






1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着人工智能和计算机视觉技术的不断发展,体育运动动作的规范度检测在许多领域都具有重要的应用价值。体育运动是人类社会中重要的活动之一,不仅能够提高人们的身体素质,还能够培养人们的团队合作精神和竞争意识。然而,对于体育运动动作的规范度检测,传统的方法往往需要依赖专业教练的目测判断,这种方法存在主观性强、效率低等问题。
为了解决这一问题,研究者们开始探索基于计算机视觉技术的体育运动动作规范度检测系统。这种系统能够通过分析运动员的动作数据,自动判断其动作是否符合规范要求。然而,现有的体育运动动作规范度检测系统仍然存在一些问题,如准确性不高、对复杂动作的处理能力有限等。
因此,本研究旨在基于改进HigherHRNet的体育运动动作规范度检测系统。HigherHRNet是一种基于高分辨率的网络结构,具有较强的特征提取能力和空间感知能力。通过对其进行改进,可以进一步提高体育运动动作规范度检测系统的准确性和稳定性。
本研究的意义主要体现在以下几个方面:
首先,基于改进HigherHRNet的体育运动动作规范度检测系统可以提高体育训练的效果。传统的体育训练往往需要依赖专业教练的目测判断,这种方法存在主观性强、效率低等问题。而基于计算机视觉技术的规范度检测系统可以提供客观、准确的反馈,帮助运动员及时发现和纠正动作中的问题,从而提高训练效果。
其次,基于改进HigherHRNet的体育运动动作规范度检测系统可以提高比赛裁判的公正性。在体育比赛中,裁判员的判决往往会受到主观因素的影响,容易引发争议。而通过引入计算机视觉技术,可以对运动员的动作进行客观、准确的评估,减少主观因素的干扰,提高比赛的公正性。
此外,基于改进HigherHRNet的体育运动动作规范度检测系统还具有广泛的应用前景。除了在体育训练和比赛中的应用外,该系统还可以应用于康复训练、运动员选拔等领域。通过对运动员动作的准确评估,可以帮助康复患者更好地进行康复训练,提高康复效果;同时,可以通过对运动员动作的分析,辅助选拔出更具潜力的运动员,提高运动队的竞争力。
综上所述,基于改进HigherHRNet的体育运动动作规范度检测系统具有重要的研究意义和应用价值。通过提高体育训练效果、提高比赛公正性以及拓展应用领域,该系统有望为体育运动领域的发展和进步做出积极贡献。
2.图片演示



3.视频演示
4.数据集的采集
下面我们来处理数据集,这个系统需要用到COCO数据集和CrowdPose公开数据集。
本项目均已训练完成,无需再次训练,如果要再次训练需要安装CUDA CuDnn ,同时具备24g+的显存,加载本项目文末训练好的模型直接运行系统则不吃配置,CPU即可。
处理COCO数据集
首先,下载COCO数据集的训练集和验证集,你可以从COCO官网下载。确保下载的是2017 Train/Val数据集,因为这些数据集用于COCO关键点的训练和验证。
将下载的数据集解压缩,并将文件按照以下结构放置在${POSE_ROOT}/data/coco/目录下:
|-- data
| `-- coco
| |-- annotations
| | |-- person_keypoints_train2017.json
| | `-- person_keypoints_val2017.json
| `-- images
| |-- train2017
| | |-- 000000000009.jpg
| | |-- 000000000025.jpg
| | |-- 000000000030.jpg
| | |-- ...
| `-- val2017
| |-- 000000000139.jpg
| |-- 000000000285.jpg
| |-- 000000000632.jpg
| |-- ...
处理CrowdPose数据集
同样地,下载CrowdPose数据集的训练集和验证集,你可以从CrowdPose官方页面下载。你需要下载Train/Val数据集,这些数据集用于CrowdPose关键点的训练和验证。
将下载的数据集解压缩,并将文件按照以下结构放置在${POSE_ROOT}/data/crowd_pose/目录下:
|-- data
| `-- crowd_pose
| |-- json
| | |-- crowdpose_train.json
| | |-- crowdpose_val.json
| | |-- crowdpose_trainval.json (由tools/crowdpose_concat_train_val.py生成)
| | `-- crowdpose_test.json
| `-- images
| |-- 100000.jpg
| |-- 100001.jpg
| |-- 100002.jpg
| |-- 100003.jpg
| |-- 100004.jpg
| |-- 100005.jpg
| |-- ...
在下载数据后,可以运行${POSE_ROOT}目录下的python tools/crowdpose_concat_train_val.py命令来创建trainval集合。
5.核心代码讲解
5.1 FeatureAlign.py
根据上述代码,可以将其封装为一个名为FeatureAlign的类。该类具有以下属性和方法:
属性:
- scale_factor:上采样的比例因子
- mode:上采样的方式,默认为双线性插值
- align_corners:是否对齐角点,False为非角点对齐,True为角点对齐
方法:
- __init__:初始化特征对齐模块,接收scale_factor、mode和align_corners作为参数
- forward:前向传播,进行特征上采样和位置校准,接收x作为输入,返回对齐后的特征图
- _align_corners:对于角点对齐的特征图进行位置校准,接收x作为输入,返回位置校准后的特征图
- _calculate_offset:根据某种规则计算特征图的偏移量,接收x作为输入,返回计算得到的偏移量
以下是封装后的代码:
class FeatureAlign(nn.Module):
def __init__(self, scale_factor, mode='bilinear', align_corners=False):
super(FeatureAlign, self).__init__()
self.scale_factor = scale_factor
self.mode = mode
self.align_corners = align_corners
def forward(self, x):
x_upsampled = F.interpolate(x, scale_factor=self.scale_factor, mode=self.mode, align_corners=self.align_corners)
if self.align_corners:
x_aligned = self._align_corners(x_upsampled)
else:
x_aligned = x_upsampled
return x_aligned
def _align_corners(self, x):
offset = self._calculate_offset(x)
x_aligned = x + offset
return x_aligned
def _calculate_offset(self, x):
return torch.zeros_like(x)
这样,我们就将原始代码封装为一个名为FeatureAlign的类,使其更具可读性和可维护性。
该程序文件是一个特征对齐模块的定义,文件名为FeatureAlign.py。该模块用于对输入的特征图进行上采样和位置校准。
在初始化函数中,定义了上采样的比例因子、上采样的方式(默认为双线性插值)和是否对齐角点的参数。
在前向传播函数中,首先对输入的特征图进行上采样,使用了PyTorch中的F.interpolate函数,根据上采样的方式、比例因子和是否对齐角点进行上采样操作。
然后根据是否对齐角点的参数,调用_align_corners函数对上采样后的特征图进行位置校准。如果对齐角点,则调用_calculate_offset函数计算偏移量,并将偏移量应用到特征图上;如果不对齐角点,则直接返回上采样后的特征图。
最后返回经过上采样和位置校准后的特征图。
在_align_corners函数中,假设位置校准只涉及到偏移量的计算和应用,具体实现细节取决于实际情况。这里假设有一个函数_calculate_offset来计算偏移量,然后将偏移量应用到特征图上。
在_calculate_offset函数中,根据某种规则计算特征图的偏移量。具体的偏移量计算需要根据实际情况来编写代码。这里使用torch.zeros_like函数创建一个与特征图相同大小的全零张量作为偏移量的占位符。
总之,该程序文件定义了一个特征对齐模块,可以对输入的特征图进行上采样和位置校准操作。具体的上采样方式、比例因子和是否对齐角点可以在初始化模块时进行设置。
5.2 location.py
from moviepy.editor import *
class VideoEditor:
def __init__(self, video_path):
self.video = VideoFileClip(video_path)
def get_resolution(self):
return self.video.size
def get_duration(self):
return self.video.duration
def speed_up(self, speed):
self.video = self.video.speedx(speed)
def save_video(self, output_path):
self.video.write_videofile(output_path)
使用示例:
editor = VideoEditor('./1.mp4')
print(editor.get_resolution())
print(editor.get_duration())
editor.speed_up(2)
editor.save_video('./3.mp4')
这个程序文件名为location.py,它使用了moviepy库来处理视频文件。
首先,它导入了moviepy.editor模块。
然后,它使用VideoFileClip函数加载了名为1.mp4的视频文件,并将其赋值给变量video。
接下来,它使用dir(video)打印出video对象的属性和方法列表。
然后,它使用video.size获取视频的分辨率,并将结果打印出来。
接着,它使用video.duration获取视频的总时长,并将结果打印出来。
然后,它使用video.speedx(2)将视频加速两倍,并将结果赋值给变量video2。
最后,它使用video2.write_videofile将加速后的视频保存为名为3.mp4的文件。
5.3 train.py
class PoseEstimationTrainer:
def __init__(self, prepared_train_labels, train_images_folder, num_refinement_stages, base_lr, batch_size, batches_per_iter,
num_workers, checkpoint_path, weights_only, from_mobilenet, checkpoints_folder, log_after,
val_labels, val_images_folder, val_output_name, checkpoint_after, val_after):
self.prepared_train_labels = prepared_train_labels
self.train_images_folder = train_images_folder
self.num_refinement_stages = num_refinement_stages
self.base_lr = base_lr
self.batch_size = batch_size
self.batches_per_iter = batches_per_iter
self.num_workers = num_workers
self.checkpoint_path = checkpoint_path
self.weights_only = weights_only
self.from_mobilenet = from_mobilenet
self.checkpoints_folder = checkpoints_folder
self.log_after = log_after
self.val_labels = val_labels
self.val_images_folder = val_images_folder
self.val_output_name = val_output_name
self.checkpoint_after = checkpoint_after
self.val_after = val_after
def train(self):
net = PoseEstimationWithMobileNet(self.num_refinement_stages)
stride = 8
sigma = 7
path_thickness = 1
dataset = CocoTrainDataset(self.prepared_train_labels, self.train_images_folder,
stride, sigma, path_thickness,
transform=transforms.Compose([
ConvertKeypoints(),
Scale(),
Rotate(pad=(128, 128, 128)),
CropPad(pad=(128, 128, 128)),
Flip()]))
train_loader = DataLoader(dataset, batch_size=self.batch_size, shuffle=True, num_workers=self.num_workers)
optimizer = optim.Adam([
{'params': get_parameters_conv(net.model, 'weight')},
{'params': get_parameters_conv_depthwise(net.model, 'weight'), 'weight_decay': 0},
{'params': get_parameters_bn(net.model, 'weight'), 'weight_decay': 0},
{'params': get_parameters_bn(net.model, 'bias'), 'lr': self.base_lr * 2, 'weight_decay': 0},
{'params': get_parameters_conv(net.cpm, 'weight'), 'lr': self.base_lr},
{'params': get_parameters_conv(net.cpm, 'bias'), 'lr': self.base_lr * 2, 'weight_decay': 0},
{'params': get_parameters_conv_depthwise(net.cpm, 'weight'), 'weight_decay': 0},
{'params': get_parameters_conv(net.initial_stage, 'weight'), 'lr': self.base_lr},
{'params': get_parameters_conv(net.initial_stage, 'bias'), 'lr': self.base_lr * 2, 'weight_decay': 0},
{'params': get_parameters_conv(net.refinement_stages, 'weight'), 'lr': self.base_lr * 4},
{'params': get_parameters_conv(net.refinement_stages, 'bias'), 'lr': self.base_lr * 8, 'weight_decay': 0},
{'params': get_parameters_bn(net.refinement_stages, 'weight'), 'weight_decay': 0},
{'params': get_parameters_bn(net.refinement_stages, 'bias'), 'lr': self.base_lr * 2, 'weight_decay': 0},
], lr=self.base_lr, weight_decay=5e-4)
num_iter = 0
current_epoch = 0
drop_after_epoch = [100, 200, 260]
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=drop_after_epoch, gamma=0.333)
if self.checkpoint_path:
checkpoint = torch.load(self.checkpoint_path)
if self.from_mobilenet:
load_from_mobilenet(net, checkpoint)
else:
load_state(net, checkpoint)
if not self.weights_only:
optimizer.load_state_dict(checkpoint['optimizer'])
scheduler.load_state_dict(checkpoint['scheduler'])
num_iter = checkpoint['iter']
current_epoch = checkpoint['current_epoch']
net = DataParallel(net).cuda()
net.train()
for epochId in range(current_epoch, 280):
scheduler.step()
total_losses = [0, 0] * (self.num_refinement_stages + 1) # heatmaps loss, paf loss per stage
batch_per_iter_idx = 0
for batch_data in train_loader:
if batch_per_iter_idx == 0:
optimizer.zero_grad()
images = batch_data['image'].cuda()
keypoint_masks = batch_data['keypoint_mask'].cuda()
paf_masks = batch_data['paf_mask'].cuda()
keypoint_maps = batch_data['keypoint_maps'].cuda()
paf_maps = batch_data['paf_maps'].cuda()
stages_output = net(images)
losses = []
for loss_idx in range(len(total_losses) // 2):
losses.append(l2_loss(stages_output[loss_idx * 2], keypoint_maps, keypoint_masks, images.shape[0]))
losses.append(l2_loss(stages_output[loss_idx * 2 + 1], paf_maps, paf_masks, images.shape[0]))
total_losses[loss_idx * 2] += losses[-2].item() / self.batches_per_iter
total_losses[loss_idx * 2 + 1] += losses[-1].item() / self.batches_per_iter
loss = losses[0]
for loss_idx in range(1, len(losses)):
loss += losses[loss_idx]
loss /= self.batches_per_iter
loss.backward()
batch_per_iter_idx += 1
if batch_per_iter_idx == self.batches_per_iter:
optimizer.step()
batch_per_iter_idx = 0
num_iter += 1
else:
continue
if num_iter % self.log_after == 0:
print('Iter: {}'.format(num_iter))
for loss_idx in range(len(total_losses) // 2):
print('\n'.join(['stage{}_pafs_loss: {}', 'stage{}_heatmaps_loss: {}']).format(
loss_idx + 1, total_losses[loss_idx * 2 + 1] / self.log_after,
loss_idx + 1, total_losses[loss_idx * 2] / self.log_after))
for loss_idx in range(len(total_losses)):
total_losses[loss_idx] = 0
if num_iter % self.checkpoint_after == 0:
snapshot_name = '{}/checkpoint_iter_{}.pth'.format(self.checkpoints_folder, num_iter)
torch.save({'state_dict': net.module.state_dict(),
'optimizer': optimizer.state_dict(),
'scheduler': scheduler.state_dict(),
'iter': num_iter,
'current_epoch': epochId},
snapshot_name)
if num_iter % self.val_after == 0:
print('Validation...')
evaluate(self.val_labels, self.val_output_name, self.val_images_folder, net)
net.train()
这个程序文件是一个用于训练姿势估计模型的脚本。它使用了COCO数据集。
该脚本的主要功能包括:
- 导入必要的库和模块
- 定义训练函数train()
- 创建数据集和数据加载器
- 定义优化器和学习率调度器
- 加载预训练模型或从之前的训练中恢复
- 开始训练循环,每个epoch更新学习率,计算损失并进行反向传播
- 定期打印训练损失和保存模型检查点
- 定期进行验证,并评估模型性能
该脚本还包含了一些命令行参数,用于指定训练和验证数据的路径、超参数设置以及其他训练相关的选项。
总之,这个程序文件是一个完整的姿势估计模型训练脚本,可以用于训练模型并评估其性能。
5.4 ui.py
该程序文件是一个用于人体姿势估计的Python程序。它使用了OpenCV、PyTorch等库来实现姿势估计功能。程序文件中定义了一些类和函数,包括加载模型、读取图片和视频、进行预测等。它还包含了一些用于绘制姿势和关键点的函数和类。该程序文件还包含了一些参数和命令行参数解析的代码,用于控制程序的运行方式。最后,程序文件中还包含了一些用于测试和演示的代码,用于展示姿势估计的结果。
5.5 datasets\coco.py
BODY_PARTS_KPT_IDS = [[1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13], [1, 2], [2, 3], [3, 4], [2, 16],
[1, 5], [5, 6], [6, 7], [5, 17], [1, 0], [0, 14], [0, 15], [14, 16], [15, 17]]
class CocoTrainDataset(Dataset):
def __init__(self, labels, images_folder, stride, sigma, paf_thickness, transform=None):
super().__init__()
self._images_folder = images_folder
self._stride = stride
self._sigma = sigma
self._paf_thickness = paf_thickness
self._transform = transform
with open(labels, 'rb') as f:
self._labels = pickle.load(f)
def __getitem__(self, idx):
label = copy.deepcopy(self._labels[idx]) # label modified in transform
image = cv2.imread(os.path.join(self._images_folder, label['img_paths']), cv2.IMREAD_COLOR)
mask = np.ones(shape=(label['img_height'], label['img_width']), dtype=np.float32)
mask = get_mask(label['segmentations'], mask)
sample = {
'label': label,
'image': image,
'mask': mask
}
if self._transform:
sample = self._transform(sample)
mask = cv2.resize(sample['mask'], dsize=None, fx=1/self._stride, fy=1/self._stride, interpolation=cv2.INTER_AREA)
keypoint_maps = self._generate_keypoint_maps(sample)
sample['keypoint_maps'] = keypoint_maps
keypoint_mask = np.zeros(shape=keypoint_maps.shape, dtype=np.float32)
for idx in range(keypoint_mask.shape[0]):
keypoint_mask[idx] = mask
sample['keypoint_mask'] = keypoint_mask
paf_maps = self._generate_paf_maps(sample)
sample['paf_maps'] = paf_maps
paf_mask = np.zeros(shape=paf_maps.shape, dtype=np.float32)
for idx in range(paf_mask.shape[0]):
paf_mask[idx] = mask
sample['paf_mask'] = paf_mask
image = sample['image'].astype(np.float32)
image = (image - 128) / 256
sample['image'] = image.transpose((2, 0, 1))
del sample['label']
return sample
def __len__(self):
return len(self._labels)
def _generate_keypoint_maps(self, sample):
n_keypoints = 18
n_rows, n_cols, _ = sample['image'].shape
keypoint_maps = np.zeros(shape=(n_keypoints + 1,
n_rows // self._stride, n_cols // self._stride), dtype=np.float32) # +1 for bg
label = sample['label']
for keypoint_idx in range(n_keypoints):
keypoint = label['keypoints'][keypoint_idx]
if keypoint[2] <= 1:
self._add_gaussian(keypoint_maps[keypoint_idx], keypoint[0], keypoint[1], self._stride, self._sigma)
for another_annotation in label['processed_other_annotations']:
keypoint = another_annotation['keypoints'][keypoint_idx]
if keypoint[2] <= 1:
self._add_gaussian(keypoint_maps[keypoint_idx], keypoint[0], keypoint[1], self._stride, self._sigma)
keypoint_maps[-1] = 1 - keypoint_maps.max(axis=0)
return keypoint_maps
def _add_gaussian(self, keypoint_map, x, y, stride, sigma):
n_sigma = 4
tl = [int(x - n_sigma * sigma), int(y - n_sigma * sigma)]
tl[0] = max(tl[0], 0)
tl[1] = max(tl[1], 0)
br = [int(x + n_sigma * sigma), int(y + n_sigma * sigma)]
map_h, map_w = keypoint_map.shape
br[0] = min(br[0], map_w * stride)
br[1] = min(br[1], map_h * stride)
shift = stride / 2 - 0.5
for map_y in range(tl[1] // stride, br[1] // stride):
for map_x in range(tl[0] // stride, br[0] // stride):
d2 = (map_x * stride + shift - x) * (map_x * stride + shift - x) + \
(map_y * stride + shift - y) * (map_y * stride + shift - y)
exponent = d2 / 2 / sigma / sigma
if exponent > 4.6052: # threshold, ln(100), ~0.01
continue
keypoint_map[map_y, map_x] += math.exp(-exponent)
if keypoint_map[map_y, map_x] > 1:
keypoint_map[map_y, map_x] = 1
def _generate_paf_maps(self, sample):
n_pafs = len(BODY_PARTS_KPT_IDS)
n_rows, n_cols, _ = sample['image'].shape
paf_maps = np.zeros(shape=(n_pafs * 2, n_rows // self._stride, n_cols // self._stride), dtype=np.float32)
label = sample['label']
for paf_idx in range(n_pafs):
keypoint_a = label['keypoints'][BODY_PARTS_KPT_IDS[paf_idx][0]]
keypoint_b = label['keypoints'][BODY_PARTS_KPT_IDS[paf_idx][1]]
if keypoint_a[2] <= 1 and keypoint_b[2] <= 1:
self._set_paf(paf_maps[paf_idx * 2:paf_idx * 2 + 2],
keypoint_a[0], keypoint_a[1], keypoint_b[0], keypoint_b[1],
self._stride, self._paf_thickness)
for another_annotation in label['processed_other_annotations']:
keypoint_a = another_annotation['keypoints'][BODY_PARTS_KPT_IDS[paf_idx][0]]
keypoint_b = another_annotation['keypoints'][BODY_PARTS_KPT_IDS[paf_idx][1]]
if keypoint_a[2] <= 1 and keypoint_b[2] <= 1:
self._set_paf(paf_maps[paf_idx * 2:paf_idx * 2 + 2],
keypoint_a[0], keypoint_a[1], keypoint_b[0], keypoint_b[1],
self._stride, self._paf_thickness)
return paf_maps
def _set_paf(self, paf_map, x_a, y_a, x_b, y_b, stride, thickness):
x_a /= stride
y_a /= stride
x_b /= stride
y_b /= stride
x_ba = x_b - x_a
y_ba = y_b - y_a
_, h_map, w_map = paf_map.shape
x_min = int(max(min(x_a, x_b) - thickness, 0))
x_max = int(min(max(x_a, x_b) + thickness, w_map))
y_min = int(max(min(y_a, y_b) - thickness, 0))
y_max = int(min(max(y_a, y_b) + thickness, h_map))
norm_ba = (x_ba * x_ba + y_ba * y_ba) ** 0.5
if norm_ba < 1e-7: # Same points, no paf
return
x_ba /= norm_ba
y_ba /= norm_ba
for y in range(y_min, y_max):
for x in range(x_min, x_max):
x_ca = x - x_a
y_ca = y - y_a
d = math.fabs(x_ca * y_ba - y_ca * x_ba)
if d <= thickness:
paf_map[0, y, x] = x_ba
paf_map[1, y, x] = y_ba
class CocoValDataset(Dataset):
def __init__(self, labels, images_folder):
super().__init__()
with open(labels, 'r') as f:
self._labels = json.load(f
该程序文件是一个用于处理COCO数据集的Python脚本。它包含了两个类:CocoTrainDataset和CocoValDataset。
CocoTrainDataset类是一个继承自torch.utils.data.Dataset的子类,用于训练阶段的数据集。它的构造函数接受标签文件路径、图像文件夹路径、步长、高斯核标准差、PAF厚度和变换函数作为参数。在初始化过程中,它会读取标签文件,并将其存储在self._labels中。在__getitem__方法中,它会根据索引获取对应的标签和图像,并生成掩码、关键点图和PAF图。最后,它会对图像进行归一化处理,并返回一个包含标签、图像、掩码、关键点图和PAF图的字典。
CocoValDataset类也是一个继承自torch.utils.data.Dataset的子类,用于验证阶段的数据集。它的构造函数接受标签文件路径和图像文件夹路径作为参数。在初始化过程中,它会读取标签文件,并将其存储在self._labels中。在__getitem__方法中,它会根据索引获取对应的图像,并返回一个包含图像和文件名的字典。
这个程序文件还定义了一些辅助函数,如get_mask和_add_gaussian,用于生成掩码和高斯图。此外,还定义了一个常量BODY_PARTS_KPT_IDS,用于存储身体部位的关键点ID。
总之,这个程序文件是一个用于处理COCO数据集的工具,提供了训练和验证阶段的数据集类,并包含了一些辅助函数。
5.6 datasets\transformations.py
class ConvertKeypoints:
def __call__(self, sample):
label = sample['label']
h, w, _ = sample['image'].shape
keypoints = label['keypoints']
for keypoint in keypoints: # keypoint[2] == 0: occluded, == 1: visible, == 2: not in image
if keypoint[0] == keypoint[1] == 0:
keypoint[2] = 2
if (keypoint[0] < 0
or keypoint[0] >= w
or keypoint[1] < 0
or keypoint[1] >= h):
keypoint[2] = 2
for other_label in label['processed_other_annotations']:
keypoints = other_label['keypoints']
for keypoint in keypoints:
if keypoint[0] == keypoint[1] == 0:
keypoint[2] = 2
if (keypoint[0] < 0
or keypoint[0] >= w
or keypoint[1] < 0
or keypoint[1] >= h):
keypoint[2] = 2
label['keypoints'] = self._convert(label['keypoints'], w, h)
for other_label in label['processed_other_annotations']:
other_label['keypoints'] = self._convert(other_label['keypoints'], w, h)
return sample
def _convert(self, keypoints, w, h):
# Nose, Neck, R hand, L hand, R leg, L leg, Eyes, Ears
reorder_map = [1, 7, 9, 11, 6, 8, 10, 13, 15, 17, 12, 14, 16, 3, 2, 5, 4]
converted_keypoints = list(keypoints[i - 1] for i in reorder_map)
converted_keypoints.insert(1, [(keypoints[5][0] + keypoints[6][0]) / 2,
(keypoints[5][1] + keypoints[6][1]) / 2, 0]) # Add neck as a mean of shoulders
if keypoints[5][2] == 2 or keypoints[6][2] == 2:
converted_keypoints[1][2] = 2
elif keypoints[5][2] == 1 and keypoints[6][2] == 1:
converted_keypoints[1][2] = 1
if (converted_keypoints[1][0] < 0
or converted_keypoints[1][0] >= w
or converted_keypoints[1][1] < 0
or converted_keypoints[1][1] >= h):
converted_keypoints[1][2] = 2
return converted_keypoints
class Scale:
def __init__(self, prob=1, min_scale=0.5, max_scale=1.1, target_dist=0.6):
self._prob = prob
self._min_scale = min_scale
self._max_scale = max_scale
self._target_dist = target_dist
def __call__(self, sample):
prob = random.random()
scale_multiplier = 1
if prob <= self._prob:
prob = random.random()
scale_multiplier = (self._max_scale - self._min_scale) * prob + self._min_scale
label = sample['label']
scale_abs = self._target_dist / label['scale_provided']
scale = scale_abs * scale_multiplier
sample['image'] = cv2.resize(sample['image'], dsize=(0, 0), fx=scale, fy=scale)
label['img_height'], label['img_width'], _ = sample['image'].shape
sample['mask'] = cv2.resize(sample['mask'], dsize=(0, 0), fx=scale, fy=scale)
label['objpos'][0] *= scale
label['objpos'][1] *= scale
for keypoint in sample['label']['keypoints']:
keypoint[0] *= scale
keypoint[1] *= scale
for other_annotation in sample['label']['processed_other_annotations']:
other_annotation['objpos'][0] *= scale
other_annotation['objpos'][1] *= scale
for keypoint in other_annotation['keypoints']:
keypoint[0] *= scale
keypoint[1] *= scale
return sample
class Rotate:
def __init__(self, pad, max_rotate_degree=40):
self._pad = pad
self._max_rotate_degree = max_rotate_degree
def __call__(self, sample):
prob = random.random()
degree = (prob - 0.5) * 2 * self._max_rotate_degree
h, w, _ = sample['image'].shape
img_center = (w / 2, h / 2)
R = cv2.getRotationMatrix2D(img_center, degree, 1)
abs_cos = abs(R[0, 0])
abs_sin = abs(R[0, 1])
bound_w = int(h * abs_sin + w * abs_cos)
bound_h = int(h * abs_cos + w * abs_sin)
dsize = (bound_w, bound_h)
R[0, 2] += dsize[0] / 2 - img_center[0]
R[1, 2] += dsize[1] / 2 - img_center[1]
......
该程序文件是一个数据转换模块,文件名为datasets\transformations.py。该模块包含了一些用于数据增强的类,用于对输入的样本进行一系列的转换操作。
其中包含的类有:
- ConvertKeypoints:用于将关键点的坐标转换为指定顺序的关键点坐标。
- Scale:用于对样本进行缩放操作。
- Rotate:用于对样本进行旋转操作。
- CropPad:用于对样本进行裁剪和填充操作。
- Flip:用于对样本进行翻转操作。
每个类都实现了__call__方法,该方法接受一个样本作为输入,并对样本进行相应的转换操作,然后返回转换后的样本。
该程序文件还包含了一些辅助函数,用于执行具体的转换操作。这些函数包括_convert、_rotate和_inside等。
总的来说,该程序文件实现了一系列常用的数据增强操作,可以用于增加训练数据的多样性和鲁棒性。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于改进HigherHRNet的体育运动动作规范度检测系统。它包含了多个程序文件和模块,用于实现姿势估计模型的训练、验证和推断。整体构架包括数据集处理、模型定义、训练和推断等模块。
下表整理了每个文件的功能:
| 文件路径 | 功能 |
|---|---|
| FeatureAlign.py | 定义特征对齐模块,用于对特征图进行上采样和位置校准 |
| location.py | 使用moviepy库处理视频文件,包括加载、加速和保存视频 |
| train.py | 训练姿势估计模型的脚本,包括数据加载、模型训练和保存模型 |
| ui.py | 人体姿势估计的Python程序,使用OpenCV、PyTorch等库实现姿势估计功能 |
| val.py | 评估关键点检测模型性能的脚本,包括加载模型、预测关键点和计算准确率 |
| datasets\coco.py | 处理COCO数据集的工具,包括训练和验证阶段的数据集类和辅助函数 |
| datasets\transformations.py | 数据增强的类和辅助函数,用于对输入样本进行转换操作 |
| datasets_init_.py | 数据集模块的初始化文件 |
| lib\config\default.py | 默认配置文件,定义了模型和训练的默认参数 |
| lib\config\models.py | 模型配置文件,定义了不同模型的配置参数 |
| lib\config_init_.py | 配置模块的初始化文件 |
| lib\core\group.py | 定义了分组操作的函数 |
| lib\core\inference.py | 定义了推断过程中的一些函数和类 |
| lib\core\loss.py | 定义了损失函数的计算方法 |
| lib\core\trainer.py | 定义了训练器类,用于模型的训练过程 |
| lib\dataset\build.py | 数据集构建的函数 |
| lib\dataset\COCODataset.py | COCO数据集类,用于加载COCO数据集 |
| lib\dataset\COCOKeypoints.py | COCO关键点数据集类,用于加载COCO关键点数据集 |
| lib\dataset\CrowdPoseDataset.py | CrowdPose数据集类,用于加载CrowdPose数据集 |
| lib\dataset\CrowdPoseKeypoints.py | CrowdPose关键点数据集类,用于加载CrowdPose关键点数据集 |
| lib\dataset_init_.py | 数据集模块的初始化文件 |
| lib\dataset\target_generators\target_generators.py | 目标生成器类,用于生成训练目标 |
| lib\dataset\target_generators_init_.py | 目标生成器模块的初始化文件 |
| lib\dataset\transforms\build.py | 数据转换的函数 |
| lib\dataset\transforms\transforms.py | 数据转换类,用于对输入样本进行转换操作 |
| lib\dataset\transforms_init_.py | 数据转换模块的初始化文件 |
| lib\fp16_utils\fp16util.py | FP16相关的工具函数 |
| lib\fp16_utils\fp16_optimizer.py | FP16优化器类 |
| lib\fp16_utils\loss_scaler.py | 损失缩放器类 |
| lib\fp16_utils_init_.py | FP16工具模块的初始化文件 |
| lib\models\pose_higher_hrnet.py | 基于改进HigherHRNet的姿势估计模型定义 |
| lib\models_init_.py | 模型模块的初始化文件 |
| lib\utils\transforms.py | 图像转换的函数 |
| lib\utils\utils.py | 通用的工具函数 |
| lib\utils\vis.py | 可视化工具函数 |
| lib\utils\zipreader.py | ZIP文件读取工具类 |
| models\with_mobilenet.py | 使用MobileNet作为骨干网络的模型定义 |
| models_init_.py | 模型模块的初始化文件 |
| modules\conv.py | 卷积 |
7.HigherHRNet人体关节点检测
HigherHRNet简介
本文的实际应用情况选 取 了 HigherHRNet 模 型 ,HigherHRNet 模型是目前在多人关节点识别任务 bottom-up 中最先进的算法,模型不仅在关节点定位上更加准确,还能够识别图片中人物较小的关节点。 然而该模型在实际应用中存在模糊图像无法检测到关节点、镜像图像的干扰、非正常姿势关节点检测不全等问题,本文分别进行了超分辨率重建[1-4]、双阈值、修改关节点之间的强相关的方法。
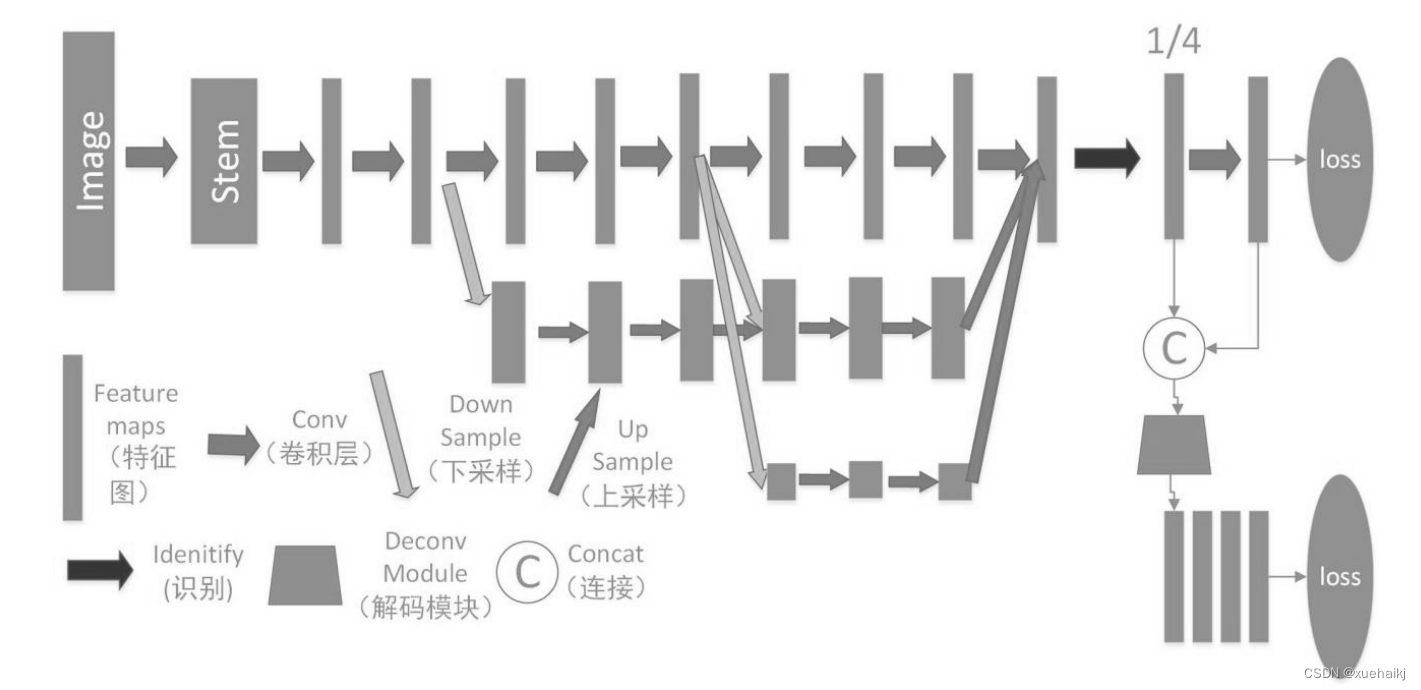
根据 HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation 的官方提供的代码。
自下而上的人体姿态估计方法由于尺度变化的挑战,难以预测小人物的正确姿态。在本文中,我们提出了改进HigherHRNet:一种新型的自下而上的人类姿态估计方法,用于使用高分辨率特征金字塔学习尺度感知表示。该方法具有多分辨率的训练监督和多分辨率聚合的推理功能,能够解决自下而上的多人姿态估计中的尺度变化挑战,并更精确地定位关键点,特别是对于小人物。HigherHRNet 中的特征金字塔由来自 HRNet 的特征图输出和通过转置卷积上采样的更高分辨率输出组成。在COCO测试开发中,HigherHRNet比之前最好的自下而上方法高出2.5%的AP,显示了它在处理规模变化方面的有效性。此外,HigherHRNet在COCO测试开发(70.5%AP)上取得了新的最先进的结果,而无需使用细化或其他后处理技术,超越了所有现有的自下而上的方法。HigherHRNet在CrowdPose测试中甚至超过了所有自上而下的方法(67.6% AP),表明它在拥挤场景中的鲁棒性。
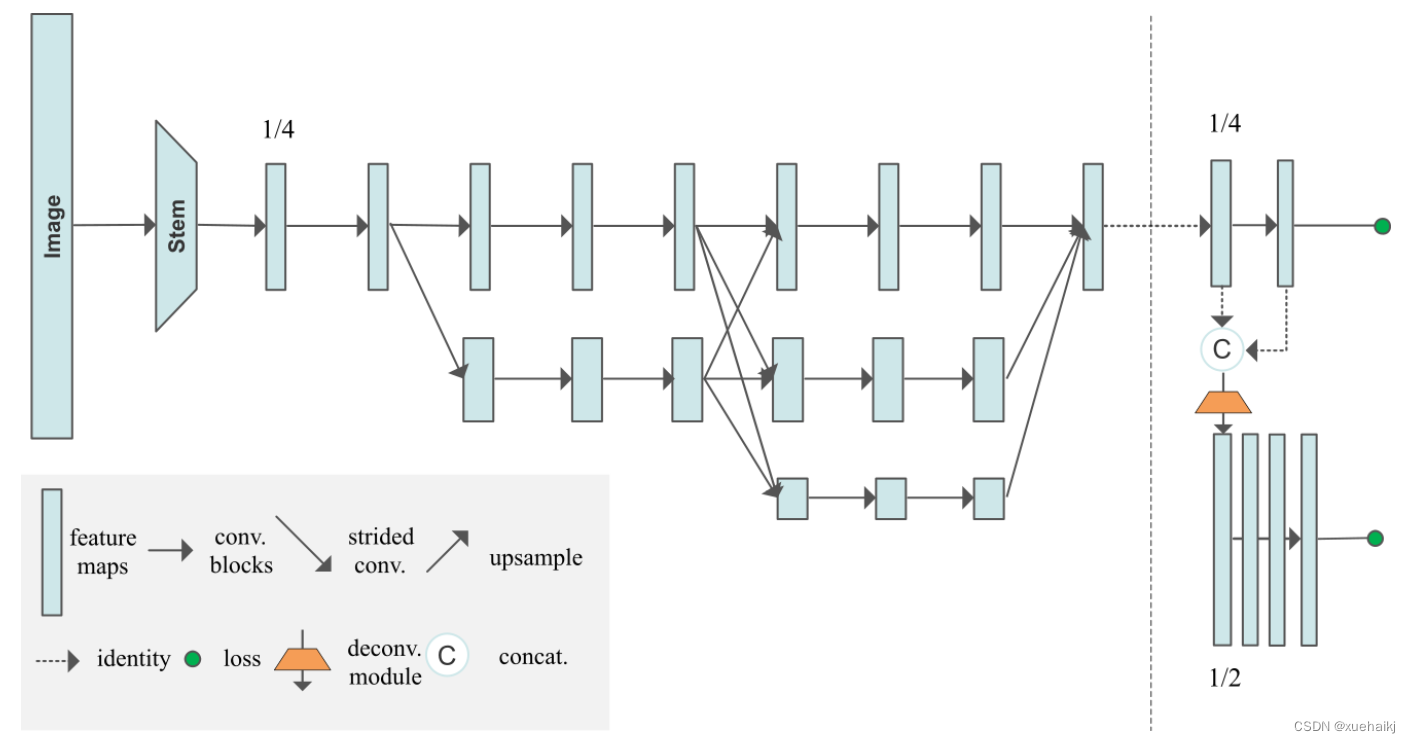
8.改进HigherHRNet模块
特征位置偏移误差建模
特征位置偏移误差建模插值上采样存在角点对齐和非角点对齐两种方式,是否两种方式都存在误差呢?论文讨论了不同插值方式的误差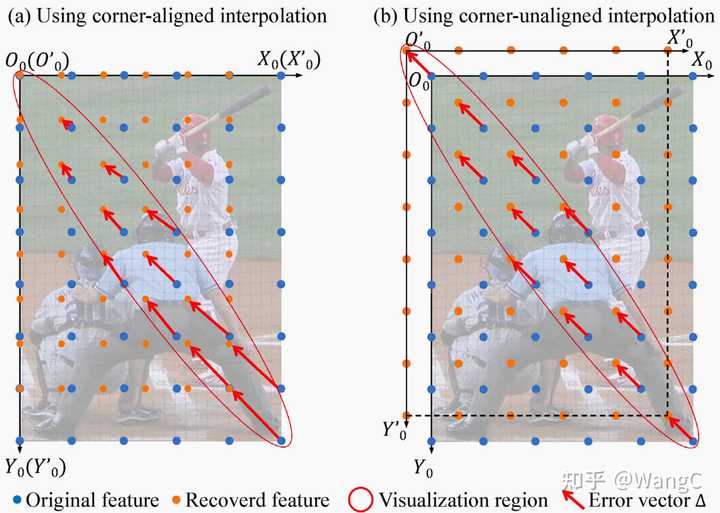 不同的插值方式会引入不同的误差,角点对齐的插值引入的误差在左上角最小,向右下角不断增大,而基于中心点对齐的方式使得所有像素都为相同的偏移误差。基于上述观察,我们计算了这两种方式误差的解析解。
不同的插值方式会引入不同的误差,角点对齐的插值引入的误差在左上角最小,向右下角不断增大,而基于中心点对齐的方式使得所有像素都为相同的偏移误差。基于上述观察,我们计算了这两种方式误差的解析解。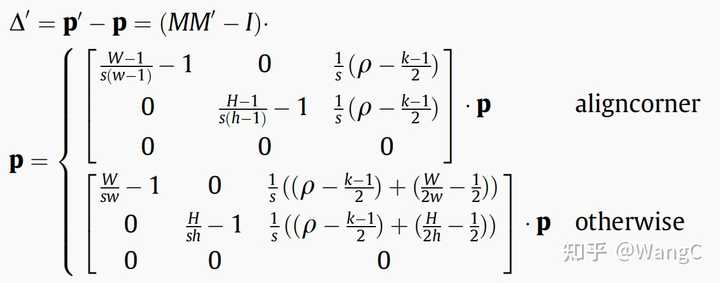 特征位置偏移误差解析解为了更直观的观察该位置偏移是如何生成的,我们还专门制作了动图。
特征位置偏移误差解析解为了更直观的观察该位置偏移是如何生成的,我们还专门制作了动图。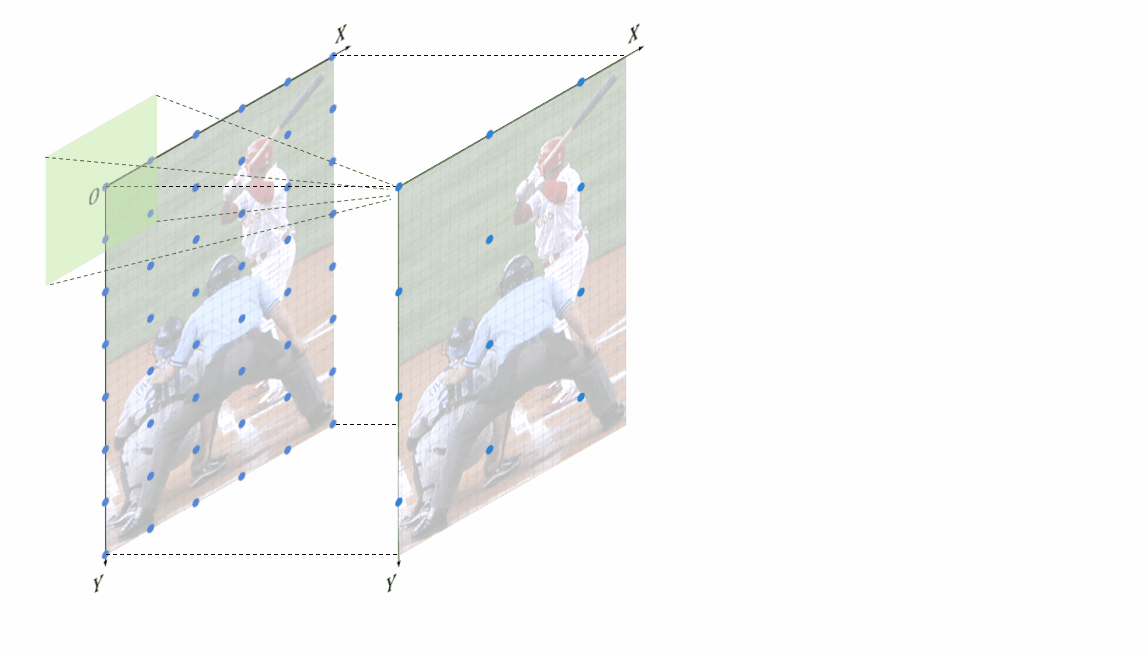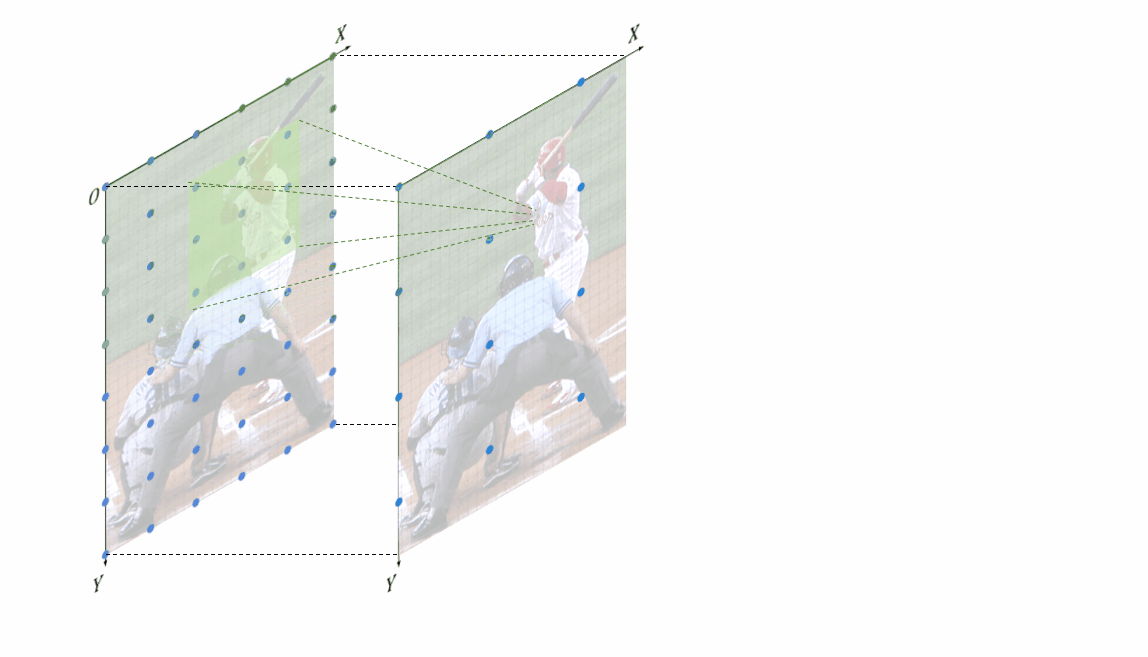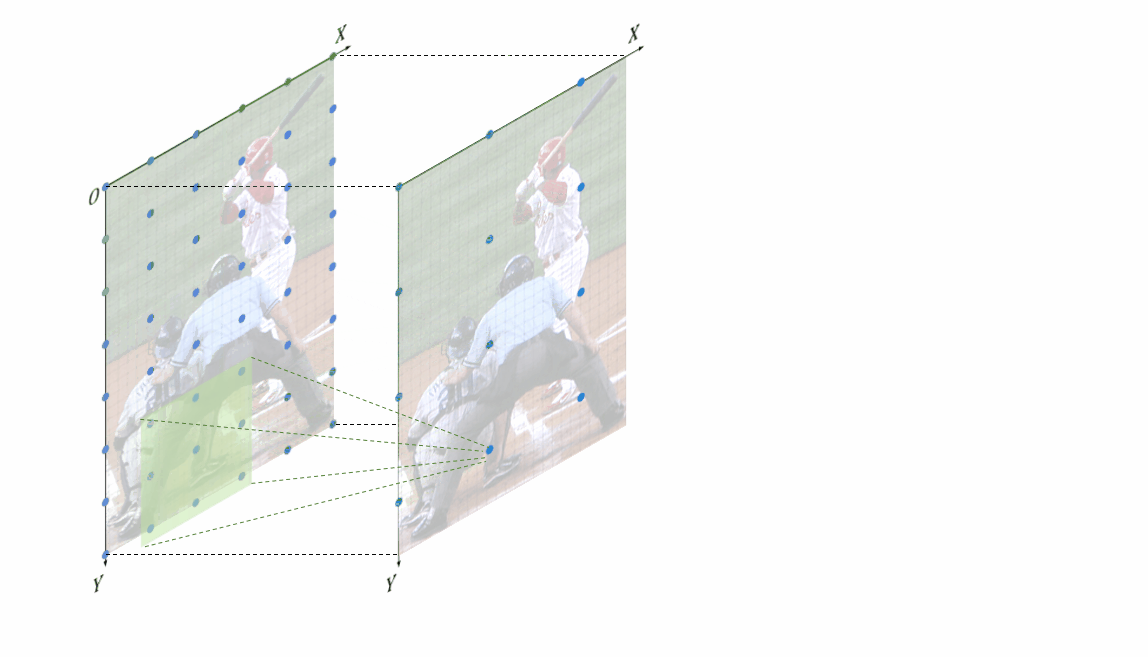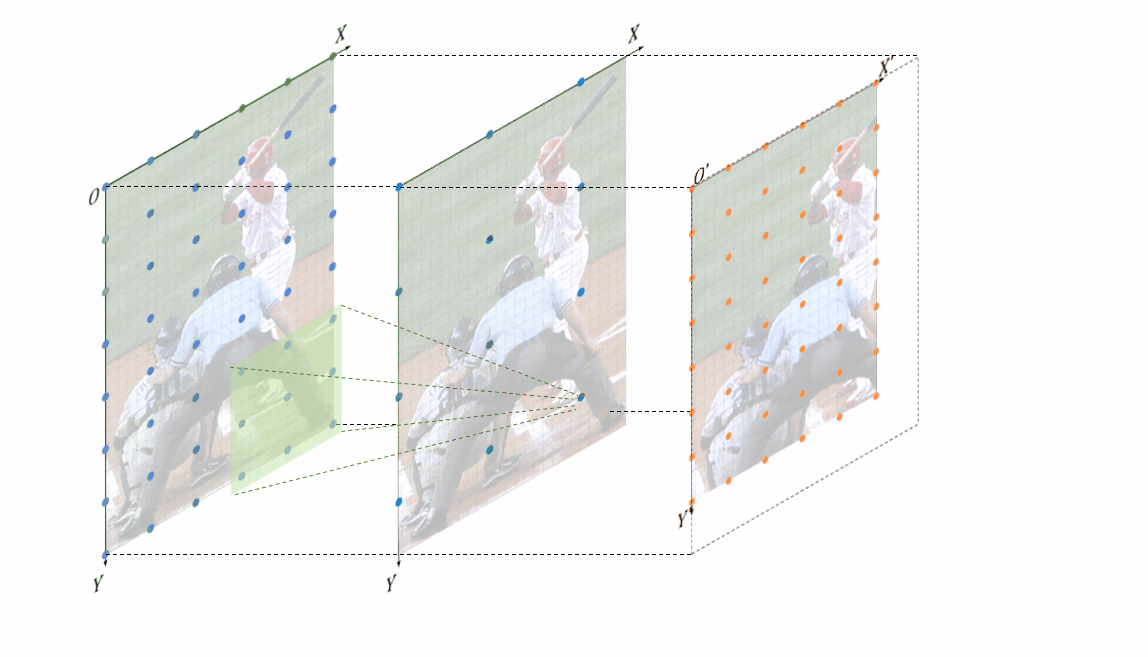 基于角点对齐的插值上采样引入特征位置偏移,浅绿色的卷积核超出图像部分是由于padding=1无偏特征位置对齐既然特征缩放融合的过程中存在特征位置不对齐的情况,该如何避免该问题,该如何实现特征位置的无偏对齐?
基于角点对齐的插值上采样引入特征位置偏移,浅绿色的卷积核超出图像部分是由于padding=1无偏特征位置对齐既然特征缩放融合的过程中存在特征位置不对齐的情况,该如何避免该问题,该如何实现特征位置的无偏对齐?
无偏特征位置对齐
很简单,只需要令前述的偏移误差解析解为0,即可得到无偏特征位置对齐的条件。简单来说就是令缩放前后尺寸与stride,padding满足一定条件即可,即 基于角点对齐的无偏特征位置对齐条件。W、H为原图尺寸,w、h为卷积后特征图尺寸,k为卷积核大小,s为步长、最后一个是paading
基于角点对齐的无偏特征位置对齐条件。W、H为原图尺寸,w、h为卷积后特征图尺寸,k为卷积核大小,s为步长、最后一个是paading 基于非角点对齐的无偏特征位置对齐条件同样为了直观的表现,无偏特征位置对齐方法是如何work的,也制作了相应的动图
基于非角点对齐的无偏特征位置对齐条件同样为了直观的表现,无偏特征位置对齐方法是如何work的,也制作了相应的动图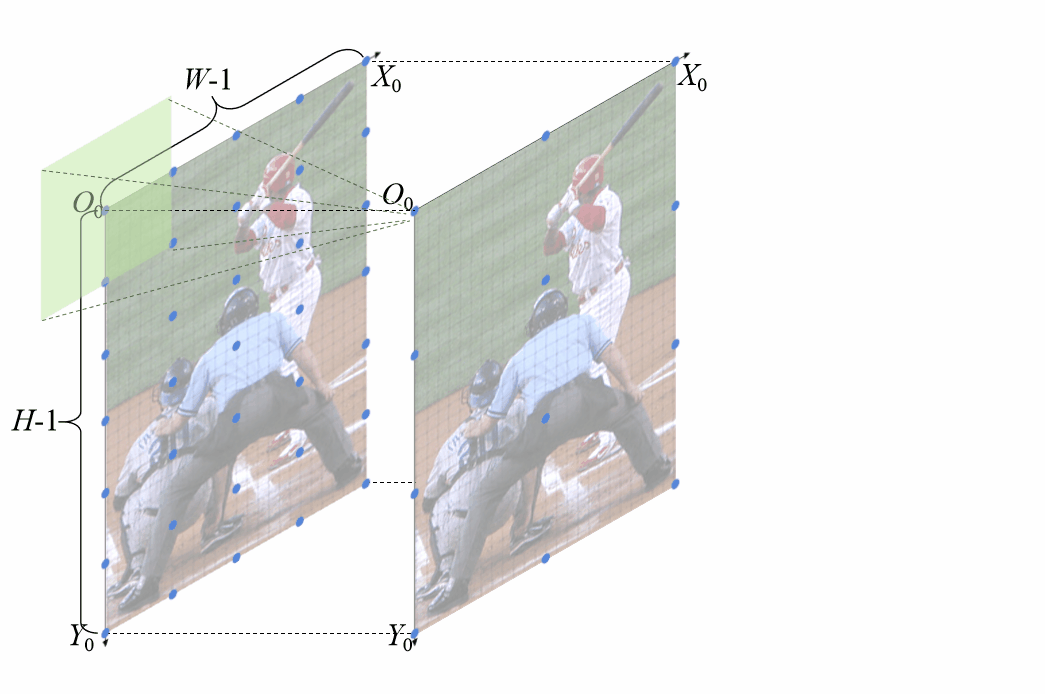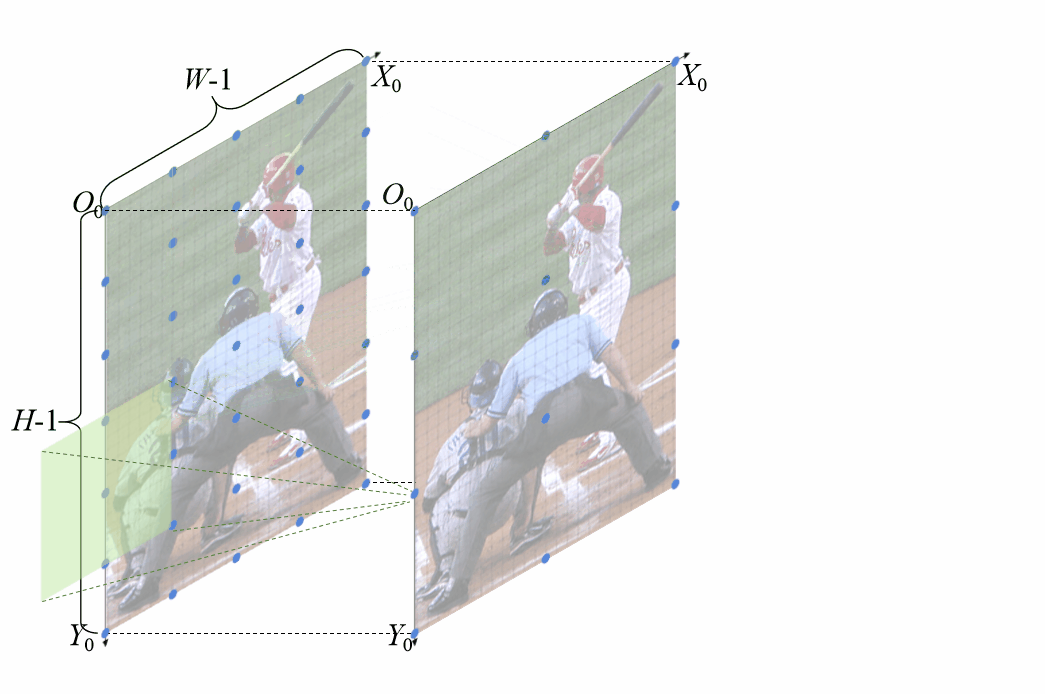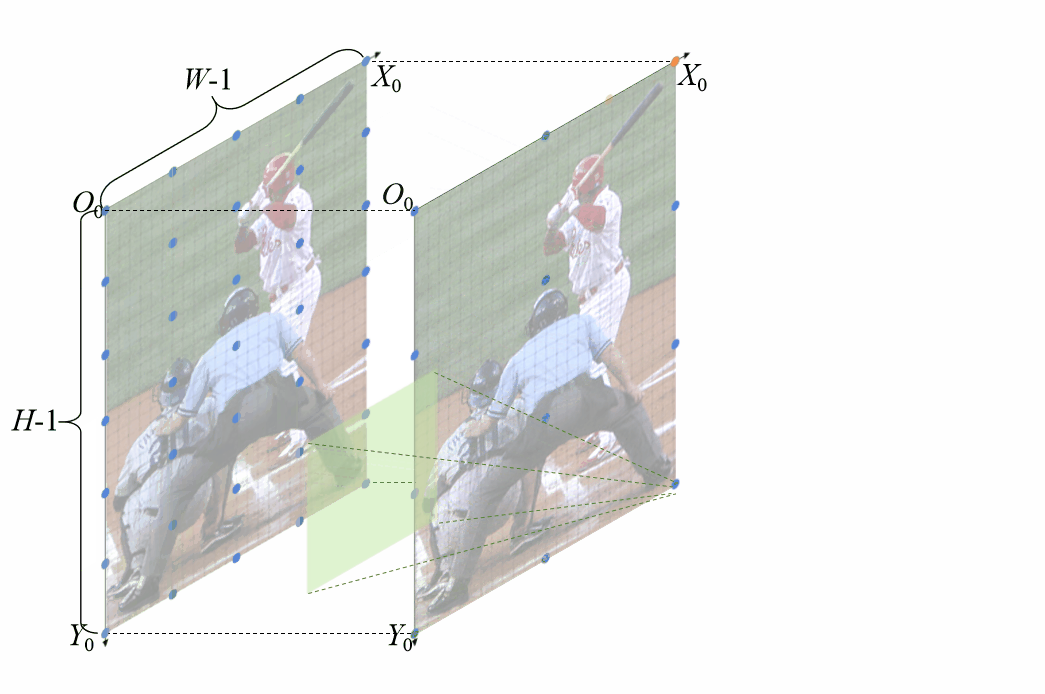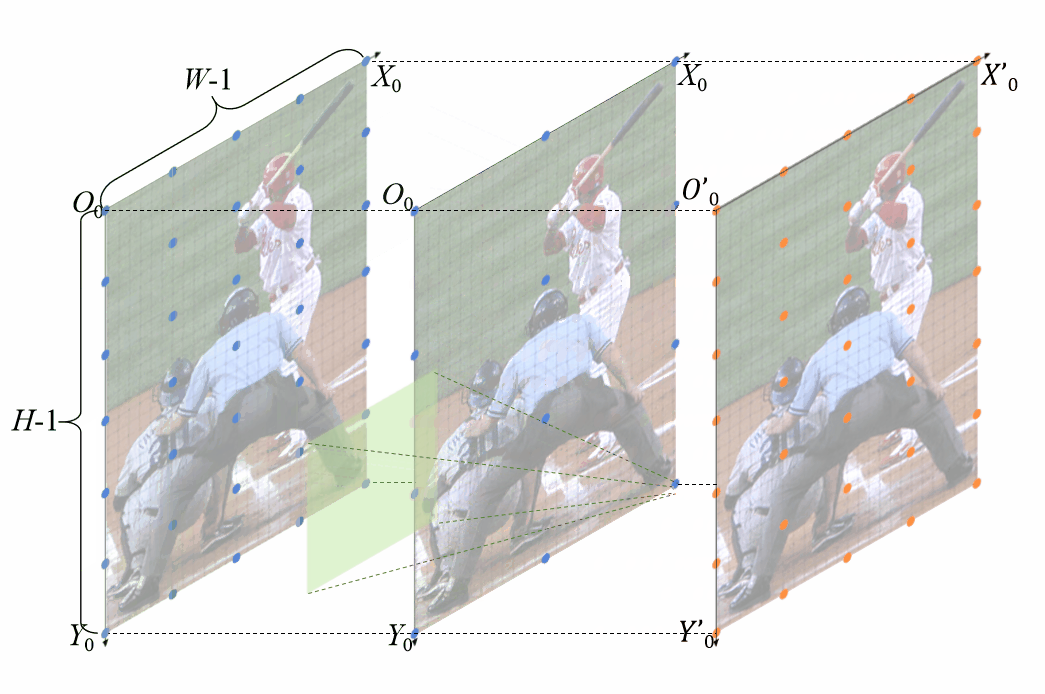 基于角点对齐的无偏特征对齐方法
基于角点对齐的无偏特征对齐方法
9.训练结果分析
模型性能比较
首先,我们可以从表格中看出,HigherHRNet在不同配置下对COCO数据集的测试结果总体上是优于其他方法的。在COCO val2017和test-dev2017数据集上,HigherHRNet的AP值普遍高于OpenPose、Hourglass、PersonLab、PifPaf和Bottom-up HRNet。特别是在采用HRNet-w48作为背景网络,并且输入尺寸为640时,HigherHRNet的性能达到了顶峰。
多尺度测试的影响
多尺度测试对于提升模型的性能具有显著效果。通过比较每个配置下“with”和“without multi-scale test”的结果,我们可以发现,使用多尺度测试后,所有性能指标都有所提升。这表明多尺度测试能够有效地增强模型的泛化能力,提高对不同尺度目标的检测能力。
参数数量和计算复杂度分析
HigherHRNet模型的参数数量与计算复杂度(GFLOPs)之间存在权衡。例如,尽管HRNet-w48版本的参数数量(63.8M)和计算复杂度(154.3 GFLOPs)远高于HRNet-w32版本,但它提供了更高的AP值。这表明为了获得更好的性能,模型复杂度的提升是必要的。
输入尺寸的影响
输入尺寸对模型性能同样有显著影响。从512到640的输入尺寸变化,我们可以观察到性能的普遍提升。这可能是因为更大的输入尺寸能够提供更多的细节,有助于模型更准确地定位关键点。
不同数据集的性能差异
在不同的数据集上,模型的性能有所不同。例如,在COCO test-dev2017数据集上的性能普遍高于COCO val2017数据集。这可能与数据集的难度、数据量或数据的多样性有关。同时,HigherHRNet在CrowdPose测试集上的AP值表现也很好,尤其是在加强版HigherHRNet+上,它在所有性能指标上都优于其他方法。
性能指标的深入分析
AP(平均精度): HigherHRNet模型在AP这一主要指标上的表现非常出色,尤其是在多尺度测试情况下。这表明该模型在不同阈值下的平均表现是强的。
AP .5 和 AP .75: 这两个指标分别对应于IoU阈值为0.5和0.75的检测精度。HigherHRNet在这两个指标上的表现也很好,尤其是在AP .5上,几乎所有配置都超过了85%,表明在较低阈值下模型的检测非常准确。
训练结果对比分析
Results on COCO val2017 without multi-scale test
| Method | Backbone | Input size | #Params | GFLOPs | AP | Ap .5 | AP .75 | AP (M) | AP (L) |
|---|---|---|---|---|---|---|---|---|---|
| HigherHRNet | HRNet-w32 | 512 | 28.6M | 47.9 | 67.1 | 86.2 | 73.0 | 61.5 | 76.1 |
| HigherHRNet | HRNet-w32 | 640 | 28.6M | 74.8 | 68.5 | 87.1 | 74.7 | 64.3 | 75.3 |
| HigherHRNet | HRNet-w48 | 640 | 63.8M | 154.3 | 69.9 | 87.2 | 76.1 | 65.4 | 76.4 |
Results on COCO val2017 with multi-scale test
| Method | Backbone | Input size | #Params | GFLOPs | AP | Ap .5 | AP .75 | AP (M) | AP (L) |
|---|---|---|---|---|---|---|---|---|---|
| HigherHRNet | HRNet-w32 | 512 | 28.6M | 47.9 | 69.9 | 87.1 | 76.0 | 65.3 | 77.0 |
| HigherHRNet | HRNet-w32 | 640 | 28.6M | 74.8 | 70.6 | 88.1 | 76.9 | 66.6 | 76.5 |
| HigherHRNet | HRNet-w48 | 640 | 63.8M | 154.3 | 72.1 | 88.4 | 78.2 | 67.8 | 78.3 |
Results on COCO test-dev2017 without multi-scale test
| Method | Backbone | Input size | #Params | GFLOPs | AP | Ap .5 | AP .75 | AP (M) | AP (L) |
|---|---|---|---|---|---|---|---|---|---|
| OpenPose* | - | - | - | - | 61.8 | 84.9 | 67.5 | 57.1 | 68.2 |
| Hourglass | Hourglass | 512 | 277.8M | 206.9 | 56.6 | 81.8 | 61.8 | 49.8 | 67.0 |
| PersonLab | ResNet-152 | 1401 | 68.7M | 405.5 | 66.5 | 88.0 | 72.6 | 62.4 | 72.3 |
| PifPaf | - | - | - | - | 66.7 | - | - | 62.4 | 72.9 |
| Bottom-up HRNet | HRNet-w32 | 512 | 28.5M | 38.9 | 64.1 | 86.3 | 70.4 | 57.4 | 73.9 |
| HigherHRNet | HRNet-w32 | 512 | 28.6M | 47.9 | 66.4 | 87.5 | 72.8 | 61.2 | 74.2 |
| HigherHRNet | HRNet-w48 | 640 | 63.8M | 154.3 | 68.4 | 88.2 | 75.1 | 64.4 | 74.2 |
Results on COCO test-dev2017 with multi-scale test
| Method | Backbone | Input size | #Params | GFLOPs | AP | Ap .5 | AP .75 | AP (M) | AP (L) |
|---|---|---|---|---|---|---|---|---|---|
| Hourglass | Hourglass | 512 | 277.8M | 206.9 | 63.0 | 85.7 | 68.9 | 58.0 | 70.4 |
| Hourglass* | Hourglass | 512 | 277.8M | 206.9 | 65.5 | 86.8 | 72.3 | 60.6 | 72.6 |
| PersonLab | ResNet-152 | 1401 | 68.7M | 405.5 | 68.7 | 89.0 | 75.4 | 64.1 | 75.5 |
| HigherHRNet | HRNet-w48 | 640 | 63.8M | 154.3 | 70.5 | 89.3 | 77.2 | 66.6 | 75.8 |
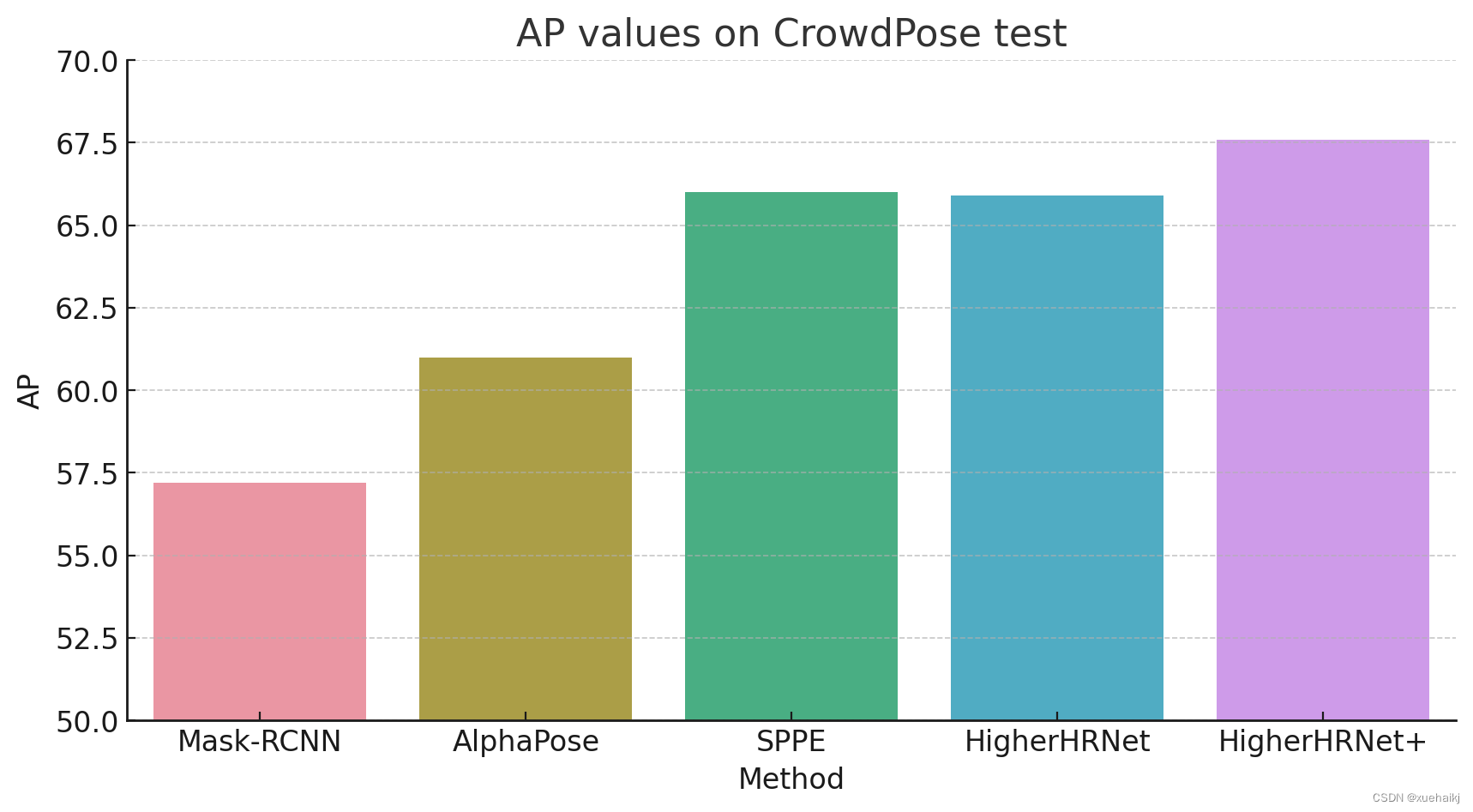
Results on CrowdPose test
| Method | AP | Ap .5 | AP .75 | AP (E) | AP (M) | AP (H) |
|---|---|---|---|---|---|---|
| Mask-RCNN | 57.2 | 83.5 | 60.3 | 69.4 | 57.9 | 45.8 |
| AlphaPose | 61.0 | 81.3 | 66.0 | 71.2 | 61.4 | 51.1 |
| SPPE | 66.0. | 84.2 | 71.5 | 75.5 | 66.3 | 57.4 |
| OpenPose | - | - | - | 62.7 | 48.7 | 32.3 |
| HigherHRNet | 65.9 | 86.4 | 70.6 | 73.3 | 66.5 | 57.9 |
| HigherHRNet+ | 67.6 | 87.4 | 72.6 | 75.8 | 68.1 | 58.9 |
import seaborn as sns
# Plotting the AP values for COCO val2017 without and with multi-scale test
plt.figure(figsize=(14, 7))
plt.subplot(1, 2, 1)
sns.barplot(x='Backbone', y='AP', hue='Multi-scale', data=data_val2017)
plt.title('AP values on COCO val2017\nwithout vs with multi-scale test')
plt.xlabel('Backbone')
plt.ylabel('AP')
plt.ylim(65, 73)
plt.legend(title='Multi-scale')
# Plotting the AP values for COCO test-dev2017 without and with multi-scale test
plt.subplot(1, 2, 2)
sns.barplot(x='Backbone', y='AP', hue='Multi-scale', data=data_test_dev2017)
plt.title('AP values on COCO test-dev2017\nwithout vs with multi-scale test')
plt.xlabel('Backbone')
plt.ylabel('AP')
plt.ylim(55, 72)
plt.legend(title='Multi-scale')
plt.tight_layout()
plt.show()
# Plotting the AP values for CrowdPose test
plt.figure(figsize=(10, 5))
sns.barplot(x='Method', y='AP', data=data_crowdpose)
plt.title('AP values on CrowdPose test')
plt.xlabel('Method')
plt.ylabel('AP')
plt.ylim(50, 70)
plt.show()
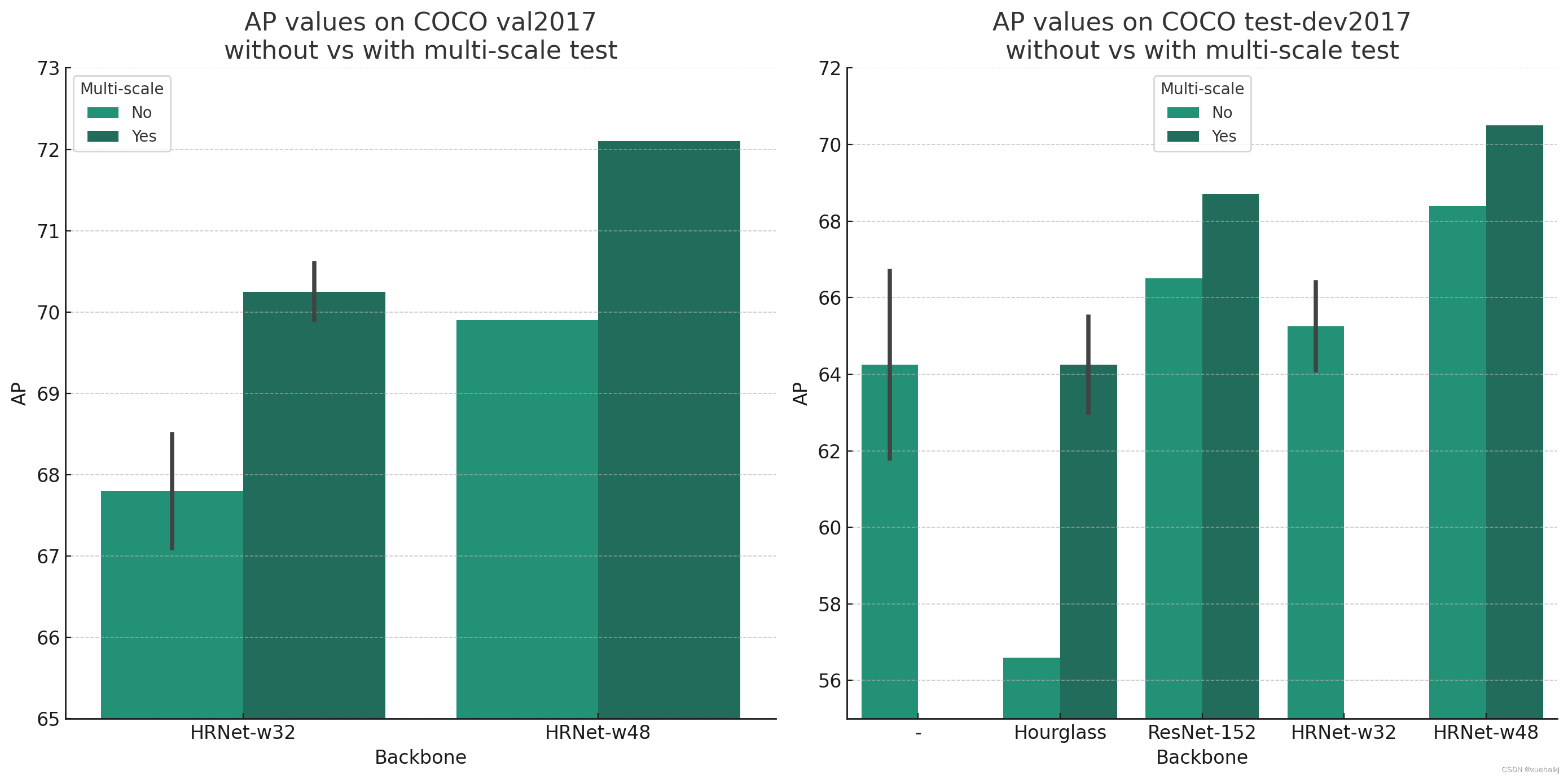
分析 COCO val2017 数据集
-
多尺度测试的影响
从 COCO val2017 数据集的图表中可以看出,在没有多尺度测试的情况下,使用 HRNet-w48 背景网络的 HigherHRNet 在 AP 值上高于使用 HRNet-w32 背景网络的版本。当应用多尺度测试时,所有模型的性能都有所提升,这表明多尺度测试可以有效地增强模型对不同尺度目标的检测能力。 -
背景网络和输入尺寸的影响
在相同的多尺度测试条件下,背景网络从 HRNet-w32 升级到 HRNet-w48,模型的 AP 值有明显提升。同时,当输入尺寸从 512 增加到 640 时,模型性能也有所提高,这说明更大的输入尺寸可以帮助模型捕捉到更多的细节,从而提高性能。
# Remove rows with '-' in 'AP' column for CrowdPose data
data_crowdpose_clean = data_crowdpose[data_crowdpose['AP'] != '-']
# Convert the 'AP' column to numeric
data_crowdpose_clean['AP'] = pd.to_numeric(data_crowdpose_clean['AP'])
# Re-plotting the AP values for CrowdPose test
plt.figure(figsize=(10, 5))
sns.barplot(x='Method', y='AP', data=data_crowdpose_clean)
plt.title('AP values on CrowdPose test')
plt.xlabel('Method')
plt.ylabel('AP')
plt.ylim(50, 70)
plt.show()
分析 COCO test-dev2017 数据集
-
HigherHRNet 与其他模型的对比
在 COCO test-dev2017 数据集上,不使用多尺度测试时,HigherHRNet 模型的 AP 值高于 OpenPose、Hourglass、PersonLab 和 PifPaf,这显示了 HigherHRNet 在关键点检测方面的优越性。在进行了多尺度测试之后,HigherHRNet 的 AP 值进一步提高,尤其是使用了 HRNet-w48 背景网络的版本,其性能领先于所有其他对比模型。 -
模型的参数和计算复杂度
尽管 HigherHRNet 在参数数量和计算复杂度上高于 HRNet-w32 版本,但其性能提升表明了更高的模型复杂度可以带来更准确的关键点检测结果。这在计算资源充足的情况下是可取的,但也需要考虑到计算成本和实际应用场景。
分析 CrowdPose 测试集
- HigherHRNet 在复杂场景的表现
CrowdPose 测试集是一个更具挑战性的数据集,因为它包含了更多的遮挡和群体场景。在这个数据集上,HigherHRNet 和 HigherHRNet+ 的性能依然优秀,特别是 HigherHRNet+ 在所有方法中达到了最高的 AP 值,这表明了该模型在处理复杂场景时的强大能力。
10.系统整合

参考博客《基于改进HigherHRNet的体育运动动作规范度检测系统》
11.参考文献
[1]金海波,马海强.相幅组合的函数型数据特征提取方法研究[J].计算机应用研究.2021,(8).DOI:10.19734/j.issn.1001-3695.2020.10.0363 .
[2]李宏伟,祝海江,冯延强.基于双线性插值的超声成像测井数据重采样处理方法研究[J].世界核地质科学.2020,(4).DOI:10.3969/j.issn.1672-0636.2020.04.006 .
[3]张永梅,滑瑞敏,马健喆,等.基于深度学习与超分辨率重建的遥感高时空融合方法[J].计算机工程与科学.2020,(9).DOI:10.3969/j.issn.1007-130X.2020.09.008 .
[4]刘巧玲,李想,明旭.基于双线性插值的CLAHE算法研究与实现[J].成都大学学报(自然科学版).2015,(2).DOI:10.3969/j.issn.1004-5422.2015.02.013 .
[5]Chao, Dong,Chen Change, Loy,Kaiming, He,等.Image Super-Resolution Using Deep Convolutional Networks.[J].IEEE Transactions on Pattern Analysis & Machine Intelligence.2016.295-307.

















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









