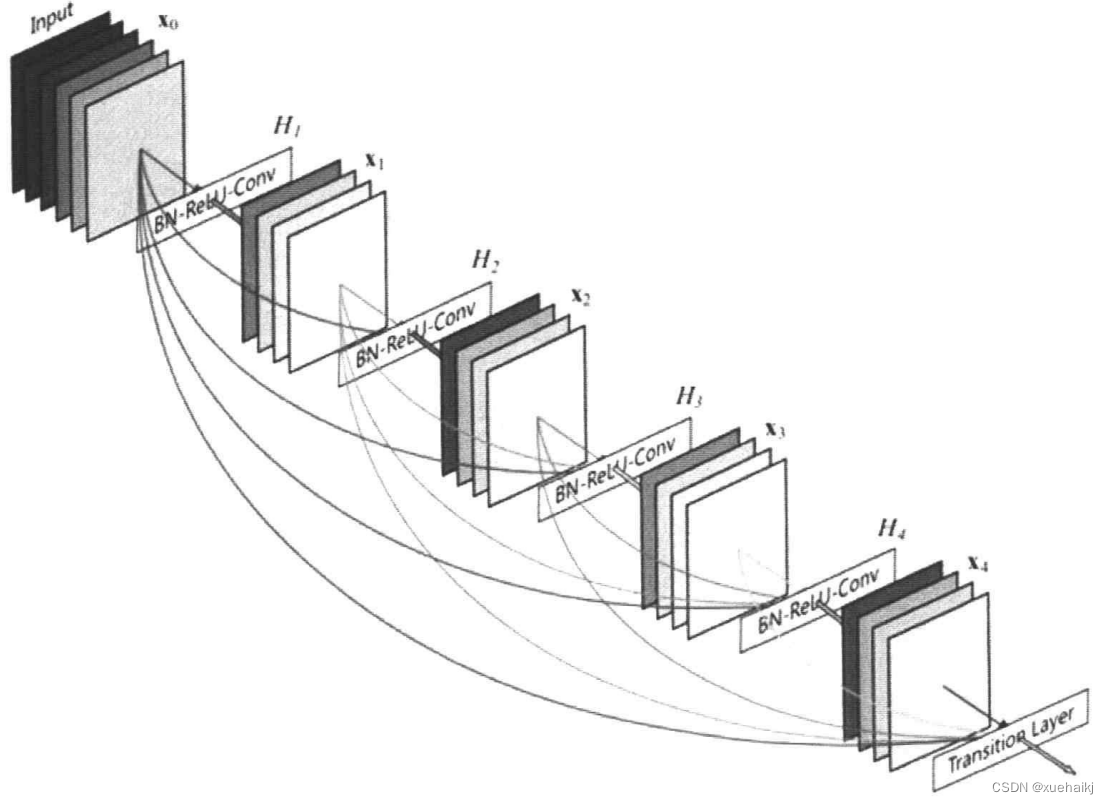
DenscNet提出了比 ResNet更密集的连接机制。互相连接所有的层,将前面所有层的信息作为输入送到下一层。使用concat操作连接来自不同层的特征图,实现特征的重复使用。DenseNet的连接机制如下图所示。
而MobileNet的特征是深度可分离卷积,使用了不同的卷积核,卷积同一特征图的不同通道,将通道与区域分离,极大地减少了计算量。
最近,Vision Transformer通过将自然语言处理中的Transformer结构运用到计算机视觉任务,达到了可以和卷积神经网络媲美的性能。即使没有卷积的纯Transformer 结构,也可以取得不错的性能。ViT网络具体内容已经在第二章节进行了介绍,在这里就不过多讲解了。此外在ImageNet上进行更强的正则化训练后,ViT的效果甚至优于CNN。Transformer获得的更多是全局信息,上下文依赖信息,而局部信息仍然非常重要,却被忽视了。因此,ViT一个改进方向是使得网络多注重一些局部信息。另一个改进方向是调整编码器中的多头注意力机制,减小网络的空间复杂度。下面介绍本文的改进和创新之处:
(1) ViT照搬了NLP中的做法,将单词对应到图像patch。但是对于自然语言,单词之间是没有重叠的,而图像则不一样。整个图像具有巨大的局部关联性,比如一个物体被分成了多个patch,就失去了局部相关性。因此,如果分块时进行重叠设计,就可以加强局部相关性,也相当于进行了local attention。本文提出了对图像分块时并非完全无重复,而是分块成重叠的patch序列,这样使得每一个patch中包含有更多的局部信息,更利于网络的收敛。本文使用卷积中的 padding 操作实现 patch重叠切片。Padding 操作是增加各个边的pixels 的数量,用“O”来填充。对于给定大小的输入图片H×W×C,其中H为高,W为宽,C为通道数。输入到步长为S的卷积,卷积核大小2S-1,填充大小为S-1,卷积核数量Co,则输出的大小为
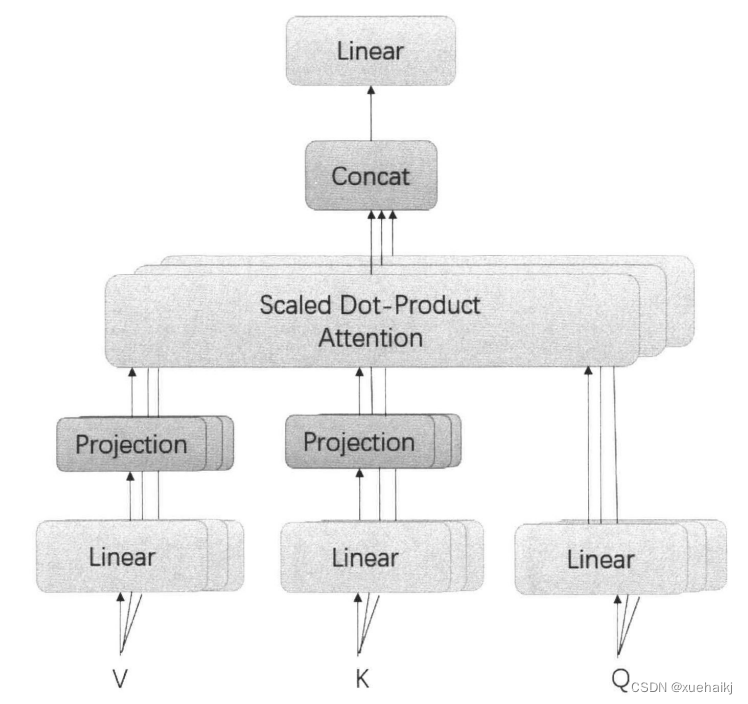
(2)对于Transformer编码器中的多头注意力机制,本文选择使用Linformerl54]这种具有线性复杂性的自注意力机制对其进行改进。Linformer是一种用低秩矩阵近似表示的自注意力机制,通过线性投影K、V矩阵进行低秩因数分解,将原始的缩放点积关注分解为更小的关注,使这些操作的组合形成了原始注意力的低秩因数分解。线性自注意的主要思想是在计算键和值的时候,添加了两个线性投影矩阵E,Fio最终使得空间和时间复杂度从O(t)降低为O(n)。具体的结构和计算过程如图所示,注意力机制和每个注意力头的计算公式如下式;
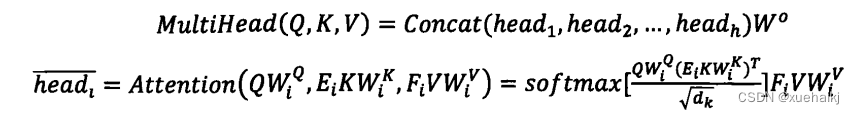
9.肺部CT图像分割
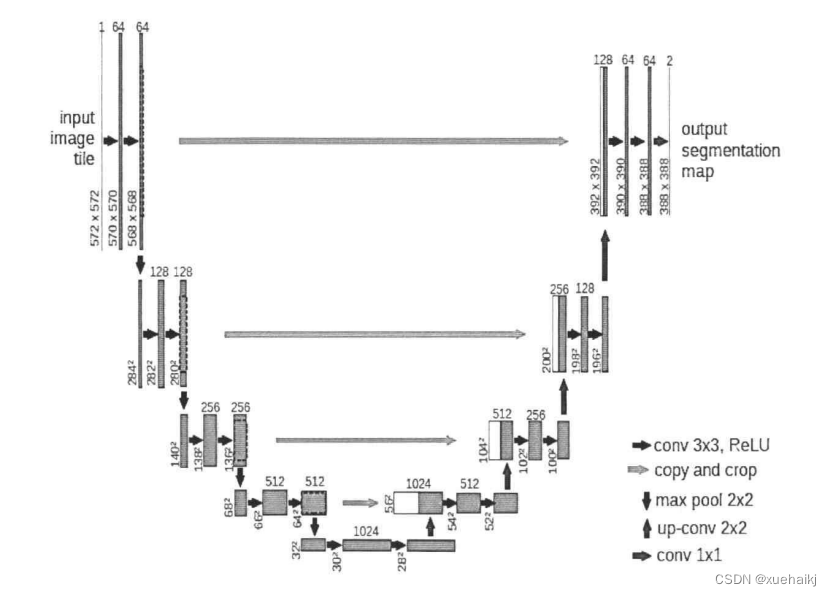
不少传统的图像处理方法研究过对于肺野的分割算法,根据肺野和外部环境的巨大差异进行阈值分割,使用一些传统的算法提取出肺野。本文也尝试过对CT 图像进行传统图像处理,但是由于最终得到的效果只能大致提取出肺野,而完全无法提取病变的信息,且效果不如深度学习的方法,所以选择不参与分割效果的比较。分割网络不同于分类网络,不仅需要编码器,还需要解码器。编码器通过多次的下采样去提取图片中的特征信息进行学习,解码器则是通过不断地上采样来恢复图像的分辨率,使得最终的输出大小和原图一样。编码器通常得到的是低分辨率特征图,解码器将特征图映射到高分辨率的像素空间,输出对应的分割掩膜。说到医学图像分割的模型,一定要提到最经典的U-Net网络,因其网络结构形状类似于“U”而得名。其结构如图4.2所示。使用编码器-解码器结构,网络中间使用跳跃连接。编码器中包括卷积、激活函数、池化等操作,进行了四次下采样,实现了对特征的提取,降低了特征图的大小,减少了网络的参数。解码器则使用反卷积进行上采样功能,恢复特征图的分辨率,使得输出与输入大小一致。中间的跳跃连接用来合并特征图,提高特征提取的能力。此后有不少研究人员基于此结构进行改进,如U-Net1+ [5]网络。改进方法是在大的网络框架中形成多层子U-Net网络,从不同的深度结构中提取不同的特征,总共四个深度,使用不同长度的跳跃连接。
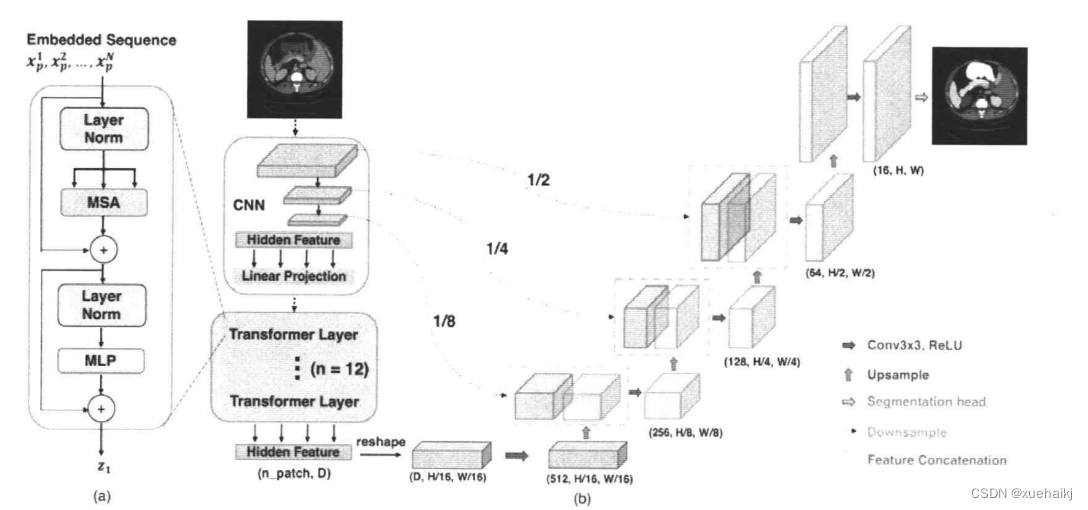
然而,全卷积网络的问题在于卷积运算是局部的,对于长距离依赖关系方面效果不好。而用于序列到序列预测的Transformer对于建模全局上下文表现强大,成功的在自然语言处理(NLP)方向取得很好的效果,并且最近在各种图像分类任务中达到了最佳表现。所以出现了将Transformer 用于图像分割的网络,用于编码器中的特征提取部分,代替卷积的作用TransUNet就将U-Net的编码器部分换成了Transformer,结合上 Transformer 和 U-Net的优点,将图像经过CNN的特征映射后,变成标记化图像块,作为输入序列送入Transformer。解码器对编码后的特征进行上采样,并与CNN的高分辨率特征图相结合,以实现精确定位。该网络还研究了跳跃连接次数对网络模型性能的影响,发现次数越多性能越好,最终网络选择了三次跳跃连接。实验证明该网络在多器官分割和心脏分割数据集上取得了优于各种竞争方法的性能。该网络的结构如下图所示:
10.系统整合

11.参考文献
[1]唐江平,周晓飞,贺鑫,等.基于深度学习的新型冠状病毒肺炎诊断研究综述[J].计算机工程.2021,(5).DOI:10.19678/j.issn.1000-3428.0060509 .
[2]靳英辉,蔡林,程真顺,等.新型冠状病毒(2019-nCoV)感染的肺炎诊疗快速建议指南(完整版)[J].医学新知.2020,(1).DOI:10.12173/j.issn.1004-5511.2020.01.09 .
[3]周飞燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报.2017,(6).DOI:10.11897/SP.J.1016.2017.01229 .
[4]徐振民,李柱.推广的Tanh-函数法及其应用[J].广西民族大学学报(自然科学版).2009,(3).DOI:10.3969/j.issn.1673-8462.2009.03.011 .
[5]李曦.神经网络信息传输函数Sigmoid与tanh比较论证[J].武汉理工大学学报(交通科学与工程版).2004,(2).DOI:10.3963/j.issn.2095-3844.2004.02.044 .
[6]史河水,韩小雨,樊艳青,等.新型冠状病毒(2019-nCoV)感染的肺炎临床特征及影像学表现[J].临床放射学杂志.2020,(1).
[7]胡海猛.基于深度学习的多场景车牌识别技术研究[D].2020.
[8]周志华, 著. 机器学习 [M].清华大学出版社,2016.
[9]李月卿. 医学影像成像原理 [M].人民卫生出版社,2002.
[10]佚名.Automatic lung segmentation in routine imaging is primarily a data diversity problem, not a methodology problem[J].European Radiology Experimental.2020,4(1).1-13.

















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









